

本文檔適用於想要了解 TVM 架構或積極開發項目的開發者。本文檔組織結構如下:
- 整體編譯流程示例:概述 TVM 如何將一個高級模型描述轉換為可部署模塊的各個步驟。建議首先閲讀本節以瞭解基礎流程。
-
簡要介紹 TVM 棧中的關鍵組件。您也可以參考 TensorIR 深度解析 和 Relax 深度解析,瞭解 TVM 棧中兩個核心部分的詳細內容。
本指南提供了架構的一些補充視圖。首先研究端到端的編譯流程,並討論關鍵的數據結構和轉換。這種基於 runtime 的視圖側重於運行編譯器時每個組件的交互,接下來我們將研究代碼庫的邏輯模塊及其關係。本部分將提供該設計的靜態總體視圖。編譯流程示例
本指南研究編譯器中的編譯流程示例,下圖展示了流程。從高層次來看,它包含以下步驟:
- 導入: 前端組件將模型引入到 IRModule 中,它包含了內部表示模型的函數集合。
- 轉換: 編譯器將 IRModule 轉換為功能與之等效或近似等效(例如在量化的情況下)的 IRModule。許多轉換與 target(後端)無關,並且允許 target 配置轉換 pipeline。
- Target 轉換: 編譯器將 IRModule 轉換(codegen)為指定 target 的可執行格式。target 的轉換結果被封裝為 runtime.Module,可以在 runtime 環境中導出、加載和執行。
-
Runtime 執行: 用户加載 runtime.Module,並在支持的 runtime 環境中運行編譯好的函數。
關鍵數據結構
設計和理解複雜系統的最佳方法之一,就是識別關鍵數據結構和操作(轉換)這些數據結構的 API。識別了關鍵數據結構後,就可以將系統分解為邏輯組件,這些邏輯組件定義了關鍵數據結構的集合,或是數據結構之間的轉換。
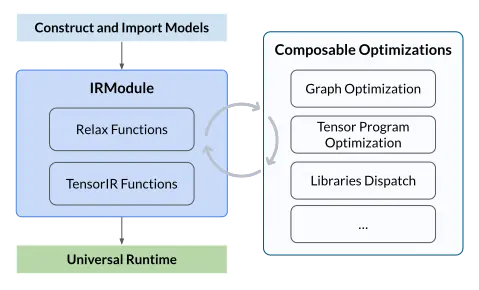
IRModule 是整個堆棧中使用的主要數據結構。一個 IRModule(intermediate representation module)包含一組函數。目前支持兩種主要的功能變體(variant):
- relay::Function 是一種高層功能程序表示。一個 relay.Function 通常對應一個端到端的模型。可將 relay.Function 視為額外支持控制流、遞歸和複雜數據結構的計算圖。
- tir::PrimFunc 是一種底層程序表示,包含循環嵌套選擇、多維加載/存儲、線程和向量/張量指令的元素。通常用於表示算子程序,這個程序在模型中執行一個(可融合的)層。 在編譯期間,Relay 函數可降級為多個 tir::PrimFunc 函數和一個調用這些 tir::PrimFunc 函數的頂層函數。
在編譯和轉換過程中,所有的 Relax 運算符都會被下沉(lower)為 tir::PrimFunc 或 TVM PackedFunc,這些函數可以直接在目標設備上執行。而對 Relax 運算符的調用,則會被下沉為對低層函數的調用(例如 R.call_tir 或 R.call_dps)。
轉換
前面介紹了關鍵數據結構,接下來講轉換。轉換的目的有:
- 優化:將程序轉換為等效,甚至更優的版本。
- 降級:將程序轉換為更接近 target 的較低級別表示。 relay/transform 包含一組優化模型的 pass。優化包括常見的程序優化(例如常量摺疊和死碼消除),以及特定於張量計算的 pass(例如佈局轉換和 scale 因子摺疊)。
Relax 轉換
Relax 轉換包括一系列應用於 Relax 函數的 Pass。優化內容包括常見的圖級優化(如常量摺疊、無用代碼消除等),以及後端特定的優化(例如庫調度)。
tir 轉換
tir 轉換包含一組應用於 tir 函數的 pass,主要包括兩類:
- TensorIR 調度(TensorIR schedule): TensorIR 調度旨在為特定目標優化 TensorIR 函數,通常由用户指導控制目標代碼的生成。對於 CPU 目標,TIR PrimFunc 即使沒有調度也可以生成有效代碼並在目標設備上運行,但性能較低。對於 GPU 目標,調度是生成有效線程綁定代碼的關鍵。詳情請參考 TensorIR 轉換教程。此外,TVM 提供了 MetaSchedule 來自動搜索最優的 TensorIR 調度。
