

作者:周強,卡牌遊戲公司高級開發工程師
向量數據庫的獨特優勢與選型經驗
向量數據庫 是專門為存儲、索引和查詢高維向量數據而設計的數據庫系統,能夠高效處理由機器學習模型生成的嵌入向量,並支持基於相似性的快速檢索。
相較於#傳統數據庫,向量數據庫在多方面顯示出其獨有的特性,可在前者涉及的領域之外發揮優勢。如圖1所示,傳統數據庫主要用於存儲結構化數據,基於精準匹配進行查詢,適用於業務數據管理,而向量數據庫用於存儲向量數據,基於相似性查詢搜索,主要適用於 AI 和#機器學習 應用場景。
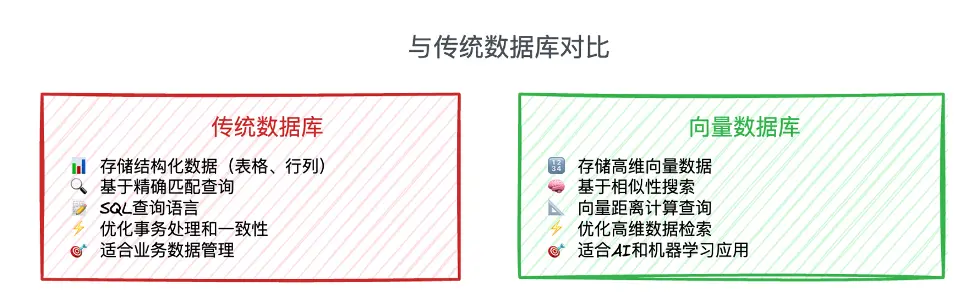
圖1 傳統數據庫與向量數據庫對比
目前,向量數據庫被廣泛應用於智能檢索業務。非結構化數據如文本、圖片、視頻、音頻等,通過深度學習神經網絡進行向量嵌入,並存儲到向量數據庫中,以便業務方基於向量數據庫進行語義相似度搜索,如圖2所示。
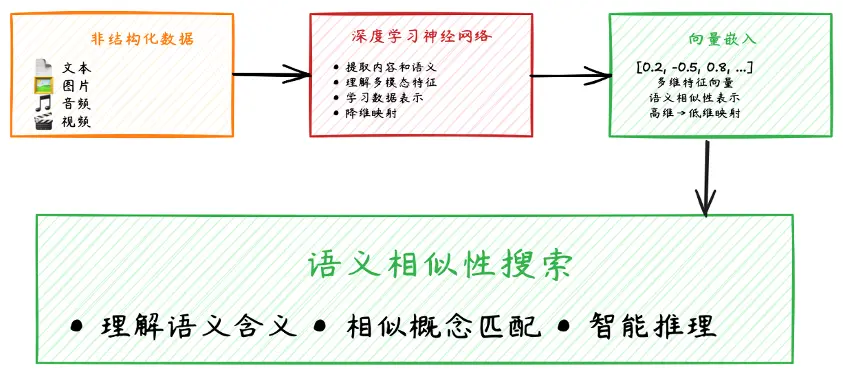
圖2 智能檢索業務流程
對應到真實的業務場景,向量數據庫的作用分別是:
- 在智能搜索引擎中,用於理解用户意圖,返回語義相關結果。
- 在推薦系統中,基於內容相似性進行個性化推薦。
- 在問答系統中,從知識庫中找到最相關的答案。
- 在內容檢索時,進行跨模態搜索(文本搜圖片、圖片搜文本等)。
- 在數據分析場景中,用於發現數據間的隱藏關聯和模式。
在眾多向量數據庫中,我們選擇 #OceanBase 支撐智能業務場景,原因主要分為以下四個方面。
1.一體化架構:保障一致性,運維成本低。
得益於OceanBase的一體化架構,可以使用同一套數據庫存儲結構化數據和向量數據,消除兩庫同步和一致性難題。同時,其#事務ACID 直接覆蓋向量表,保證了數據的強一致性。此外,OceanBase還擁有統一的 SQL 接口和管理工具,可以降低我們的運維成本。
2.原生向量能力:業務性能有保障。
- 原生向量列類型 (VECTOR),數據庫內核級支持。
- HNSW / IVFFlat 索引算法,優化檢索性。
- 毫秒級 Top-K 檢索,極速相似性搜索。
3.分佈式彈性擴展:支持超大規模數據量。
支持分佈式架構和數據分片,處理能力遠超單機數據庫,特別是在處理數百億向量或數 TB 數據時性能表現優秀。
4.生態快速集成:兼容 MySQL 技術棧,開發接入成本低。
