

下肢假肢的控制系統設計一直是個老大難問題。傳統控制理論需要建立肢體和環境的精確數學模型,但現實世界可以不一樣,比如説地面摩擦力時刻在變,坡度各不相同,患者隨時可能絆一下。這就需要控制器具備自適應能力,能從失誤中恢復,還得在沒有顯式編程的情況下習得自然的步態模式。

強化學習給出了一條思路:讓假肢自己通過試錯"學會"走路。但是標準RL算法有個毛病,它太貪心了,找到一種能用的移動方式就死守着不放,一旦外界條件變化,整個控制策略就非常容易崩盤。
這篇文章用Soft Actor-Critic(SAC)算法解決BipedalWalker-v3環境。但這不只是跑個遊戲demo那麼簡單,更重要的是從生物工程視角解讀整個問題:把神經網絡對應到神經系統,把獎勵函數對應到代謝效率。
SAC的核心思想:為什麼要"soft"?
常規強化學習只盯着一個目標——最大化期望累積獎勵。這種貪心策略在國際象棋這類確定性博弈裏表現不錯,但放到物理控制任務上問題就非常的多了,這是因為系統動力學稍有變化,貪心策略往往直接翻車。
要理解SAC裏的"軟"字,先得搞清楚Actor-Critic架構。這個框架其實模擬了人類學習運動技能的過程。打個比方:患者(Actor)在學習使用假肢,旁邊有個理療師(Critic)在觀察和指導。
Actor(策略網絡π) 負責控制肢體,觀察當前狀態(關節角度、身體平衡),然後決定該怎麼動。訓練初期它啥也不懂只能瞎動彈。Critic(Q函數網絡) 負責評估Actor動作的質量,不直接控制肢體,只預測某個動作長期來看能拿到多少獎勵。
傳統算法裏,Actor拼命想找到那個"最優解"來討好Critic。但SAC不一樣,Critic鼓勵Actor嘗試多種不同的成功路徑,不僅看結果,還看方法的多樣性。
SAC採用最大熵框架,智能體的目標變成了同時最大化期望獎勵和策略熵(隨機性):
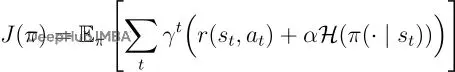
這裏的𝓗就是熵。
這對假肢控制有什麼意義?
一方面是探索機制。比如説嬰兒會用隨機運動(所謂motor babbling)來摸索肢體的運動規律。高熵保證了充分探索,避免智能體掉進"安全小碎步"的局部最優陷阱,就是那種幾乎不動、只求不摔的保守策略。另一方面是泛化性,熵最大化訓練出來的智能體掌握了一整套策略組合。某條肌肉激活路徑被幹擾了?沒關係,還有備選方案。這讓步態對打滑、絆絆腳之類的意外具備容錯能力。
從仿真到臨牀的映射關係
BipedalWalker-v3是個24維數字向量。但從生物工程角度看它相當於膝上假肢控制問題的簡化版。
觀察空間對應傳感器融合
Gym裏的24維觀察向量可以直接對應到Otto Bock Genium這類智能假肢的傳感器配置:
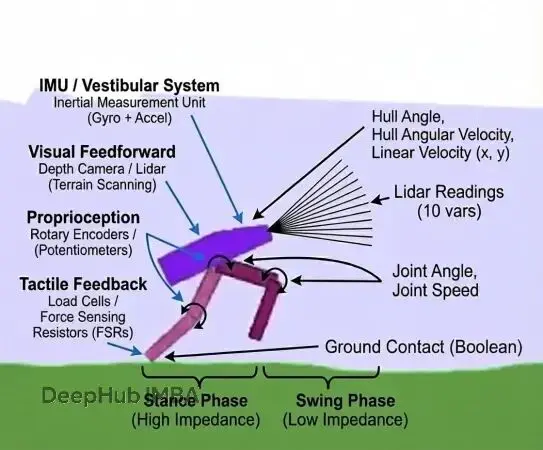
軀幹角度和速度對應前庭系統——"軀幹"代表質心位置,硬件上用IMU(慣性測量單元)採集平衡數據。關節編碼器對應本體感覺,仿真裏提供的關節角度和速度,在真實假肢上由霍爾傳感器和旋轉編碼器獲取。激光雷達對應視覺前饋,現代研究型假肢已經開始集成深度相機來預判地形。
動作空間對應執行器
智能體用[-1, 1]範圍的連續值控制髖關節和膝關節。這對應到硬件上就是直流電機的電流控制,或者氣動人工肌肉(PAMs)的壓力調節。
為什麼連續控制這麼重要呢?DQN這類離散算法輸出的是生硬的開關命令,SAC輸出的是連續平滑的扭矩曲線。對患者來説這可不是小事,生硬的驅動會在殘肢上產生剪切力長期下去會損傷組織。
代碼實現
以下實現改編自CleanRL並使用PyTorch搭建網絡,通過Gymnasium提供仿真環境運行。
Actor網絡:物理約束的強制執行
