

上一篇文章以近乎囉嗦的方式詳細描述了BIO與非阻塞IO的各種細節。如果各位還沒有讀過這篇文章,強烈建議先閲讀一下,然後再來看本篇,因為邏輯關係是層層遞進的。
1. 多路複用的誕生
非阻塞IO使用一個線程就可以處理所有socket,但是付出的代價是必須頻繁調用系統調用來輪詢每一個socket的數據,這種輪詢太耗費性能,而且大部分輪詢都是空輪詢。
我們希望有個組件能同時監控多個socket,並在socket把數據準備好的時候告訴進程哪些socket已“就緒”,然後進程只對就緒的socket進行數據讀寫。
Java在JDK1.4的時候引入了NIO,並提供了Selector這個組件來實現這個功能。
2. NIO
在引入NIO代碼之前,有點事情需要解釋一下。
“就緒”這個詞用得有點曖昧,因為不同的socket對就緒有不同的表達。比如對於監聽socket而言,如果有客户端對其進行了連接,就説明處於就緒狀態,它並不像連接socket一樣,需要對數據的收發進行處理;相反,連接socket的就緒狀態就至少包含了數據準備好讀(is ready for reading)與數據準備好寫(is ready for writing)這兩種。
因此,可以想象,我們讓Selector對多個socket進行監聽時,必然需要告訴Selector,我們對哪些socket的哪些事件感興趣。這個動作叫註冊。
接下來看代碼。
public class NIOServer {
static Selector selector;
public static void main(String[] args) {
try {
// 獲得selector多路複用器
selector = Selector.open();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 監聽socket的accept將不會阻塞
serverSocketChannel.configureBlocking(false);
serverSocketChannel.socket().bind(new InetSocketAddress(8099));
// 需要把監聽socket註冊到多路複用器上,並告訴selector,需要關注監聽socket的OP_ACCEPT事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 該方法會阻塞
selector.select();
// 得到所有就緒的事件,事件被封裝成了SelectionKey
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isAcceptable()) {
handleAccept(key);
} else if (key.isReadable()) {
handleRead(key);
} else if (key.isWritable()) {
//發送數據
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 處理「讀」事件的業務邏輯
private static void handleRead(SelectionKey key) {
SocketChannel socketChannel = (SocketChannel) key.channel();
ByteBuffer allocate = ByteBuffer.allocate(1024);
try {
socketChannel.read(allocate);
System.out.println("From Client:" + new String(allocate.array()));
} catch (IOException e) {
e.printStackTrace();
}
}
// 處理「連接」事件的業務邏輯
private static void handleAccept(SelectionKey key) {
ServerSocketChannel serverSocketChannel = (ServerSocketChannel) key.channel();
try {
// socketChannel一定是非空,並且這裏不會阻塞
SocketChannel socketChannel = serverSocketChannel.accept();
// 將連接socket的讀寫設置為非阻塞
socketChannel.configureBlocking(false);
socketChannel.write(ByteBuffer.wrap("Hello Client, I am Server!".getBytes()));
// 註冊連接socket的「讀事件」
socketChannel.register(selector, SelectionKey.OP_READ);
} catch (IOException e) {
e.printStackTrace();
}
}
}我們首先使用Selector.open();得到了selector這個多路複用對象;然後在服務端創建了監聽socket,並將其設置為非阻塞,最後將監聽socket註冊到selector多路複用器上,並告訴selector,如果監聽socket有OP_ACCEPT事件發生的話就要告訴我們。
我們在while循環中調用selector.select();方法,進程將會阻塞在該方法上,直到註冊在selector上的任意一個socket有事件發生為止,才會返回。如果不信的話可以在selector.select();的下一行打個斷點,debug模式運行後,在沒有客户端連接的情況下斷點不會被觸發。
當select()返回,意味着有一個或多個socket已經處於就緒狀態,我們使用Set<SelectionKey>來保存所有事件,SelectionKey封裝了就緒的事件,我們循環每個事件,根據不同的事件類型進行不同的業務邏輯處理。
OP_READ事件就緒的話,我們就準備一個緩衝空間,將數據從內核空間讀到緩衝中;如果是OP_ACCEPT就緒,那就調用監聽socket的accept()方法得到連接socket,並且accept()不會阻塞,因為在最開始的時候我們已經將監聽socket設置為非阻塞了。得到的連接socket同樣需要設置為非阻塞,這樣連接socket的讀寫操作就是非阻塞的,最後將連接socket註冊到selector多路複用器上,並告訴selector,如果連接socket有OP_READ事件發生的話就要告訴我們。
上個動圖對Java的多路複用代碼做個解釋。

