

一. 寫作原因
遇到了 3 個事情,讓我想到要好好梳理一下 session id 的相關知識。
- 發現一個事務中查到的 OceanBase 的 session id 會發生變化(其實也算沒有變,原因下文會説)。
- 查到的 session id 在使用 kill 命令時候報錯找不到該 ID(不是因為 ID 真的不存在或者變化了)。
- 通過不同的查詢方式,查到很多和 session id 有關的 ID 值,沒法在腦中組織成知識網絡,不理解部分 ID 為什麼這麼設計。
session id 概述
session id 是用於描述客户端和數據庫的訪問鏈路的,OceanBase 數據庫架構中使用了 ODP(一般也稱為proxy,下文也用 proxy 指代),所以客户端對數據庫的訪問鏈路被拆成了兩段,第一段是客户端和 ODP 之間的連接(Client session,下文用 C 連接指代),第二段是 ODP 和 OBServer 之間的連接(Server session,下文多用 S 連接指代)。
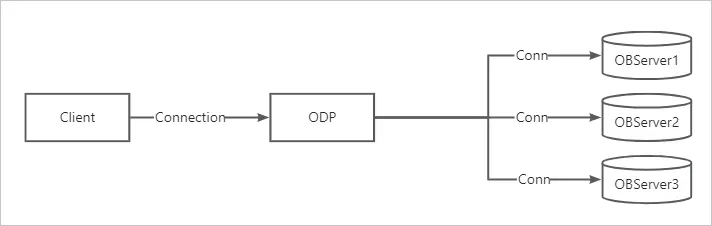
一個客户端的連接,會使用一個 C 連接,然後對應多個 S 連接,C 連接和 S 連接的對應關係是 1 : N。值得注意的是,在執行一條 SQL 的時候,同一時間,只有一個 S 連接在服務(先不考慮遠程計劃或分佈式計劃帶來的二次路由)。
那麼問題來了:用於定義 2 種連接的 Session id,卻可以在官方文檔中找到 10 種名詞定義:
- ID
- session id
- client session id
- server session id
- connection id
- proxy_sessid
- cs_id
- server_sessid
- ss_id
- MASTER_SESSID
