

PDF文檔中常常包含大量數據,尤其是官方報告、學術論文、財務報表等文檔,往往包含了結構化的表格數據。表格作為承載關鍵信息的載體,其內容的準確提取對於數據分析、研究論證乃至業務決策具有重大意義。然而,PDF格式雖保證了文檔的跨平台一致性,卻給數據的直接提取和利用設置了障礙。掌握如何用Python高效地從PDF文檔中提取表格,可以提升我們的數據處理能力、加速信息流轉的能力。本文介紹如何利用Python來快速提取PDF文檔中的表格數據,以及將表格數據保存到Excel表格和CSV文件。
- 用Python提取PDF文檔中的表格數據
- 提取PDF文檔中的表格並保存到Excel文件
本文所使用的方法需要用到Spire.PDF for Python,可通過PyPI安裝:pip install Spire.PDF。
提取PDF文檔中的表格數據
PdfTableExtractor(PdfDocument) 類可以用於處理PDF文檔表格提取工作。創建好此類的實例之後,再使用 PdfTableExtractor.ExtractTable(int: page index) 方法就可以提取到指定頁面上的所有表格了。獲取到表格之後,我們就可以使用 PdfTable.GetText(int: row index, int column index) 方法提取表格數據保存到其他位置了。
以下是提取PDF表格並保存到文本的操作步驟:
- 導入所需模塊。
- 創建
PdfDocument實例,並使用PdfDocument.LoadFromFile()方法載入PDF文檔。 - 創建一個列表儲存表格數據,再使用文檔創建一個
PdfTableExtractor實例。 - 遍歷文檔頁面,使用
PdfTableExtractor.ExtractTable(int: page index)方法提取頁面上的表格。 - 遍歷每個提取到的表格,為每個表格創建字符串對象,再使用
PdfTable.GetText(int: row index, int column index)方法獲取表格數據並添加到字符串中。 - 將每個表格保存為一個文本文件。
- 釋放資源。
代碼示例:
from spire.pdf import *
from spire.pdf.common import *
# 創建PdfDocument類的實例
pdf = PdfDocument()
# 加載PDF文件
pdf.LoadFromFile("示例.pdf")
# 創建列表
list = []
# 創建PdfTableExtractor對象
extractor = PdfTableExtractor(pdf)
# 遍歷文檔的頁面
for pageIndex in range(pdf.Pages.Count):
# 從頁面提取表格
tableList = extractor.ExtractTable(pageIndex)
# 檢查表格列表是否不為空且列表不為空
if tableList is not None and len(tableList) > 0:
# 遍歷列表中的表格
for table in tableList:
tableData = ''
# 獲取行數和列數
row = table.GetRowCount()
column = table.GetColumnCount()
# 遍歷表格的行和列
for i in range(row):
for j in range(column):
# 從單元格獲取文本
text = table.GetText(i, j)
# 將文本添加到列表中
tableData += text + " "
tableData += "\n"
list.append(tableData)
# 將每個表格保存為txt文件
for i in range(len(list)):
fileName = "output/Tables/ExtractedPDFTables{0}.txt".format(i)
