

天氣預報的精準度和預見期,直接影響災害防禦、農業生產和全球資源調度。從短時預警到季節乃至更長期的氣候預測,每延長一步,技術挑戰都成倍增加。傳統數值預報發展多年後,AI 為這一領域帶來了新動力。近年來,AI 天氣預報模型已在中期預報上取得突破,其性能媲美甚至超越了先進的傳統動力模式。
目前主流 AI 氣象模型多采用自迴歸架構,其原理是逐步推演,通過學習歷史數據中的短期大氣變化規律,預測未來幾小時的狀態。這種模型在中期預報中表現出色,但在向次季節至季節(S2S)等長期尺度拓展時,遇到了根本性瓶頸。
長期預報需依賴概率方法,而自迴歸模型只能通過反覆迭代進行多步預測,導致誤差不斷累積,且難以校準。其核心矛盾在於:訓練目標是學習短期規律,而長期預報需要構建能夠刻畫氣候慢變率的概率模型。
為突破此侷限,研究者開始探索單步長預測新路徑。但新問題隨之而來:基於現有再分析數據訓練長期單步模型時,會因數據樣本稀少而嚴重過擬合,模型可靠性無法保證。
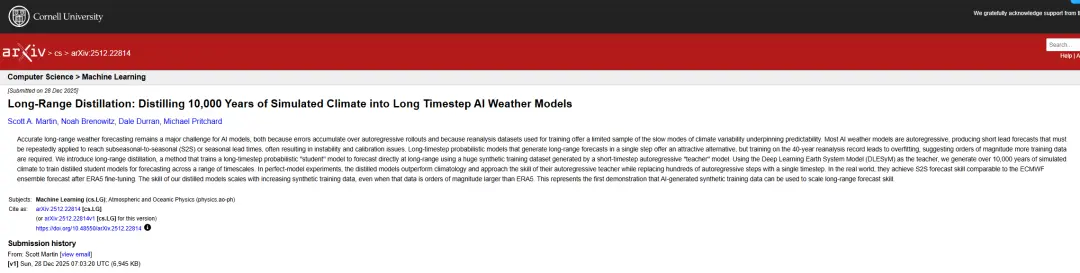
在此背景下,英偉達研究院聯合華盛頓大學的研究團隊推出了一種長距離蒸餾(Long-Range Distillation)新方法,其核心思路是利用擅長生成真實大氣變率的自迴歸模型作為「教師」,通過其低成本、快速模擬產生海量合成氣象數據;再用這些數據訓練一個概率化的「學生」模型。學生模型僅需單步計算即可生成長期預報,既避免了迭代誤差累積,也繞過了複雜的數據校準難題。
這一方法脱離自迴歸建模框架,轉而將大規模氣候數據壓縮為條件生成模型,突破了以往訓練數據有限的制約。研究中採用能穩定模擬百年氣候的自迴歸耦合模型作為教師,生成了規模遠超真實記錄的訓練樣本。初步實驗表明,基於此訓練出的學生模型,在 S2S 預報上與 ECMWF 集成預報系統相當,且其性能隨合成數據量增加而持續提升,有望在未來實現更可靠、更經濟的氣候尺度預測。
相關研究成果以「Long-Range Distillation: Distilling 10,000 Years of Simulated Climate into Long Timestep AI Weather Models」為題,已發表於 arXiv 。
