

很多人認為使用AI Agent就是直接扔個提示詞過去,然後等結果。做實驗這樣是沒問題的,但要是想在生產環境穩定輸出高質量結果,這套玩法就不行了。
核心問題是這種隨意的提示方式根本擴展不了。你會發現輸出結果亂七八糟,質量完全不可控,還浪費計算資源。
真正有效的做法是設計結構化的Agent工作流。
那些做得好的團隊從來不指望一個提示詞解決所有問題。他們會把複雜任務拆解成步驟,根據不同輸入選擇合適的模型,然後持續驗證輸出質量,直到結果達標。
本文會詳細介紹5種常用的的Agent工作流模式,每種都有完整的實現代碼和使用場景分析。看完你就知道每種模式解決什麼問題,什麼時候用,以及為什麼能產生更好的效果。
模式一:串行鏈式處理
鏈式處理的核心思路是把一個LLM調用的輸出直接作為下一個調用的輸入。比起把所有邏輯塞進一個巨大的提示詞,拆分成小步驟要靠譜得多。
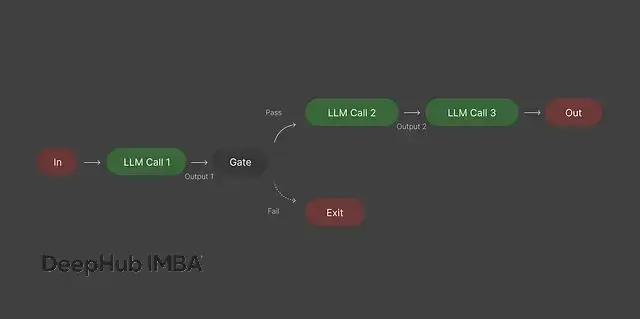
道理很簡單:步驟越小,出錯的概率越低。鏈式處理等於給模型提供了明確的推理路徑,而不是讓它自己瞎猜。
如果不用鏈式處理,你可能會經常會遇到輸出冗長混亂、前後邏輯不一致、錯誤率偏高的問題。有了鏈式處理,每一步都可以單獨檢查,整個流程的可控性會大幅提升。
from typing import List
from helpers import run_llm
def serial_chain_workflow(input_query: str, prompt_chain : List[str]) -> List[str]:
"""運行一系列LLM調用來處理`input_query`,
使用`prompt_chain`中指定的提示詞列表。
"""
response_chain = []
response = input_query
for i, prompt in enumerate(prompt_chain):
print(f"Step {i+1}")
response = run_llm(f"{prompt}\nInput:\n{response}", model='meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo')
response_chain.append(response)
print(f"{response}\n")
return response_chain
# 示例
question = "Sally earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?"
prompt_chain = ["""Given the math problem, ONLY extract any relevant numerical information and how it can be used.""",
"""Given the numberical information extracted, ONLY express the steps you would take to solve the problem.""",
"""Given the steps, express the final answer to the problem."""]
responses = serial_chain_workflow(question, prompt_chain)模式二:智能路由
路由系統的作用是決定不同類型的輸入應該交給哪個模型處理。
現實情況是,不是每個查詢都需要動用你最強大、最昂貴的模型。簡單任務用輕量級模型就夠了,複雜任務才需要重型武器。路由機制確保資源分配的合理性。
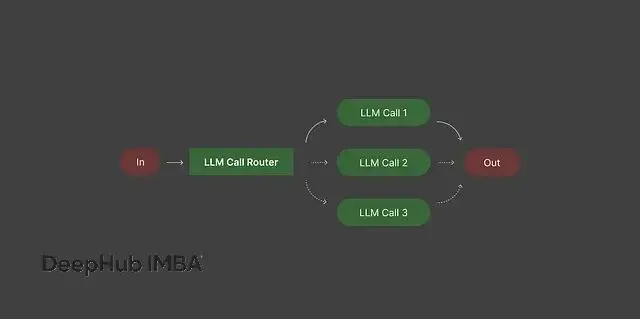
沒有路由的話,要麼在簡單任務上浪費資源,要麼用不合適的模型處理複雜問題導致效果很差。
實現路由需要先定義輸入的分類標準,比如簡單查詢、複雜推理、受限領域等,然後為每個類別指定最適合的模型或處理流程。這樣做的好處是成本更低、響應更快、質量更穩定,因為每種任務都有專門的工具來處理。
from pydantic import BaseModel, Field
from typing import Literal, Dict
from helpers import run_llm, JSON_llm
def router_workflow(input_query: str, routes: Dict[str, str]) -> str:
"""給定一個`input_query`和包含每個選項和詳細信息的`routes`字典。
為任務選擇最佳模型並返回模型的響應。
"""
ROUTER_PROMPT = """Given a user prompt/query: {user_query}, select the best option out of the following routes:
{routes}. Answer only in JSON format."""