由於OceanBase支持 MySQL 協議,我們可以通過 Python 或 Java 的 SDK 訪問。降低了接入成本。同時,由於OceanBase生態豐富,適配各種 AI 應用開發框架如 LlamaIndex、LangChain、 Dify 等,使用起來更加便捷。
綜上所述,我們使用 OceanBase 在開發層面基本零學習成本,可以直接適配開發框架,方便易用。目前,我們已在多個場景應用OceanBase,下面以智能客服業務和UGC社區推薦系統為例,闡述應用經驗。
智能客服業務實現毫秒級檢索性能,效率提升 300%
在詳細介紹智能客服業務前,我們先了解傳統客服目前存在的問題,以感知智能客服系統中#向量檢索 的關鍵作用。
對於傳統客服,相信大家在生活中多少使用過,其典型的問題是響應慢,比如需要排隊等待,高峯期的等待時間更久。在服務過程中由於對產品信息更新不及時或每位客服人員對產品信息的理解不一,還會出現回答標準不統一的問題,甚至一些客服的情緒也會影響服務質量。
在引入 AI 客服後,上述傳統客服的問題可以得到基本解決。首先,#智能客服 可以全天候響應,無需客户等待,且秒級回覆,能夠提升用户滿意度。其次,智能客服會分析用户行為,並提供個性化服務,對於客户不滿意的回答可以持續學習進行自我優化,不斷提升服務質量。
智能客服業務流程及關鍵技術
如圖3所示,當智能客服收到客户消息後,首先進行智能總結,從消息中提取核心意圖,然後到知識庫中進行向量匹配,查詢與客户消息最相似的話題。其次,根據話題選擇對應標籤並進行路由匹配,開始多源數據查詢。在查詢過程中會出現多種情況:如果是報錯或#Bug 相關,需要在 Bug 表中查詢故障記錄和修復情況;如果是遊戲玩法相關,需要查詢遊戲知識庫;如果是工單類,需要查詢歷史工單。總而言之,通過多源數據查詢與信息整合,生成個性化的回覆或專業、準確的解決方案。
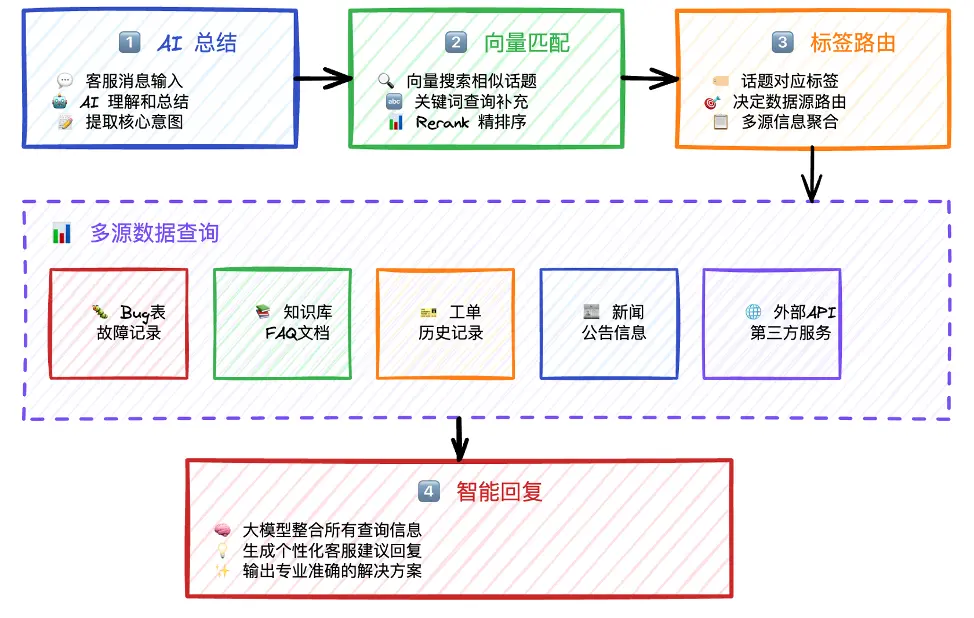
圖3 智能客服系統工作流程
在這套智能客服系統工作流程中,最關鍵的步驟是向量檢索,也就是搜索到與問題最相似的話題。其他技術細節包括關鍵字查詢、Rerank 重排序、標籤路由系統、LLM 智能生成等,是相對複雜的步驟。
- 向量檢索:基於語義相似度快速匹配相關話題,提高召回率和準確性。
- 關鍵詞查詢:補充精確匹配,處理專業術語和特定名詞。
- Rerank 重排序:對初步結果進行精確排序,確保最相關內容優先。
- 標籤路由系統:根據話題類型智能路由到對應數據源,實現精準查詢。
- LLM 智能生成:整合多源信息,生成上下文相關的專業客服回覆。
那麼,如何保證智能客服給出的信息是有效、準確的呢?
