

視頻演示
基於深度學習的水下海洋生物檢測系統演示
1. 前言
大家好,歡迎來到 Coding 茶水間。今天要分享的是一個基於 YOLO 算法的水下海洋生物識別系統,它能幫我們快速判斷畫面中出現的海洋生物種類。
這套系統界面清晰、功能齊全,分為左側功能區、中央展示區與右側數據區三大板塊。左側可選取圖片、視頻、批量圖片或攝像頭進行檢測,還能切換不同訓練好的模型;中央區域不僅能實時預覽檢測畫面,還提供置信度與交併比的滑動調節,並顯示檢測耗時與目標數量;右側則會統計各類別數量、支持類別過濾,並以表格形式列出詳細檢測數據,方便導出為 Excel。
我們還會演示從圖片、視頻、文件夾到攝像頭的實時檢測流程,以及結果保存與標註導出的效果。除此之外,系統內置了登錄與個人中心模塊,可進行註冊、修改信息與密碼管理,也支持無界面的腳本批量檢測,並具備完整的模型訓練能力——從數據集劃分、訓練過程到權重輸出與可視化分析,全流程都可在代碼中實現與查看。
接下來,就讓我們一步步走進這個系統的功能細節與使用場景,感受 YOLO 在水下視覺識別中的魅力。
2. 項目演示
2.1 用户登錄界面
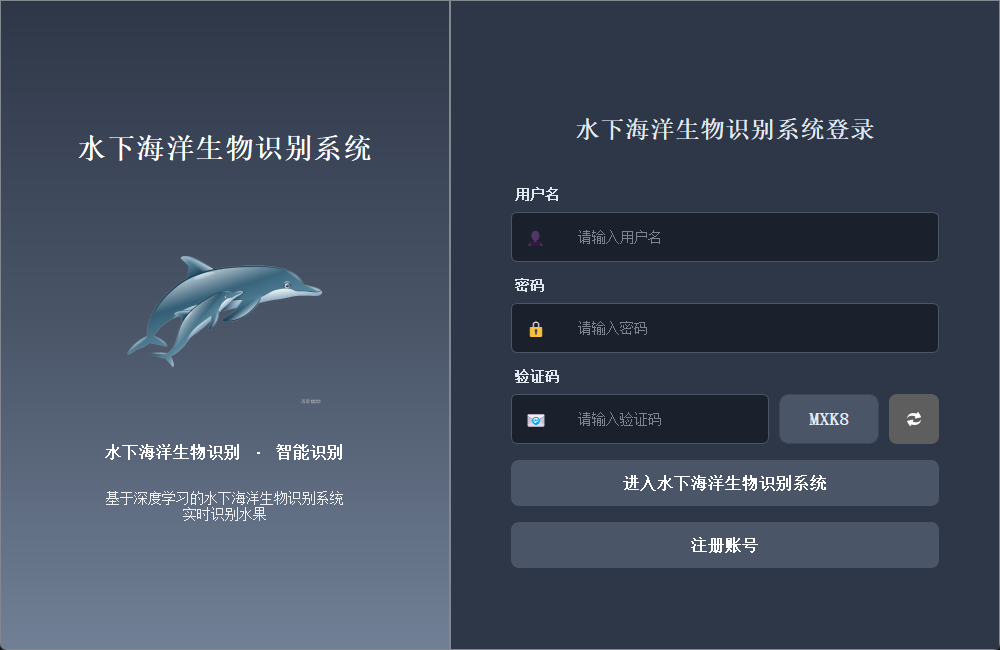
登錄界面佈局簡潔清晰,左側展示系統主題,用户需輸入用户名、密碼及驗證碼完成身份驗證後登錄系統。
2.2 新用户註冊
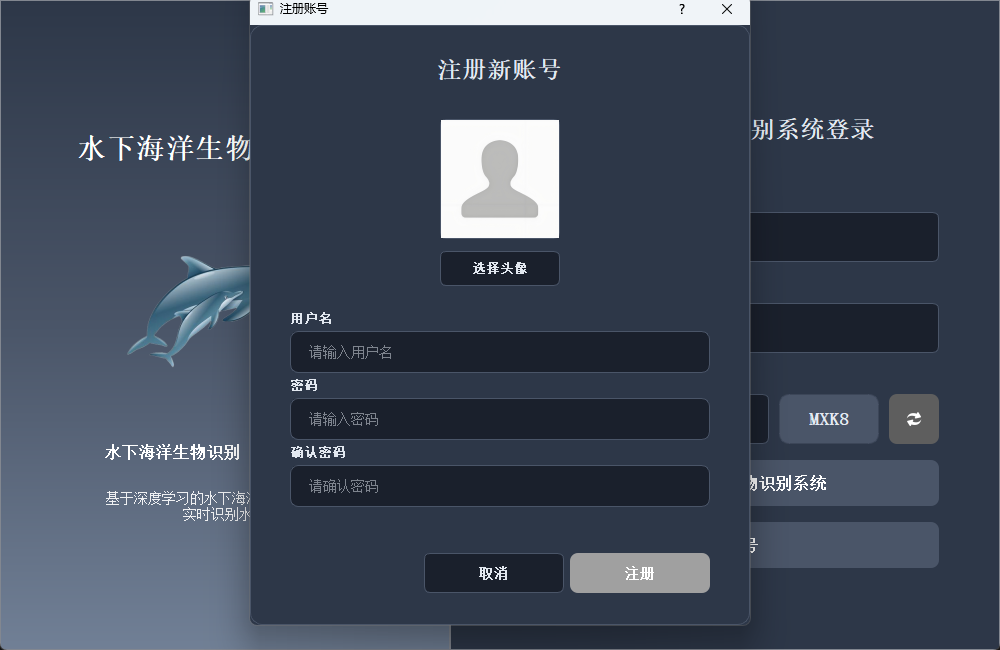
註冊時可自定義用户名與密碼,支持上傳個人頭像;如未上傳,系統將自動使用默認頭像完成賬號創建。
2.3 主界面佈局
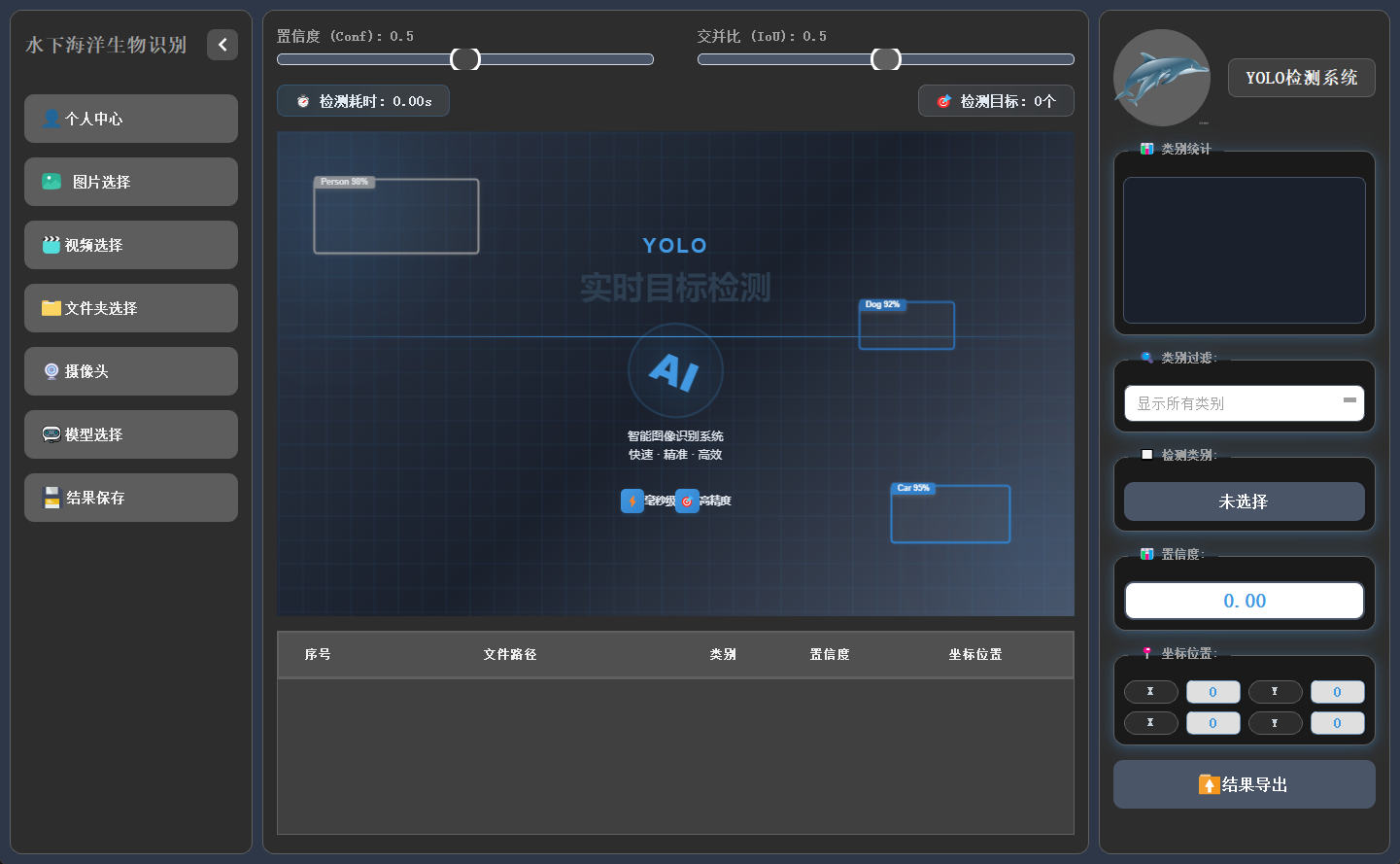
主界面採用三欄結構,左側為功能操作區,中間用於展示檢測畫面,右側呈現目標詳細信息,佈局合理,交互流暢。