# 從路由字典創建模式
class Schema(BaseModel):
route: Literal[tuple(routes.keys())]
reason: str = Field(
description="Short one-liner explanation why this route was selected for the task in the prompt/query."
)
# 調用LLM選擇路由
selected_route = JSON_llm(
ROUTER_PROMPT.format(user_query=input_query, routes=routes), Schema
)
print(
f"Selected route:{selected_route['route']}\nReason: {selected_route['reason']}\n"
)
# 在選定的路由上使用LLM。
# 也可以為每個路由使用不同的提示詞。
response = run_llm(user_prompt=input_query, model=selected_route["route"])
print(f"Response: {response}\n")
return response
prompt_list = [
"Produce python snippet to check to see if a number is prime or not.",
"Plan and provide a short itenary for a 2 week vacation in Europe.",
"Write a short story about a dragon and a knight.",
]
model_routes = {
"Qwen/Qwen2.5-Coder-32B-Instruct": "Best model choice for code generation tasks.",
"Gryphe/MythoMax-L2-13b": "Best model choice for story-telling, role-playing and fantasy tasks.",
"Qwen/QwQ-32B-Preview": "Best model for reasoning, planning and multi-step tasks",
}
for i, prompt in enumerate(prompt_list):
print(f"Task {i+1}: {prompt}\n")
print(20 * "==")
router_workflow(prompt, model_routes)模式三:並行處理
大部分人習慣讓LLM一個任務一個任務地處理。但如果任務之間相互獨立,完全可以並行執行然後合併結果,這樣既節省時間又能提升輸出質量。
並行處理的思路是把大任務分解成可以同時進行的小任務,等所有部分都完成後再把結果整合起來。
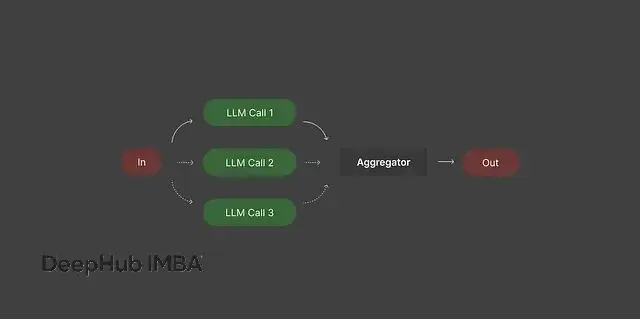
比如做代碼審查的時候,可以讓一個模型專門檢查安全問題,另一個關注性能優化,第三個負責代碼可讀性,最後把所有反饋合併成完整的審查報告。文檔分析也是類似的思路:把長報告按章節拆分,每個部分單獨總結,再合併成整體摘要。文本分析任務中,情感分析、實體提取、偏見檢測可以完全並行進行。
不用並行處理的話,不僅速度慢,還容易讓單個模型負擔過重,導致輸出混亂或者前後不一致。並行方式讓每個模型專注於自己擅長的部分,最終結果會更準確,也更容易維護。
import asyncio
from typing import List
from helpers import run_llm, run_llm_parallel
async def parallel_workflow(prompt : str, proposer_models : List[str], aggregator_model : str, aggregator_prompt: str):
"""運行並行LLM調用鏈來處理`input_query`,
使用`models`中指定的模型列表。
返回最終聚合器模型的輸出。
"""
# 從建議器模型收集中間響應
proposed_responses = await asyncio.gather(*[run_llm_parallel(prompt, model) for model in proposer_models])
# 使用聚合器模型聚合響應
final_output = run_llm(user_prompt=prompt,
model=aggregator_model,
system_prompt=aggregator_prompt + "\n" + "\n".join(f"{i+1}. {str(element)}" for i, element in enumerate(proposed_responses)
))
return final_output, proposed_responses
reference_models = [
"microsoft/WizardLM-2-8x22B",
"Qwen/Qwen2.5-72B-Instruct-Turbo",
"google/gemma-2-27b-it",
"meta-llama/Llama-3.3-70B-Instruct-Turbo",
]
user_prompt = """Jenna and her mother picked some apples from their apple farm.
