

各位參觀者請看,
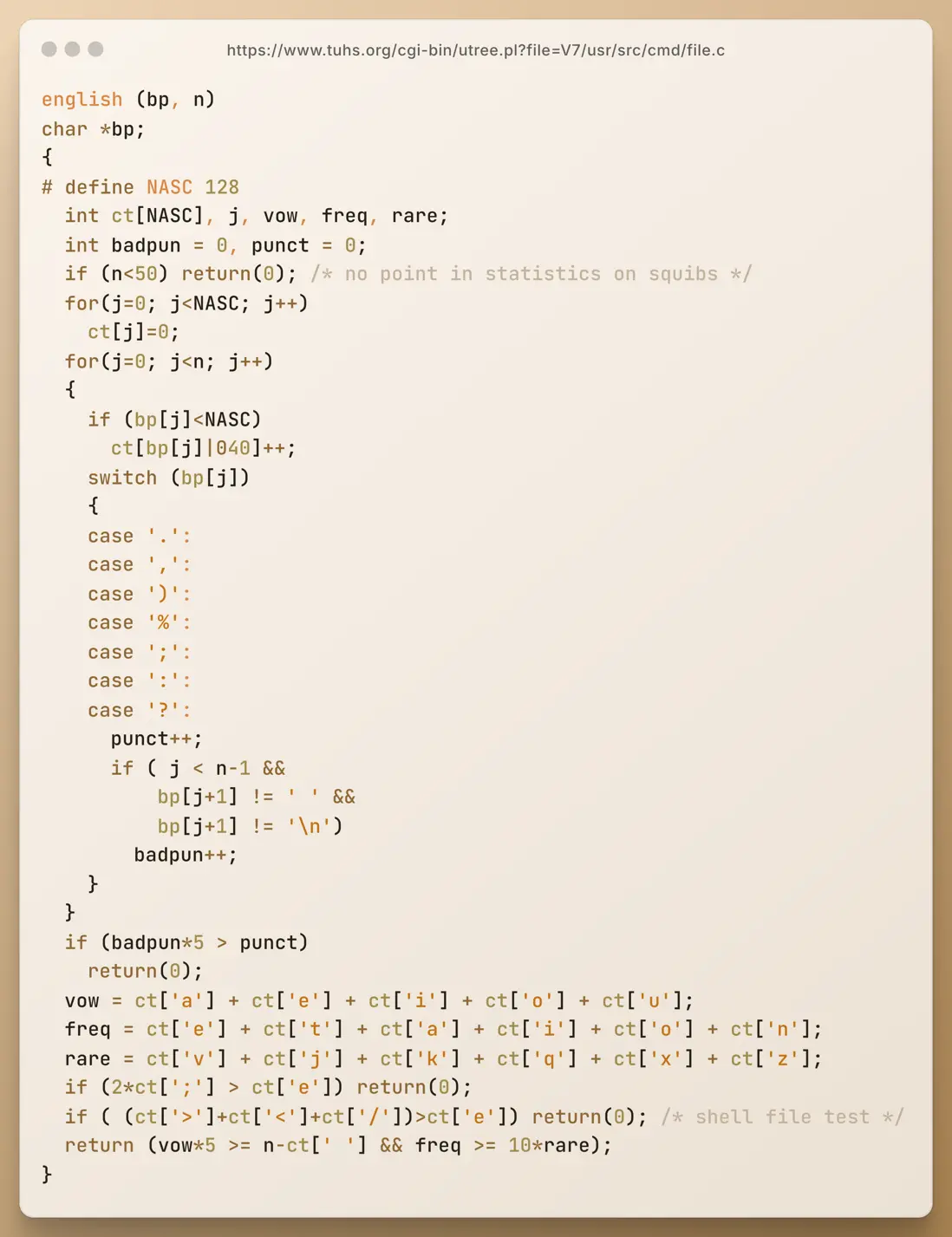
圖中是一段出土自 Unix V7 系統“遺蹟”的 C 語言代碼,這段代碼可追溯至距今 40 餘年的 1979 年左右,作者是 Ian Darwin。它是早期 file 命令源代碼的一部分。
file 命令用於在不依賴文件擴展名的情況下判斷文件類型——當“打開方式不對”時,file 命令能告訴你文件中實際包含的內容。直到今天,大多數類 Unix 操作系統裏還能見到 file 命令的身影。
現在看到的這個名為 english(bp, n) 的函數能夠對文本的特徵進行分析,並以此來判斷一段文本是否由英文寫成。換句話説,這是一個早期的“文本語言識別器”。

運行在 Unix V7 模擬器上的file命令。這裏輸出了根目錄下所有文件的類型。可見,文件“COPYRIGHT”是一個英文文檔
接下來,我們就來一同看看這件“數字文物”是如何構思和實現的,它的寫法與我們今天的編碼風格有何不同?在算法設計上是否還有可借鑑之處?