這是為什麼呢?
二. 寫作思路
開始研究這個主題的時候,是想要寫一個 Session ID 的前世今生的,但在翻文檔、找人聊、自己測之後,發現問題比以前更多了……
在幾次草稿都被自己否了以後,我悟了 —— 追求細節和完備最終導致我無法搞定文章,一個理解框架才是我們需要的東西。通過這個框架可以串聯起知識,然後遇到問題之後可以通過框架解決問題,這才是最有價值的。
三. session id 介紹
從一張圖開始:
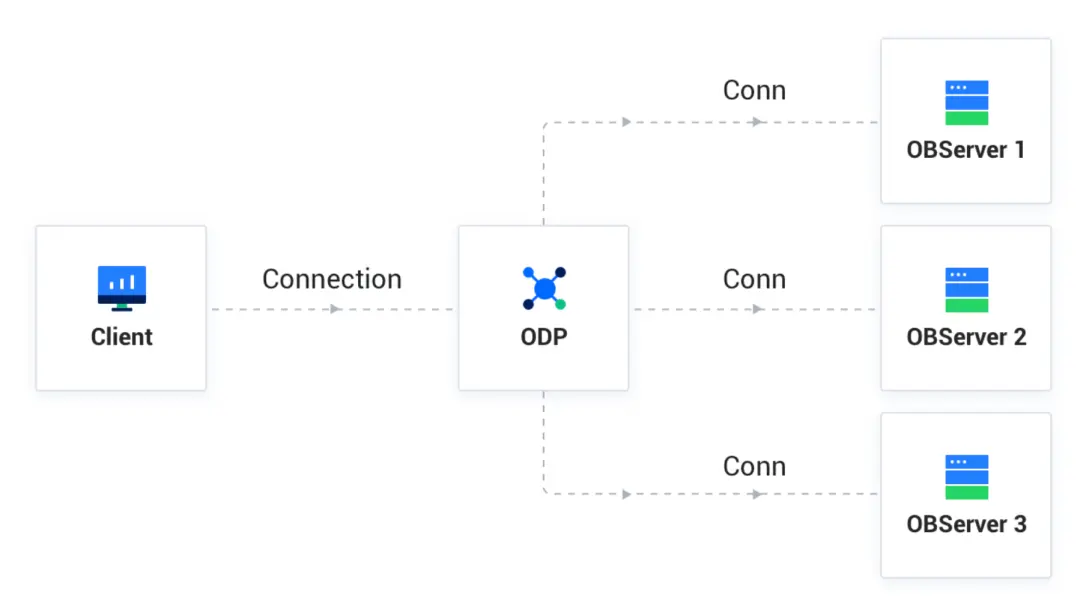
圖中直觀的展示了客户端(client)和數據庫(ODP + OBServer)之間的鏈路關係。
為了方便下面的描述,我們把圖中的 4 根連接線分別命名,client 和 ODP 之間的鏈路叫 C-1,ODP 分別連接 OBServer 的 3 個鏈路叫 S-1、S-2、S-3(下面沒有特殊説明,都不考慮直連的情況)。
那麼有一些事情需要大家能想清楚(可能會有點兒繞):
- C-1、S-1、S-2、S-3 都是獨立的連接,背後會對應各自的 ID。而且一個連接兩端的組件(比如 S-1 兩端分別對應了 ODP 和 OBServer)可能對同個連接 S-1,給予不同的 ID。不同組件對 S-1 不同的 ID 編號這個事情,這麼設計有很多種可能。大家能想到幾種呢?
- 一整個會話(包含 C-1、S-1、S-2、S-3),只要不斷開,不結束,都是被獨佔的。其他的會話不可能共用裏面的任何一條鏈路。
- 單一個 SQL 的執行,只會使用一種組合,C-1 + S-X(這裏的 S-X 就是指 3 條 S 中的其中一條)。也就是針對一個 SQL 只有一個 S 連接參與服務(這裏不考慮二次路由)。
- 同一個事務的不同 SQL,會使用到不同的連接組合,這也是 ODP 的事務內路由的功能,這樣可以讓更多的SQL 使用本地執行計劃。