Jenna picked half as many apples as her mom. If her mom got 20 apples, how many apples did they both pick?"""
aggregator_model = "deepseek-ai/DeepSeek-V3"
aggregator_system_prompt = """You have been provided with a set of responses from various open-source models to the latest user query.
Your task is to synthesize these responses into a single, high-quality response. It is crucial to critically evaluate the information
provided in these responses, recognizing that some of it may be biased or incorrect. Your response should not simply replicate the
given answers but should offer a refined, accurate, and comprehensive reply to the instruction. Ensure your response is well-structured,
coherent, and adheres to the highest standards of accuracy and reliability.
Responses from models:"""
async def main():
answer, intermediate_reponses = await parallel_workflow(prompt = user_prompt,
proposer_models = reference_models,
aggregator_model = aggregator_model,
aggregator_prompt = aggregator_system_prompt)
for i, response in enumerate(intermediate_reponses):
print(f"Intermetidate Response {i+1}:\n\n{response}\n")
print(f"Final Answer: {answer}\n")
模式四:編排器-工作器架構
這種模式的特點是用一個編排器模型來規劃整個任務,然後把具體的子任務分配給不同的工作器模型執行。
編排器的職責是分析任務需求,決定執行順序,你不需要事先設計好完整的工作流程。工作器模型各自處理分配到的任務,編排器負責把所有輸出整合成最終結果。
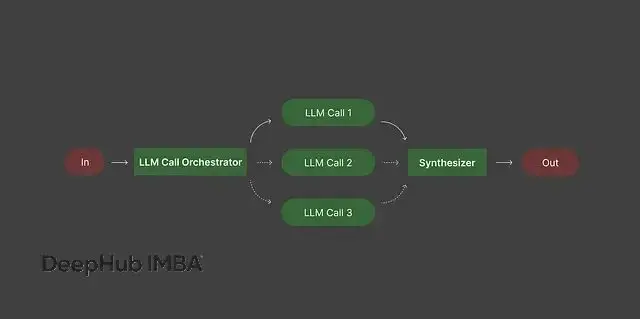
這種架構在很多場景下都很實用。寫博客文章的時候,編排器可以把任務拆分成標題設計、內容大綱、具體章節寫作,然後讓專門的工作器處理每個部分,最後組裝成完整文章。開發程序時,編排器負責分解成環境配置、核心功能實現、測試用例編寫等子任務,不同的工作器生成對應的代碼片段。數據分析報告也是類似思路:編排器識別出需要數據概覽、關鍵指標計算、趨勢分析等部分,工作器分別生成內容,編排器最後整合成完整報告。
這種方式的好處是減少了人工規劃的工作量,同時保證複雜任務的有序進行。編排器處理任務管理,每個工作器專注於自己的專業領域,整個流程既有條理又有效率。
import asyncio
import json
from pydantic import BaseModel, Field
from typing import Literal, List
from helpers import run_llm_parallel, JSON_llm
ORCHESTRATOR_PROMPT = """
分析這個任務並將其分解為2-3種不同的方法:
任務: {task}
提供分析:
解釋你對任務的理解以及哪些變化會有價值。
關注每種方法如何服務於任務的不同方面。
除了分析之外,提供2-3種處理任務的方法,每種都有簡要描述:
正式風格: 技術性和精確地寫作,專注於詳細規範
對話風格: 以友好和引人入勝的方式寫作,與讀者建立聯繫
混合風格: 講述包含技術細節的故事,將情感元素與規範相結合
僅返回JSON輸出。
"""
WORKER_PROMPT = """
基於以下內容生成內容:
任務: {original_task}
風格: {task_type}
指導原則: {task_description}
僅返回你的響應:
[你的內容在這裏,保持指定的風格並完全滿足要求。]