- 降層 Pass(Lowering Passes): 這些 Pass 通常在應用調度後執行,將 TIR PrimFunc 轉換為功能等價但更貼近目標表示的版本。例如,有些 Pass 會將多維訪問扁平化為一維指針訪問,或者將中間表示中的 intrinsic 擴展為目標特定的形式,並對函數入口進行修飾以符合運行時調用約定。
許多底層優化可以在目標階段由 LLVM、CUDA C 以及其他目標編譯器處理。因此,我們將寄存器分配等底層優化留給下游編譯器處理,僅專注於那些它們未涵蓋的優化。
跨層轉換(Cross-level transformations)
Apache TVM 提供統一的策略來優化端到端模型。由於 IRModule 同時包含 Relax 和 TIR 函數,跨層轉換的目標是在這兩類函數之間應用變換來修改 IRModule。
例如,relax.LegalizeOps Pass 會通過將 Relax 算子降層為 TIR PrimFunc 並添加至 IRModule 中,同時將原有的 Relax 算子替換為對該 TIR 函數的調用,從而改變 IRModule。另一個例子是 Relax 中的算子融合流程(包括 relax.FuseOps 和 relax.FuseTIR),它將多個連續的張量操作融合為一個操作。與以往手動定義融合規則的方法不同,Relax 的融合流程會分析 TIR 函數的模式,自動檢測出最佳融合策略。
目標轉換(Target Translation)
目標轉換階段將 IRModule 轉換為目標平台的可執行格式。對於 x86 和 ARM 等後端,TVM 使用 LLVM IRBuilder 構建內存中的 LLVM IR。也可以生成源碼級別的語言,如 CUDA C 和 OpenCL。此外,TVM 支持通過外部代碼生成器將 Relax 函數(子圖)直接翻譯為目標代碼。
目標代碼生成階段應儘可能輕量,大多數轉換和降層操作應在此階段之前完成。
TVM 還提供了 Target 結構體用於指定編譯目標。目標信息也可能影響前期轉換操作,例如目標的向量長度會影響向量化行為。
Runtime 執行
TVM runtime 的主要目標是提供一個最小的 API,從而能以選擇的語言(包括 Python、C++、Rust、Go、Java 和 JavaScript)加載和執行編譯好的工件。以下代碼片段展示了一個 Python 示例:
import tvm
# Python 中 runtime 執行程序示例,帶有類型註釋
mod: tvm.runtime.Module = tvm.runtime.load_module("compiled_artifact.so")
arr: tvm.runtime.Tensor = tvm.runtime.tensor([1, 2, 3], device=tvm.cuda(0))
fun: tvm.runtime.PackedFunc = mod["addone"]
fun(arr)
print(arr.numpy())tvm.runtime.Module 封裝了編譯的結果。runtime.Module 包含一個 GetFunction 方法,用於按名稱獲取 PackedFuncs。
tvm.runtime.PackedFunc 是一種為各種構造函數消解類型的函數接口。runtime.PackedFunc 的參數和返回值的類型如下:POD 類型(int, float)、string、runtime.PackedFunc、runtime.Module、runtime.Tensor 和 runtime.Object 的其他子類。
tvm.runtime.Module 和 tvm.runtime.PackedFunc 是模塊化 runtime 的強大機制。例如,要在 CUDA 上獲取上述 addone 函數,可以用 LLVM 生成主機端代碼來計算啓動參數(例如線程組的大小),然後用 CUDA 驅動程序 API 支持的 CUDAModule 調用另一個 PackedFunc。OpenCL 內核也有相同的機制。
以上示例只處理了一個簡單的 addone 函數。下面的代碼片段給出了用相同接口執行端到端模型的示例:
import tvm
# python 中 runtime 執行程序的示例,帶有類型註釋
factory: tvm.runtime.Module = tvm.runtime.load_module("resnet18.so")
# 在 cuda(0) 上為 resnet18 創建一個有狀態的圖執行模塊
gmod: tvm.runtime.Module = factory["resnet18"](tvm.cuda(0))
data: tvm.runtime.Tensor = get_input_data()
# 設置輸入
gmod["set_input"](0, data)
# 執行模型
gmod["run"]()
# 得到輸出
result = gmod["get_output"](0).numpy()主要的結論是 runtime.Module 和 runtime.PackedFunc 可以封裝算子級別的程序(例如 addone),以及端到端模型。
總結與討論
綜上所述,編譯流程中的關鍵數據結構有:
- IRModule:包含 relay.Function 和 tir.PrimFunc
- runtime.Module:包含 runtime.PackedFunc
編譯基本是在進行關鍵數據結構之間的轉換。 - relay/transform 和 tir/transform 是確定性的基於規則的轉換
- meta-schedule 則包含基於搜索的轉換
最後,編譯流程示例只是 TVM 堆棧的一個典型用例。將這些關鍵數據結構和轉換提供給 Python 和 C++ API。然後,就可以像使用 numpy 一樣使用 TVM,只不過關注的數據結構從 numpy.ndarray 改為 tvm.IRModule。以下是一些用例的示例: - 用 Python API 直接構建 IRModule。
- 編寫一組自定義轉換(例如自定義量化)。
-
用 TVM 的 Python API 直接操作 IR。
tvm/support
support 模塊包含基礎架構最常用的程序,例如通用 arena 分配器(arena allocator)、套接字(socket)和日誌(logging)。
tvm/runtime
runtime 是 TVM 技術棧的基礎。它提供加載和執行已編譯產物的機制。運行時定義了一套穩定的 C API 標準接口,用於與前端語言(如 Python 和 Rust)交互。
除了 ffi::Function, runtime::Object 是 TVM 運行時的核心數據結構之一。它是一個帶有類型索引的引用計數基類,支持運行時類型檢查和向下轉型。該對象系統允許開發者向運行時引入新的數據結構,例如 Array、Map 以及新的 IR 數據結構。
除了用於部署場景,TVM 編譯器本身也大量依賴運行時機制。所有 IR 數據結構都是 runtime::Object 的子類,因此可以直接從 Python 前端訪問和操作。我們使用 PackedFunc 機制將各種 API 暴露給前端使用。
不同硬件後端的運行時支持定義在 runtime 子目錄中(例如 runtime/opencl)。這些特定於硬件的運行時模塊定義了設備內存分配和設備函數序列化的 API。
runtime/rpc 實現了對 PackedFunc 的 RPC 支持。我們可以利用 RPC 機制將交叉編譯後的庫發送到遠程設備,並基準測試其執行性能。該 RPC 基礎設施使得能夠從多種硬件後端收集數據,用於基於學習的優化。
- TVM 運行時系統
- 運行時信息
- 模塊序列化指南
-
設備/目標交互
tvm/node
node 模塊在 runtime::Object 的基礎上為 IR 數據結構增加了更多功能。其主要功能包括:反射、序列化、結構等價性檢查以及哈希計算。
得益於 node 模塊,我們可以在 Python 中通過字段名直接訪問 TVM IR 節點的任意字段:
x = tvm.tir.Var("x", "int32")
y = tvm.tir.Add(x, x)
# a 和 b 是 tir.Add 節點的字段
# 可以通過字段名直接訪問
assert y.a == x我們還可以將任意 IR 節點序列化為 JSON 格式,並加載回來。這種保存/加載和查看 IR 節點的能力為提高編譯器的可用性打下了基礎。