研究亮點:
* 突破真實觀測數據時長限制,利用 AI 氣象模型生成超萬年合成氣候數據,使模型能夠學習實際觀測中未曾充分呈現的慢變氣候模態;
* 提出長距離蒸餾方法,僅需單步計算即可輸出長期概率預報的模型,克服了傳統自迴歸框架中數百步迭代導致的誤差累積與不穩定問題;
* 經真實世界數據適配後,模型在次季節至季節預報上的技巧,已達到歐洲中期天氣預報中心業務系統的相當水平。
論文地址:
https://arxiv.org/abs/2512.22814
關注公眾號,後台回覆「長距離蒸餾」獲取完整 PDF
更多 AI 前沿論文:
https://hyper.ai/papers
數據集:合成氣候數據的生成、劃分與評估框架
在評估長距離蒸餾模型的跨時效集成預報能力時,該研究首先在受控的理想模型實驗中進行驗證。所有評估數據均取自自迴歸教師模型 DLESyM(Deep Learning Earth System Model)預留的模擬數據,且在蒸餾模型的訓練過程中從未被使用。這一設置的核心目的,是檢驗在初始條件未完全確定的情況下,蒸餾長步長模型與 DLESyM 教師模型對未見模擬天氣的預報表現,確保評估的客觀性。
評估不僅採用了集成均方根誤差(RMSE)等確定性指標,還引入了連續排序概率評分(CRPS)這一概率預報評估工具,以更全面地衡量預報性能。研究人員選取了 3 個具有不同可預測性機制的預報時效進行測試:
* 中期時效:
針對 7 天的日平均預報(參數 N=28, M=4),使用 2017 年 1 月 1 日至 2019 年 3 月 10 日(模擬年)的預留數據,每 2 天選取一個初始日期,共 400 餘個樣本。
* S2S 時效:
針對 4 周的周平均預報(參數 N=112, M=28),使用 2017 年 1 月 1 日至 2021 年 5 月 16 日(模擬年)的數據,每 4 天一個初始日期,樣本量同樣超過 400 個。
* 季節時效:
針對 12 周的月平均預報(參數 N=336, M=112),使用 2017 年 1 月 1 日至 2025 年 9 月 28 日(模擬年)的數據,每 8 天選取初始日期,樣本數約 400 個。
