

LLM推理服務中,(Time-To-First-Token) 一直是個核心指標。用户發起請求到看見第一個token輸出,這段時間越短體驗越好,但實際部署中往往存在各種問題。
LMCache針對TTFT提出了一套KV緩存持久化與複用的方案。項目開源,目前已經和vLLM深度集成。

原理
大模型推理有個特點:每次處理輸入文本都要重新計算KV緩存。KV緩存可以理解為模型"閲讀"文本時產生的中間狀態,類似於做的筆記。
問題在於傳統方案不復用這些"筆記"。同樣的文本再來一遍,整個KV緩存從頭算。
LMCache的做法是把KV緩存存下來——不光存GPU顯存裏,還能存到CPU內存、磁盤上。下次遇到相同文本(注意不只是前綴匹配,是任意位置的文本複用),直接取緩存,省掉重複計算。
實測效果:搭配vLLM,在多輪對話、RAG這類場景下,響應速度能快3到10倍。
偽代碼大概是這樣:
# Old way: Slow as molasses
def get_answer(prompt):
memory = build_memory_from_zero(prompt) # GPU cries
return model.answer(memory)
# With LMCache: Zippy and clever
import lmcache
def get_answer(prompt):
if lmcache.knows_this(prompt): # Seen it before?
memory = lmcache.grab_memory(prompt) # Snag it fast
else:
memory = build_memory_from_zero(prompt)
lmcache.save_memory(prompt, memory) # Keep it for later
return model.answer(memory)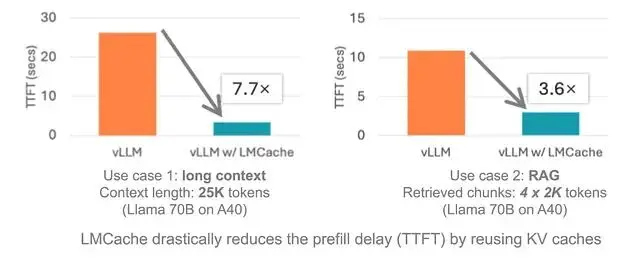
幾個特性
緩存讀取速度比原生方案快7倍左右,吞吐量也有提升。文本不管在prompt的什麼位置,只要重複出現就能命中緩存。
存儲層面支持多級——GPU顯存、CPU內存、磁盤都行,甚至可以接NIXL這種分佈式存儲,GPU壓力能減輕不少。
LMCache和vLLM v1集成得比較深,支持跨設備共享KV緩存、跨節點傳遞等特性。生產環境裏可以配合llm-d、KServe這些工具用。
做聊天機器人或者RAG應用的話,這東西能在不升級硬件的情況下把延遲壓下來一部分。
安裝
LMCache目前主要支持Linux,Windows上得走WSL或者社區的適配方案。
基本要求:Python 3.9+,NVIDIA GPU(V100、H100這類),CUDA 12.8以上。裝好之後離線也能跑。
pip直接裝:
pip install lmcache自帶PyTorch依賴。遇到奇怪報錯的話,建議換源碼編譯。
想嚐鮮可以裝TestPyPI上的預發佈版:
pip install --index-url https://pypi.org/simple --extra-index-url https://test.pypi.org/simple lmcache==0.3.4.dev61驗證一下版本:
importlmcache
fromimportlib.metadataimportversion
print(version("lmcache")) # Should be 0.3.4.dev61 or newer具體版本號去GitHub看最新的。
源碼編譯
喜歡折騰的可以clone下來自己編:
git clone https://github.com/LMCache/LMCache.git
cd LMCache
pip install -r requirements/build.txt
# Pick one:
# A: Choose your Torch
pip install torch==2.7.1 # Good for vLLM 0.10.0
# B: Get vLLM with Torch included
pip install vllm==0.10.0
pip install -e . --no-build-isolation跑個驗證:
python3 -c"import lmcache.c_ops"不報錯就行。
用uv的話會快一些:
git clone https://github.com/LMCache/LMCache.git
cd LMCache
uv venv --python3.12
source .venv/bin/activate
uv pip install -r requirements/build.txt
# Same Torch/vLLM choices
uv pip install -e . --no-build-isolationDocker部署
如果嫌麻煩直接拉鏡像:
# Stable
docker pull lmcache/vllm-openai
# Nightly
docker pull lmcache/vllm-openai:latest-nightlyAMD GPU(比如MI300X)需要從vLLM基礎鏡像開始,加上ROCm編譯參數:
PYTORCH_ROCM_ARCH="gfx942" \
TORCH_DONT_CHECK_COMPILER_ABI=1 \
CXX=hipcc \
BUILD_WITH_HIP=1 \
python3 -m pip install --no-build-isolation -e .小結
KV緩存複用這個思路已經是基本操作了,但LMCache把它做得比較完整:多級存儲、任意位置匹配、和vLLM的原生集成,這些組合起來確實能解決實際問題。對於多輪對話、RAG這類prompt重複率高的場景,3-10倍的TTFT優化是實打實的。
LMCache目前主要綁定vLLM生態,Linux優先,AMD GPU支持還在完善中。但作為一個開源方案,值得關注。
項目地址:https://avoid.overfit.cn/post/7854fe6d56b24e6fb836c6bfe42981fb
作者:Algo Insights