2.4 個人信息管理
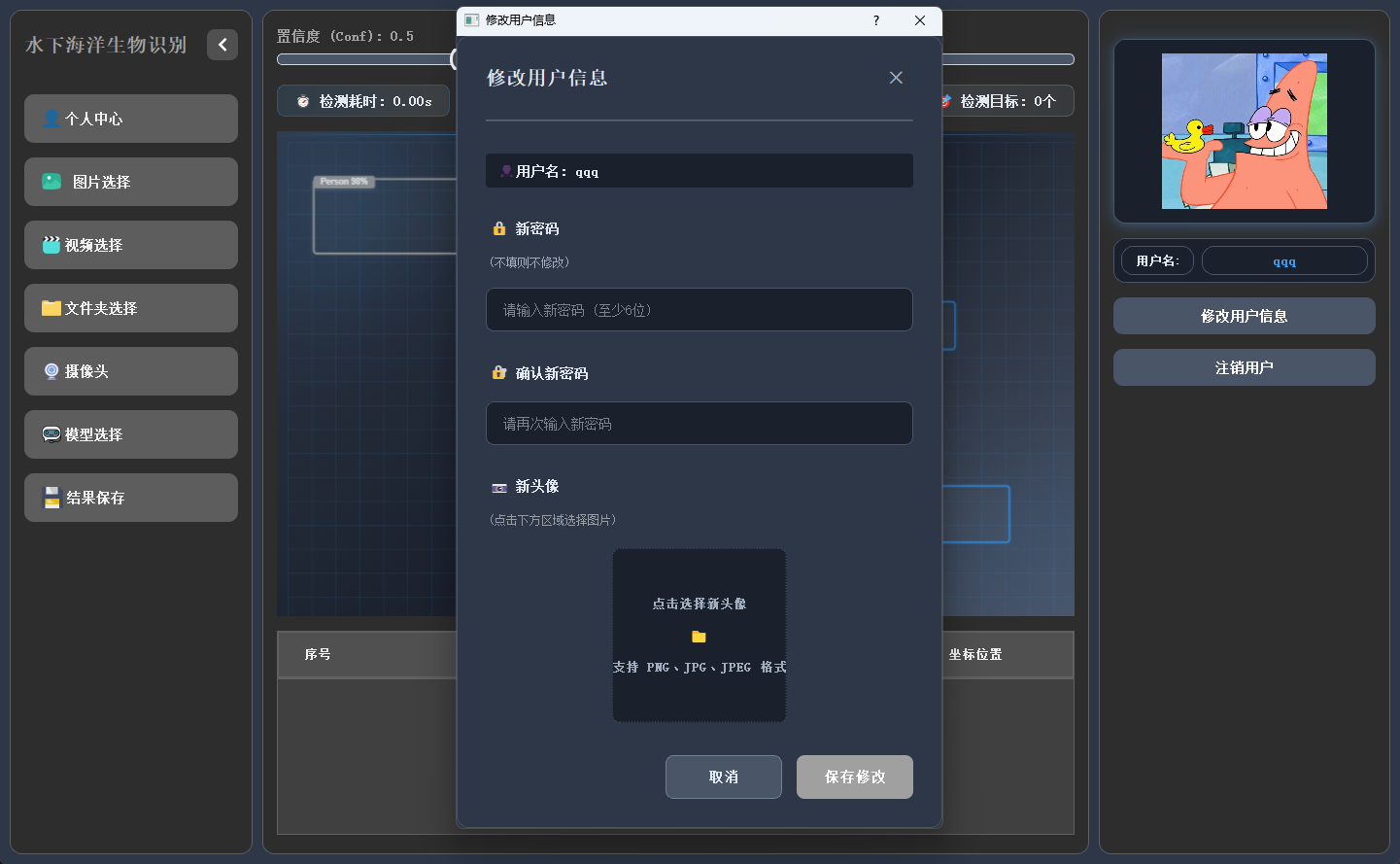
用户可在此模塊中修改密碼或更換頭像,個人信息支持隨時更新與保存。
2.5 多模態檢測展示
系統支持圖片、視頻及攝像頭實時畫面的目標檢測。識別結果將在畫面中標註顯示,並在下方列表中逐項列出。點擊具體目標可查看其類別、置信度及位置座標等詳細信息。
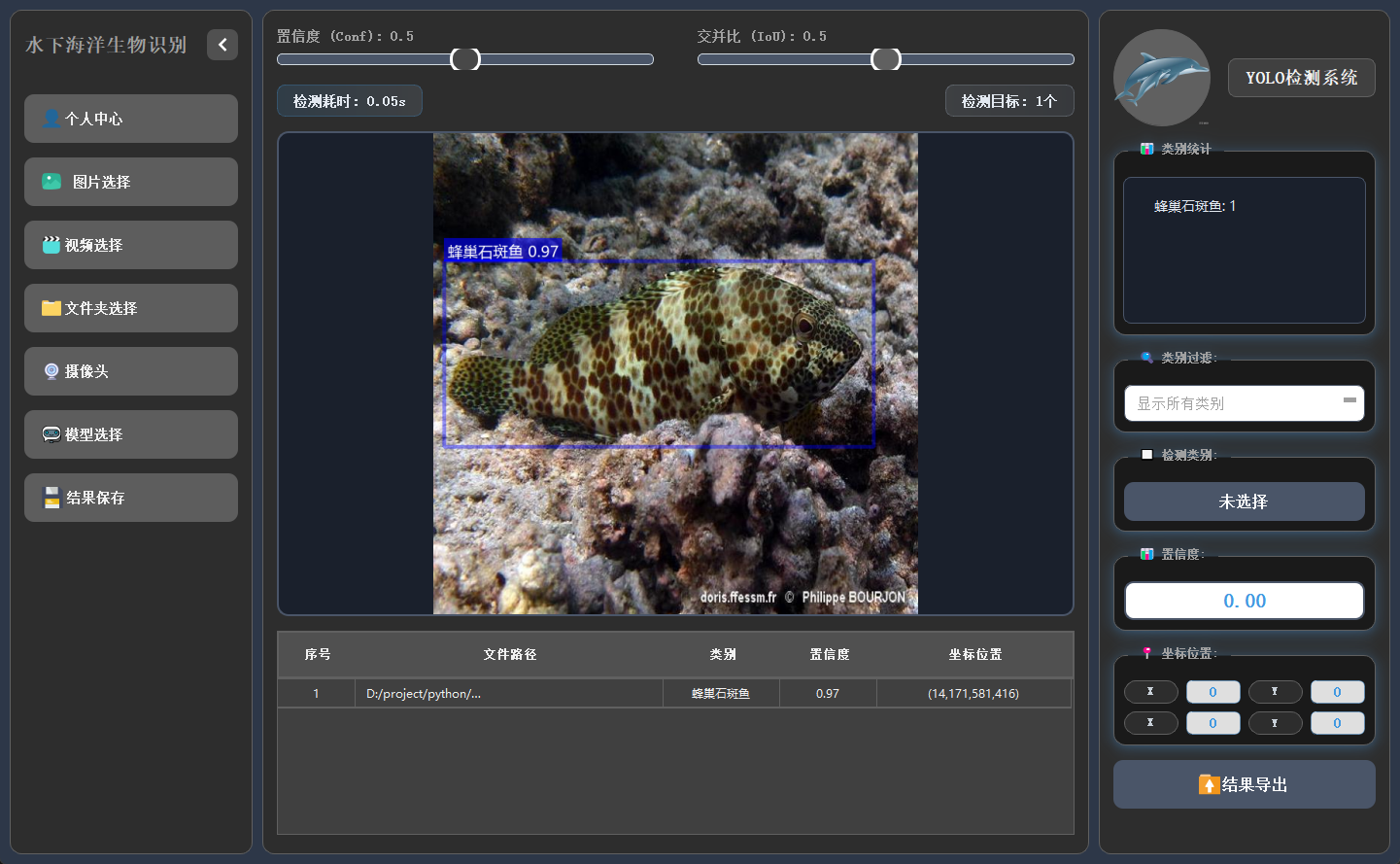
2.6 檢測結果保存
可以將檢測後的圖片、視頻進行保存,生成新的圖片和視頻,新生成的圖片和視頻中會帶有檢測結果的標註信息,並且還可以將所有檢測結果的數據信息保存到excel中進行,方便查看檢測結果。
2.7 多模型切換
系統內置多種已訓練模型,用户可根據實際需求靈活切換,以適應不同檢測場景或對比識別效果。
3.模型訓練核心代碼
本腳本是YOLO模型批量訓練工具,可自動修正數據集路徑為絕對路徑,從pretrained文件夾加載預訓練模型,按設定參數(100輪/640尺寸/批次8)一鍵批量訓練YOLOv5nu/v8n/v11n/v12n模型。
# -*- coding: utf-8 -*-
"""
該腳本用於執行YOLO模型的訓練。
它會自動處理以下任務:
1. 動態修改數據集配置文件 (data.yaml),將相對路徑更新為絕對路徑,以確保訓練時能正確找到數據。
2. 從 'pretrained' 文件夾加載指定的預訓練模型。
3. 使用預設的參數(如epochs, imgsz, batch)啓動訓練過程。
要開始訓練,只需直接運行此腳本。
"""
import os
import yaml
from pathlib import Path