關鍵在於向量檢索質量,如果檢索的準確度不高,則無法精準匹配用户的業務意圖。因此 嵌入質量(Embedding)決定“能檢到什麼”——是檢索質量的上限;向量數據庫的檢索效果(ANN 索引、召回率)決定“實際能不能撈上來”——是檢索質量的下限, 比如下面兩種索引呈乘法關係,更低的一方就是瓶頸所在。
- 支持HNSW/HNSW_SQ/HNSW_BQ 索引,索引列最大維度為 4096。
- 支持IVF 索引/IVF_SQ 索引/IVF_PQ 索引,索引列最大維度為 4096。
因為嵌入向量通常使用開源模型,比如常見的開源中文嵌入模型 Qwen3-Embedding-8BBGE-large-zh-v1.5,所以我們沒有可優化的方向,轉而優化向量數據庫檢索,以更好地匹配實際數據。
向量數據庫檢索優化
1.數據表設計
如下是一個具體的知識庫數據表設計,可以看到其中包含了 Embedding 模型、問題,放在一張表中。關於向量和索引算法,使用了768維的向量、HNSW 索引算法和餘弦相似計算索引。
CREATE TABLE `data_kf_faq` (
`id` varchar(36) NOT NULL COMMENT '主鍵ID,UUID格式,唯一標識一條FAQ記錄',
`project_id` varchar(100) DEFAULT NULL COMMENT '項目ID,用於區分不同項目的數據歸屬',
`kid` varchar(100) DEFAULT NULL COMMENT '知識項ID(Knowledge ID)',
`question` text DEFAULT NULL COMMENT 'FAQ問題文本',
`embedding` VECTOR(768) DEFAULT NULL COMMENT '問題的向量表示,用於語義搜索(768維向量)',
PRIMARY KEY (`id`) COMMENT '主鍵索引,保證記錄唯一性',
KEY `idx_kid` (`kid`) COMMENT 'kid字段普通索引,加快按知識項ID查詢速度',
KEY `idx_proj_kid` (`project_id`, `kid`) COMMENT '項目ID+知識項ID聯合索引,加快多條件精確查詢',
VECTOR KEY `idx_embedding_faq` (`embedding`)
WITH (DISTANCE = COSINE, TYPE = HNSW, LIB=VSAG) COMMENT '向量索引,使用HNSW算法,餘弦相似度計算,支持語義近似搜索'
)2.使用 jieba 進行分詞,提取業務關鍵詞
關鍵詞表分為主表和附表,主要用於存儲知識庫的 Embedding 模型,以及問題關鍵詞的分解,包括業務的特殊關鍵詞。主表和附表結合進行查詢。如果向量查詢效果比較好,就可以省略關鍵詞查詢。
CREATE TABLE `data_kf_faq_kw` (
`faq_id` CHAR(36) NOT NULL COMMENT 'FAQ主表的ID(UUID),關聯data_kf_faq.id',
`kw` VARCHAR(100) NOT NULL COMMENT '關鍵詞(單個詞項),用於分詞檢索',
`project_id` BIGINT NOT NULL COMMENT '項目ID,用於區分不同項目數據',