- 查看會話的視圖,習慣是一個會話是展示一行(因為在同一時刻,一個會話中只能執行一條 SQL)。其實 OceanBase 這裏有 2 種展示模式,show processlist 是一個會話 C 連接的維度,show full processlist 就是展示 S 連接的維度(會有多條)。可以想見同一個會話中,最多也只有一條在工作,其他的都是 sleep。
- 一個客户端第一次連接上數據庫,返回連接成功,説明 C-1 + S-1 的鏈路已經建立了,這個時候其實 S-2 和 S-3 還不存在,直到 ODP 需要連接的時候才會建立連接。
回到上面很多的名詞問題,這裏給出一個初步的解釋:
- 連接的類型是隻有 2 種,C 連接和 S 連接。
-
描述他們的不同編碼(小編理解這裏的 “編碼” 就是序號或者 ID 的含義) 一共 4 種,其他的名詞都是這 4 種的其中一種的指代。
- cs_id:這是由 proxy 生成的用於描述 C 連接的編碼,也是我們最常見的 session id 表述之一,show processlist 裏的 ID 列通常指代的就是這個 cs_id(注意是通常)。
- proxy_sessid:這也是由 proxy 生成的用於描述 C 連接的編碼,編碼比較長一些,在 proxy 和 OBServer 建立連接的時候,proxy 會告訴 OBServer,我上游服務的 C 連接的編碼就是這個。(注意 proxy 沒有告訴下游編碼是 cs_id,而是 proxy_sessid 。簡單的記憶就是,同樣一個 C 連接,對客户端 proxy 使用 cs_id ,對 OBServer 端則使用 proxy_sessid。挺住,別暈。
- server_sessid:由 OBServer 生成的用於描述 S 連接的編碼,在整個 OceanBase 集羣內是唯一的,也是 OBServer 中用的很多的編碼,比如 OB_LOCKS 視圖中用的就是這個。
