

在軟件開發之中,高效、精準地理解代碼是至關重要的環節,尤其當面對一個包含幾十萬行代碼、上千個文件 的龐大項目時,這一挑戰尤為嚴峻。一個典型且棘手的場景是:從一個龐雜的代碼庫中,快速識別並提取出 300 多個對外暴露的 API 及其詳細定義。傳統的代碼分析方法面對這個場景往往力不從心。
本文根據字節跳動服務框架團隊研發工程師尹旭然在 CloudWeGo 四週年技術沙龍上的演講內容整理,詳細介紹如何通過結合 ABCoder (AI-Based Coder) 與 Deep Code Research,使模型能夠像人類專家一樣深度解析代碼,從而有效破解大規模代碼庫的理解難題。
一、傳統代碼分析方法的困境
當前,主流的大模型或 Agent 在執行代碼理解任務時,其"原料"(即代碼上下文信息)的獲取方式主要依賴以下兩種方法:
- 語義化搜索:通過將項目代碼轉化為向量化知識庫,並利用語義相似性進行搜索。這種方法的精確度有限,雖然結果相關,但並非團隊真正想找的目標。
- 關鍵字匹配:直接在代碼文本中進行關鍵字搜索。此方法雖然直接,但嚴重依賴代碼的字面表達,極易因缺乏上下文而遺漏關鍵信息或被無關內容干擾。
這些方法提供的"原料"往往精度不足,夾雜大量冗餘信息。當模型處理這些低質量數據時,其有限的上下文窗口和注意力機制會被迅速佔用,進而導致分析精度顯著下降。
二、解決方案:模擬人類專家的代碼解讀模式
面對傳統方法的侷限,團隊迴歸本源,深入思考一名經驗豐富的開發者是如何解決這類問題的。通常,他會從應用程序的入口函數(main 函數)着手,定位到註冊路由的關鍵節點(如 Router 或 Register 相關邏輯),然後沿着調用鏈層層深入,逐一追蹤,最終精確地找到所有 API 的定義及其實現。
這個過程並非基於模糊的搜索,而是一種結構化的、循序漸進的深度探索。這一思路為團隊提供了核心啓發:讓模型模擬人類專家的思維模式去走讀和理解代碼。基於此,團隊提出了結合 ABCoder 和 Deep Code Research 的解決方案。
2.1 精準的"原料":ABCoder
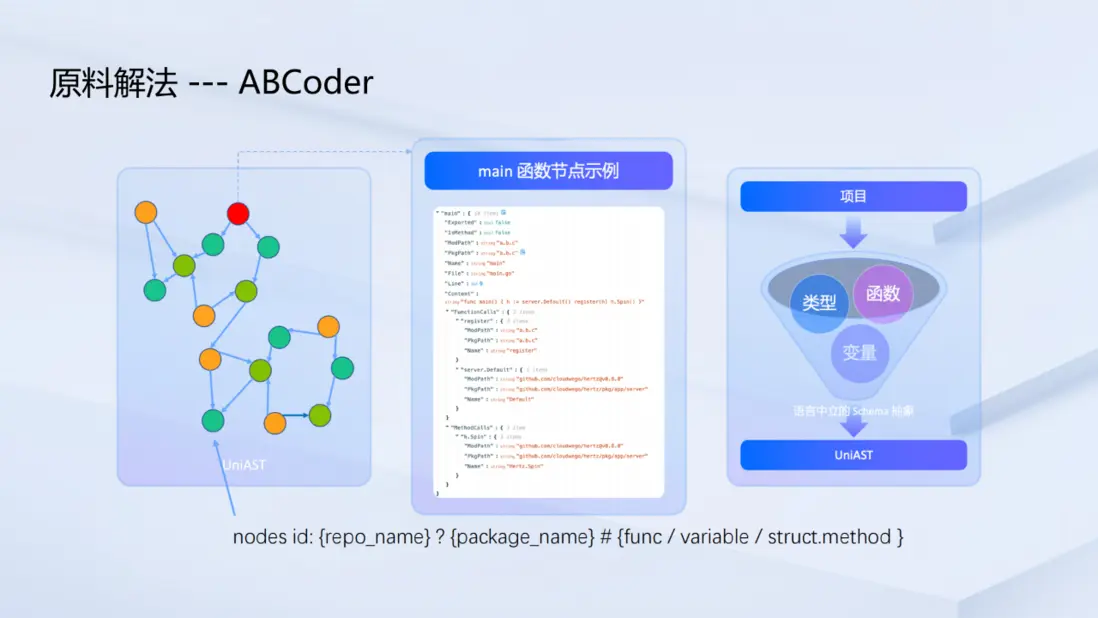
為從根本上解決"原料"的純度問題,團隊引入了 ABCoder 。它的核心理念是將整個項目代碼抽象為一個語言無關的抽象語法樹(UniAST),並具備以下特點:
- 節點化:代碼中的變量、函數、方法等基本單元被抽象成獨立的"節點"。
- 唯一標識 :每個節點都擁有一個唯一的 ID(
node id),允許系統通過該 ID 進行精準定位。 -
精確上下文:通過定位一個節點,團隊可以獲取其完整的、無冗餘的上下文信息,包括:
- 源代碼:該函數或方法的精確代碼範圍。
- 調用關係:該函數調用了哪些依賴,以及它被哪些其他函數所調用。
通過這種方式,原本分散的代碼文件被重構為一張結構化、相互連接的"代碼圖"。分析時,團隊可以從任意一個起始節點(如 main 函數對應的節點)出發,沿着調用關係進行深度探索,直至發掘出所有相關信息。這為代碼的深度理解提供了前所未有的高質量"原料"。
2.2 優化的流程:Deep Code Research

僅有精準的"原料"尚不足以解決問題,因為無限制的深度探索同樣會導致上下文溢出。因此,團隊設計了 Deep Code Research 流程對分析過程進行優化。
- 引入 Knowledge 機制,提升信息密度 :團隊在傳統大模型的 Actions 架構之上,增設了一個 Knowledge 模塊。在探索過程中,系統會動態評估信息的相關性,僅將對當前任務至關重要的信息存入
Knowledge模塊。這意味着每一步分析都基於一份小而精的知識集,從而極大地提升了信息密度與分析效率。 -
任務分解,化繁為簡:團隊將宏觀、複雜的任務分解為一系列更小、更具體的子任務。例如,將"找出所有暴露的 API 及其接口詳情"這一複雜請求,拆解為兩個步驟:
- 任務一:找出項目中所有 API 的聲明或註冊列表。
- 任務二 :基於第一步的產出,為每一個 API 單獨創建子任務,以獲取其詳細的實現邏輯。
通過這種"化整為零"的策略,模型的處理壓力得到有效緩解,其注意力也更為集中,最終顯著提升了分析的準確性與深度。
三、案例對比:查找工廠類的實現
為了直觀地展示該方案的有效性,團隊以"查找工廠類(Factory Pattern)實現"這一具體場景進行對比。
- 傳統方法 (Grep/Search) :嚴重依賴關鍵詞匹配。在執行過程中,它會反覆調用
search工具,嘗試使用不同的關鍵詞進行搜索。如果項目代碼的語義化表達不佳,這種方式極有可能陷入無效的遞歸搜索循環,難以獲得準確結果。 -
ABCoder + Deep Code Research
- 精準定位 :通過