tvm/ir
tvm/ir 文件夾包含所有 IR 函數變體所共享的統一數據結構與接口。該模塊中的組件被 tvm/relax 和 tvm/tir 共享,主要包括:
- IRModule
- 類型
- PassContext 和 Pass
- Op
不同的函數變體(如 relax.Function 和 tir.PrimFunc)可以共存於一個 IRModule 中。儘管這些變體的內容表示不同,但它們使用相同的數據結構來表示類型。因此,不同函數變體之間可以共享函數簽名的表示結構。統一的類型系統使得在定義好調用約定的前提下,一個函數變體可以調用另一個,從而為跨函數變體的優化奠定了基礎。
此外,我們還提供了統一的 PassContext 用於配置 Pass 行為,並提供組合 Pass 的方式構建優化流程。如下示例:
# 配置 tir.UnrollLoop pass 的行為
with tvm.transform.PassContext(config={"tir.UnrollLoop": { "auto_max_step": 10 }}):
# 在該上下文下執行的代碼Op 是用於表示系統內置的原始操作符/內建指令的通用類。開發者可以向系統註冊新的 Op,並附加屬性(例如該操作是否是逐元素操作)。
-
Pass 基礎設施
tvm/target
target 模塊包含將 IRModule 轉換為目標運行時代碼的所有代碼生成器,同時也提供了一個通用的 Target 類用於描述目標平台。
編譯流程可以根據目標平台的屬性信息和每個目標 id(如 cuda、opencl)所註冊的內建信息來自定義。
-
設備/目標交互
tvm/relax
Relax 是用於表示模型計算圖的高級 IR。多種優化過程定義在 relax.transform 中。需要注意的是,Relax 通常與 TensorIR 的 IRModule 協同工作,許多轉換會同時作用於 Relax 和 TensorIR 函數。更多信息可參考: Relax 深度解析。
tvm/tir
TIR 定義了低級程序表示。我們使用 tir::PrimFunc 來表示可以由 TIR Pass 轉換的函數。除了 IR 數據結構,TIR 模塊還包括:
- 位於 tir/schedule 中的一組調度原語
- 位於 tir/tensor_intrin 中的內置指令
- 位於 tir/analysis 中的分析 Pass
-
位於 tir/transform 中的轉換/優化 Pass
更多信息請參考: TensorIR 深度解析。tvm/arith
該模塊與 TIR 緊密相關。低級代碼生成中的一個核心問題是對索引的算術屬性進行分析——如是否為正數、變量界限、描述迭代器空間的整數集合等。arith 模塊提供了一套主要用於整數分析的工具,TIR Pass 可以利用這些工具簡化和優化代碼。
tvm/te 和 tvm/topi
TE(Tensor Expression)是用於描述張量計算的領域專用語言(DSL)。需要注意的是,Tensor Expression 本身並不是可以直接存儲進 IRModule 的自包含函數。我們可以使用 te.create_prim_func 將其轉換為 tir::PrimFunc,然後集成進 IRModule。
儘管可以使用 TIR 或 TE 為每個場景直接構造算子,但這種方式較為繁瑣。為此,topi(Tensor Operator Inventory)提供了一組預定義算子,覆蓋了 numpy 操作和深度學習常見操作。
tvm/meta_schedule
MetaSchedule 是一個用於自動搜索優化程序調度的系統。它是 AutoTVM 和 AutoScheduler 的替代方案,可用於優化 TensorIR 調度。需要注意的是,MetaSchedule 目前僅支持靜態形狀工作負載。
tvm/dlight
DLight 提供一套預定義、易用且高性能的 TIR 調度策略。其目標包括:
- 全面支持動態形狀工作負載
- 輕量級:提供無需調優或僅需極少調優的調度策略,且性能合理
- 穩定性強:DLight 的調度策略具有通用性,即使當前規則不適用也不會報錯,而是自動切換至下一個規則