

編者按:
11 月 18 日,2025 OceanBase 年度發佈會在北京舉行,現場發佈並開源了 OceanBase 首款 AI 原生混合搜索數據庫 seekdb(簡稱 seekdb )。
OceanBase 開源生態總經理封仲淹(花名:紀君祥,就是這個公眾號 “老紀的技術嘮嗑局” 裏的話事人 —— 老紀)會在這篇文章中,為大家介紹 OceanBase 開源 seekdb 的初衷。
在 2025 OceanBase 年度發佈會上,我們正式發佈並開源了 OceanBase 首款 AI 原生混合搜索數據庫 OceanBase seekdb(簡稱 seekdb)。
發佈之後,社區裏很多朋友都在問三個問題:
1. seekdb 為什麼要開源?
2. 它和 OceanBase 的定位有什麼區別?
3. 這個開源是否具有長期性?
我想借這篇文章系統性地回答這三個問題。但在此之前,有必要先回顧一個更根本的問題:OceanBase 為什麼要走開源這條路?

回望:OceanBase 的開源之旅
開源是戰略選擇,而非戰術動作
2021 年 6 月 OceanBase 宣佈開源時,外界最普遍的疑問是:一個商業上已經取得成功的數據庫產品,為什麼要選擇開源?
我們當時的判斷是:數據庫是基礎設施,基礎設施的發展必須與用户和生態共同演進。這不是一句空話。基礎設施軟件的特殊性在於,它的價值不僅取決於技術本身的先進性,更取決於生態的完整性和用户的信任度。而開源,是構建這種信任最直接、最有效的方式。
所以從開源的第一天,就把 OceanBase 開源作為一個公司級戰略。從資源投入來看,OceanBase 的開源項目投入是非常大的,從研發到運營,都是給到最好的資源配置。
從內核到完整解決方案
開源初期,我們只開放了內核和安裝器。用户很快給出了反饋:他們需要的是完整的解決方案,而非單一的技術組件。
這個反饋促使我們在開源後的半年內,相繼開放了 OMS、OCP、ODC 等核心工具。這些努力的目標只有一個:降低用户的使用門檻,讓更多人能夠真正用起來。
易用性的提升是一個持續性的工程。與數據庫內核的優化一樣,它沒有終點,只有不斷逼近用户期望的過程。
開源戰略的關鍵演進:代碼分支的統一
開源大約一年後,我們遇到了一個嚴峻的工程問題:社區版與企業版的代碼同步。
在 OceanBase 3.X 時代,兩個版本分屬不同的代碼分支,由不同的團隊維護。這種架構導致了大量的同步成本和潛在的功能差異。用户時常會遇到社區版已修復的問題在企業版中依然存在的情況。
到了 4.X 時代,我們做出了一個重要的技術決策:將社區版與企業版合併到同一個代碼分支,通過編譯宏來區分不同的發行版本。為了達到這個目標,我們投入了大量的研發資源對代碼進行模塊化改造,雖然投入的資源比較大,但它向社區傳遞了一個明確的信號——我們對開源的承諾是真實的、長期的。
四年成績:規模化驗證
截至目前,OceanBase 開源已經四年,部署量突破 10 萬套,企業用户超過 2000 家。從增長曲線來看,前年 6000 套,去年 3 萬套,今年突破 10 萬套——這是一個指數級的增長態勢。
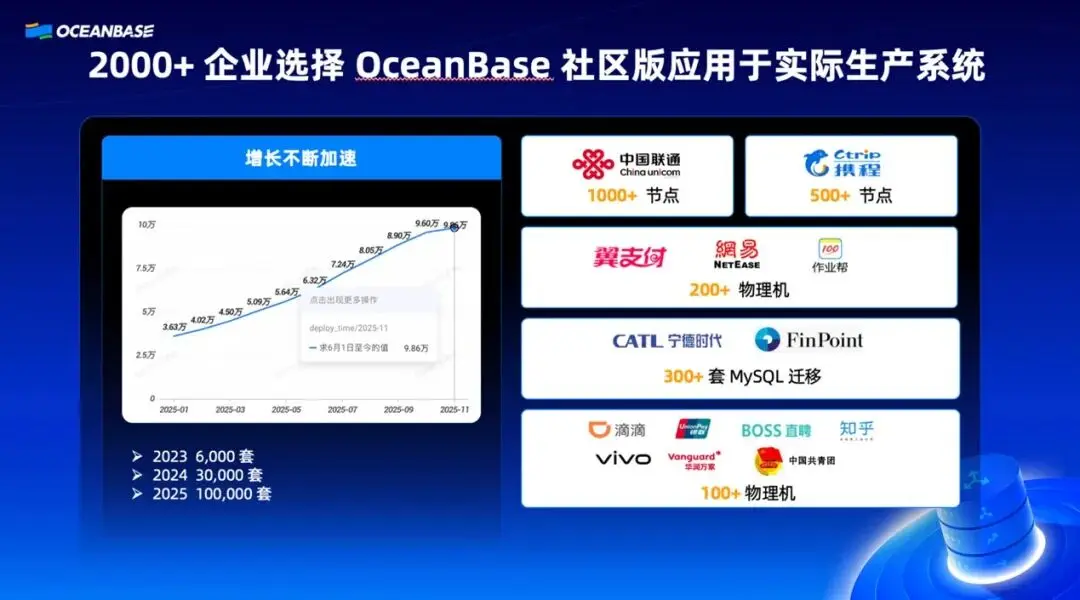
在國產數據庫領域,除 PostgreSQL 和 MySQL 生態外,OceanBase 社區的規模是最大的。這組數據説明,開源策略得到了市場的驗證。
但規模的增長並不意味着挑戰的消失。恰恰相反,最大的挑戰正在到來。