from ultralytics import YOLO
def main():
"""
主訓練函數。
該函數負責執行YOLO模型的訓練流程,包括:
1. 配置預訓練模型。
2. 動態修改數據集的YAML配置文件,確保路徑為絕對路徑。
3. 加載預訓練模型。
4. 使用指定參數開始訓練。
"""
# --- 1. 配置模型和路徑 ---
# 要訓練的模型列表
models_to_train = [
{'name': 'yolov5nu.pt', 'train_name': 'train_yolov5nu'},
{'name': 'yolov8n.pt', 'train_name': 'train_yolov8n'},
{'name': 'yolo11n.pt', 'train_name': 'train_yolo11n'},
{'name': 'yolo12n.pt', 'train_name': 'train_yolo12n'}
]
# 獲取當前工作目錄的絕對路徑,以避免相對路徑帶來的問題
current_dir = os.path.abspath(os.getcwd())
# --- 2. 動態配置數據集YAML文件 ---
# 構建數據集yaml文件的絕對路徑
data_yaml_path = os.path.join(current_dir, 'train_data', 'data.yaml')
# 讀取原始yaml文件內容
with open(data_yaml_path, 'r', encoding='utf-8') as f:
data_config = yaml.safe_load(f)
# 將yaml文件中的 'path' 字段修改為數據集目錄的絕對路徑
# 這是為了確保ultralytics庫能正確定位到訓練、驗證和測試集
data_config['path'] = os.path.join(current_dir, 'train_data')
# 將修改後的配置寫回yaml文件
with open(data_yaml_path, 'w', encoding='utf-8') as f:
yaml.dump(data_config, f, default_flow_style=False, allow_unicode=True)
# --- 3. 循環訓練每個模型 ---
for model_info in models_to_train:
model_name = model_info['name']
train_name = model_info['train_name']
print(f"\n{'='*60}")
print(f"開始訓練模型: {model_name}")
print(f"訓練名稱: {train_name}")
print(f"{'='*60}")
# 構建預訓練模型的完整路徑
pretrained_model_path = os.path.join(current_dir, 'pretrained', model_name)
if not os.path.exists(pretrained_model_path):
print(f"警告: 預訓練模型文件不存在: {pretrained_model_path}")
print(f"跳過模型 {model_name} 的訓練")
continue
try:
# 加載指定的預訓練模型
model = YOLO(pretrained_model_path)
# --- 4. 開始訓練 ---
print(f"開始訓練 {model_name}...")
