

首先為大家推薦這個 OceanBase 開源負責人老紀的公眾號 “老紀的技術嘮嗑局”,會持續更新和 #數據庫、#AI、#技術架構 相關的各種技術內容。歡迎感興趣的朋友們關注!
本文整理自6月21日“OceanBase 城市交流會 · SQL 遇上 AI ”《度小滿 × OceanBase 實踐:統一架構驅動效率與成本雙突破》,點擊鏈接可觀看視頻回顧。
作者:趙輝,度小滿技術委員會負責人
度小滿,原百度金融。2018年4月,百度宣佈旗下金融服務事業羣組正式完成拆分融資協議簽署,實現獨立運營。作為一家金融科技公司,度小滿充分發揮百度的AI優勢和技術實力,攜手金融機構合作伙伴,用科技更好地提供金融服務。本文介紹度小滿業務高速增長背後,面臨的存儲挑戰與數據庫解決方案。
四大成本優勢決定數據庫選型結果
度小滿金融業務規模的高速擴張,使存儲需求呈指數級增長。那時,底層的數據庫方案面臨數億用户的高併發交易、毫秒級實時風控決策、高吞吐變量數據寫入,以及報表分析的極低延遲的挑戰。經大數據部門的深入分析,存儲架構存在五個方面的問題,導致其很難面對上述挑戰,持續支撐業務需求。
其一,度小滿自研技術棧多,比如關係存儲類DDBS、KV存儲類的CKV、稀疏海量存儲類的Eggroll、等等。對於一線開發人員來説學習成本較高,需要對接並學習多種用法,開發和對接效率有待提高。
其二,資源成本高,主機規模大,主從備架構部署冗餘,存在多個小集羣,導致存儲成本高、CPU利用率低、資源難複用。
其三,一些業務操作如流量切換與屏蔽、數據均衡操作、擴縮容操作複雜,且對業務不透明,需要多方配合,執行週期較長,部分場景更是需要方案定製。
其四,存在可用性風險,所有類型的存儲引擎在全場景下,比如進程掛起、硬件故障、機房故障、地域災難等場景,難以達到9999的SLA。
其五,工具生態欠缺,工具自動化,尤其是產品化程度較低,運維效率有提升空間。
針對業務需求及原本數據庫方案面臨的困境,我們決定重新選擇一款既滿足業務需求又可以統一當前所有技術棧的產品。那麼,為什麼最終選擇OceanBase呢?
經過前期對多款數據庫在遷移成本、資源成本、學習成本、運維成本等方面的調研,我們發現 OceanBase 非常符合我們的選型需求。
1.遷移成本低:兼容 MySQL 和 Redis 協議,遷移過程平滑無感。
為了實現底層架構棧的統一,我們替換數據庫方案面臨的第一個要求就是遷移成本不能過高,否則將會面臨較大的業務阻力。由於 OceanBase 兼容 MySQL 和 Redis 協議,整個遷移過程非常平滑,幾乎沒有改造,我們投入的人力、時間都較少,對業務有正向收益,因此,間接降低了整體的遷移成本。
2.資源成本低:引擎執行高效,TPCC 刷榜世界紀錄,超高壓縮比。
OceanBase 有世界領先的計算執行引擎,曾打破 TPCC 世界紀錄。而且,極致的數據壓縮比在業內聞名,相比傳統數據庫 MySQL,能夠實現幾倍的存儲空間節約,極大地降低了企業的存儲成本,帶來顯著的資源利用率提升。
3.學習成本低:支持關係/KV /向量等技術棧統一,多種部署架構的運維方式統一。