接下來的重點自然是NIO中的select()的底層原理了,還是那句話,NIO之所以能提供多路複用的功能,本質上還是操作系統底層提供了多路複用的系統調用。
多路複用本質上就是同時監聽多個socket的請求,當我們訂閲的socket上有我們感興趣的事件發生的時候,多路複用函數會返回,然後我們的用户程序根據返回結果繼續處理這些就緒狀態的socket。
但是,不同的多路複用模型在具體的實現上有所不同,主要體現在三個方面:
- 多路複用模型最多可以同時監聽多少個socket?
- 多路複用模型會監聽socket上哪些事件?
- 當socket就緒時,多路複用模型如何找到就緒的socket?
多路複用主要有3種,分別是select、poll和epoll,接下來將帶着上面3個問題分別介紹這3種底層模型。
下文相關函數的聲明以及參數的定義源於64位CentOS 7.9,內核版本為3.10.0
3. select
我們可以通過select告訴內核,我們對哪些描述符(這些描述符可以表示標準輸入、監聽socket或者連接socket等)的哪些事件(可讀、可寫、發生異常)感興趣,或者某個超時時間之後直接返回。
舉個例子,我們調用select告訴內核僅在下列情況下發生時才返回:
- 集合{1, 4, 7}中有任何描述符讀就緒;
- 集合{2, 9}中有任何描述符寫就緒;
- 集合{1, 3, 5}中有任何描述符有異常發生;
- 超過了10S,啥事兒也沒有發生。
3.1. select使用方法
// 返回:若有就緒描述符則為其數目,若超時則為0,若出錯則為-1
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);nfds參數用來告訴select需要檢查的描述符的個數,取值為我們感興趣的最大描述符 + 1,按照剛才的例子來講nfds應該是{{1, 4, 7}, {2, 9}, {1, 3, 5}}中的最大描述符+1,也就是9 + 1,為10。至於為什麼這樣,別急,我們下文再説。
timeout參數允許我們設置select的超時時間,如果超過指定時間還沒有我們感興趣的事件發生,就停止阻塞,直接返回。
readfds裏保存的是我們對讀就緒事件感興趣的描述符,writefds保存的是我們對寫就緒事件感興趣的描述符,exceptfds保存的是我們對發生異常這種事件感興趣的描述符。這三個參數會告訴內核,分別需要在哪些描述符上檢測數據可讀、可寫以及發生異常。
但是這些描述符並非像我的例子一樣,直接把集合{1, 4, 7}作為數組存起來,設計者從內存空間和使用效率的角度設計了fd_set這個數據結構,我們看一下它的定義以及某些重要信息。
// file: /usr/include/sys/select.h
/* __fd_mask 是 long int 類型的別名 */
typedef long int __fd_mask;
#define __NFDBITS (8 * (int) sizeof (__fd_mask))
typedef struct {
...
__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS];
...
} fd_set;因此,fd_set的定義,其實就是long int類型的數組,元素個數為__FD_SETSIZE / __NFDBITS,我直接在我的CentOS上輸出了一下兩個常量值,如下:
#include <stdio.h>
#include "sys/select.h"
int main(){
printf("__FD_SETSIZE:%d\n",__FD_SETSIZE);
printf("__NFDBITS:%d\n",__NFDBITS);
return 0;
}
// 輸出結果
__FD_SETSIZE:1024
__NFDBITS:64因此該數組中一共有16個元素(1024 / 64 = 16),每個元素為long int類型,佔64位。
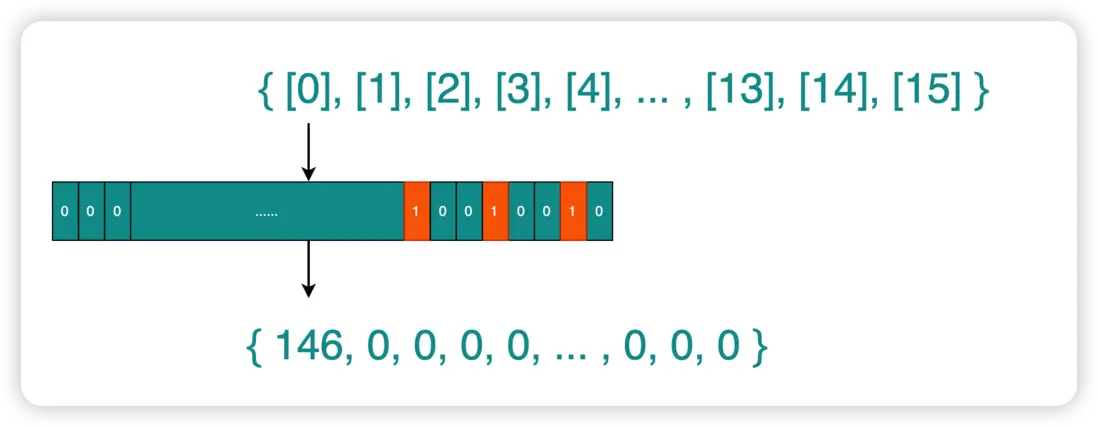
數組的第1個元素用於表示描述符0~63,第2個元素用於表示描述符64~127,以此類推,每1個bit位用0、1兩種狀態表示是否檢測當前描述符的事件。
假設我們對{1, 4, 7}號描述符的讀就緒事件感興趣,那麼readfds參數的數組第1個元素的二進制表示就如下圖所示,第1、4、7位分別被標記為1,實際存儲的10進制數字為146。
實際使用select的時候如果讓我們自己推導上面這個過程進行參數設置那可費了勁了,於是操作系統提供了4個宏來幫我們設置數組中每個元素的每一位。
// 將數組每個元素的二進制位重置為0
void FD_ZERO(fd_set *fdset);
// 將第fd個描述符表示的二進制位設置為1
void FD_SET(int fd, fd_set *fdset);
// 將第fd個描述符表示的二進制位設置為0
void FD_CLR(int fd, fd_set *fdset);
// 檢查第fd個描述符表示的二進制位是0還是1
int FD_ISSET(int fd, fd_set *fdset);還是上面{1, 4, 7}這個例子,再順帶着介紹一下用法,知道有這麼回事兒就行了。
fd_set readSet;
FD_ZERO(&readSet);
FD_SET(1, &readSet);
FD_SET(4, &readSet);
FD_SET(7, &readSet);既然fd_set底層用的是數組,那就一定有長度限制,也就是説select同時監聽的socket數量是有限的,你之前可能聽過這個有限的數量是1024,但是1024是怎麼來的呢?
3.2. 上限為什麼是1024
其實select的監聽上限就等於fds_bits數組中所有元素的二進制位總數。接下來我們用初中數學的解題步驟推理一下這個二進制位到底有多少。
已知:

證明如下:

結論就是__FD_SETSIZE這個宏其實就是select同時監聽socket的最大數量。該數值在源碼中有定義,如下所示:
// file: /usr/include/bits/typesizes.h
/* Number of descriptors that can fit in an `fd_set'. */
#define __FD_SETSIZE 1024所以,select函數對每一個描述符集合fd_set,最多可以同時監聽1024個描述符。
3.3. nfds的作用
為什麼偏偏把最大值設置成1024呢?沒人知道,或許只是程序員喜歡這個數字罷了。
最初設計select的時候,設計者考慮到大多數的應用程序根本不會用到很多的描述符,因此最大描述符的上限被設置成了31(4.2BSD版本),後來在4.4BSD中被設置成了256,直到現在被設置成了1024。
這個數量説多不多,説少也不算少,select()需要循環遍歷數組中的位判斷此描述符是否有對應的事件發生,如果每次都對1024個描述符進行判斷,在我們感興趣的監聽描述符比較少的情況下(比如我上文的例子)那就是一種極大的浪費。於是,select給我們提供了nfds這個參數,讓我們告訴select()只需要迭代數組中的前nfds個就行了,而不要總是在每次調用的時候遍歷整個數組。
身為一個系統函數,執行效率自然需要優化到極致。
3.4. 再談阻塞
上一篇文章講過,當用户線程發起一個阻塞式的read系統調用,數據未就緒時,線程就會阻塞。阻塞其實是調用線程被投入睡眠,直到內核在某個時機喚醒線程,阻塞也就結束。這裏我們藉着select再聊一聊這個阻塞。
本小節中不做「進程」和「線程」的明確區分,線程作為輕量級進程來看待
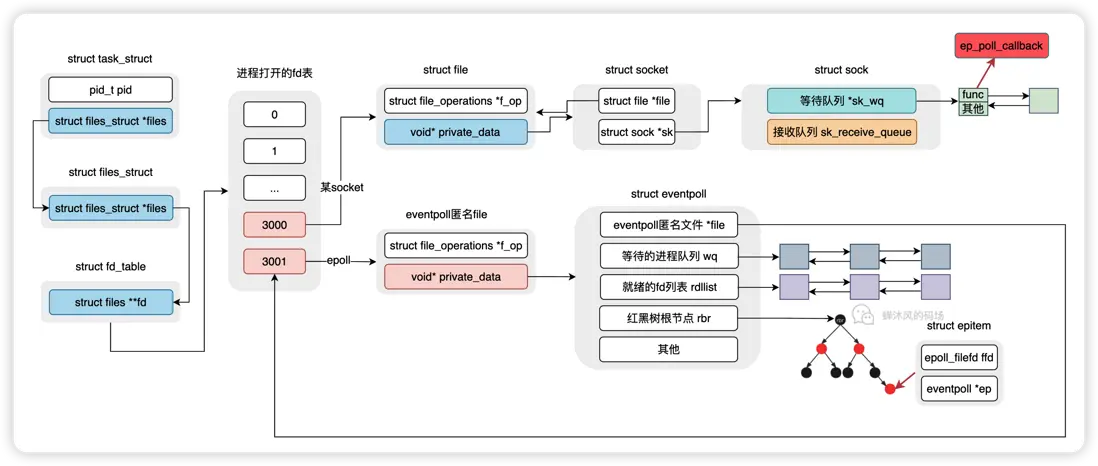
內核會為每一個進程創建一個名為task_struct的數據結構,這個數據結構本身是分配在內核空間的,其中保存了當前進程的進程號、socket信息、CPU的運行上下文以及其他很重要但是我不講的信息(/狗頭)。
Linux內核維護了一個執行隊列,裏邊放的都是處於TASK_RUNNING狀態的進程的task_struct,這些進程以雙向鏈表的方式排隊等待CPU極短時間的臨幸。

阻塞的本質就是將進程的task_struct移出執行隊列,讓出CPU的調度,將進程的狀態的置為TASK_UNINTERRUPTIBLE或者TASK_INTERRUPTIBLE,然後添加到等待隊列中,直到被喚醒。
那這個等待隊列在哪兒呢?比如我們對一個socket發起一個阻塞式的 read 調用,用户進程肯定是需要和這個socket進行綁定的,要不然socket就緒之後都不知道該喚醒誰。這個等待隊列其實就是保存在socket數據結構中,我們瞄一眼socket源碼:
struct socket {
...
// 這個在epoll中會提到
struct file *file;
...
// struct sock - network layer representation of sockets
struct sock *sk;
...
};
struct sock {
...
// incoming packets
struct sk_buff_head sk_receive_queue;
...
// Packet sending queue
struct sk_buff_head sk_write_queue;
...
// socket的等待隊列,wq的意思就是wait_queue
struct socket_wq __rcu *sk_wq;
};
不用深入理解哈,只要知道socket自己維護了一個等待隊列sk_wq,這個隊列中每個元素保存的是:
- 阻塞在當前socket上的進程描述符
- 進程被喚醒之後應該調用的回調函數
這個回調函數是進程在加入等待隊列的時候設置的一個函數指針(行話叫,向內核註冊了一個回調函數),告訴內核:我正等着這個socket上的數據呢,先睡一會兒,等有數據了你就執行這個回調函數吧,裏邊有把我喚醒的邏輯。
就這樣,經過網卡接收數據、硬中斷以及軟中斷再到內核調用回調函數喚醒進程,把進程的task_struct從等待隊列移動到執行隊列,進程再次得到CPU的臨幸,函數返回結果,阻塞結束。
現在回到select。
用户進程會阻塞在select之上,由於select會同時監聽多個socket,因此當前進程會被添加到每個被監聽的socket的等待隊列中,每次喚醒還需要從每個socket等待隊列中移除。