# 調用train方法開始訓練
model.train(
data=data_yaml_path, # 數據集配置文件
epochs=100, # 訓練輪次
imgsz=640, # 輸入圖像尺寸
batch=8, # 每批次的圖像數量
name=train_name, # 模型名稱
)
print(f"{model_name} 訓練完成!")
except Exception as e:
print(f"訓練 {model_name} 時出現錯誤: {str(e)}")
print(f"跳過模型 {model_name},繼續訓練下一個模型")
continue
print(f"\n{'='*60}")
print("所有模型訓練完成!")
print(f"{'='*60}")
if __name__ == "__main__":
# 當該腳本被直接執行時,調用main函數
main()4. 技術棧
-
語言:Python 3.10
-
前端界面:PyQt5
-
數據庫:SQLite(存儲用户信息)
-
模型:YOLOv5、YOLOv8、YOLOv11、YOLOv12
5. YOLO模型對比與識別效果解析
5.1 YOLOv5/YOLOv8/YOLOv11/YOLOv12模型對比
基於Ultralytics官方COCO數據集訓練結果:
|
模型 |
尺寸(像素) |
mAPval 50-95 |
速度(CPU ONNX/毫秒) |
參數(M) |
FLOPs(B) |
|---|---|---|---|---|---|
|
YOLO12n |
640 |
40.6 |
- |
2.6 |
6.5 |
|
YOLO11n |
640 |
39.5 |
56.1 ± 0.8 |
2.6 |
6.5 |
|
YOLOv8n |
640 |
37.3 |
80.4 |
3.2 |
8.7 |
|
YOLOv5nu |
640 |
34.3 |
73.6 |
2.6 |
7.7 |
關鍵結論:
-
精度最高:YOLO12n(mAP 40.6%),顯著領先其他模型(較YOLOv5nu高約6.3個百分點);
-