get nodes detail工具直接獲取main函數的精確上下文,包括其依賴的函數列表。 - 深入追查 :模型根據入口信息,識別出需要進一步檢查
register函數,並沿着調用鏈持續深入。在追查過程中,模型能夠精確識別出項目所使用的 Web 框架(如 Hertz),並定位到具體的 Handler 實現。 - 得出結論:Deep Code Research 迅速完成分析,並輸出其提煉的完整知識,最終精確定位了工廠模式的具體實現。
- 精準定位 :通過
四、落地成果與未來展望
4.1 知識庫的多維度增強
團隊將 ABCoder 與 Deep Code Research 的能力應用於構建多維度增強知識庫。 如果説從代碼中提取的基礎信息,如變量、函數、接口及其調用關係等是製作麪包的"麪粉",那麼通過 Deep Code Research 的深度加工,團隊便能得到藴含更高價值的"麪包"------即高階領域知識。
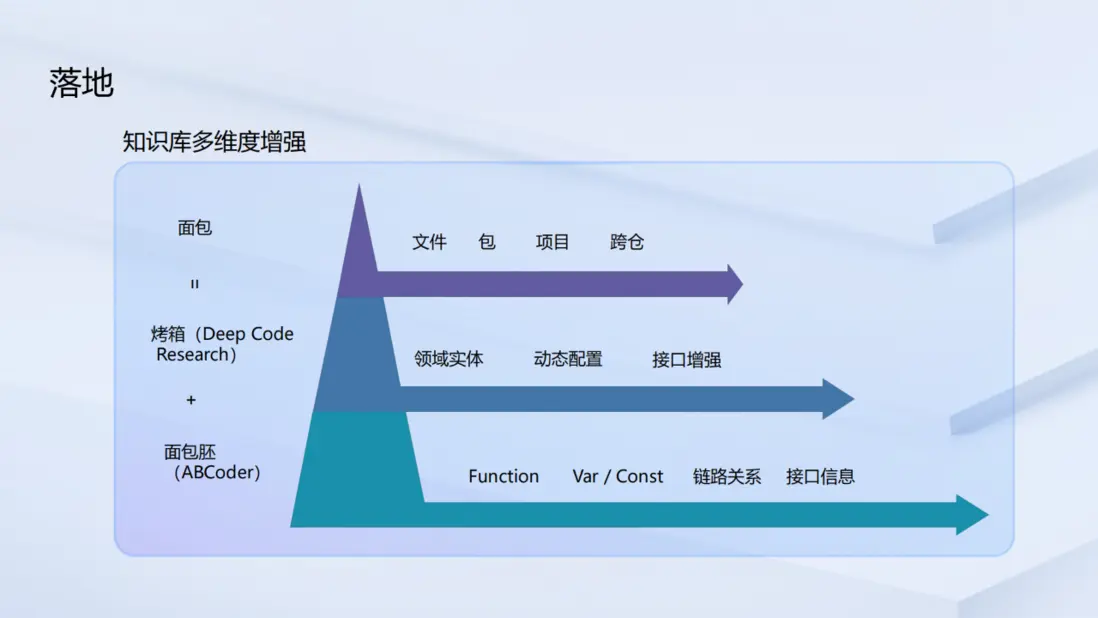
其過程如下:
- 基礎信息構建:提取項目中的基礎信息,構建出"代碼知識圖譜"。
- 高階知識提煉:通過 Deep Code Research 對這些基礎信息進行深度分析與加工,提煉出更高維度的領域知識,如領域實體、動態配置、接口間的深層依賴等。
- 關鍵信息整合:團隊得到項目粒度的關鍵信息摘要,甚至能夠構建出跨代碼倉庫的全局依賴視圖。
例如,傳統方法難以追蹤一個服務中的字段變更對其他服務產生的具體影響。而通過 Deep Code Research,團隊可以清晰地刻畫數據流,從而精確評估變更的影響範圍。同樣,對於那些在長期迭代中註釋缺失的字段,團隊也能通過分析其在代碼中的實際使用邏輯,反向推導出其確切含義與默認值。
此外,該技術已在火焰圖分析 、系統穩定性分析 、自動化 Code Review 等多個領域展開了落地探索。
4.2 從 AI Coding 到 AI Development

團隊的最終願景,是推動 AI 在軟件工程中的角色從 AI Coding 邁向 AI Development,讓 AI 不再只是輔助編寫代碼的工具,而是能夠深度參與並貫穿軟件開發的全生命週期。藉助結構化的代碼表徵(ABCoder)與深度的邏輯提煉(Deep Code Research),團隊相信可以持續為業務賦能,在大幅提升研發效率的同時實現真正的降本增效。