PRIMARY KEY(`faq_id`, `kw`) COMMENT '聯合主鍵,保證同一FAQ下關鍵詞不重複',
INDEX `idx_kw_proj` (`kw`, `project_id`, `faq_id`) COMMENT '按關鍵詞+項目ID快速查詢FAQ列表'
) COMMENT='FAQ關鍵詞表,用於按關鍵詞快速定位FAQ記錄';3.檢索步驟及優化
檢索分為五步,涉及兩個優化。: 第一步:文本向量化,命令如下。
embedding = vectorize_text(question)第二步:向量相似度搜索。當文本向量化完成後,需要在向量數據庫進行檢索,撈取部分數據,根據數據複雜度進行搜索。下文是一條直接在 OceanBase 中進行查詢的 SQL。
vector_results = database.vector_search(
project_id=project_id,
embedding=embedding,
top_k=20
)
SELECT id, kid, project_id, question, keywords,
COSINE_DISTANCE(embedding, %s) as distance,
(1.0 - COSINE_DISTANCE(embedding, %s)) as similarity
FROM {table_name}
WHERE project_id = %s
ORDER BY distance ASC
LIMIT %s第三步:關鍵詞搜索補充 。關鍵詞補充涉及向量查詢和關鍵詞查詢。關鍵詞指遊戲中的專有關鍵詞,AI 可能難以理解,需要單獨作為分詞。
keyword_results = database.search_by_keywords(project_id, keywords)第四步:對關鍵字查詢的候選結果進行合併去重。
seen_ids = set()
result = []
for item in vector_results + keyword_results:
if item['id'] not in seen_ids:
seen_ids.add(item['id'])
result.append(item)第五步:智能重排序。前面幾步完成後,我們會得到一個最佳匹配結果,並根據標籤路由查詢數據源,交給大模型進行個性化恢復。
ranked_results = rerank_question(question, result)
# 按分數降序排序
sorted_ranked_results = sorted(ranked_results, key=lambda x:x.get("rerank_score", 0), reverse=True)
# 返回最佳匹配結果
sorted_ranked_results[0]在真實業務環境下實施上述檢索步驟時,還涉及兩個優化點。
一是智能候選數量控制。如果我們判斷客户問題是複雜問題,就需要多取一些數據進行比對;如果是簡單問題,則不需要取太多數據。
# 優化:動態調整
def adaptive_search_size(project_id, question_complexity):
if question_complexity > 0.8: # 複雜問題
return {"vector_k": 20, "keyword_limit": 30}
else: # 簡單問題