速度最優:YOLO11n(CPU推理56.1ms),比YOLOv8n快42%,適合實時輕量部署;
-
效率均衡:YOLO12n/YOLO11n/YOLOv8n/YOLOv5nu參數量均為2.6M,FLOPs較低(YOLO12n/11n僅6.5B);YOLOv8n參數量(3.2M)與計算量(8.7B)最高,但精度優勢不明顯。
綜合推薦:
-
追求高精度:優先選YOLO12n(精度與效率兼顧);
-
需高速低耗:選YOLO11n(速度最快且精度接近YOLO12n);
-
YOLOv5nu/YOLOv8n因性能劣勢,無特殊需求時不建議首選。
5.2 數據集分析
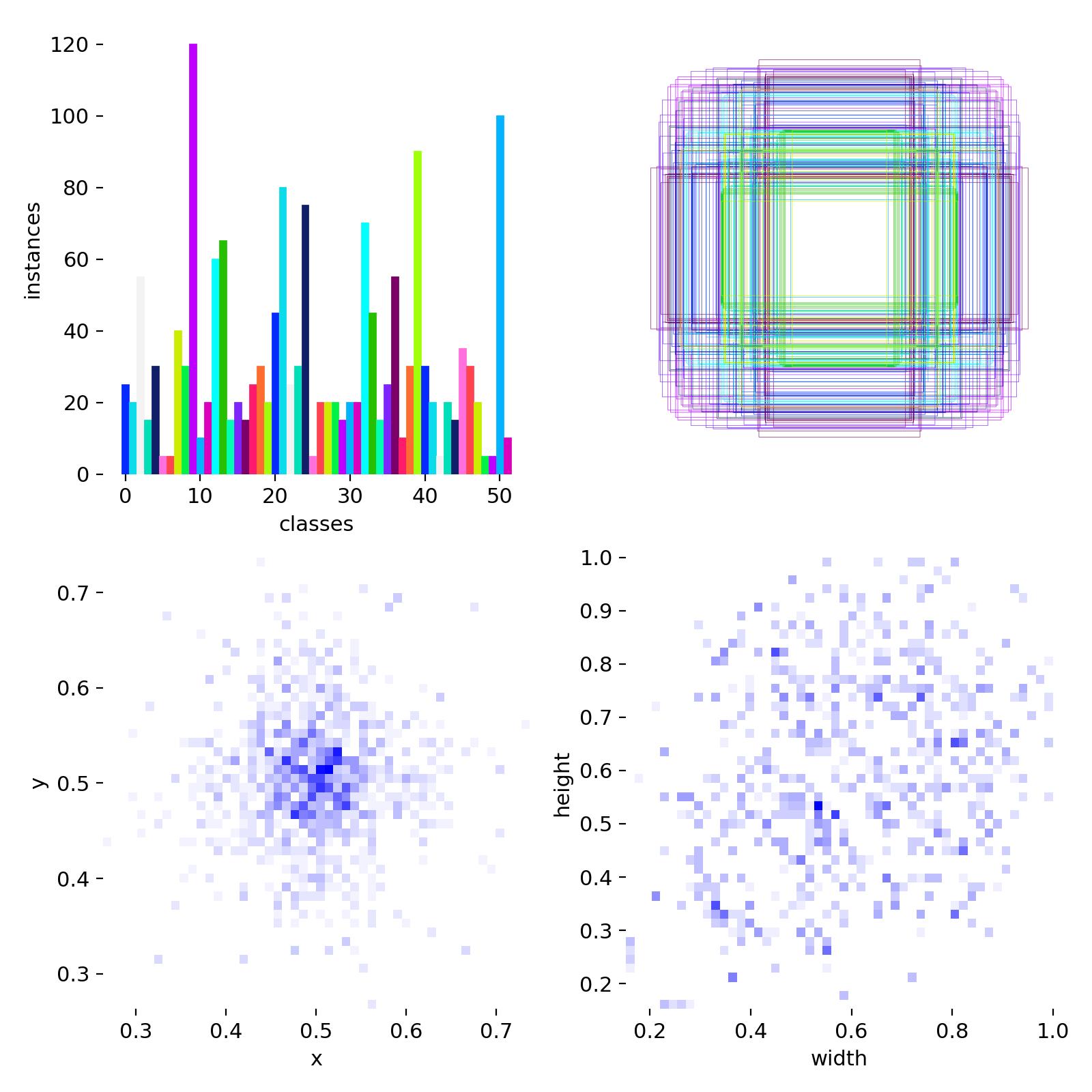
數據集中訓練集和驗證集一共1700張圖片,數據集目標類別兩種:正常腎臟,腎結石,數據集配置代碼如下:
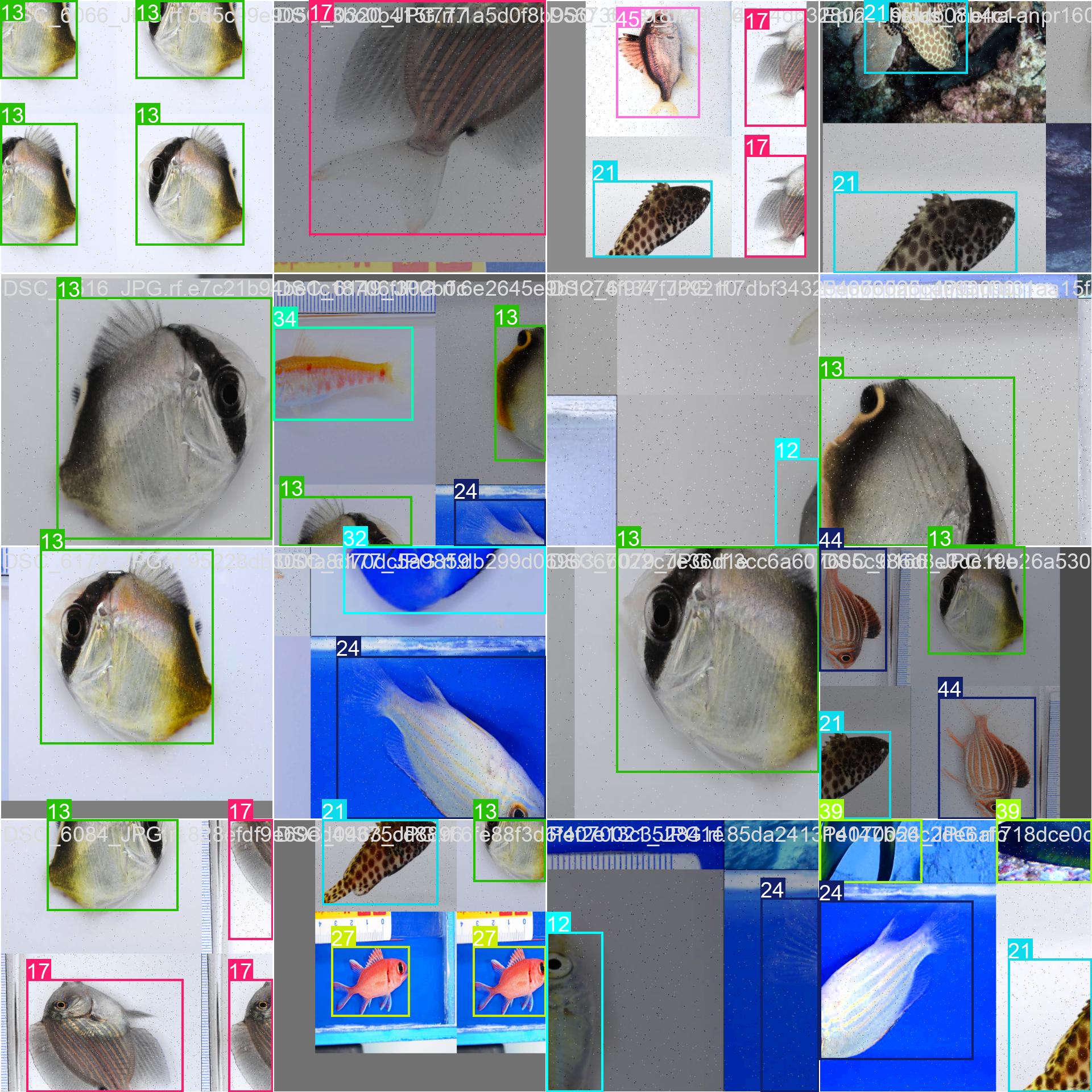

上面的圖片就是部分樣本集訓練中經過數據增強後的效果標註。
5.3 訓練結果
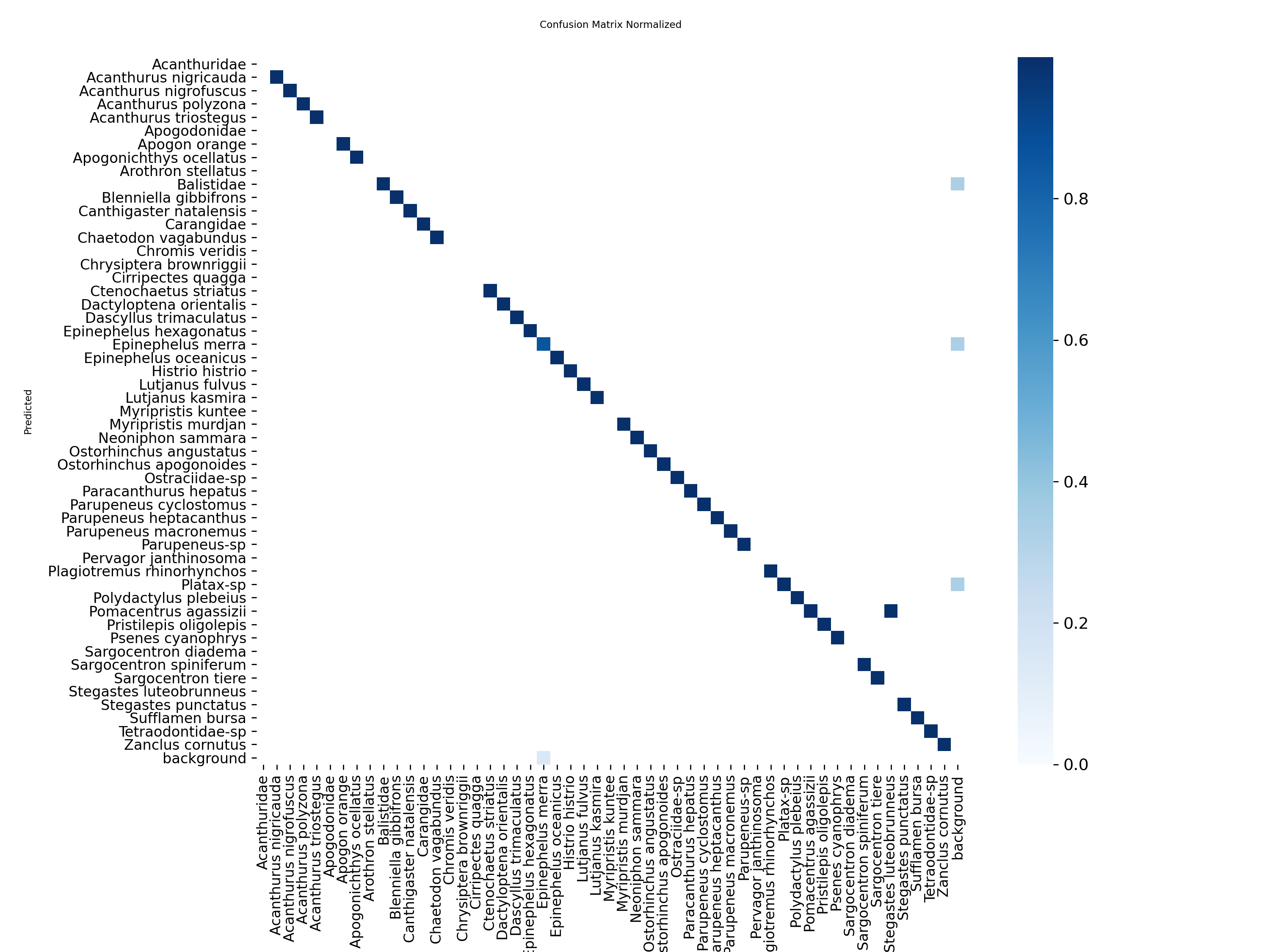