為確保獨立性,研究人員將由 DLESyM 生成的總計約 15,000 年合成氣候模擬數據,按集合成員維度劃分為訓練集(75%,約 11,000 年)和驗證集(25%),併為每個預報時效訓練了獨立的蒸餾模型。這些合成數據的生成採用了並行化策略:在 2008 年 1 月 1 日至 2016 年 12 月 31 日期間均勻選取 200 個初始日期,每個日期對應進行 90 年模擬,從而獲得總時長 18,000 年的氣候數據。
該研究的最終目標是將訓練好的模型應用於真實世界長期預報。需要注意的是,DLESyM 長期運行形成的「模型氣候」與真實氣候存在差異。因此,將模型遷移至真實應用時,需重點解決這一「域轉移」問題。
長距離蒸餾:「數據蒸餾」與「概率校準」的雙重創新
長距離蒸餾方法的創新思路在於,它利用一個能夠穩定長期運行的短步長自迴歸模型作為「教師」,來訓練一個僅需單步計算即可輸出長期預報的「學生」模型。這從根本上避免了傳統自迴歸框架中數百步迭代所帶來的誤差累積問題。
具體而言,研究人員從教師模型的長期滾動序列中定義長期預報目標,即未來某一時間窗口內狀態的平均值。學生模型則直接學習從初始狀態到該長期目標的條件概率分佈。教師模型的核心價值在於其高效生成海量合成數據的能力,這些數據的規模遠超原始再分析數據,從而解決了長期預報訓練樣本稀缺的難題。
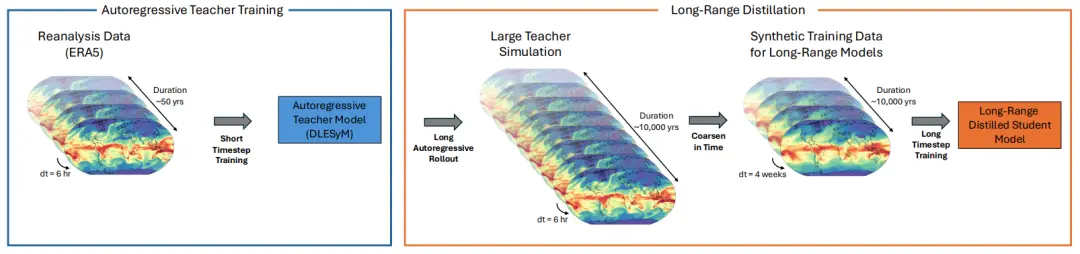
長距離蒸餾示意圖
為實現這一目標,該研究採用 DLESyM 模型作為「教師」。該模型基於 ERA5 再分析數據初始化,預報關鍵變量如海温、氣温和位勢高度等。研究人員設計了高效的數據生成策略:從 2008 至 2016 年間均勻選取 200 個初始日期,並行開展為期 90 年的模擬,總計得到 18,000 年的合成氣候數據。在強大算力支持下,數據生成過程僅耗時數小時,充分體現了 AI 氣候模擬的效率優勢。經過質量篩選,約 15,000 年的有效數據被用於後續模型的訓練與驗證。
「學生」模型採用條件擴散模型架構,專門為概率預報而設計。其目標是建模未來長期天氣狀態與輸入條件(如前 4 天的日平均狀態)之間的複雜關係。模型架構基於一個適配於 HEALPix 網格的 UNet 網絡改進而成,通過引入可學習的空間嵌入和週期性的時間嵌入,以有效捕捉全球天氣場的時空依賴特性。在訓練中,研究人員採用特定的噪聲調度策略,以確保模型能學習到數據中所有尺度的特徵。