select的喚醒也有個問題,調用select的進程被喚醒之後是一臉懵啊,內核直接扔給他一個整數,進程不知道哪些socket收到數據了,還必須遍歷一下才能知道。

3.5. select如何多路複用
select在超時時間內會被阻塞,直到我們感興趣的socket讀就緒、寫就緒或者有異常事件發生(這話好像囉嗦了好多遍了,是不是自然而然已經記住了),然後select會返回已就緒的描述符數。
其實讀就緒、寫就緒或者有異常事件發生這3種事件裏邊的道道兒非常多,這裏我們就僅作字面上的理解就好了,更多細節,可以參考《Unix網絡編程 卷一》。
用户進程拿到這個整數説明了兩件事情:
- 我們上文講的所有
select操作都是在內核態運行的,select返回之後,權限交還到了用户空間; - 用户進程拿到這個整數,需要對
select監聽的描述符逐個進行檢測,判斷二進制位是否被設置為1,進而進行相關的邏輯處理。可是問題是,內核把“就緒”的這個狀態保存在了哪裏呢?換句話説,用户進程該遍歷誰?
select的readfds、writefds、exceptfds 3個參數都是指針類型,用户進程傳遞這3個參數告訴內核對哪些socket的哪些事件感興趣,執行完畢之後反過來內核會將就緒的描述符狀態也放在這三個參數變量中,這種參數稱為值-結果參數。
用户進程通過調用FD_ISSET(int fd, fd_set *fdset)對描述符集進行判斷即可,看個整體流程的動圖。

- 用户進程設置
fd_set參數,調用select()函數,並將描述符集合拷貝到內核空間; - 為了提高效率,內核通過
nfds參數避免檢測那些總為0的位,遍歷的過程發生在內核空間,不存在系統調用切換上下文的開銷; select函數修改由指針readset、writeset以及exceptset所指向的描述符集,函數返回時,描述符集中只有之前我們標記過的並且處於就緒狀態的描述符對應的二進制位才是1,其餘都會被重置為0(因此每次重新調用select時,我們必須把所有描述符集中感興趣的位再次設置為1);- 進程根據
select()返回的結果判斷操作是否正常,如果為0表示超時,-1表示出錯,大於0表示有相應數量的描述符就緒了,進而利用FD_ISSET遍歷檢查所有相應類型的fd_set中的所有描述符,如果為1,則進行業務邏輯處理即可。
3.6. 總結
select(包括下文講到的poll)是阻塞的,進程會阻塞在select之上,而不是阻塞在真正的I/O系統調用上,模型示意圖見下圖:

我們從頭到尾都是使用一個用户線程來處理所有socket,同時又避免了非阻塞IO的那種無效輪詢,為此付出的代價是一次select系統調用的阻塞,外加N次就緒文件描述符的系統調用。
4. poll
poll是select的繼任者,接下來聊它。
4.1. 函數原型
先看一下函數原型:
// 返回:若有就緒描述符則為其數目,若超時則為0,若出錯則為-1
int poll(struct pollfd *fds, nfds_t nfds, int timeout);函數有3個參數,第一個參數是一個pollfd類型的數組,其中pollfd結構如下:
struct pollfd {
int fd; /* file descriptor */
short events; /* events to look for */
short revents; /* events returned */
};4.2. poll訂閲的事件
pollfd由3部分組成,首先是描述符fd,其次events表示描述符fd上待檢測的事件類型,一個short類型的數字用來表示多種事件,自然可以想到用的是二進制掩碼的方式來進行位操作。
源碼中我們可以找到所有事件的定義,我根據事件的分類對源碼的順序做了一定調整,如下:
// file: /usr/include/bits/poll.h
/* 第一類:可讀事件 */
#define POLLIN 0x001 /* There is data to read. */
#define POLLPRI 0x002 /* There is urgent data to read. */
#define POLLRDNORM 0x040 /* Normal data may be read. */
#define POLLRDBAND 0x080 /* Priority data may be read. */
/* 第二類:可寫事件 */
#define POLLOUT 0x004 /* Writing now will not block. */
#define POLLWRNORM 0x100 /* Writing now will not block. */
#define POLLWRBAND 0x200 /* Priority data may be written. */
/* 第三類:錯誤事件 */
#define POLLERR 0x008 /* Error condition. */
#define POLLHUP 0x010 /* Hung up. */
#define POLLNVAL 0x020 /* Invalid polling request. */pollfd結構中還有一個revents字段,全稱是“returned events”,這是poll與select的第1個不同點。
poll會將每次遍歷之後的結果保存到revents字段中,沒有select那種值-結果參數,也就不需要每次調用poll的時候重置我們感興趣的描述符以及相關事件。
還有一點,錯誤事件不能在events中進行設置,但是當相應事件發生時會通過revents字段返回。這是poll與select的第2個不同點。
再來看poll的第2個參數nfds,表示的是數組fds的元素個數,也就是用户進程想讓poll同時監聽的描述符的個數。
如此一來,poll函數將設置最大監聽數量的權限給了程序設計者,自由控制pollfd結構數組的大小,突破了select函數1024個最大描述符的限制。這是poll與select的第3個不同點。
至於timeout參數就更好理解了,就是設置超時時間罷了,更多細節朋友們可以查看一下api。
poll和select是完全不同的API設計,因此要説不同點那真是海了去了,但是由於本質上和select沒有太大的變化,因此我們也只關注上面的這幾個不同點也就罷了。需要注意的是poll函數返回之後,被喚醒的用户進程依然是懵的,踉踉蹌蹌地去遍歷文件描述符、檢查相關事件、進行相應邏輯處理。
其他的細節就再參考一下select吧,poll我們到此為止。
5. epoll
epoll是三者之中最強大的多路複用模型,自然也更難講,要三言兩語只講一下epoll的優勢倒也不難,不過會喪失很多細節,用源碼解釋又太枯燥,思來想去,於是。。。
我拖更了。。。