- ss_id:由 proxy 生成的用於描述 S 連接的編碼,用到這個編碼的地方非常少,瞭解即可。
總結:proxy 生成了 3 個編碼,包括 cs_id、proxy_sessid、ss_id。其中 cs_id 和 ss_id 偏向於 proxy 內部使用,proxy_sessid 會傳遞給 OBServer,在 OBServer 的日誌中可能會有查詢的需求。OBServer 生成了一個編碼,即 server_sessid,用於定義 S 連接的 session id。如果是直連的情況,則只有 server_sessid,因為其他 3 個都是在 proxy 體系下使用的。
如果你能繞清楚,那就繼續來到下一關,先和這些 session 相關名詞混個臉熟:
- ID:在不同的查詢場景下,這個列有時顯示的是 cs_id 值,有時是 server_sessid 值。
- session id:泛指 session 的編碼,出現在 OceanBase 官方文檔各處,一般查表中沒有這個字段。
- client session id:一種新版本的 cs_id,後面會介紹為什麼需要重新設計 cs_id。有時也指代 C 連接。
- server session id:就是 server_sessid ,有時也指代 S 連接。
- connection id:MySQL 租户使用函數 connection_id() 查詢獲得,就是 server_sessid。需要注意的是使用 obclient 連接 proxy 時候,登陸信息中會有輸出 Your Mysql connection id is xxx,這裏顯示的 id 是 cs_id。
- MASTER_SESSID:這個比較特殊,指的是分佈式查詢中的主 server_sessid,不屬於 S 連接(本文暫不討論)。