為精確校準概率預報的不確定性,本研究創新性地引入了「無分類器引導(Classifier-Free Guidance)」,允許在模型推理階段通過調節一個簡單的權重參數,靈活控制預報集合的離散度,使其與預報誤差達到最佳平衡,從而便捷地生成校準良好的概率預報。
為使模型能夠勝任真實世界的預報任務,該研究針對「域轉移(domain shift)」問題實施了雙重策略。一是進行氣候偏差訂正,修正模擬數據與真實觀測在平均態上的系統性差異;二是利用有限的 ERA5 再分析數據對模型進行微調,僅更新網絡中的部分關鍵參數,使模型在保留從海量合成數據中學到規律的同時,更好地適應真實大氣的特徵。最終,通過與歐洲中期天氣預報中心(ECMWF)等頂尖業務系統的對比,評估了模型在真實場景中的競爭力。
多維度突破,數據可擴展、預報可校準、技能可比肩頂尖業務系統
通過系列實驗,該研究圍繞訓練數據規模的影響、預報不確定性的校準、多時效預報技能,以及與業務系統的對標四個方向,系統地驗證了長距離蒸餾模型的性能與潛力。
首先,該研究驗證了核心假設——增加合成訓練數據量能顯著提升模型預報能力。如下圖所示,該研究使用僅 40 年模擬數據訓練的模型很快出現過擬合,而基於約 1.1 萬年合成數據訓練的模型(簡稱 DLESyM10K)則表現出穩定的學習曲線。更重要的是,數據量的增長直接轉化為預報技能的提升:在 4 周氣温預報中,CRPS 評分降低了 14% 。這首次證明,利用自迴歸模型生成大規模合成數據,可有效構建更強大的長期預報模型。
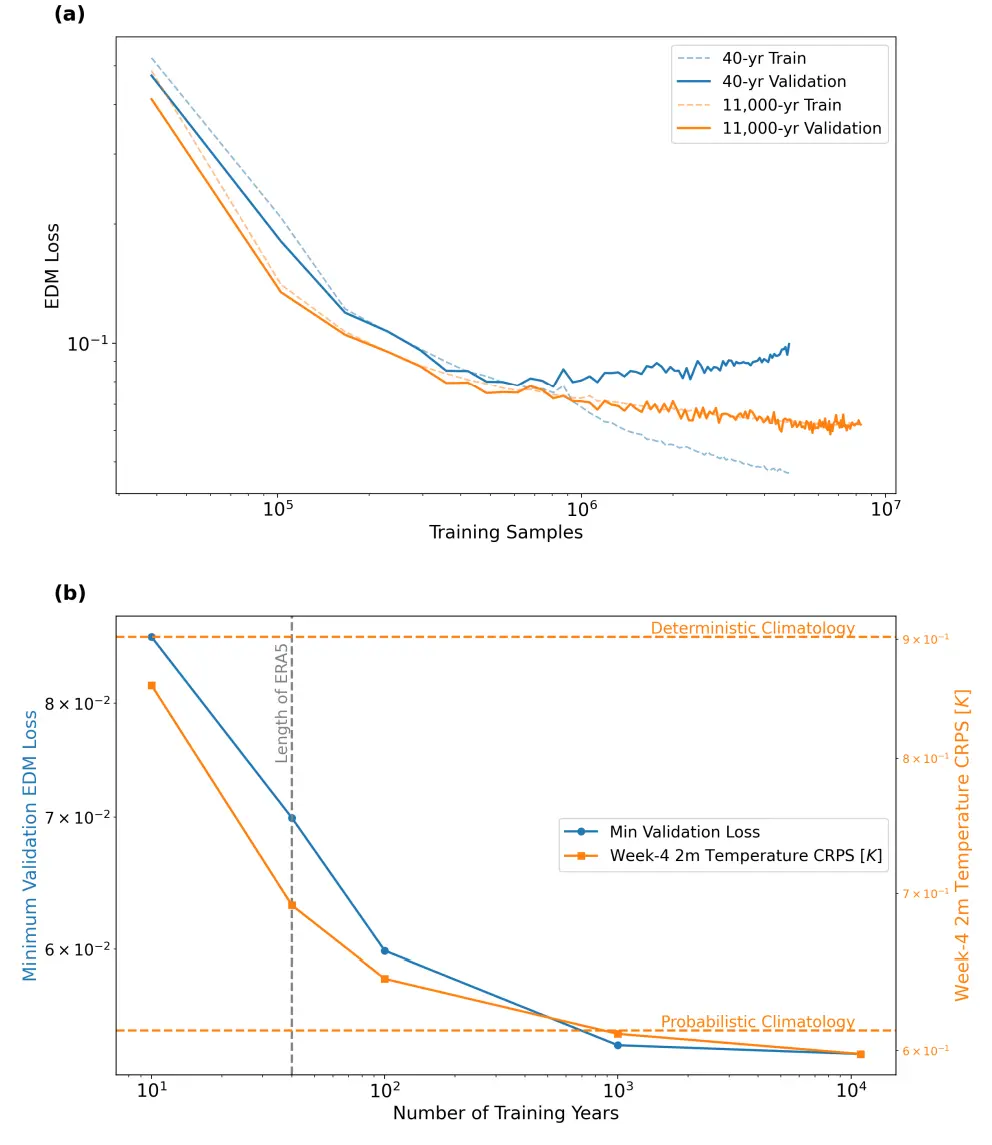
基於訓練數據集的學生模型 S2S 預測技能縮放
研究採用「無分類器引導」技術來校準概率預報的離散度。通過調節引導強度,可以控制預報集合的分散程度,使其與預報誤差達到最佳平衡。實驗表明,引導強度設為 1 時,模型即可自動實現良好的校準;若需調整,也只需在推理階段簡單調節該參數。這為概率預報提供了一種高效、靈活的校準手段。