如上文提到的,我們的多種技術棧及組件給一線的開發人員和運維人員帶來了極大的學習成本,OceanBase 用一套引擎就可以解決關係型數據、KV、向量等多種數據類型的存儲及計算,滿足所有業務場景的需求,極大降低了學習成本,提升了運維效率。
4.運維成本低:支持機房地域級的容災,RTO<8s,RPO=0。原生支持分佈式,擴縮容對用户透明。
OceanBase 具備完善的周邊工具生態,包括 OCP(雲平台)、OMS(數據遷移服務)和 ODC(開發者中心)、OBD(安裝部署工具)等,為用户提供了全方位的支持,從安裝部署、遷移數據、開發工具到運維管理、監控告警,一應俱全。在支持在線擴縮容的基礎上,通過雲管理平台 OCP,可以白屏化實現非常便捷的擴縮容能力,極大地提升了我們目前的運營能力、使用體驗和工作效率。此外,OceanBase 原生具備高可用能力、經過我們的實際測試,發現在故障發生時,業務完成切換的時間在 8s 之內,且數據零丟失,證明OceanBase確實達到了 RPO=0,RTO< 8s。
五個場景探索OceanBase在業務落地的可行性
到底OceanBase在實際場景中的表現如何,能否解決我們此前面臨的數據延遲、查詢性能問題?下文通過五個技術場景的實踐舉例説明。
場景1:海量數據的低延遲查
在單表月數據量 10億,佔用內存約 30GB 的查詢場景中,通常僅查詢月內數據且查詢語句複雜。使用原本的MySQL方案時,需要將一張表拆分為多張表才能實現較好的性能。但這樣的操作會使業務邏輯和使用邏輯變得更加複雜,無法滿足業務需求,同時,存儲成本很高,不符合整體業務訴求。
在切入 OceanBase 後,2025年5月單表存儲數據近 10 億,內存佔用 29.5GB,在響應耗時最大的update 場景中耗時8毫秒,符合我們的預期,而在其他場景如 select、insert 場景的耗時更低。對於業務操作整體耗時,OceanBase方案可以控制在10毫秒內,完全滿足業務要求。
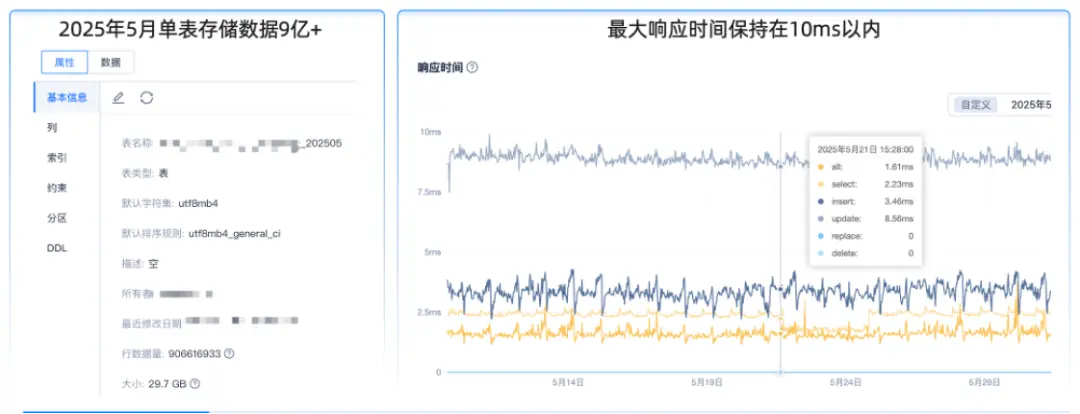
該場景中,我們的經驗是:由於 OceanBase 為原生分佈式架構,建議大家針對需要手動分表的場景使用分區能力,降低一線人員的改造成本和業務邏輯設計成本。另外對於複雜查詢語句,例如 in 值太多的情況,需綁定執行計劃,避免全表掃描導致執行時間過長。
場景2:數倉加工高性能讀寫
實時數倉的高性能讀寫是另一個需要優化的業務場景,涉及 10w 寫 + 36w 讀,其中查詢涉及 TP 點查 + AP 聚合關聯查詢,並且存量數據和增量數據分別是兩種存儲系統。原本我們使用 MySQL 的 DDBS 分佈式存儲進行增量數據的實時讀寫,這是因為在存儲數據量較多時,訪問存量數據帶來的性能壓力較大。而對於存量數據,則使用 Eggroll 存儲,但由於 Eggroll 是磁盤型存儲,即一個簡易的基於 RocksDB 的分佈式架構,擴縮容週期相對較長。
下圖顯示了我們的數倉加工鏈路,在改造前,業務數據源通過 Kafka、Flink,在 ODS 層讀寫MySQL,然後讀 Eggroll,再經過 Kafka 多輪的寫,鏈路從 ODS 層到 DWD 層再到 DWS 層。開發該數據鏈路的人員既要熟悉 DDBS 架構、Eggroll 架構,還要清楚從 Kafka 到 Flink 再到 Hive 的整條鏈路,涉及多個引擎和鏈路加工,交付週期非常長。