5.1. epoll入門
還是先從epoll的函數使用開始,不同於select/poll單個函數走天下,epoll用起來稍微麻煩了一點點,它提供了函數三件套,epoll_create、epoll_ctl、epoll_wait,我們一個個來看。
5.1.1. 創建epoll實例
// size參數從Linux2.6.8之後失去意義,為保持向前兼容,需要使size參數 > 0
int epoll_create(int size);
// 這個函數是最新款,如果falgs為0,等同於epoll_create()
int epoll_create1(int flags);epoll_create() 方法創建了一個 epoll 實例,並返回了指向epoll實例的描述符,這個描述符用於下文即將介紹的另外兩個函數。也可以使用epoll_create1()這個新函數,這個函數相比前者可以多添加EPOLL_CLOEXEC這個可選項,至於有啥含義,對本文並不重要。
這個epoll實例內部維護了兩個重要結構,分別是需要監聽的文件描述符樹和就緒的文件描述符(這兩個結構下文會講),對於就緒的文件描述符,他們會被返回給用户進程進行處理,從這個角度來説,epoll避免了每次select/poll之後用户進程需要掃描所有文件描述符的問題。
5.1.2. epoll註冊事件
創建完epoll實例之後,我們可以使用epoll_ctl(ctl就是control的縮寫)函數,向epoll實例中添加、修改或刪除我們感興趣的某個文件描述符的某些事件。
// 返回值: 若成功返回0;若返回-1表示出錯
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); 第一個參數epfd就是剛才調用epoll_create創建的epoll實例的描述符,也就是epoll的句柄。
第二個參數op表示要進行什麼控制操作,有3個選項
EPOLL_CTL_ADD: 向 epoll 實例註冊文件描述符對應的事件;EPOLL_CTL_DEL:向 epoll 實例刪除文件描述符對應的事件;EPOLL_CTL_MOD: 修改文件描述符對應的事件。
第三個參數fd很簡單,就是被操作的文件描述符。
第四個參數就是註冊的事件類型,我們先看一下epoll_event的定義:
struct epoll_event {
uint32_t events; /* 向epoll訂閲的事件 */
epoll_data_t data; /* 用户數據 */
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;events這個字段和poll的events參數一樣,都是通過二進制掩碼設置事件類型,epoll的事件類型在/usr/include/sys/epoll.h中有定義,更詳細的可以使用man epoll_ctl看一下文檔説明,其中內容很多,知道有這麼回事兒就行了,但是注意一下EPOLLET這個事件,我特意加了一下注釋,下文會講到。
enum EPOLL_EVENTS {
EPOLLIN = 0x001,
#define EPOLLIN EPOLLIN
EPOLLPRI = 0x002,
#define EPOLLPRI EPOLLPRI
EPOLLOUT = 0x004,
#define EPOLLOUT EPOLLOUT
EPOLLRDNORM = 0x040,
#define EPOLLRDNORM EPOLLRDNORM
EPOLLRDBAND = 0x080,
#define EPOLLRDBAND EPOLLRDBAND
EPOLLWRNORM = 0x100,
#define EPOLLWRNORM EPOLLWRNORM
EPOLLWRBAND = 0x200,
#define EPOLLWRBAND EPOLLWRBAND
EPOLLMSG = 0x400,
#define EPOLLMSG EPOLLMSG
EPOLLERR = 0x008,
#define EPOLLERR EPOLLERR
EPOLLHUP = 0x010,
#define EPOLLHUP EPOLLHUP
EPOLLRDHUP = 0x2000,
#define EPOLLRDHUP EPOLLRDHUP
EPOLLWAKEUP = 1u << 29,
#define EPOLLWAKEUP EPOLLWAKEUP
EPOLLONESHOT = 1u << 30,
#define EPOLLONESHOT EPOLLONESHOT
// 設置為 edge-triggered,默認為 level-triggered
EPOLLET = 1u << 31
#define EPOLLET EPOLLET
};data字段比較有意思,我們可以在data中設置我們需要的數據,具體是什麼意思現在説起來還有點麻煩,稍安勿躁,我們接着看最後一個函數。
5.1.3. epoll_wait
// 返回值: 成功返回的是一個大於0的數,表示事件的個數;0表示超時;出錯返回-1.
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);這個是不是就感覺很熟悉了啊。epoll_wait的用法和select/poll很類似,用户進程被阻塞。不同的是,epoll會直接告訴用户進程哪些描述符已經就緒了。
第一個參數是epoll實例的描述符。
第二個參數是返回給用户空間的需要處理的I/O事件,是一個epoll_event類型的數組,數組的長度就是epoll_wait函數的返回值,再看一眼這個結構吧。
struct epoll_event {
uint32_t events; /* 向epoll訂閲的事件 */
epoll_data_t data; /* 用户數據 */
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;events 表示具體的事件類型,至於這個data就是在epoll_ctl中設置的data,這樣用户進程收到這個epoll_event,根據之前設置的data就能獲取到相關信息,然後進行邏輯處理了。
第三個參數是一個大於 0 的整數,表示 epoll_wait 可以返回的最大事件值。
第四個參數是 epoll_wait 阻塞調用的超時值,如果設置為 -1,表示不超時;如果設置為 0 則立即返回,即使沒有任何 I/O 事件發生。
5.2. edge-triggered 和 level-triggered
epoll還提供了一個利器——邊緣觸發(edge-triggered),也就是上文我沒解釋的EPOLLET 參數。
啥意思呢?我舉個例子。如果有個socket有100個字節的數據可讀,邊緣觸發(edge-triggered)和條件觸發(level-triggered)都會產生讀就緒事件。
但是如果用户進程只讀取了50個字節,邊緣觸發就會陷入等待,數據不會丟失,但是你愛讀不讀,反正老子已經通知過你了;而條件觸發會因為你還沒有讀完,兢兢業業地不停產生讀就緒事件催你去讀。
邊緣觸發只會產生一次事件提醒,效率和性能要高於條件觸發,這是epoll的一個大殺器。
5.3. epoll進階
5.3.1. file_operations與poll
進階之前問個小問題,Linux下所有文件都可以使用select/poll/epoll來監聽文件變化嗎?
答案是不行!
只有底層驅動實現了 file_operations 中 poll 函數的文件類型才可以被 epoll 監視!
注意,這裏的file_operations中定義的poll和上文講到的poll()是兩碼事兒,只是恰好名字一樣罷了。
socket 類型的文件驅動實現了 poll 函數,具體實現是sock_poll(),因此才可以被 epoll 監視。
下面我摘錄了 file_operations 中我們常見的函數定義給大家看一下。
// file: include/linux/fs.h
struct file_operations {
...
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
...
unsigned int (*poll) (struct file *, struct poll_table_struct *);
...
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
...
};有點懵對吧,繼續看。
Linux對文件的操作做了高度的抽象,每個開發者都可以開發自己的文件系統,Linux並不知道其中的具體文件應該怎樣open、read/write或者release,所以Linux定義了file_operations這個“接口”,設備類型需要自己實現struct file_operations結構中定義的函數的細節。有點類似於Java中的接口和具體實現類的關係。
poll函數的作用我們下文再説。
5.3.2. epoll內核對象的創建
epoll_create()的主要作用是創建一個struct eventpoll內核對象,後續epoll的操作大部分都是對這個數據結構的操作。