return {"vector_k": 10, "keyword_limit": 10}二是早停機制。如果在第二步即向量相似度搜索,匹配度已經很高,則不需要進行後續的關鍵字搜索和重排序,可以直接獲取最佳匹配結果。
# 優化:高置信度早停
if vector_results and vector_results[0]['similarity'] > 0.95:
logger.info("高置信度匹配,跳過關鍵詞搜索和重排序")
return format_high_confidence_result(vector_results[0])使用 OceanBase 向量數據庫的主要價值
在智能客服業務中,我們使用 OceanBase 後,在數據架構、檢索性能、運維等方面獲得了較大收益:
- 由於向量數據和結構化數據統一存儲,降低了 50% 運維成本。
- HNSW 優化後,實現了毫秒級檢索性能,客服效率提升 300%。
- 多節點快速擴容,實現99.99% 的可用性。
- OceanBase兼容 MySQL 協議,我們的運維和開發人員幾乎零學習成本投入就實現了快速接入,開發效率非常高。
UGC 社區智能推薦系統,延遲降低75%
架構對比:傳統推薦系統VS一體化智能推薦系統
如圖4 所示,傳統推薦系統架構的運行鏈路是:當收到用户請求推薦時,API 服務從 MySQL 中查詢並獲取用户信息,再到向量數據庫中撈取相似數據,然後回到 MySQL 補充內容詳情。此處查詢數據後,可能還要緩存到 Redis 中,最後才能將結果返回給用户。整個流程共計4次網絡往返,鏈路長、延遲高、複雜度高。由於涉及多個業務,很難保證數據一致性。
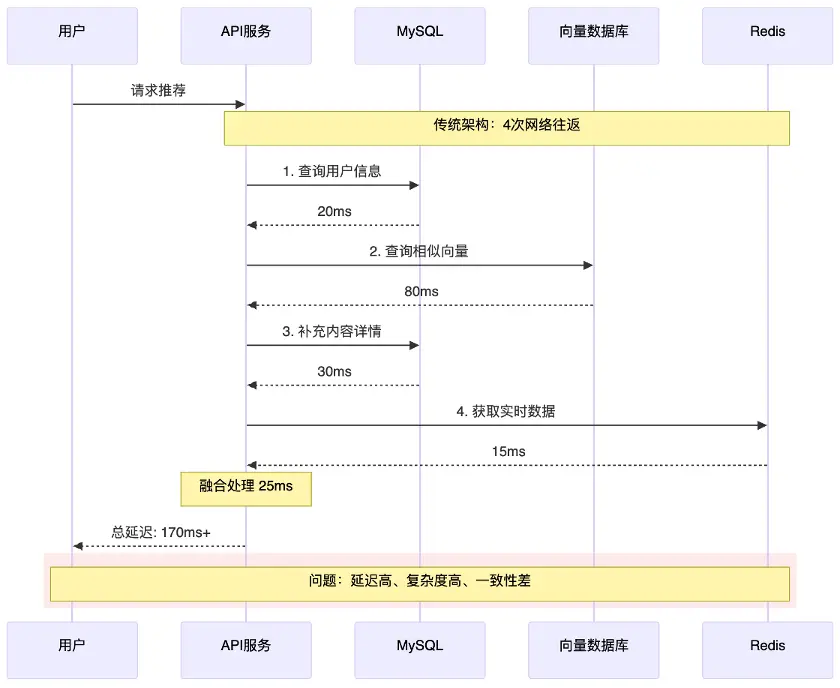
圖4 傳統推薦系統架構
我們接入OceanBase 後,通過一套數據庫就可以完成整個智能推薦系統的所有查詢需求(見圖5)。使用 OceanBase 只需進行一次查詢,就可以達到傳統推薦系統鏈路中 MySQL 查詢、向量數據庫查詢,Redis 緩存等步驟的執行結果。換句話説,我們通過一套 OceanBase 替換多種數據庫,獲得了更低的網絡延遲、更簡單的架構,以及數據強一致性。
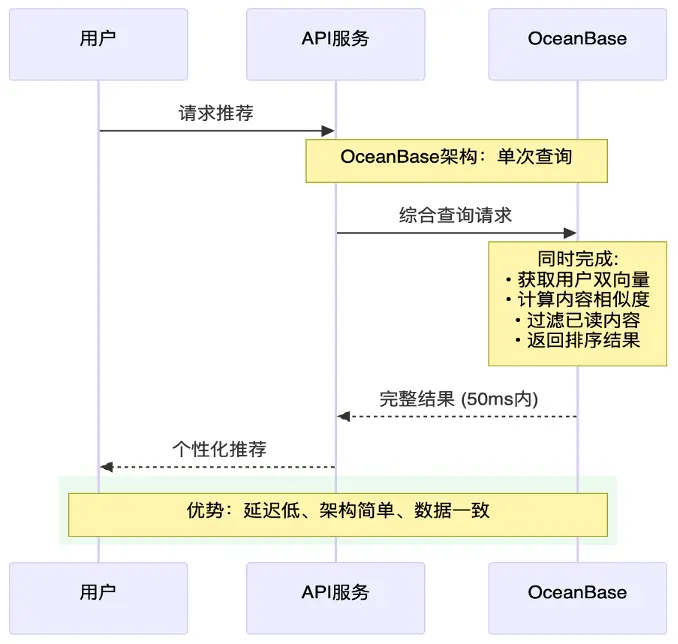
圖5 使用OceanBase的智能推薦系統架構
圖6是基於 OceanBase 實現的 UGC 社區智能推薦系統的詳細架構,可以看到 OceanBase 在統一存儲的同時實現了向量存儲、關係數據存儲。由於OceanBase高度兼容 MySQL 語法和協議,使原本基於 MySQL 的 UGC 社區推薦系統可以平滑遷移到 OceanBase。只需DBA 實現一些兼容性內容,不涉及開發改造,同時,開發側無需額外操作就得到了事務一致性的保證。
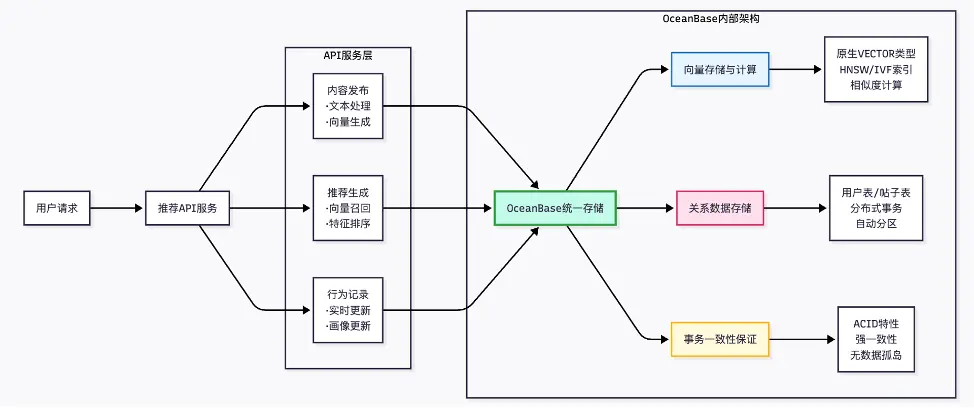
圖6 基於 OceanBase 的 UGC 社區智能推薦系統架構
除了系統架構、開發改造層面的優勢外,基於 OceanBase 的智能推薦系統也帶來了三個關鍵技術優勢。
1.原生向量類型支持。
OceanBase 原生支持向量類型,例如,可以直接將帖子內容 Embedding 後存儲在帖子表即可,不需要單獨再引入一套向量數據庫。
CREATE TABLE posts (
post_id BIGINT PRIMARY KEY,