四. 查詢 session id 的例子
下面是模擬的一個例子,大家通過這個例子可以更好的理解相關概念。
架構中一個客户端連接了一個 proxy,然後 proxy 連接了後面的 2 個 OBServer。
也就是 C-1 ,對應了後面的 S-1 和 S-2 。
在確保 C-1,S-1,S-2 都被啓用過以後,執行下面這些命令:
show proxysession;
show proxysession attribute;
show processlist;
show full processlist;
select connection_id();
select * from gv$ob_session;
select * from gv$ob_processlist;分別得到下面的結果:
-
show proxysession;
- 這裏的 id 就是 cs_id。
- 直連是無法執行這個命令的(需要有 proxy)。

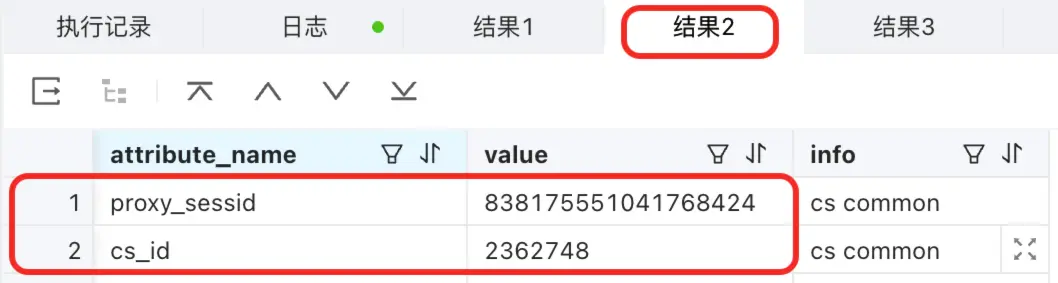
-
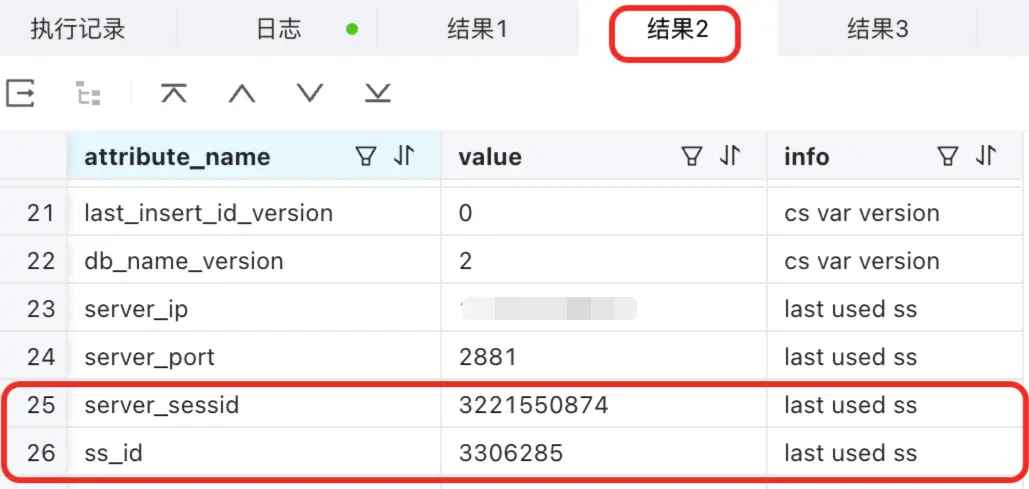
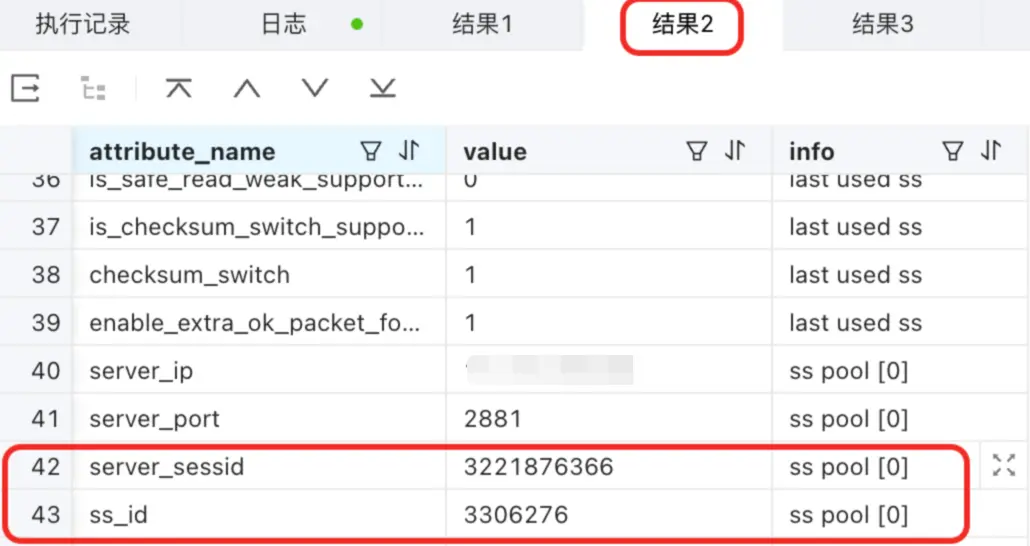
show proxysession attribute; 這裏就是查看這個 cs_id 的明細了。這個 cs_id 對應了 2 個 server_sessid ,分別是 3221550874 和 3221876366,它們的區別在 info 這個列:
- last used ss 指的就是我執行這個查詢 SQL 是用的這個 S 連接。
- ss pool 就是已經建立了這個 S 連接,之前是用到過的。
同樣的,這個命令在直連時候是無法執行的,因為這個命令只有 proxy 能處理。
