

過去兩年,你可能經常看到類似的信息洪流:
- 一台服務器賣 300 萬?因為它裝了 8 張 H100 GPU。
- 大模型訓練一次要燒掉上億人民幣?
- 雲計算巨頭都在搶「算力調度業務」?
- 各國發布「AI 國家戰略」?
看新聞彷彿置身一場術語大混戰:
AI、大模型、GPU、雲原生,到底在説啥?
是彼此替代?還是互為上下游?能不能一句話講明白?
如果把當今 AI 技術體系比作一家 米其林三星餐廳:
|
角色
|
對應概念
|
職責類比
|
技術定位
|
|
最終端的精美菜品
|
人工智能(AI)
|
呈現的價值成果
|
應用與願景
|
|
頂級主廚
|
大模型(LLM)
|
掌握核心配方
|
智能核心
|
|
廚房爐具與自動化設備
|
GPU
|
高效烹飪體系
|
算力底座
|
|
餐廳管理與食材供應系統
|
雲原生(Cloud Native)
|
流程調度
|
算力管理基礎設施
|
一句話總綱:
GPU 提供算力 → 雲原生調度算力 → 大模型實現智能 → 人工智能走向真實世界價值落地
它們不是替代,而是“垂直貫通”的技術鏈條。

編輯
下面我們逐層拆解。
01|GPU:深度學習時代的“暴力美學”
GPU = 並行算力的工業化生產線
CPU 像一位邏輯大師,可以思考複雜流程,但一次處理少量任務:
串行強、並行弱
GPU 像一個訓練有素的萬人方陣:
並行爆炸強 → 執行海量簡單位運算(矩陣加乘)
大模型訓練的底層本質就是:
矩陣乘法 × 海量數據 × 無限迭代優化
以 GPT 類模型為例:
- 模型參數可達 10,000,000,000,000(10萬億)級別
- 單次訓練算力需求為 ExaFLOPS(百億億次)級
如果用 CPU:
訓練 GPT-4 ≈ 等待幾十年
如果用 GPU:
數千張 H100 服務器:幾周完成
所以 GPU 被稱為:
AI 時代的「石油」
誰掌握 GPU,誰就掌握智能計算的加速度
02|雲原生:馴服算力巨獸的“繮繩”
擁有 GPU ≠ 擁有 AI 能力
更像擁有了一羣極難管理的猛獸
問題包括:
- 10000 張 GPU 如何協同?
- GPU 故障如何自動容錯?
- 如何根據用户訪問變化自動擴縮容?
- 如何讓訓練和推理像消費水電一樣便捷?
這正是**雲原生(Cloud Native)**登場的意義。
雲原生典型技術組合:
|
能力
|
核心技術
|
解決的問題
|
|
資源抽象
|
容器(Docker)
|
應用運行環境標準化
|
|
智能調度
|
Kubernetes(K8s)
|
哪塊卡幹活?什麼時候擴?怎麼補位?
|
|
微服務架構
|
Service Mesh
|
複雜業務模塊化、自治化
|
|
自動化 DevOps
|
CI/CD
|
更新不宕機,快速迭代
|
一句話總結雲原生:
把 GPU 集羣變成“有調度、有彈性、有韌性”的超級算力工廠
它的目標就是:
≈「自來水模式算力」
隨取隨用、省錢省人省心,越大越穩定
03|大模型:從統計學習到“涌現智能”
模型為什麼“大”才能“聰明”?