連續控制的一個核心挑戰是把動作限制在物理邊界內。這裏用高斯策略配合
tanh函數壓縮輸出,確保電機指令不會超出[−1, 1]的安全範圍。
# LOGIC: The Actor Network (from sac_bipedalwalker_enhanced.py)
def get_action(self, x):
mean, log_std = self(x)
std = log_std.exp()
# The Reparameterization Trick:
# Allows gradients to flow back through the sampling process
normal = torch.distributions.Normal(mean, std)
x_t = normal.rsample()
# Squash output to [-1, 1] for the environment limits
y_t = torch.tanh(x_t)
action = y_t * self.action_scale + self.action_bias
# Correction for the log_prob due to tanh squashing (Math detail)
log_prob = normal.log_prob(x_t)
log_prob -= torch.log(self.action_scale * (1 - y_t.pow(2)) + 1e-6)
log_prob = log_prob.sum(1, keepdim=True)
return action, log_prob, mean注意
x_t = normal.rsample()這行。看起來普普通通,實際上是整個算法的數學根基。
標準隨機策略裏,採樣動作是個隨機事件,會打斷反向傳播需要的導數鏈,隨機數生成器沒法求導。重參數化技巧繞開了這個問題:不直接從分佈採樣,而是先採一個標準正態噪聲ε,再用網絡輸出的均值μ和標準差σ做變換:xt = μ + σ · ε。因為ε跟網絡參數無關,μ和σ的梯度就能正常計算了,Actor網絡也就能從Critic的反饋裏學到東西。沒這個技巧,連續策略根本沒法訓。
自動熵調節
早期SAC版本里,温度參數α是固定的。α太大,智能體走路像喝醉了;α太小,又永遠學不會探索。現在的做法是把α當成可學習參數,讓智能體自己決定什麼時候該收斂:
# LOGIC: Automatic Entropy Tuning (inside training loop)
if args.autotune:
with torch.no_grad():
_, log_pi, _ = actor.get_action(data.observations)
# Minimize difference between current entropy and target entropy
# target_entropy is usually -dim(Action Space)
alpha_loss = (-log_alpha.exp() * (log_pi + target_entropy)).mean()
a_optimizer.zero_grad()
alpha_loss.backward()
a_optimizer.step()
alpha = log_alpha.exp().item()實驗結果分析
訓練跑了350k步。這裏我們要看的不是最終分數多高,而是學出來的步態在生物力學上是否合理。
學習曲線的解讀
智能體一開始回報是負的,站都站不穩,跟患者剛裝上新假肢時的狀態很像。