AI重構基礎設施的底層邏輯
GenAI:不是工具升級,而是基礎設施的代際更替
觀察一組數據:ChatGPT 發佈 17 個月後,月活用户突破 8 億,年搜索量達到谷歌的 5.5 倍。
這組數據的意義不在於某個產品的成功,而在於它揭示了一個趨勢:GenAI 正在成為新一代基礎設施的核心。這不是工具層面的迭代升級,而是整個技術棧的代際更替。
對於數據庫而言,這意味着什麼?意味着我們必須重新思考數據庫的核心價值主張。
AI應用:從概念驗證到規模落地
AI 的大規模落地,最終要通過應用來實現。只有應用才能將 AI 的能力轉化為端到端的生產力提升。
以 AI Coding 為例。使用過這類工具的開發者會有一個共同的感受:這是兩個完全不同的世界。這種體驗上的斷層,正是 AI 應用價值的直觀體現。
AI 時代對數據庫的三重挑戰
縱觀全球 AI 數據庫領域的技術領先者,會發現他們都在迴應三個共同的挑戰:數據的融合、模型的融合、對開發者的快速響應。
這三個方向,構成了 AI 時代數據庫演進的核心命題。OceanBase 的迴應,就是 seekdb。

OceanBase 應對 AI 時代數據挑戰的解法:seekdb
seekdb 的定位是 AI 原生混合搜索數據庫。理解這個定位,需要從三個維度展開。

數據融合:多模態存儲與混合搜索
需求的真實來源
數據融合的需求,源於業務場景的真實演變,而非技術團隊的自我想象。
我們與內部多個大規模業務團隊進行過深入交流——釘釘、飛豬等日活過億、數據量達 PB 級別的業務。這些業務處於技術應用的最前沿,他們遇到的問題往往預示着整個行業即將面臨的挑戰。
以飛豬為例,他們在向量搜索場景中遇到了一個典型問題:單純的向量相似度檢索無法滿足業務需求。他們需要對標量數據的每一行設置權重,需要實現複雜的 Trigger 邏輯來動態調整搜索策略。換言之,向量檢索必須與結構化數據的精確過濾深度結合,才能產出真正有業務價值的結果。
這不是個案。當 RAG 和搜索場景進入深水區,幾乎所有團隊都會遇到類似的問題。
從單一索引到混合檢索
傳統數據庫的設計假設是:不同類型的數據使用不同的索引,彼此相對獨立。全文索引處理文本,B+ 樹索引處理結構化數據,它們各司其職。
但 AI 時代的數據使用方式打破了這個假設。一個典型的 AI 應用查詢可能同時涉及:向量相似度匹配(語義理解)、全文檢索(關鍵詞匹配)、結構化過濾(時間、地點、類別等約束)、JSON 字段的嵌套查詢、GIS 空間計算。這些不同類型的檢索需要在一個查詢中協同工作,並且需要統一的相關性排序。
這就是混合搜索的本質:不是簡單地把多種索引堆疊在一起,而是讓它們在查詢層面實現真正的融合,產出統一的、業務可用的結果。
深水區的技術挑戰
混合搜索帶來的技術挑戰是多維度的。
首先是數據理解的深度。當底層數據的使用方式發生變化,編程接口也必須隨之演進。開發者需要新的表達方式來描述複雜的混合查詢意圖,這對 API 設計提出了很高的要求。
其次是性能優化的複雜度。不同類型的索引有不同的性能特徵,如何在混合查詢中找到最優的執行路徑,是一個複雜的優化問題。
最後是一致性保障。多模態數據的事務一致性如何保證?當向量索引和結構化索引需要同時更新時,如何確保數據的完整性?
這只是起點
今天我們看到的全文索引、向量索引、JSON、GIS 的混合檢索,只是這個演進過程的起點。
未來的數據融合會更深度、更靈活。我們可以預見的方向包括:更多模態數據的支持(音頻、視頻的原生理解)、更智能的查詢理解(自然語言到混合查詢的自動轉換)、更動態的索引策略(根據查詢模式自動優化)。
這是 AI 時代對數據庫的內在要求,也是 seekdb 持續演進的方向。
模型融合:AI Inside的技術路徑
行業趨勢的觀察
觀察 Oracle、Snowflake、Databricks 等企業的技術路線圖,會發現 AI Inside 正在成為數據庫基礎設施的重要方向。
所謂 AI Inside,核心理念是將 AI 能力內置到數據庫引擎中,而非作為外部服務調用。這意味着數據庫不再僅僅是數據的存儲和檢索系統,而是具備了理解數據、生成數據、推理數據的能力。
坦率地説,這個領域目前還處於早期探索階段。包括上述巨頭在內,都還在尋找最優的技術路徑。OceanBase 也是如此,seekdb 的 AI Inside 能力剛剛起步。
但方向的確定性是清晰的。這不是“要不要做”的問題,而是“如何做好”的問題。
用户視角的終極體驗
理解 AI Inside 的價值,最好的方式是從用户視角出發。