混淆矩陣顯示中識別精準度顯示是一條對角線,方塊顏色越深代表對應的類別識別的精準度越高。
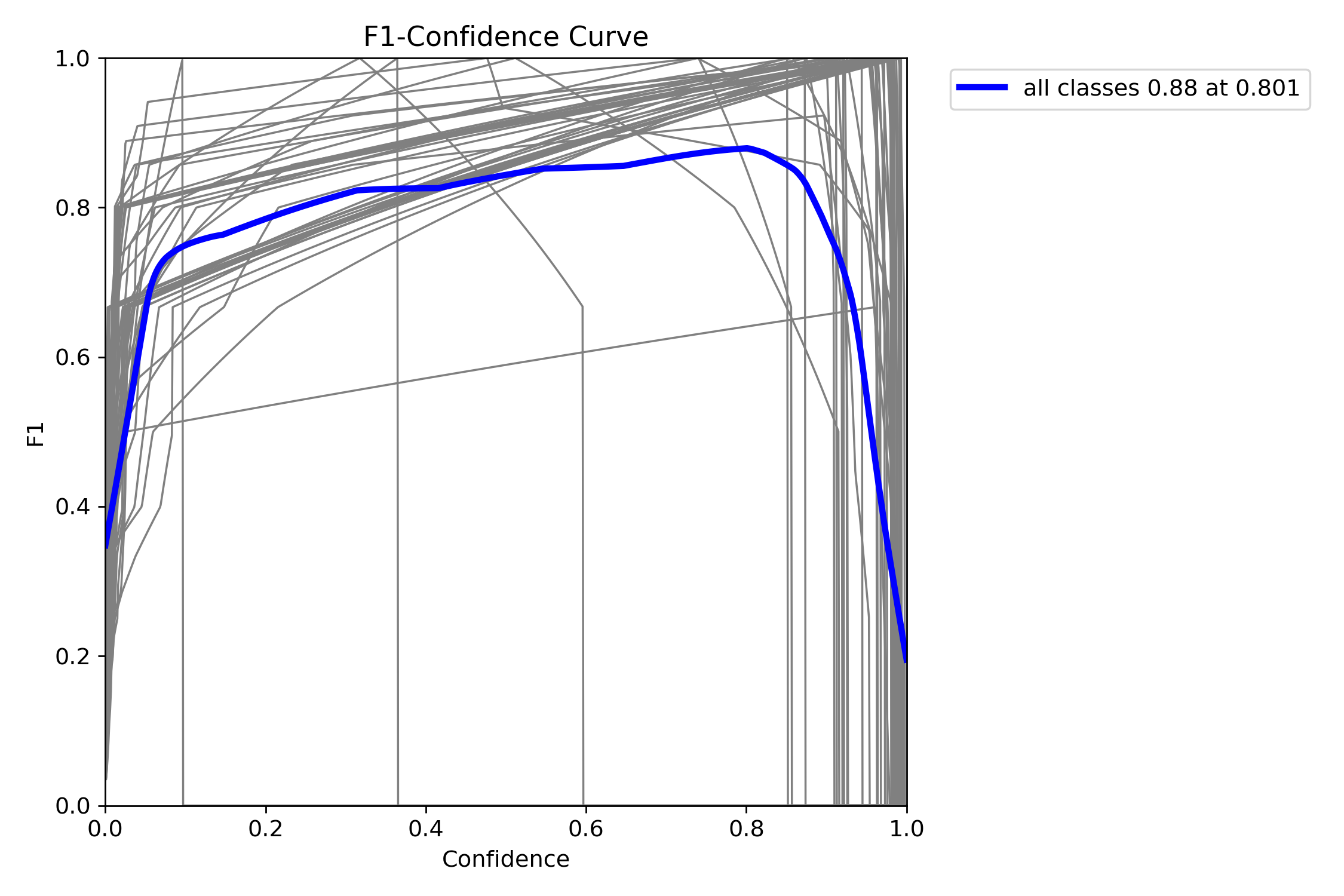
F1指數(F1 Score)是統計學和機器學習中用於評估分類模型性能的核心指標,綜合了模型的精確率(Precision)和召回率(Recall),通過調和平均數平衡兩者的表現。
當置信度為0.801時,所有類別的綜合F1值達到了0.88(藍色曲線)。
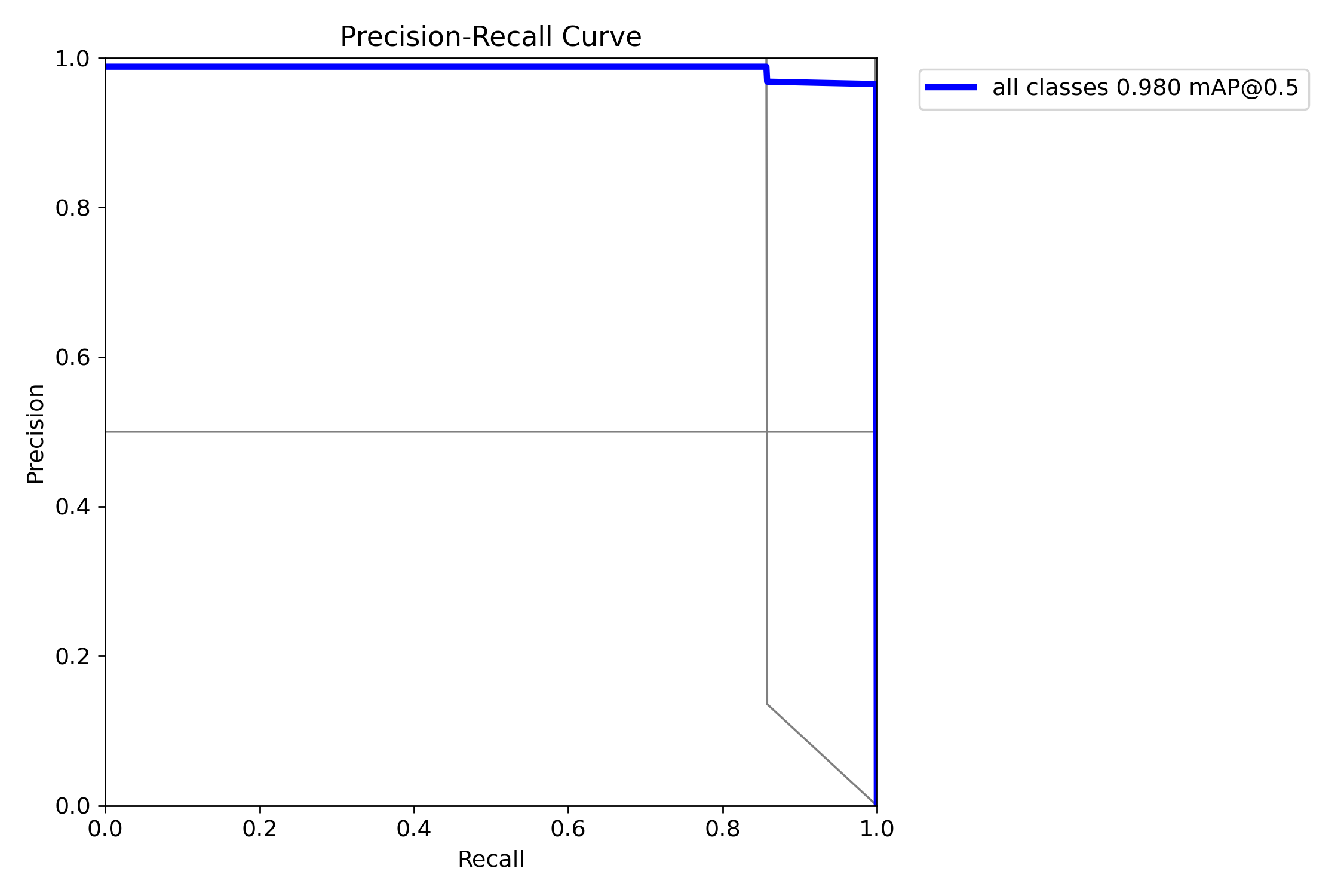
mAP@0.5:是目標檢測任務中常用的評估指標,表示在交併比(IoU)閾值為0.5時計算的平均精度均值(mAP)。其核心含義是:只有當預測框與真實框的重疊面積(IoU)≥50%時,才認為檢測結果正確。
圖中可以看到綜合mAP@0.5達到了0.980(98.0%),準確率非常高。
6. 源碼獲取方式
源碼獲取方式:https://www.bilibili.com/video/BV1Za2xBJEQv