-
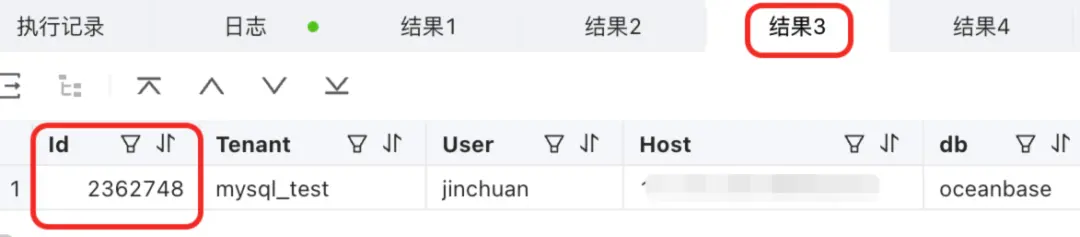
show processlist;
- 使用 proxy 的時候,這個 ID 是 cs_id。需要注意 show processlist 在 proxy 的語境下,就是查這個 proxy 上的 session,以 C 連接的視角(也就是一個客户端連接就顯示一條)。
- 使用直連時候,這個 ID 是 server_sessid。
-
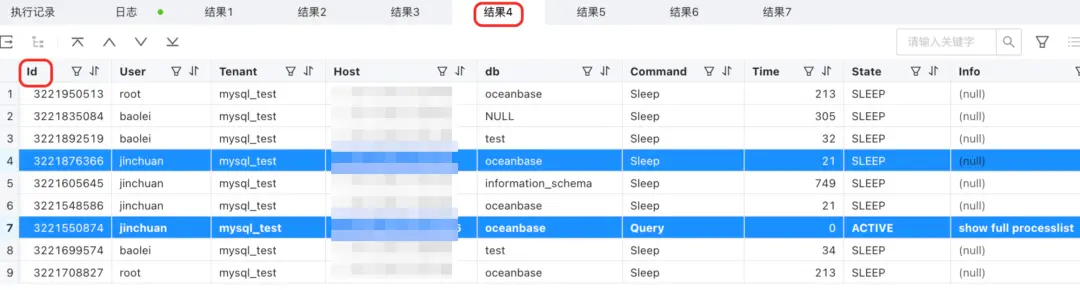
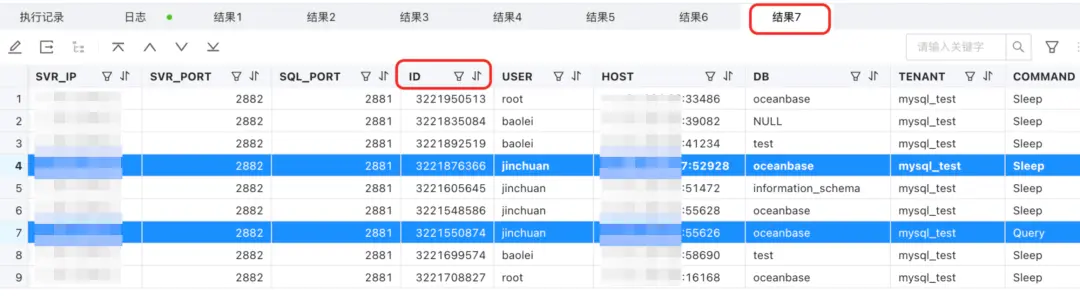
show full processlist;
- 這個就是查看所有的 S 連接了,這裏的 ID 是 server_sessid。
- 圖中標藍的部分都屬於同一個 C 連接,可以對照 show proxysession attribute 的內容看。
-
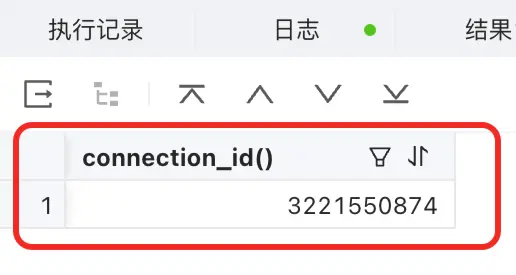
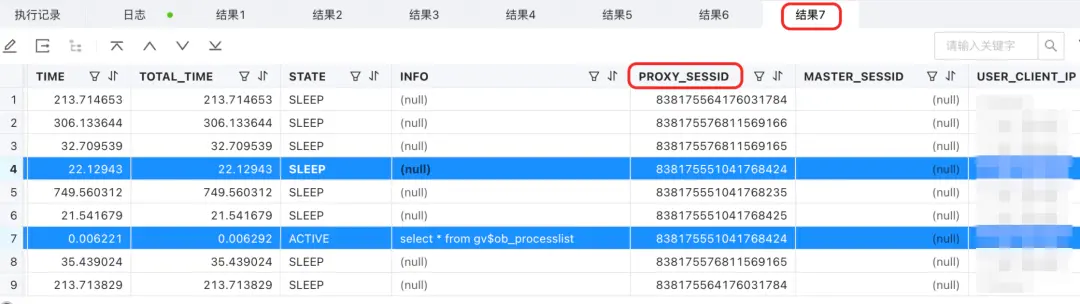
select connection_id();
- 查到的是執行這個 SQL 的 S 連接,是 server_sessid。
-
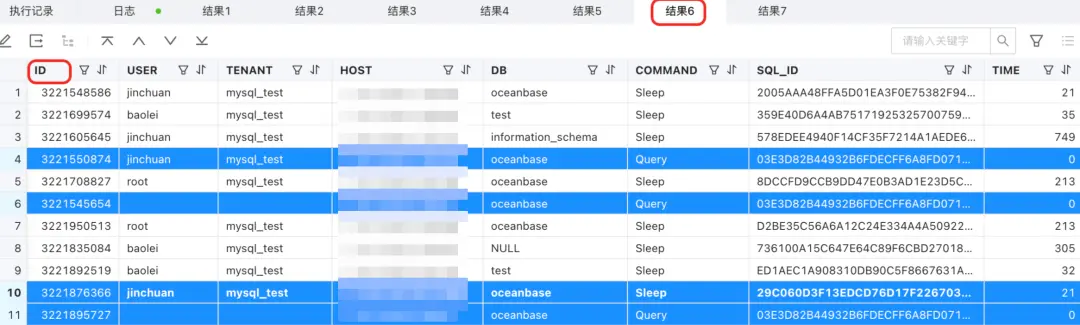
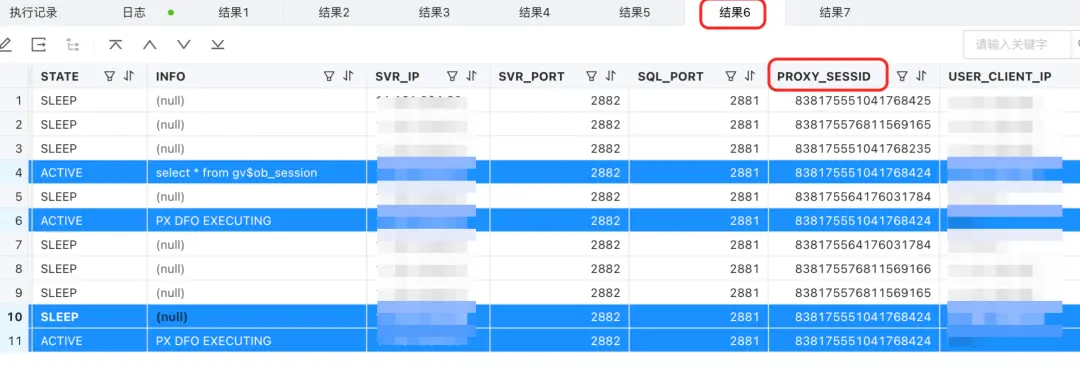
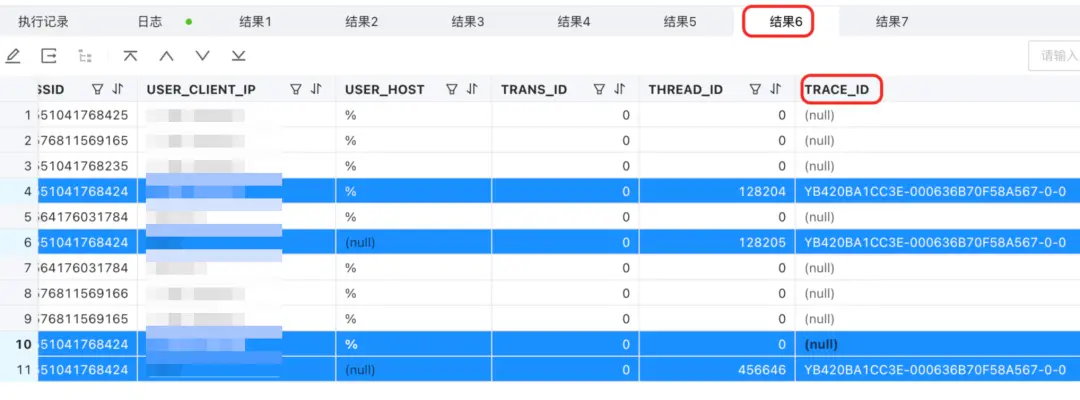
select * from gv$ob_session;
- 這裏標藍的部分都屬於同一個 C 連接,它們擁有同一個 proxy_sessid,按理只有 2 個 S 連接,為什麼有 4 條數據對應 4 個 ID 呢?