用户真正需要的體驗是什麼?是"Document in, Data out"——輸入自然語言描述的需求,直接獲得可用的數據結果。用户不應該需要理解底層的數據模型,不應該需要編寫複雜的查詢語句,不應該需要手動組合多個 API 調用。
舉一個具體的例子。假設用户想要查詢“過去一個月銷售額增長最快的產品類別,排除季節性因素的影響”。在傳統模式下,這個查詢需要:編寫 SQL 聚合查詢、實現季節性調整的統計算法、可能還需要調用外部的時間序列分析服務。
在 AI Inside 的理想狀態下,用户只需要用自然語言描述這個需求,數據庫內置的 AI 能力會自動完成:理解查詢意圖、生成執行計劃、調用內置的統計分析能力、返回最終結果。
這是三句話完成數據查詢的願景背後的技術含義。
AI Inside 的技術內涵
實現 AI Inside 需要在多個技術層面進行深度整合。
第一是自然語言理解與查詢生成。數據庫需要理解用户的自然語言輸入,並將其轉換為可執行的查詢計劃。這不是簡單的 Text-to-SQL,而是需要理解業務語境、處理模糊表達、支持多輪交互。
第二是內置的向量計算能力。向量是 AI 時代數據的核心表示形式。數據庫需要原生支持向量的存儲、索引、計算,而非依賴外部的向量數據庫。
第三是模型推理的本地化。將模型推理能力集成到數據庫引擎中,可以避免數據在數據庫和 AI 服務之間的頻繁傳輸,大幅降低延遲並提高安全性。
第四是智能化的查詢優化。利用 AI 能力來優化查詢執行計劃,根據數據分佈和查詢模式動態調整策略。
第五是數據增強與生成。數據庫具備對數據進行自動標註、增強、甚至生成的能力,為下游 AI 應用提供更高質量的數據。
seekdb的技術佈局
與模型的深度融合,是我們做 seekdb 的核心技術方向之一。
在當前版本中,seekdb 已經具備了基礎的 AI Inside 能力:原生的向量數據類型和索引、內置的 Embedding 生成、簡化的自然語言查詢接口。
在未來的路線圖中,我們會持續強化這個方向:更強大的自然語言理解、更多預置的 AI 函數、更深度的模型集成、更智能的自動優化。
這是一個需要長期投入的方向,但也是數據庫在 AI 時代必須具備的核心能力。競爭的焦點在於誰能更早、更好地實現它。
輕量化:重新定義開發者體驗
應用開發者決定數據庫的未來
回顧歷史,20 年前 LAMP 架構的出現,讓 MySQL 佔據了中國互聯網幾乎全部的數據庫市場份額。這個現象的本質是:應用開發者決定了數據庫的選型走向。
傳統場景下,DBA 選擇數據庫的核心標準是成熟穩定。但在AI時代,如果要贏得開發者,就必須滿足他們的核心訴求:更快的迭代速度、更低的使用門檻、更輕的資源佔用。
架構層面的徹底重構
OceanBase 長期以來的一個目標是實現 1C幾G 資源下的運行。過去 2 年,我們投入了大量努力,不斷給 OceanBase 瘦身,但這個目標始終沒有徹底實現。
seekdb 選擇了一條更徹底的路徑:完全拋開歷史包袱,大刀闊斧進行設計,我們裁掉了分佈式架構、多租户、RS 部分模塊(集羣管理)、分佈式事務等複雜組件,大幅精簡了代碼量。
最終的結果是:OceanBase 最小需要 2C6G 資源,seekdb 最小隻需要1C2G(實際可以把資源佔用配置成更小,大家不妨一試),支持秒級啓動和嵌入式部署。嵌入式能力將打開端雲一體的場景空間,這在 IoT 等領域有廣闊的應用前景。
開發體驗的重新設計
我們為 seekdb 設計了全新的 SDK,相比原有的 Python SDK 更加簡潔——三行代碼即可完成一個基礎應用。安裝流程也進行了全面簡化。
迭代速度的根本性提升
上述所有改進,最終指向一個核心目標:更快地響應開發者需求。
OceanBase 的分佈式版本承載了金融級的高可用、強一致性等要求。這些要求決定了它的架構複雜度。數據庫中最複雜的模塊是事務管理,分佈式事務更是複雜性的頂峯——它涉及 RPC、大事務恢復等一系列技術難題。
seekdb 裁掉這些模塊後,可以實現真正的輕裝迭代,快速響應開發者的反饋和需求。
開放協議與生態戰略
seekdb 採用 Apache 2.0 協議。相比其他開源協議,Apache 2.0 對所有用户更加友好,尤其有利於海外市場的拓展。生態建設是 seekdb 的核心戰略方向。
seekdb 與 OceanBase 的定位區分
seekdb 的定位可以用兩個關鍵詞概括:更 AI Native、更輕量。
具體的選型建議是:數據量大、需要分佈式能力的場景,推薦 OceanBase;數據量輕量或者更偏 AI 類需求的場景,推薦 seekdb。seekdb 會在 AI 方向上保持更快的迭代節奏,更快地滿足這一領域的用户需求。