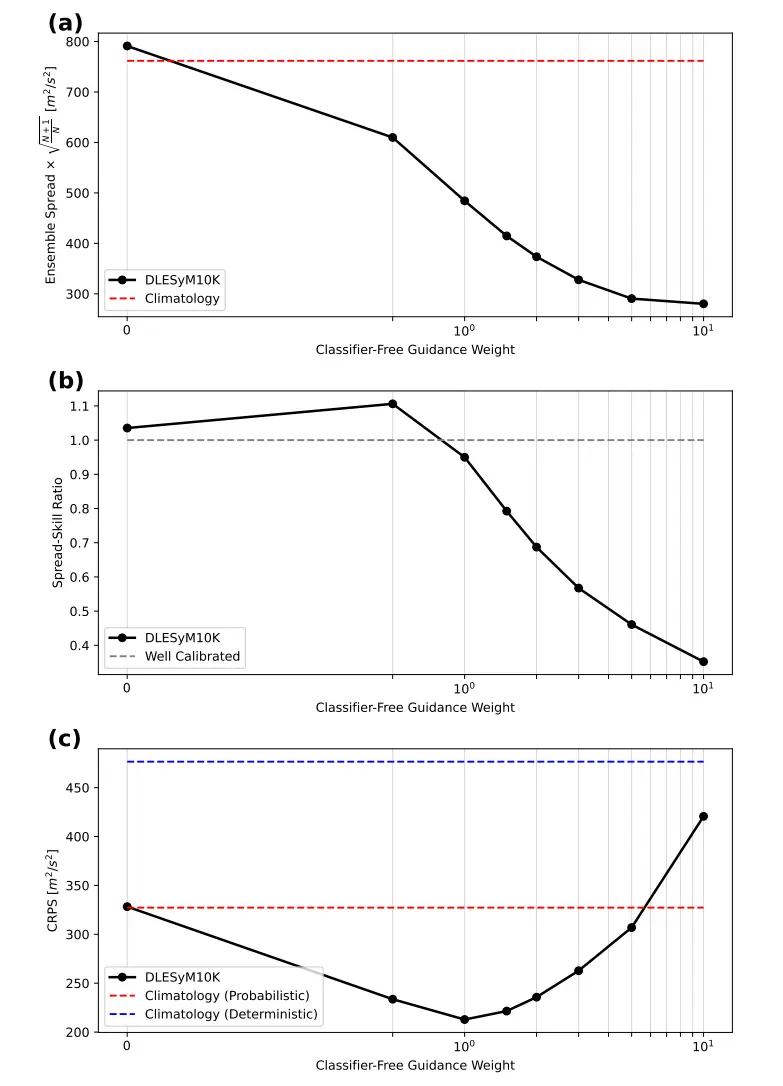
使用無分類器指導的中期蒸餾學生模型的預測校準
模型在中期、次季節至季節(S2S)和季節預報中均表現出穩健性能。在中期預報中,模型對初始誤差表現出較強的魯棒性,其概率建模特性有助於對衝初始條件的不確定性。在更具挑戰的 S2S 和季節預報中,DLESyM10K 的技能顯著優於氣候學基準,尤其在熱帶和海洋等可預測性較高的區域表現突出。值得注意的是,它通過單步計算就達到了與自迴歸教師模型數百步迭代相當的技能,體現了該框架的高效性。
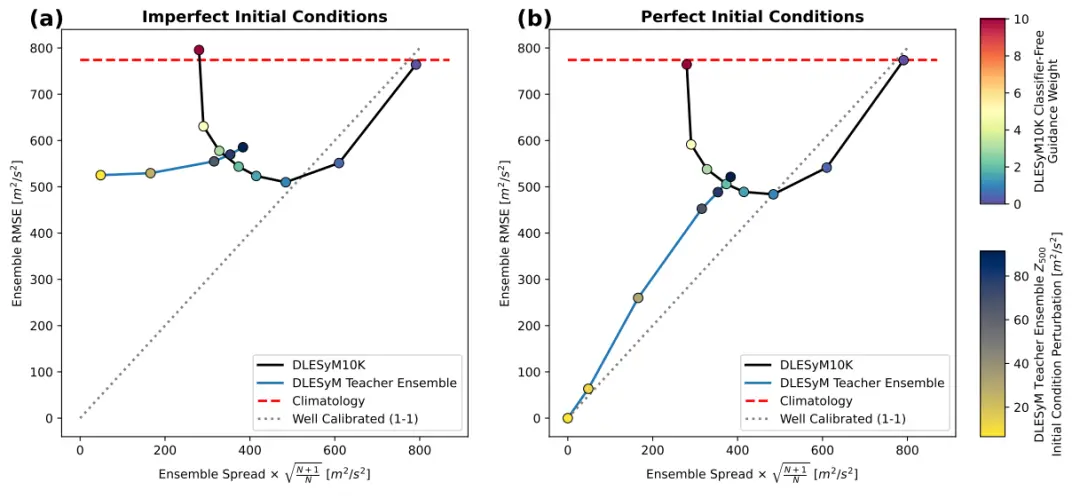
真實場景下的中期預報技能
將模型遷移至真實世界預報時,通過微調和偏差校正解決了「模型氣候」與真實氣候的差異問題。與歐洲中期天氣預報中心(ECMWF)業務系統的對比顯示:經過微調的 DLESyM10K,其 4 周氣温預報技能與 ECMWF 系統非常接近,且兩者均顯著優於氣候學基準。區域分析表明,兩者在不同地理區域各有優勢,例如 DLESyM10K 在美洲和非洲中部部分區域表現更好。這證明了該 AI 模型具備與先進業務系統競爭的潛力,同時凸顯了其差異化價值。
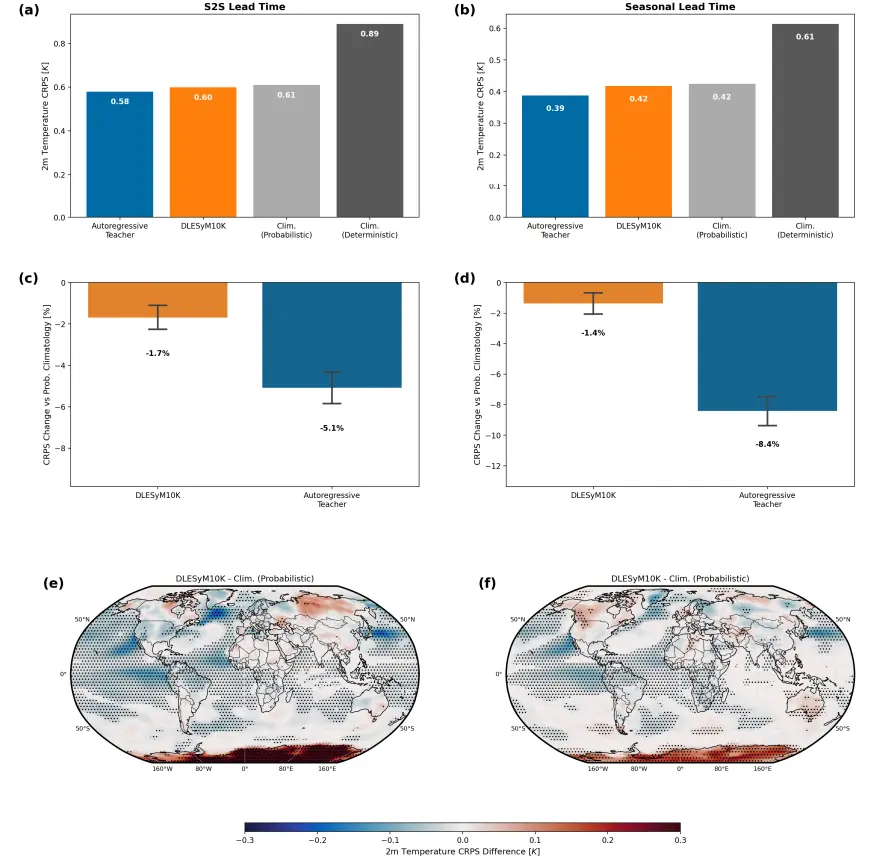
在完美模型實驗中提煉學生模型遠期預測技巧
綜上所述,長距離蒸餾方法通過「數據縮放」與「單步概率建模」的結合,訓練出能單步輸出長期概率預報的條件擴散模型,並結合無分類器引導技術實現了靈活的不確定性校準。實驗表明,該方法在次季節至季節預報中已達到與歐洲中期天氣預報中心業務系統相當的性能。這一範式不僅為長期天氣預報提供了新方案,也為構建服務於氣候科學探索的通用生成模型奠定了基礎。
全球產學研協同加速氣象技術變革
以 AI 生成合成數據解決長期預報中的數據瓶頸,正成為學術界與工業界共同推動氣象預報革新的重要方向。一系列前沿研究與工程實踐接連涌現,持續推動長期天氣預報從理論探索走向業務應用。
在學術界,跨學科協作正成為攻克核心技術難題的關鍵。例如,芝加哥大學發起的「AI 氣候計劃(AICE)」,聯合了氣候科學、計算機與統計學等多領域專家,致力於大幅降低氣候預報的計算成本。其研發的技術已實現使用普通筆記本電腦生成高水平預報,有望幫助縮小不同地區在氣象預報能力上的差距。