- 你會發現 4 個 ID 中有 2 個是前面例子中出現過的 server_sessid,而剩下的 2 個是新 server_sessid。
- 注意看 info,PX DFO EXECUTING 意思是分佈式的執行。因為 gv$ob_session 的查詢需要去所有的 OBServer 上看相關信息,所以實際執行這個 proxy_sessid 的 SQL 的 OBServer,建立新的連接(S 連接背後對應的新的分佈式執行連接),分別查詢了 OBServer 的內部信息。
- 我們可以通過其他列(比如TRACE_ID,HOST等)的信息來理解。
這也可以看到,實際上 OceanBase 數據庫等訪問連接是比較複雜的,這個案例中連接分了 3 段,第一段是客户端到 proxy,第二段是 proxy 到 OBServer,第三段是 OBServer到 OBServer(自己也需要重新訪問自己的)。
-
select * from gv$ob_processlist;
- 這裏和 show full processlist 的結果是一樣的。
- ID 代表的是 server_sessid,不會展示 S 連接後續的連接(有別於 gv$ob_session 視圖)。
如果能堅持看完上面這些例子,要麼你已經對 session id 的情況有了全面的瞭解,要麼你已經徹底暈菜。沒關係,如果暈了,可以先收藏,後面遇到問題時再有的放矢地看。
如果你能堅持看到這裏的話,那我們就繼續再説一個與 session id 配套的命令 —— kill。
五. session id 與 kill 命令
kill 後面跟的是 session id,執行後這個會話就會被殺死,執行的 SQL 會停止,之前鎖定的資源也將釋放。
但是因為 session id 本身的複雜性,kill 命令的實現,也有不同的邏輯。我們一般會使用取到的 ID 列中的值來作為 kill 後跟隨的編碼,那麼可能是 cs_id 或者是 server_sessid。
還有一些特點,大家理解一下:
- 執行 kill 的 session 本身除了可以殺自己,還可以殺別的 session。
- kill 在 ODP 4.2.3 版本之前(以下稱為不透傳 kill),是由 proxy 自己執行的,直接從 proxy 側斷開相關 session 的 C 連接和 S 連接。
- kill 在 ODP 4.2.3 版本開始(以下稱為透傳 kill),會把 kill 信息轉交給 OBServer 去執行,然後通過錯誤碼告訴 proxy,proxy 再斷開相關 C 連接和 S 連接。
- proxy 本身是無狀態的,看不到其他 proxy 中的 cs_id。
- cs_id 是 proxy 內部對 C 連接的編碼,OBServer 對 C 連接的認知是 proxy_sessid。
不透傳 kill 的情況,做了個表格:
| *\組件(列)ID(行)* | proxy (C 連接在此 proxy) | proxy (C 連接不在此 proxy) | 直連 (不區分 S 連接是不是在這台 OBServer 上) |
|---|---|---|---|
| cs_id | 認識,可以 kill。 | 不認識,因為 proxy 無狀態,無法 kill。 或者恰巧有個一樣的 cs_id,kill 錯。 | 不認識,根本沒有 cs_id 信息。 |
| server_sessid(主) | 認識,可以 kill。 | 可以認識,但是不歸這個 proxy 管,無法 kill。 | 認識,kill 成功,proxy 感知後,後續把對應的 C 連接斷開。 |
| server_sessid(非主) | 認識,可以 kill。 | 可以認識,但是不歸這個 proxy 管,無法 kill。 | 多種情況,比較複雜。 |