title VARCHAR(255),
content TEXT,
-- 原生向量類型,無需額外存儲系統
content_vector VECTOR(768),
view_count INT DEFAULT 0,
-- 向量索引,查詢性能媲美專業向量數據庫
VECTOR INDEX idx_content_vec(content_vector) WITH (distance=cosine, type=hnsw)
);2.事務一致性保證。
在同一個事務中,OceanBase可以同時更新結構化數據和向量數據,保證了事務一致性。而如果是使用傳統數據庫,則需要再引入一套向量數據庫,會涉及兩個庫之間的數據同步問題,無法保證事務一致性。
-- 在同一個事務中更新結構化數據和向量數據
BEGIN;
UPDATE posts SET view_count = view_count + 1 WHERE post_id = ?;
UPDATE users SET short_term_vector = ? WHERE user_id = ?;
COMMIT;3.一次查詢,多路召回。
利用 OceanBase 的向量計算能力,可以用一條 SQL 完成所有的複雜推薦邏輯,包含短期向量和長期向量的融合、已看過內容的過濾、時間篩選等,不需要在業務側執行復雜處理步驟,對業務開發很友好。
-- 利用OceanBase的向量計算能力,一次SQL完成複雜推薦邏輯
WITH user_vectors AS (
SELECT short_term_vector, long_term_vector
FROM users WHERE user_id = ?
)
SELECT
p.post_id, p.title,
-- 融合雙向量得分
0.7 * COSINE_SIMILARITY(p.content_vector, u.short_term_vector) +
0.3 * COSINE_SIMILARITY(p.content_vector, u.long_term_vector) AS score
FROM posts p, user_vectors u
WHERE p.created_at > DATE_SUB(NOW(), INTERVAL 7 DAY)
-- 過濾已看過內容
AND NOT EXISTS (SELECT 1 FROM user_actions WHERE user_id = ? AND post_id = p.post_id)
ORDER BY score DESC LIMIT 50;用户興趣建模的雙向量的創新
UGC 社區智能推薦系統實現了基於#用户興趣 建模的雙向量的創新,用於捕捉即時興趣的短期向量和維護用户穩定偏好的長期向量。每個玩家都可以有兩個向量表示短期和長期的興趣愛好:長期代表固定的興趣愛好;短期代表當下的關注點。將兩個向量的查詢結果基於一定權重分配進行動態融合後,即可生成向量化#個性化推薦。
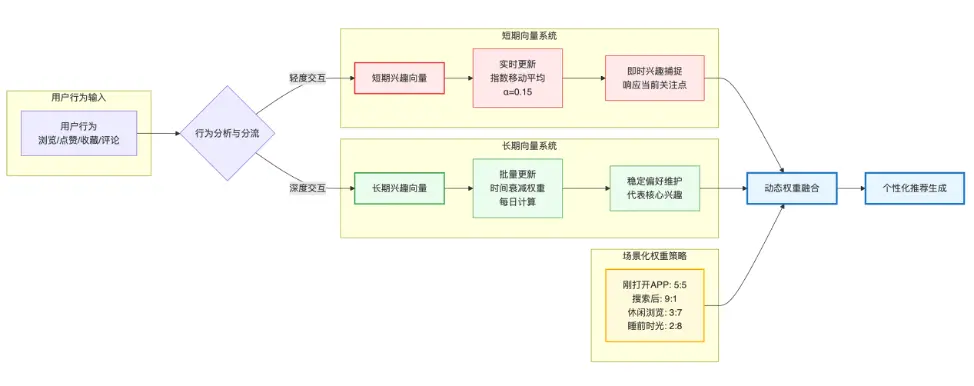
圖7 基於用户興趣建模的雙向量創新
短期向量:捕捉即時興趣
短期向量用於捕捉用户即時興趣,所以當用户進行查詢動作後,系統會實時更新該用户數據。短期向量的數據存儲特點是響應快,可以捕捉用户最關注的核心點。
def update_short_term_vector(user_id, post_vector, action_type):