wq:等待隊列。雙向鏈表,軟中斷就緒的時候會通過wq找到阻塞在epoll對象上的進程;rdllist:就緒的描述符鏈表。雙向鏈表,當描述符就緒時,內核會將就緒的描述符放到rdllist,這樣用户進程就可以通過該鏈表直接找到就緒的描述符;rbr:Red Black Root。指向紅黑樹根節點,裏邊的每個節點表示的就是epoll監聽的文件描述符。
然後,內核將eventpoll加入到當前進程已打開的文件列表中。啥?eventpoll也是一個文件?別急,我們看看epoll_create1的源碼。
//file: /fs/eventpoll.c
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
int error, fd;
struct eventpoll *ep = NULL;
struct file *file;
...
// 1. 為struct eventpoll分配內存並初始化
// 初始化操作主要包括初始化等待隊列wq、rdllist、rbr等
error = ep_alloc(&ep);
...
// 2. 獲取一個可用的描述符號fd,此時fd還未與具體的file綁定
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
...
// 3. 創建一個名為"[eventpoll]"的匿名文件file
// 並將eventpoll對象賦值到匿名文件file的private_data字段進行關聯
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC));
// 4. 將eventpoll對象的file指針指向剛創建的匿名文件file
ep->file = file;
// 5. 將fd和匿名文件file進行綁定
fd_install(fd, file);
return fd;
}好好看一下代碼中的註釋(一定要看!),代碼執行完畢的結果就如下圖這般。

調用epoll_create1後得到的文件描述符本質上是匿名文件[eventpoll]的描述符,該匿名文件中的private_data字段才指向了真正的eventpoll對象。
Linux中的一切皆文件並非虛言。這樣一來,eventpoll文件也可以被epoll本身監測,也就是説epoll實例可以監聽其他的epoll實例,這一點很重要。
至此,epoll_create1調用結束。是不是很簡單吶~
5.3.3. 添加socket到epoll
現在我們考慮使用EPOLL_CTL_ADD向epoll實例中添加fd的情況。
接下來會涉及到較多的源碼,別恐懼,都很簡單
這時候就要用到上文的rbr紅黑樹了, epoll_ctl對fd的增刪改操查作實際上就是對這棵紅黑樹進行操作,樹的節點結構epitem如下所示:
// file: /fs/eventpoll.c
struct epitem {
/* 紅黑樹的節點 */
struct rb_node rbn;
/* 用於將當前epitem連接到eventpoll中rdllist中的工具 */
struct list_head rdllink;
...
/* 該結構保存了我們想讓epoll監聽的fd以及該fd對應的file */
struct epoll_filefd ffd;
/* 當前epitem屬於哪個eventpoll */
struct eventpoll *ep;
};