seekdb 之外:構建完整的 AI 開發者支持體系
AI 應用的三大熱點方向
當前 AI 領域最活躍的三個方向是 Agent、RAG 和 Memory。幾乎所有主要廠商都在這三個方向上進行佈局。對於 OceanBase 而言,除了 seekdb 本身,我們也在這些領域進行了系統性的投入。
PowerRAG:站在巨人肩膀上的創新
PowerRAG 是基於 RAGFlow 的二次開發項目。PowerRAG 的價值在於在此基礎上進行企業級的增強。
主要的增強方向包括:更好的企業級適配(高可用、權限管理等特性)、豐富的組件和插件支持(如 DeepSeek OCR, MinerU),這些能力在企業級 RAG 場景中非常關鍵。
PowerMem:讓 AI 應用更省 Token
PowerMem 是我們同期開源的 Memory 項目。它的核心價值是顯著降低 AI 應用的Token消耗——相比OpenAI的Memory方案,可以節省 96% 的 Token。
這個效果是如何實現的?主要有以下幾個技術手段:智能記憶管理、分層記憶架構、基於 seekdb 內核的混合檢索、Prompt 層面的深度優化、多模態支持。此外,我們也在探索 Graph 能力,以支持 AI Inside、千人千面等新型業務場景。
seekdb Roadmap:開發者與生態為核心
相比 OceanBase,seekdb 會更聚焦於開發者和生態。我們將積極與上下游生態夥伴合作,尤其期望能與 AI 開源項目、國內頭部開源項目和全球頂級開源項目建立深度合作。
社區很多朋友已經瞭解,今年我已經在海外工作過一段時間,明年預計會有更多時間在全球化上。這不意味着國內支持的減少——社區團隊會一如既往地服務好大家。同時,我們會投入更多資源去拓展和打通全球化開發者生態,讓 OceanBase 更開發者友好。
我一直有一個判斷:能夠走出國門的中國數據庫,必然是經過嚴苛市場考驗的優秀產品。在中國這樣競爭激烈的市場環境中存活並發展起來的數據庫,到全球市場往往更具有顯著的競爭優勢。