K&R 風格的函數聲明
先來看前兩行函數聲明的部分,這無疑是整段程序中與現代 C 語言差異最明顯的地方了吧。
english (bp, n)
char *bp;若按照今天的 C 語言語法,這個函數的簽名大致會寫作:
int english(char *bp, int n)回到 1979 年,C 語言剛剛走過了它的第 7 個年頭。那時還沒有標準化的 ANSI C,主流仍是所謂的 K&R 風格語法——函數參數的類型不寫在參數列表裏,而是緊接函數名後;而參數或返回值如果是 int 類型,通常也可以省略。這種寫法在今天看來或許有些古怪,但卻在當年普遍使用。
這個函數體可以大致分為三部分:初始化、統計和規則檢查。
初始化
先來看看初始化部分。和現代 C 語言相比,局部變量的定義倒是沒有太大變化。為了方便大家理解,先來簡單介紹下幾個關鍵標識符的含義:
english (bp, n)
char *bp;
{
# define NASC 128
int ct[NASC], j, vow, freq, rare;
int badpun = 0, punct = 0;
if (n<50) return(0); /* no point in statistics on squibs */
for(j=0; j<NASC; j++)
ct[j]=0;
... ...bp:指向待判斷的文本的指針,即指向待分析的字符串的首個字符n:文本長度NASC:定義了統計數組ct的大小,128 是 ASCII 字符的數量ct:用來統計文本中每種字符出現的次數j:i已用作全局變量,所以這裏用j作為循環變量vow:記錄文本中出現的元音字母(vowel)的數量freq:記錄高頻英文字母(e、t、a、i、o、n)的出現次數rare:記錄罕見英文字母(v、j、k、q、x、z)的數量badpun:記錄不符合英文書寫規範(即其後沒有空格或換行)的標點符號的出現次數punct:記錄所有標點符號(punctuation)的總數
統計
接下來,我們進入統計部分。簡單來説,這裏會統計文本中每種字符出現的次數。
for(j=0; j<n; j++)
{
if (bp[j]<NASC)
ct[bp[j]|040]++;
switch (bp[j])
{
case '.':
case ',':
case ')':
case '%':
case ';':
case ':':
case '?':
punct++;
if ( j < n-1 &&
bp[j+1] != ' ' &&
bp[j+1] != '\n')
badpun++;
}
}這裏就有個小技巧——使用了 | 040 這個位運算來實現英文字母大小寫的轉換。在 ASCII 碼錶中,英文字母的大寫和小寫只差一個固定的位,這個位就是第 6 位,即 0010 0000,十進制的 32,也就是八進制的 040)。
舉個例子吧,把英文字母 A 的 ASCII 碼(65)與 040 做按位“或”操作,就能把它轉換成小寫字母 a。這樣,不管是大寫還是小寫字母,都會被統一為小寫,方便統計和比較。