先説建議:就是如果用的是 proxy,那就不要使用直連方式去 kill。
如果遇到 kill 不掉(可能是因為 F5 這樣的負載均衡把 kill 語句路由到了其他無法處理的 proxy),就多執行幾遍,一般總有一次 kill 成功的(成功一次就算 kill 成功了)。雖然上面的表格中寫了有可能 kill 錯,但是概率很低。
因為上面不透傳的情況,會遇到各種的問題。後來 OceanBase 研發對 kill 進行了重新設計。主要解決了 2 個問題:
- C 連接不歸 proxy 管的問題(現在統一交給後面的 OBServer 執行,然後相關的 proxy 就可以收到來自 OBServer 的返回碼後,處理斷開 C 連接了)。
- cs_id 可能在不同的 proxy 之間重複的問題(啓用新設計的 client session id 替代 cs_id,通過合理編碼來使其具有唯一性),另外 client session id 也將在 proxy 和 OBServer 之間建立連接的時候告訴 OBServer,這樣 OBServer 就都認識了。
透傳 kill 的情況,也做了一張對應表格:
| *\組件(列)ID(行)* | proxy (C 連接在此 proxy) | proxy (C連接不在此 proxy) | 直連 (不區分 S 連接是不是在這台 OBServer 上) |
|---|---|---|---|
| client session id | 認識,可以 kill。 | 可以認識(問 OBServer 嘛)然後透傳給 OBServer執行,可以kill。不會有重複問題 | 認識,可以 kill。 |
| server_sessid(主) | 認識,可以 kill。 | 可以認識,透傳,可以 kill。 | 認識,kill 成功,效果就等於 proxy 把 kill 透傳了。 |
| server_sessid(非主) | 認識,可以 kill。 | 可以認識,透傳,可以 kill。 | 多種情況,比較複雜。 |
透傳以後,是不是情況好多了?但我的建議依然還是建議都使用 proxy 來管理 kill,(而且2個組件都升級到新的使用 client session id 的版本)按照常用情況來管理,問題最少。
值得一提的是,透傳後的情況表格漏掉了很多情況,你看出來了嗎?原因就是這個時候 proxy 和 OBServer 面對 kill 命令都有 2 套邏輯,這裏的例子都是新 proxy 邏輯對新 OBServer 邏輯,還有老 proxy 邏輯對新 OBServer 邏輯和新 proxy 邏輯對老 OBServer 邏輯的情況。
理想中是要列出所有情況的,但這篇文章的作者今川説他偷懶不想整理其他情況了,那我們還是選擇原諒吧~
六. 總結
最後返回文章開頭的問題,為什麼要使用這麼多的名詞來管理 2 種連接。
- 最大的原因還是分佈式的架構引入的複雜性決定的。而且 proxy 被設計成無狀態的,在前面還加入 F5 這樣的負載均衡組件,也增加了管理難度。
- 數據庫軟件複雜度很高,多個團隊協作開發,必然有一些東西是不統一的,並且存在冗餘設計,否則溝通成本將被無限放大。
- 數據庫軟件是一個不斷演進的系統,有些東西雖然現在看來已經沒有用了,但是也不能去掉,作為兼容性的一部分長久留在代碼中。如同我們的 DNA,很多序列都是不表達的,沒什麼用處,但是是人類演進過程中的一部分也就被保存在 DNA 中了。

七. 後續
還有一個出現在 proxy 日誌中,用於指代 C 連接的代碼 sm_id,相關的信息比較少。sm_id 是 proxy 中的 proxy_sm 模塊對 cs_id 的指代。只在日誌中出現,由於數據庫裏沒有視圖查到這個信息,我認為主要是給 proxy_sm 模塊研發使用的。一般排查日誌可以通過 trace_id 來過濾。