with open(fileName, "w") as f:
f.writelines(list[i])
# 釋放資源
pdf.Close()提取結果:
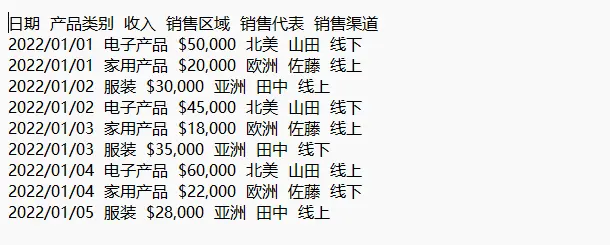

提取PDF文檔中的表格並保存到CSV文件
在提取表格數據時,我們可以結合Spire.XLS for Python庫(pip install Spire.XLS)來直接將表格數據寫入Excel文件中。以下是操作步驟:
- 導入所需模塊。
- 創建一個
PdfDocument類的實例。 - 使用
PdfDocument.LoadFromFile()方法加載一個示例PDF文檔。 - 創建一個
Workbook類的實例,並清除其中的默認工作表。 - 遍歷PDF文檔中的頁面。
- 使用
PdfTableExtractor.ExtractTable()方法從頁面中提取表格。 - 遍歷提取出的表格。
- 對於每個表格,使用
Workbook.Worksheets.Add()方法向工作簿中添加一個工作表。 - 使用
PdfTable.GetText()方法獲取表格中單元格的文本。 - 使用
Worksheet.Range[rowIndex, columnIndex].Value屬性將文本寫入工作表中的特定單元格。 - 使用
Workbook.SaveToFile()方法將結果工作簿保存為Excel文件。 - 釋放資源。
代碼示例:
from spire.pdf import *
from spire.xls import *
# 創建一個PdfDocument對象
doc = PdfDocument()
# 加載示例PDF文件
doc.LoadFromFile("示例.pdf")
# 創建一個Workbook對象
workbook = Workbook()
# 清除默認的工作表
workbook.Worksheets.Clear()
# 創建一個PdfTableExtractor對象
extractor = PdfTableExtractor(doc)
sheetNumber = 1
# 循環遍歷頁面
for pageIndex in range(doc.Pages.Count):
# 從特定頁面提取表格
tableList = extractor.ExtractTable(pageIndex)
# 判斷表格列表是否不為空
if tableList is not None and len(tableList) > 0:
# 循環遍歷列表中的表格
for table in tableList:
# 添加一個工作表
sheet = workbook.Worksheets.Add(f"sheet{sheetNumber}")
# 獲取某個表格的行數和列數
row = table.GetRowCount()
column = table.GetColumnCount()
# 循環遍歷行和列
for i in range(row):
for j in range(column):
# 從特定單元格獲取文本
text = table.GetText(i, j)
# 將文本寫入指定的單元格
sheet.Range[i + 1, j + 1].Value = text
# 自動調整列寬
sheet.AllocatedRange.AutoFitColumns()
sheetNumber += 1
# 保存到文件
workbook.SaveToFile("output/Tables/PDF表格到Excel文件.xlsx", ExcelVersion.Version2013)
workbook.Dispose()提取的表格:
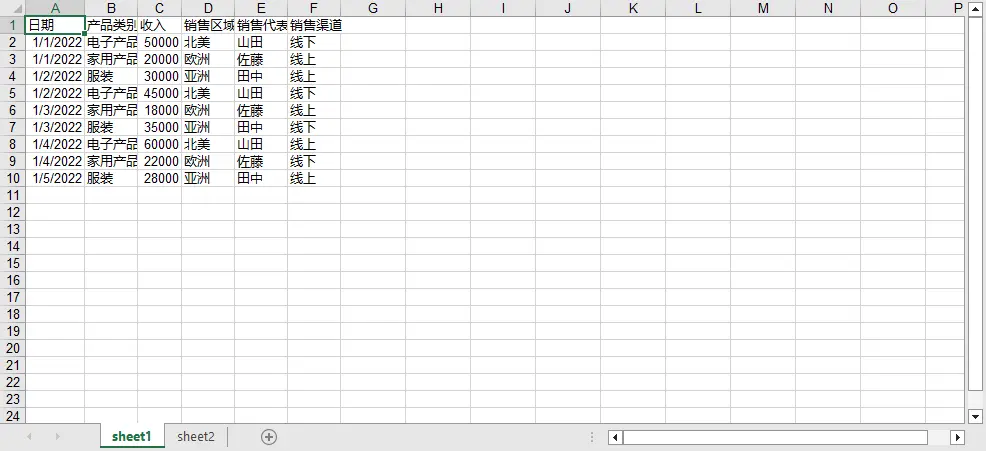
本文演示瞭如何使用Python提取PDF文檔中的表格數據,並將其保存到文本文件或Excel文件。
更多PDF文檔操作技巧請前往Spire.PDF for Python教程。
申請免費許可