接着我們看一下epoll_ctl的源碼。
// file: /fs/eventpoll.c
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
struct file *file, *tfile;
struct eventpoll *ep;
struct epitem *epi;
...
/* 根據epfd找到eventpoll對應的匿名文件 */
file = fget(epfd);
/* fd是我們感興趣的socket描述符,根據它找到對應的文件 */
tfile = fget(fd);
/* 根據file的private_data字段找到eventpoll實例 */
ep = file->private_data;
...
/* 在紅黑樹中查找一下,看看是不是已經存在了
如果存在了,那就報錯;否則,執行ep_insert */
epi = ep_find(ep, tfile, fd);
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tfile, fd);
} else
error = -EEXIST;
clear_tfile_check_list();
break;
...
}
...
}epoll_ctl中,首先根據傳入的epfd以及fd找到相關的內核對象,然後在紅黑樹中判斷這個epitem是不是已經存在,存在的話就報錯,否則繼續執行ep_insert函數。
ep_insert故名思義就是將epitem結構插入到紅黑樹當中,但是並非單純插入那麼簡單,其中涉及到一些細節。
5.3.3.1. ep_insert
很多關鍵操作都是在ep_insert函數中完成的,看一下源碼。
// file: /fs/eventpoll.c
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
{
int error, revents, pwake = 0;
unsigned long flags;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
// 1. 分配epitem內存空間
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
...
// 2. 將epitem進行初始化
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
...
/* 3. 初始化 poll table,設置回調函數為ep_ptable_queue_proc */
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
/*
* 4. 調用ep_ptable_queue_proc函數,
* 設置socket等待隊列的回調函數為ep_poll_callback
*/
revents = ep_item_poll(epi, &epq.pt);
...
/* 5. epitem插入eventpoll的紅黑樹 */
ep_rbtree_insert(ep, epi);
...
}5.3.3.2. 分配與初始化epitem
雖然源碼行數不少,但是這一步非常簡單,就是將epitem中的數據準備好,到插入的時候直接拿來用就行了。用一張圖來説明這一步的重點問題。

epitem已經準備好了,也就是監聽的socket對象已經有了,就差插入到紅黑樹了,但是在插入之前需要解決個問題,當監聽的對象就緒了之後內核該怎麼辦?
那就是設置回調函數!
這個回調函數是通過函數 ep_ptable_queue_proc 來進行設置的。回調函數是幹什麼的呢?就是當對應的文件描述符上有事件發生,就會調用這個函數,比如socket緩衝區有數據了,內核就會回調這個函數。這個函數就是 ep_poll_callback。
5.3.3.3. 設置回調函數
這一小節就是通過源碼講解如何設置ep_poll_callback回調函數的。
沒有耐心的話可以暫時跳過這一小節,但是強烈建議整體看完之後回看這部分內容。
// file: /include/linux/poll.h
static inline void init_poll_funcptr(poll_table *pt, poll_queue_proc qproc)
{
pt->_qproc = qproc;
pt->_key = ~0UL; /* all events enabled */
}init_poll_funcptr函數將poll_table結構的_qproc函數指針設置為qproc參數,也就是在ep_insert中看到的ep_ptable_queue_proc函數。
接下來輪到ep_item_poll了,扒開它看看。
// file: /fs/eventpoll.c
static inline unsigned int ep_item_poll(struct epitem *epi, poll_table *pt)
{
pt->_key = epi->event.events;
// 這行是重點
return epi->ffd.file->f_op->poll(epi->ffd.file, pt) & epi->event.events;
}重點來了,通過上文我們知道了,ffd.file指的是socket代表的文件,也就是調用了socket文件自己實現的poll方法,也就是上文提到過的sock_poll()。
然後經過下面層層函數調用,最終來到了poll_wait函數。

// file: /include/linux/poll.h
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);
}你看,poll_wait又調用了poll_table的_qproc函數,我們剛剛在init_poll_funcptr中將其設置為了ep_ptable_queue_proc,於是,代碼來到了ep_ptable_queue_proc。
// file: /fs/eventpoll.c
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
...
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
// 設置最終的回調方法ep_poll_callback
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
...
// 將包含ep_poll_callback在內的信息放入socket的等待隊列
add_wait_queue(whead, &pwq->wait);
...
}
}ep_ptable_queue_proc被我簡化地只剩2個函數調用了,我們在3.4節中提到了socket自己維護了一個等待隊列sk_wq,並且這個等待隊列中的每一項保存了阻塞在當前socket上的進程描述符(明確知道該喚醒誰)以及回調函數(內核明確知道數據來了該怎麼做)。
這一系列的操作就是設置回調函數為ep_poll_callback,並封裝隊列項數據結構,然後把這個結構放到socket的等待隊列中。
還有一個小問題,不知道朋友們注意到了沒有,我沒提保存當前用户進程信息這回事兒。這也是epoll更加高效的一個原因,現在socket已經完全託管給epoll了,因此我們不能在一個socket準備就緒的時候就立刻去喚醒進程,喚醒的時機得交給epoll,這就是為什麼eventpoll對象還有一個隊列的原因,裏邊存放的就是阻塞在epoll上的進程。
再看一遍這個結構。

説完這些,你可能在想,交給epoll不也是讓epoll喚醒嘛,有啥區別?還有ep_poll_callback這個回調具體怎麼用也沒解釋。
別急,現在還不是解釋的時候,繼續往下。
5.3.3.4. 插入紅黑樹
最後一步就是通過ep_rbtree_insert(ep, epi)把epitem插入到紅黑樹中。