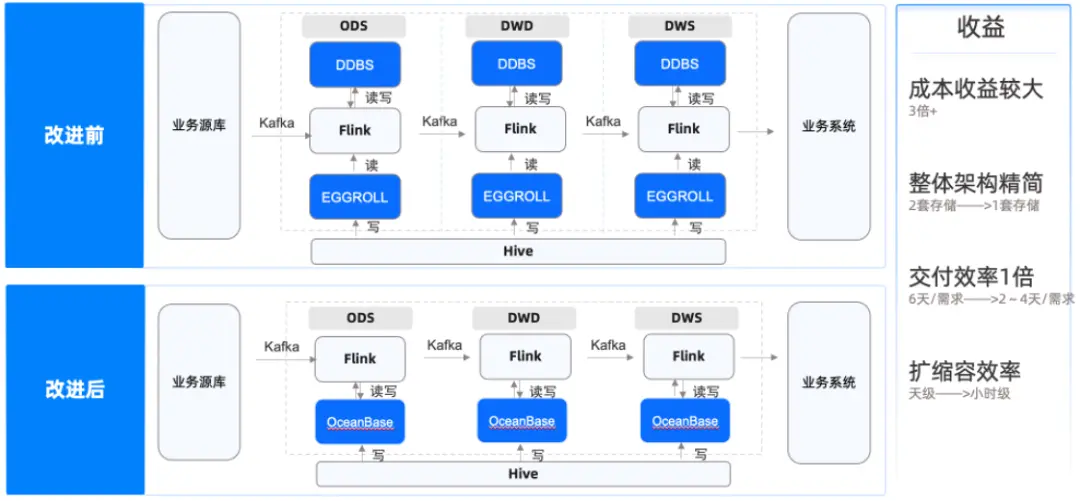
經過改造後,我們將 DDBS 和 Eggroll 切換為 OceanBase ,在整體架構、交付效率、擴縮容、成本等方面都取得了巨大收益。
- 架構精簡:原本維護兩套存儲引擎變成了維護一套交互鏈路,撰寫這部分代碼的同學只需要熟悉一套邏輯和接口就可以完成整個鏈路工作。
- 交付效率翻倍:除了撰寫代碼的效率提升外,學習成本也大幅降低,開發週期從6天縮短到3天左右,交付效率翻倍。
- 擴縮容效率提升:原來一個擴容可能是要天級別甚至周級別才能完成,切換到支持在線擴縮容的 OceanBase 後,可以實現小時級擴容。
- 成本收益3倍以上:DDBS 及 Eggroll 的壓縮比並不高,切換到 OceanBase 後,壓縮比可以做到 4:1,帶來的成本收益非常大,加上性能收益,整體成本收益達到3倍以上。
當然,在本次改造過程中,我們也積累了一些技術實踐經驗,供大家參考。
一是在使用 OceanBase 的過程中應儘量避免跨分區的 RPC 通信問題,如果 RPC 通信次數較高,查詢性能下降會比較明顯,需要對業務模型做盡量合理的設計,例如 SQL 中要帶分區信息,儘量命中本地節點以便取得更極致的性能表現。
二是熱點數據的寫衝突。由於 Flink 的數據是實時同步的,如果我們更新一個變量,變量也會實時讀寫,導致熱點數據的寫衝突及性能下降,因此建議開啓 Early Lock Release 特性,整個性能表現會更加優秀。
三是存量數據高壓力寫對結果點查的影響,由於批量存量數據需要每天更新入庫,會和正常的業務請求發生資源爭搶,導致業務請求的時間變長。我們的解決方案是,對存量寫任務進行資源隔離與管控,進一步解決問題。
後續我們計劃使用 obbinlog 代替現有 Kafka 的數據傳輸鏈路,與OceanBase社區合作優化obbinlog的性能,實現基於 Flink和OceanBase 及其工具的監控鏈路,降低實時數倉加工鏈路的架構複雜度,進一步提升查詢效率和交付效率。
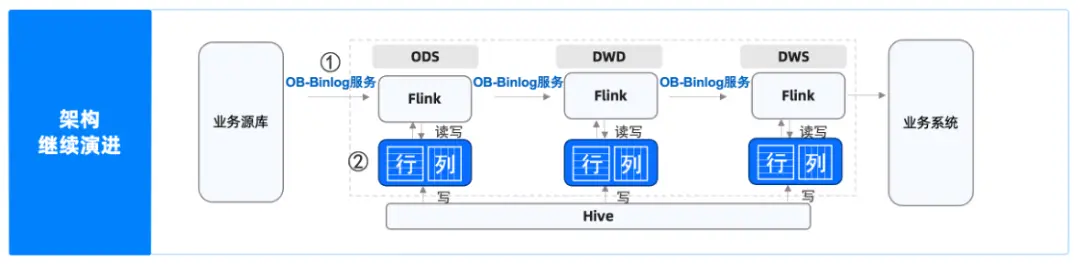
此外,我們也期望 AP 聚合關聯查的延遲問題能被解決,所以未來會探索OceanBase 的行列混存。目前,我們關注到 OceanBase已經發布面向AP的第一個 LTS 版本——V4.3.5,後續將持續關注該版本的完善情況。
場景3:變量數據高吞吐寫入
度小滿存在很多變量有 T+1 加工的場景,加工完成後需要進行變量入庫,供在線業務查詢。我們的原方案是使用 HBase 的 Bulkload 能力更新到存儲引擎 Eggroll 上,當 Eggroll 切換到 OceanBase 後,開始使用 OceanBase 的 Obloader 腳本。