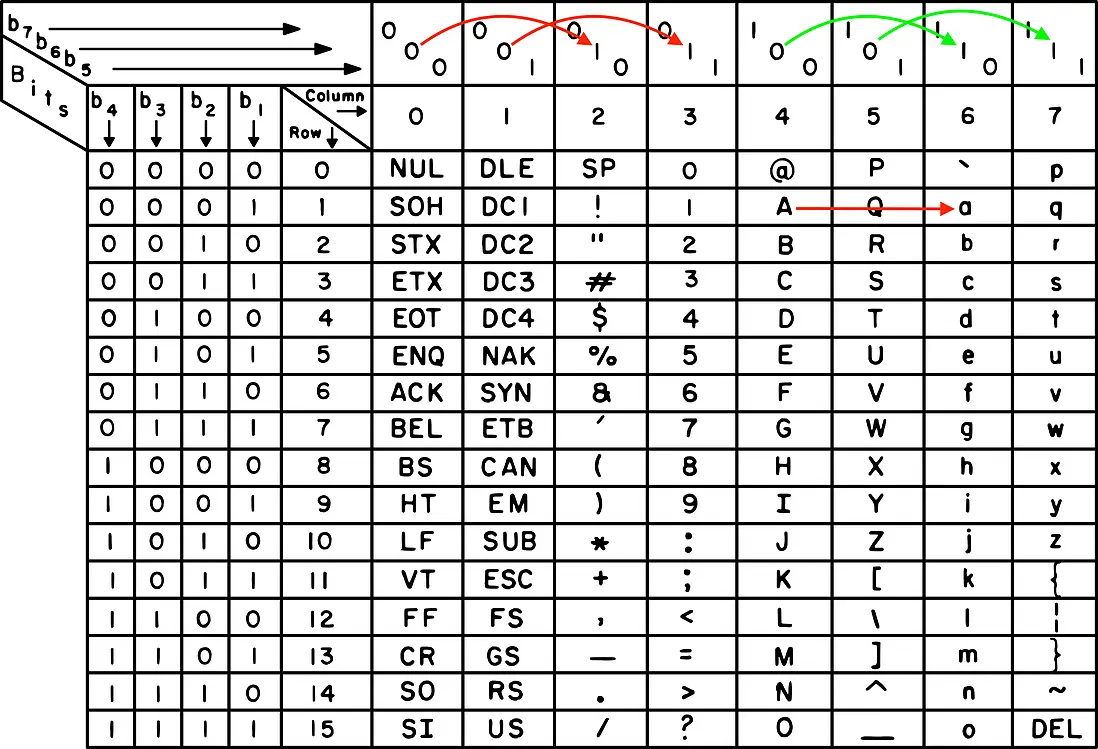
不過,從更嚴謹的角度看,這相當於把 ASCII 碼錶中第 1、2 列的字符分別映射到了第 3、4 列上,把第 5、6 列的字符分別映射到了第 7、8 列上(所以 “)” 和“*”的數量可能虛高)。
規則檢查
好了,現在我們來到了整段代碼的“壓軸環節”——規則檢查部分。
if (badpun*5 > punct)
return(0);
vow = ct['a'] + ct['e'] + ct['i'] + ct['o'] + ct['u'];
freq = ct['e'] + ct['t'] + ct['a'] + ct['i'] + ct['o'] + ct['n'];
rare = ct['v'] + ct['j'] + ct['k'] + ct['q'] + ct['x'] + ct['z'];
if (2*ct[';'] > ct['e']) return(0);
if ( (ct['>']+ct['<']+ct['/'])>ct['e']) return(0); /* shell file test */
return (vow*5 >= n-ct[' '] && freq >= 10*rare);這裏使用了一些簡單的規則,基於以下幾個語言統計特徵來判斷文本是否為英語:
- 不符合書寫規範的標點符號是否過多(> 20%)
- 元音字母
vow的比例 - 高頻英文字母
freq(e、t、a、i、o、n)出現的頻率 - 罕見英文字母
rare(v、j、k、q、x、z)的比例 - 特殊(非自然語言)符號的比例,例如 <、> 等 Shell 腳本中常用的符號
- ……
總之,雖然這些規則未必來自正式的語言統計方面的論文,但它們的確描述了英文的基本結構特徵:一段“像”英語的文本應該足夠長、標點用得得當、元音字母夠多、常用的英文字母佔優勢,而且不能像代碼那樣滿是奇怪的符號。
尾聲:古老代碼中的現代迴響
今天,判斷一段文本屬於哪種語言,早已有了更復雜、更強大的工具。例如基於樸素貝葉斯分類的算法,或利用大量語料庫對各類語言進行概率建模,特別是眼下熱門的大語言模型(LLMs),甚至已經能夠對語言風格、上下文、甚至作者習慣做出精準判斷。
相比之下,1979 年的這段 english() 函數雖然原始,卻展現了早期計算的美學:在資源有限的條件下,用最簡單的方法儘可能準確地解決實際的問題。
回望這段塵封多年的 C 語言代碼,我們依然能感受到它的精巧。就像在展櫃中看到一件鏽跡斑斑的工具,讓人不禁感嘆:“原來當年,已經有人想得這麼遠了啊。”
🔚
🏛️ 遺蹟地址
- https://www.tuhs.org/cgi-bin/utree.pl?file=V7/usr/src/cmd/file.c Unix V7 上的
file命令的源代碼 - https://copy.sh/v86/?profile=unix-v7 Unix V7 模擬器