看下面的學習曲線,藍色陰影是各episode的標準差。0-100k步階段方差很低,但這不好,因為智能體一直在失敗,每次都是秒摔。
到了150k-250k步,方差突然爆炸。這是個關鍵轉折期,智能體開始嘗試高風險策略,有時走得漂亮,有時摔得很慘。只有進入300k步之後的穩定區,均值高、方差收窄,這樣才能考慮"凍結"策略用於實際部署。方差收窄意味着策略從"碰運氣"進化到了"真會走"。
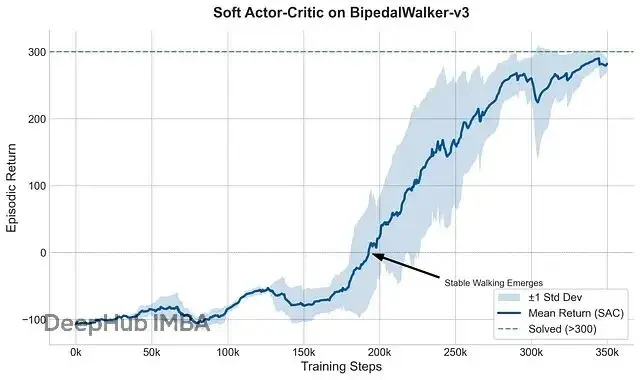
而150k步左右發生了"相變",智能體突然開竅了,獎勵曲線急劇上升。250k步後穩定在200分以上,算是解決了這個環境。
相位圖分析
光看分數不夠,還得檢查運動學特徵。下圖是髖關節的相位圖,橫軸關節角度,縱軸角速度。
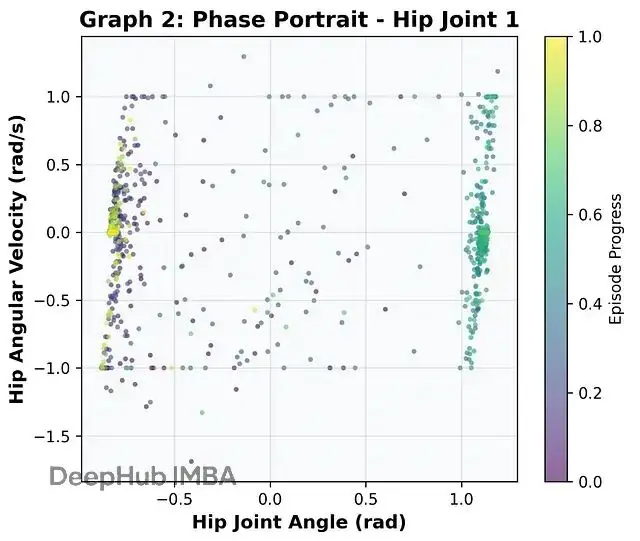
紫色和藍色的散點代表早期階段,角度和速度之間毫無關聯,智能體就是在瞎蹬腿,漫無目的地探索狀態空間。
隨着訓練推進(顏色向黃綠過渡),散點開始收斂成一個封閉的軌道形狀。這在控制論和生物力學裏叫極限環(Limit Cycle)。
極限環説明系統找到了穩定的週期軌道。即使遇到小擾動,系統也傾向於回到這個環上,這正是動態穩定步態的定義。這個環是從SAC目標函數裏自發涌現出來的,不是顯式編程的結果。環的形狀比較光滑並且沒有鋸齒,説明Actor網絡裏的
tanh壓縮確實產生了平滑的扭矩曲線,避免了離散RL常見的"抖振"問題。這對假肢安全性至關重要。
能效特徵
最後看Critic損失(智能體的"困惑程度")和動作幅度(扭矩大小)的關係。
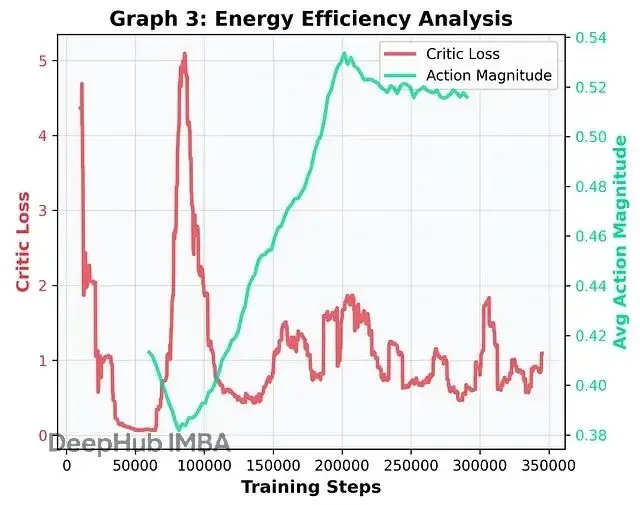
學習階段(50k-200k步),Critic損失達到峯值,智能體還在跟物理規律較勁。極限環建立後(200k步以後),動作幅度穩定下來,Critic損失也降到較低水平。
更細緻地看,可以把訓練過程分成三個力學階段:
"僵住"階段(0-70k步):動作幅度(綠線)起始值很低。智能體把關節鎖死以避免摔倒懲罰,這在運動學習裏叫"共同收縮"策略。不怎麼動,自然也不會摔得太慘。
"瘋狂試探"階段(70k-200k步):Critic損失劇烈震盪,這正是智能體開始嘗試往前走的時候。反覆失敗帶來高"驚訝度"。同時動作幅度急劇攀升説明智能體意識到想走路就得狠狠發力,哪怕暫時會摔。
"熟練掌握"階段(200k步以後):極限環形成,Critic損失驟降,智能體對物理世界不再感到意外。有意思的是動作幅度:在200k附近達到峯值後反而略有下降然後趨於平穩。這是熟練運動的典型特徵,智能體學會了借力,不再每一步都用蠻力,而是順着動力學"流"起來,能量消耗得到了優化。
一個可能的改進方向是在獎勵函數里加入代謝運輸成本(COT)懲罰項,鼓勵智能體發現更"被動-動態"的步態模式,靠慣性而不是持續肌肉輸出來行走,這對延長真實假肢的電池續航很有價值。
總結
SAC算法在BipedalWalker環境中跑了350k步後,智能體從"秒摔"進化到穩定行走(200+分)。相位圖顯示髖關節運動收斂成極限環,動態穩定步態的標誌。能效曲線也印證了這點:智能體最終學會借力而非蠻幹。
從假肢控制角度看,SAC的最大熵框架帶來的策略多樣性是關鍵優勢,讓系統對打滑、絆腳這類意外有容錯空間。不過真要落地到Otto Bock C-Leg這類設備上,還得解決傳感器噪聲、執行延遲和安全約束的問題,域隨機化和PID安全籠是兩個可行方向。
https://avoid.overfit.cn/post/ab5860e7071441e9aab80e9876b2f45d
作者:Cristlianreal