目前,在使用Obloader 方案時也遇到一些問題。由於 DGS 是我們內部自研的對象存儲,協議獨特,不能完全兼容 Obloader 腳本,需要我們先將其下載到本地再用腳本入庫,效率較低。但由於我們在更新 T+1 數據時,需要把一天之內完成所有數據的全量寫入,單個腳本入庫數據量太大,時效性要求很高。當效率不足以支撐時,會導致一天內需要寫入的數據寫不進去,因此當前的方案無法滿足實際業務需求。
對此, OceanBase 官方為我們推薦了旁路 SDK 方式,直接對接自研 DGS 協議,遠程讀取直接入庫,避免了一次落盤操作。同時針對超大數據量場景,利用 K8S 彈性能力,動態啓動多進程分片入庫,提升了整個吞吐量,確保了該場景下業務的適配性。
場景4:標量過濾+向量檢索的混合查詢
在AI大潮下,標量過濾+向量檢索的混合查詢將成為常態。對於該場景,我們當前使用 Elasticsearch 支撐,而我們將積極探索切換為 OceanBase 方案的可能性,並開啓了性能測試。
在性能測試中,我們使用了兩種業界常用的測試集:
- 數據集:cohere 768 1M(768維,100W向量),在 Limit 10、召回率 0.9、索引類型為 HNSW、併發 50 的情況下進行基礎性能對比,OceanBase 性能是 Elasticsearch 的1.24倍。
- 數據集:cohere 1536 500K(1536維,50W向量),在 Limit 10、召回率 0.9、索引類型為 HNSW、併發 50 的情況下進行基礎性能對比,OceanBase 性能是 Elasticsearch 的1.04倍。

從測試結果來看,OceanBase 在 AI 場景中會有 10%~20% 的性能提升。我們已聯合業務方進行試點,後續會進一步完成OceanBase在 AI 場景的落地。
場景5:極致的 KV 讀寫性能
在我們的 KV 場景中,前端面臨 120w QPS 的查詢壓力,並且會映射到底層存儲。我們搭建了 OceanBase 三節點,經過測試,OceanBase能夠做到 60w QPS 的性能支持,平均延遲 1 毫秒左右,且可以持久化存儲,完全滿足我們的業務需求。同時 OceanBase 存量數據在磁盤中也能夠持久化存儲,提升了系統的穩定性和可用性,相較於原本的 CKV 方案,優勢明顯。因此,我們計劃近期在KV場景正式上線OceanBase。

總結與展望
引入 OceanBase 對度小滿來説,不僅是替換傳統關係型數據庫解決性能和成本問題,更大的意義在於:將關係型/KV 型/ AI 向量型等眾多在線存儲技術棧進行統一,實現開發與運維的雙重提效。
進一步展望,我們對 OceanBase 的內部測試表明其性能優於其他主流向量數據庫,但這些結果尚未獲得獨立的第三方驗證,如 VectorDBBench 第三方基準測試項目。我們希望 OceanBase 做進一步的驗證,同時也期待和 OceanBase 的專家做更深入的探討,並最終應用到真實的業務中。
「老紀的技術嘮嗑局」不僅希望能持續給大家帶來有價值的技術分享,也希望能和大家一起為開源社區貢獻一份力量。如果你對 OceanBase 開源社區認可,點亮一顆小星星 ✨ 吧!你的每一個Star,都是我們努力的動力。
https://github.com/oceanbase/oceanbase