未來:seekdb的成長空間
今天的 seekdb,可以理解為 OceanBase 生態中的一個新生成員。OceanBase 積累了 15 年,已經具備了相當的規模和影響力。seekdb 則剛剛起步。

但我們對未來的判斷是:seekdb 的成長空間將充滿想象。
這個判斷基於兩個基本事實。第一,在數據庫市場中,集中數據庫市場還是很大的,這將幫助我們拓展一個更大的市場空間的可能性。第二,AI 是下一個時代的分水嶺,而 seekdb 繼承了 OceanBase 的可靠性、穩定性和強一致的 15 年的基礎能力,在 AI 這個方向上具有先天優勢。
未來,seekdb 將在 AI 的賽道上不斷快速迭代,然後不斷把沉澱的 AI 能力反哺給 OceanBase,更好的滿足更多企業級客户在關鍵業務負載、實時分析和 AI 搜索上的多元需求。

結語
回到開篇的三個問題。
seekdb 為什麼開源?因為開源是 OceanBase 的核心戰略,數據庫作為基礎設施必須與用户和生態共同成長。
seekdb 與 OceanBase 的定位有何區別?seekdb 更 AI Native、更輕量,更面向 AI 時代的開發者;OceanBase 則主要通過一體化的能力,全方位滿足企業級客户在關鍵業務負載、數據實時分析和 AI 搜索上的多元需求。
seekdb 的開源是否具有長期性?是的,它是戰略級的投入。正如 OceanBase 開源四年後依然在持續成長,seekdb 也將獲得長期、持續的投入。
開源不是終點,而是起點。seekdb 的開源,是 OceanBase 面向 AI 時代的戰略選擇。我們期待與社區一起,見證 seekdb 從起步走向成熟。