因為更多參數 = 更強表達能力
參數如同神經突觸連接,規模跨過某個閾值後會出現:
智能涌現(Emergent Intelligence)
也就是:
你沒教它,但它突然就會推理、寫代碼、寫詩、講笑話。
|
時代
|
技術範式
|
能力
|
瓶頸
|
|
傳統 AI
|
規則引擎
|
僅機械執行
|
人寫規則,規模受限
|
|
機器學習
|
特徵工程
|
特定領域表現強
|
人工特徵設計困難
|
|
深度學習
|
神經網絡
|
感知能力提升
|
通用理解能力不足
|
|
大模型(LLM)
|
Transformer
|
泛化與生成躍遷
|
算力與數據成本巨大
|
大模型本質是一種:
跨模態知識引擎 + 泛化推理能力
當它接受人類意圖後,就能生成:
- 文本、圖像、音頻、視頻
- 軟件代碼、數學推導
- 商務戰略建議
- 科研分析、法律條文草案…
它不僅回答問題,還能代替你完成任務。
04|人工智能:大目標與世界接口
AI 是 頂層願景與最終價值出口
它不是技術,而是:
改變產業與社會的「智能基礎設施」
AI 應用涵蓋:
- 醫療診斷與藥物發現
- 自動駕駛
- 金融風控
- 教育輔學
- 公檢法應急指揮
- 工業檢測與預測性運維
- 內容創作、虛擬助理、機器人…
AI 無處不在,它正在變成:
像電力一樣的通用生產力(General Purpose Technology)
而大模型是當下最有效率的 AI 實現方式,但不是全部。
AI 仍包括:
- 強化學習
- 多智能體體系(Agents)
- 具身智能(Embodied AI)
- 知識推理與符號邏輯
未來 AI 不只是“會説話的模型”,而是能行動的智能體。
技術鏈路全景圖
用一句最清晰的話總結:
想要 AI 改變世界 → 需要大模型
想要大模型跑起來 → 需要海量 GPU
想要 GPU 集羣不崩潰且不燒錢 → 需要雲原生
形成如下技術金字塔結構:
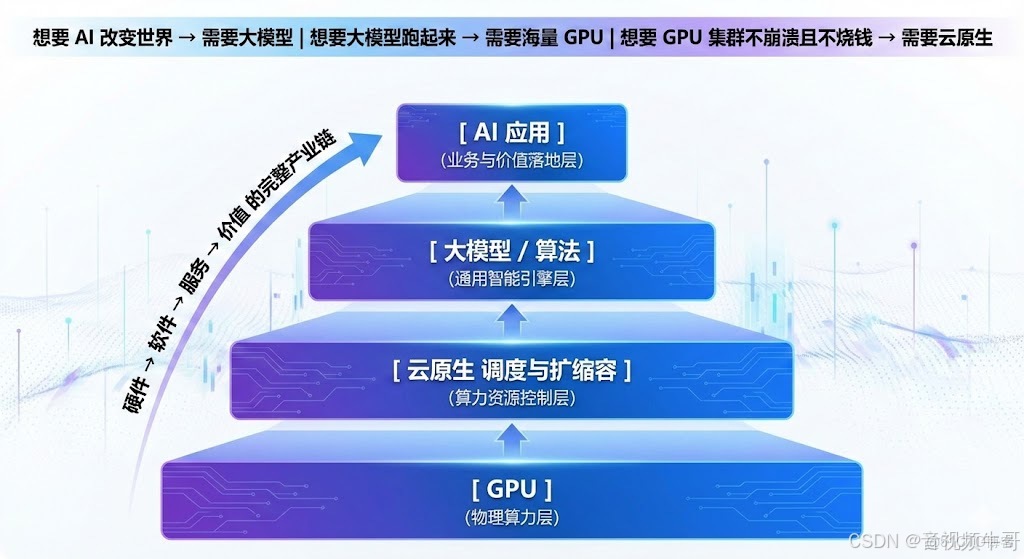
編輯
它們不是並列概念,而是:
從硬件 → 軟件 → 服務 → 價值 的完整產業鏈
為什麼這條鏈會成為國家與巨頭競爭焦點?
因為每一層都體現國家競爭力與產業控制力:
|
層級
|
決定因素
|
產業戰略價值
|
|
GPU
|
製造能力、供應鏈、安全可控
|
卡脖子最嚴重、最稀缺資源
|
|
雲原生
|
算力調度能力、規模管理
|
算力是否可成為基礎設施
|
|
大模型
|
算法積累與數據規模
|
通用智能競爭壁壘
|
|
AI 應用
|
行業落地與生態
|
真實生產力轉化
|
一句話:
誰掌握 GPU、雲原生和大模型,誰就能定義 AI 的未來
結語:時代的底層規律
當我們仰望人工智能的璀璨時,別忘了它腳下的地基:
- GPU 承擔算力之力
- 雲原生 賦予調度之序
- 大模型 凝聚知識之智
- AI 應用 承載落地之業
它們共同構成了這個時代最重要的底層公式:
算力 → 模型 → 服務 → 價值
未來十年,最激烈的競爭,不是某個應用火爆與否,而是誰能更快、更穩、更經濟地把這條鏈條跑通。
當智能成為新的基礎設施
當算力像水電一樣隨取隨用
當模型能力像操作系統一樣普世
那將不是工具升級
而是生產方式的躍遷。
技術的演進從來不是炫技
而是推動世界向前的力量。