# 行為權重:不同行為反映不同興趣強度
weights = {'view': 0.1, 'like': 0.3, 'collect': 0.5}
# 指數移動平均:新興趣逐漸替代舊興趣
new_vector = 0.85 * current_vector + 0.15 * weights[action_type] * post_vector
# 實時更新,立即生效
execute_sql("UPDATE users SET short_term_vector = ? WHERE user_id = ?",
[new_vector, user_id])長期向量:維護穩定偏好
長期向量主要用於維護用户核心的興趣愛好,一般每天批量計算更新一次,同時計算維度加入了該用户30天內的行為權重。
-- 每日批量計算長期興趣
UPDATE users u SET long_term_vector = (
SELECT VECTOR_NORMALIZE(
VECTOR_SUM(
-- 時間衰減:近期行為權重更高
VECTOR_MULTIPLY(p.content_vector,
EXP(-TIMESTAMPDIFF(DAY, ua.action_time, NOW()) / 30.0) *
-- 行為權重:深度互動權重更高
CASE ua.action_type WHEN 3 THEN 0.5 ELSE 0.1 END
)
)
)
FROM user_actions ua
JOIN posts p ON ua.post_id = p.post_id
WHERE ua.user_id = u.user_id
AND ua.action_time > DATE_SUB(NOW(), INTERVAL 30 DAY)
);雙向量的好處
我們以一個例子來説明雙向量的好處。有一個 RPG 遊戲玩家小王,平時主要關注#劇情向的遊戲,突然有一天顯卡壞了,他需要去#電商平台 收顯卡,此時如果只有一個向量表示,他的定位可能就變成了顯卡硬件發燒友,但實際上小王買完顯卡後可能又去#玩遊戲 了。因此,基於用户建模的雙向量既保留了小王長期穩定的 RPG 遊戲數據,又保留了短期的即時興趣數據,對用户畫像的判定更準確。
一體化智能推薦系統的收益總結
如圖8所示,我們在 UGC 社區智能推薦系統使用 OceanBase 後:推薦延遲從之前的200ms降低至50ms;存儲空間節省了40%;運維複雜度由之前的運維4套系統到如今的運維1套系統,簡化75%、此外,完全解決了使用傳統架構時系統偶發數據不一致的問題。
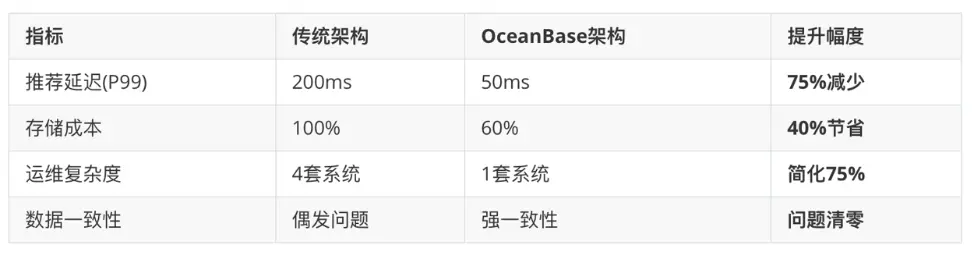
圖8 UGC 社區智能推薦系統使用 OceanBase 的收益
以上就是我們公司對向量數據庫的選型及應用經驗,雖然公司業務圍繞遊戲,但客服與推薦系統場景較為普遍,希望我們的經驗能給大家帶來參考價值。
最後為大家推薦這個 OceanBase 開源負責人老紀的公眾號「老紀的技術嘮嗑局」,會持續更新和 #數據庫、#AI、#技術架構 相關的各種技術內容。歡迎感興趣的朋友們關注!
「老紀的技術嘮嗑局」不僅希望能持續給大家帶來有價值的技術分享,也希望能和大家一起為開源社區貢獻一份力量。如果你對 OceanBase 開源社區認可,點亮一顆小星星✨吧!你的每一個Star,都是我們努力的動力。