劍橋大學聯合圖靈研究所、歐洲中期天氣預報中心等機構,共同開發了端到端數據驅動預報系統 Aardvark Weather 。該系統能夠融合多種觀測數據,同步輸出全球網格預報與局部站點預報,在 10 天預報時效上已展現出可與優化後的業務數值模式相媲美的性能。其端到端的建模理念,與長距離蒸餾簡化預報流程的初衷高度一致,為長期預報的精準化提供了技術範本。
* 點擊查看 Aardvark Weather 深度解讀:登 Nature,劍橋大學等發佈首個端到端的數據驅動天氣預報系統,預測速度提升數十倍
* 論文名稱:End-to-end data-driven weather prediction
* 論文地址:
https://www.nature.com/articles/s41586-025-08897-0
在工業界,創新實踐更側重於技術的工程化落地與場景化應用。科技企業通過深度參與產學研合作與自主研發,不斷拓展 AI 氣象的技術邊界。例如,微軟、谷歌 DeepMind 等機構深入參與了 Aardvark Weather 系統的研發,將其在大規模數據處理與深度學習架構方面的優勢,轉化為氣象模型在效率與精度上的提升。其中,谷歌 DeepMind 在生成模型與概率預報校準方面的技術積累,也為解決類似長距離蒸餾中集合離散度控制等問題提供了重要參考。
與此同時,企業界也積極推動 AI 氣象技術在具體場景中的落地。例如,通過與園區管理、應急部門合作,將精準化的長期預報技術整合進智慧防災系統中,通過全流程模擬災害演變,為園區安全、水利調度與農業生產等場景提供定製化的預報服務,使長期氣象預報的價值真正惠及終端用户。
這些來自學術界與工業界的探索,不僅驗證了以數據蒸餾和單步建模為代表的技術路徑的可行性,也逐步形成了「學術突破引領方向、工程創新驅動落地」的良性循環,共同推動全球 AI 氣象預報向着更精準、更高效、更普惠的方向持續發展。
參考鏈接:
1.https://climate.uchicago.edu/entities/aice-ai-for-climate/