"""
task = """為新的環保水瓶寫一個產品描述。
目標受眾是有環保意識的千禧一代,關鍵產品特性是:無塑料、保温、終身保修
"""
class Task(BaseModel):
type: Literal["formal", "conversational", "hybrid"]
description: str
class TaskList(BaseModel):
analysis: str
tasks: List[Task] = Field(..., default_factory=list)
async def orchestrator_workflow(task : str, orchestrator_prompt : str, worker_prompt : str):
"""使用編排器模型將任務分解為子任務,然後使用工作器模型生成並返回響應。"""
# 使用編排器模型將任務分解為子任務
orchestrator_response = JSON_llm(orchestrator_prompt.format(task=task), schema=TaskList)
# 解析編排器響應
analysis = orchestrator_response["analysis"]
tasks= orchestrator_response["tasks"]
print("\n=== ORCHESTRATOR OUTPUT ===")
print(f"\nANALYSIS:\n{analysis}")
print(f"\nTASKS:\n{json.dumps(tasks, indent=2)}")
worker_model = ["meta-llama/Llama-3.3-70B-Instruct-Turbo"]*len(tasks)
# 從工作器模型收集中間響應
return tasks , await asyncio.gather(*[run_llm_parallel(user_prompt=worker_prompt.format(original_task=task, task_type=task_info['type'], task_description=task_info['description']), model=model) for task_info, model in zip(tasks,worker_model)])
async def main():
task = """為新的環保水瓶寫一個產品描述。
目標受眾是有環保意識的千禧一代,關鍵產品特性是:無塑料、保温、終身保修
"""
tasks, worker_resp = await orchestrator_workflow(task, orchestrator_prompt=ORCHESTRATOR_PROMPT, worker_prompt=WORKER_PROMPT)
for task_info, response in zip(tasks, worker_resp):
print(f"\n=== WORKER RESULT ({task_info['type']}) ===\n{response}\n")
asyncio.run(main())模式五:評估器-優化器循環
這種模式的核心是通過反饋循環來持續改進輸出質量。
具體機制是一個模型負責生成內容,另一個評估器模型按照預設的標準檢查輸出質量。如果沒達標,生成器根據反饋進行修改,評估器再次檢查,這個過程一直重複到輸出滿足要求為止。
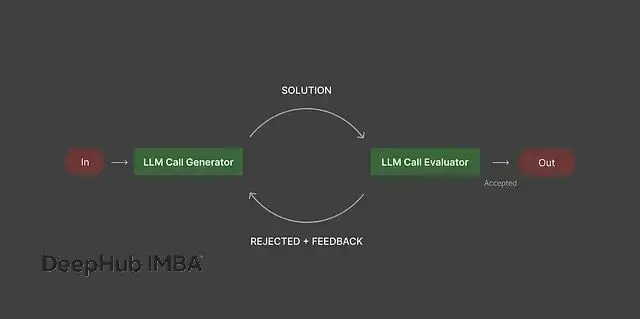
在代碼生成場景中,生成器寫出代碼後,評估器會檢查語法正確性、算法效率、代碼風格等方面,發現問題就要求重寫。營銷文案也是類似流程:生成器起草內容,評估器檢查字數限制、語言風格、信息準確性,不合格就繼續改。數據報告的製作過程中,生成器產出分析結果,評估器驗證數據完整性和結論的邏輯性。
如果沒有這套評估優化機制,輸出質量會很不穩定,需要大量人工檢查和修正。有了評估器-優化器循環,可以自動保證結果符合預期標準,減少重複的手工干預。
from pydantic import BaseModel
from typing import Literal
from helpers import run_llm, JSON_llm
task = """
實現一個棧,包含:
1. push(x)
2. pop()
3. getMin()
所有操作都應該是O(1)。
"""
GENERATOR_PROMPT = """
你的目標是基於<用户輸入>完成任務。如果有來自你之前生成的反饋,
你應該反思它們來改進你的解決方案
以下列格式簡潔地輸出你的答案:
思路:
[你對任務和反饋的理解以及你計劃如何改進]
響應:
[你的代碼實現在這裏]
"""
def generate(task: str, generator_prompt: str, context: str = "") -> tuple[str, str]:
"""基於反饋生成和改進解決方案。"""
full_prompt = f"{generator_prompt}\n{context}\n任務: {task}" if context else f"{generator_prompt}\n任務: {task}"
response = run_llm(full_prompt, model="Qwen/Qwen2.5-Coder-32B-Instruct")
print("\n## Generation start")
print(f"Output:\n{response}\n")
return response
EVALUATOR_PROMPT = """
評估以下代碼實現的:
1. 代碼正確性
2. 時間複雜度
3. 風格和最佳實踐
你應該只進行評估,不要嘗試解決任務。
只有當所有標準都得到滿足且你沒有進一步改進建議時,才輸出"PASS"。
如果有需要改進的地方,請提供詳細反饋。你應該指出需要改進什麼以及為什麼。
只輸出JSON。
"""
def evaluate(task : str, evaluator_prompt : str, generated_content: str, schema) -> tuple[str, str]:
"""評估解決方案是否滿足要求。"""
full_prompt = f"{evaluator_prompt}\n原始任務: {task}\n要評估的內容: {generated_content}"
# 構建評估模式
class Evaluation(BaseModel):
evaluation: Literal["PASS", "NEEDS_IMPROVEMENT", "FAIL"]
feedback: str
response = JSON_llm(full_prompt, Evaluation)
evaluation = response["evaluation"]
feedback = response["feedback"]
print("## Evaluation start")
print(f"Status: {evaluation}")
print(f"Feedback: {feedback}")
return evaluation, feedback
def loop_workflow(task: str, evaluator_prompt: str, generator_prompt: str) -> tuple[str, list[dict]]:
"""持續生成和評估,直到評估器通過最後生成的響應。"""
# 存儲生成器的先前響應
memory = []
# 生成初始響應
response = generate(task, generator_prompt)
memory.append(response)
# 當生成的響應沒有通過時,繼續生成和評估
while True:
evaluation, feedback = evaluate(task, evaluator_prompt, response)
# 終止條件
if evaluation == "PASS":
return response
# 將當前響應和反饋添加到上下文中並生成新響應
context = "\n".join([
"Previous attempts:",
*[f"- {m}" for m in memory],
f"\nFeedback: {feedback}"
])
response = generate(task, generator_prompt, context)
memory.append(response)
loop_workflow(task, EVALUATOR_PROMPT, GENERATOR_PROMPT)總結
這些結構化工作流徹底改變了LLM的使用方式。
不再是隨便拋個提示詞然後碰運氣,而是有章法地分解任務、合理分配模型資源、並行處理獨立子任務、智能編排複雜流程,再通過評估循環保證輸出質量。
每種模式都有明確的適用場景,組合使用能讓你更高效地處理各種複雜任務。可以先從一個模式開始熟悉,掌握之後再逐步引入其他模式。
當你把路由、編排、並行處理、評估優化這些機制組合起來使用時,就徹底告別了那種混亂、不可預測的提示方式,轉而獲得穩定、高質量、可用於生產環境的輸出結果。長期來看,這種方法不僅節省時間,更重要的是給你對AI系統的完全控制權,讓每次輸出都在預期範圍內,從根本上解決了臨時提示方式帶來的各種問題。
掌握這些工作流模式,你就能充分發揮AI的潛力,穩定地獲得高質量結果。
https://avoid.overfit.cn/post/c0be5e7283234053b03fc894fc7c7342
作者:Paolo Perrone