至此,epoll_ctl的整個調用過程全部結束。
此過程中我沒有解釋關於紅黑樹的任何操作,我也建議大家把它當成一個黑盒,只需要知道epoll底層採用了紅黑樹對epitem進行增刪改查即可,畢竟學習紅黑樹不是我們的重點。
至於為什麼內核開發者選擇了紅黑樹這個結構,自然就是為了高效地管理epitem,使得在插入、查找、刪除等各個方面不會因為epitem數量的增加而產生性能的劇烈波動。
上面幾個小節的所有工作,得到了如下這一張圖。
5.3.4. epoll_wait
epoll本身是阻塞的,阻塞也正是在這一步中體現的。
大部分人聽到阻塞這個詞就覺得很低效,這種想法並不對。
epoll_wait做的事情就是檢查eventpoll對象中的就緒fd列表rdllist中是否有數據,如果有,就説明有socket已經準備好了,那就直接返回,用户進程對該列表中的fd進行處理。
如果列表為空,那就將當前進程加入到eventpoll的進程等待隊列wq中,讓出CPU,主動進入睡眠狀態。
也就是説,只要有活兒(fd就緒),epoll會玩兒命一直幹,絕對不阻塞。但是一旦沒活兒了,阻塞就是一種正確的選擇,要不然一直佔用CPU也是一種極大的浪費。因此,epoll避免了很多不必要的進程上下文切換。
好了,現在來看epoll_wait的實現吧。
// file: /fs/eventpoll.c
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
...
error = ep_poll(ep, events, maxevents, timeout);
...
}static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
...
fetch_events:
...
// 如果就緒隊列上沒有時間發生,進入下面的邏輯
// 否則,就返回
if (!ep_events_available(ep)) {
/*
* We don't have any available event to return to the caller.
* We need to sleep here, and we will be wake up by
* ep_poll_callback() when events will become available.
*/
// 定義等待隊列項,並將當前線程和其進行綁定,並設置回調函數
init_waitqueue_entry(&wait, current);
// 將等待隊列項加入到wq等待隊列中
__add_wait_queue_exclusive(&ep->wq, &wait);
for (;;) {
/*
* We don't want to sleep if the ep_poll_callback() sends us
* a wakeup in between. That's why we set the task state
* to TASK_INTERRUPTIBLE before doing the checks.
*/
// 讓出CPU,進入睡眠狀態
set_current_state(TASK_INTERRUPTIBLE);
...
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))
timed_out = 1;
...
}
...
}
...
}源碼中有部分英文註釋我沒有刪除,讀一下這些註釋可能會對理解整個過程有幫助。
ep_poll做了以下幾件事:
- 判斷
eventpoll的rdllist隊列上有沒有就緒fd,如果有,那就直接返回;否則執行下面的步驟; - 定義
eventpoll的wq等待隊列項,將當前進程綁定至隊列項,並且設置回調函數; - 將等待隊列項加入到
wq隊列; - 當前進程讓出CPU,進入睡眠狀態,進程阻塞。
每一步都比較好理解,我們重點來看一下第2步,也就是init_waitqueue_entry函數。
// file: /include/linux/wait.h
static inline void init_waitqueue_entry(wait_queue_t *q, struct task_struct *p)
{
q->flags = 0;
q->private = p;
q->func = default_wake_function;
}
wait_queue_t就是wq等待隊列項的結構體類型,將其中的private字段設置成了當前進程的task_struct結構體指針。然後將default_wake_function作為回調函數,賦值給了func字段,至於這個回調函數幹嘛用的,還是別急,下文會説的。
於是,這個圖又完整了一些。

5.3.5. 來活兒了
收到數據之後,首先幹苦力活的是網卡,網卡會將數據放到某塊關聯的內存當中,這個操作不需要CPU的參與。等到數據保存完了之後,網卡會向CPU發起一個硬中斷,通知CPU數據來了。
這個時候CPU就要開始對中斷進行處理了,但是CPU太忙了,它必須時時刻刻準備好接收各種設備的中斷,比如鼠標、鍵盤等,而且還不能卡在一箇中斷上太長時間,要不然可以想像我們的計算機得“卡”成什麼樣子。
所以實際設計中硬中斷只負責做一些簡單的事情,然後接着觸發軟中斷,比較耗時且複雜的工作就交給軟中斷處理程序去做了。
軟中斷以內核線程的方式運行,每個CPU都會對應一個軟中斷內核線程,名字叫做ksoftirqd/CPU編號,比如 0 號 CPU 對應的軟中斷內核線程的名字是 ksoftirqd/0,為了方便,我們直接叫做ksoftirqd好了。
從這個角度上來説,操作系統就是一個死循環,在循環中不斷接收各種中斷,處理不同邏輯。
內核線程經過各個函數調用,最終會調用到就緒的socket等待隊列項中的回調函數ep_poll_callback,是時候看看這個函數了。
// file: /fs/eventpoll.c
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
...
// 獲取等待隊列項對應的epitem
struct epitem *epi = ep_item_from_wait(wait);
// 獲取epitem對應的eventpoll實例
struct eventpoll *ep = epi->ep;
...
/* 如果當前epitem指向的socket已經在就緒隊列裏了,那就直接退出
否則,將epitem添加到eventpoll的就緒隊列rdllist中
If this file is already in the ready list we exit soon
*/
if (!ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
}
// 查看eventpoll等待隊列上是否有等待的進程
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
...
}ep_poll_callback的邏輯非常簡潔清晰。
先找到就緒socket對應的等待隊列項中的epitem,繼而找到對應的eventpoll實例,再接口着判斷當前的epitem是不是已經在rdllist就緒隊列裏了,如果在,那就沒啥好做的了,函數退出就行了;如果不在,那就把epitem加入到rdllist中。
最後看看eventpoll的等待隊列上是不是有阻塞的進程,有的話就調用5.3.4節中設置的default_wake_function回調函數來喚醒這個進程。
epoll中重點介紹的兩個回調函數,ep_poll_callback和default_wake_function就串起來了。前者調用了後者,後者喚醒了進程。epoll_wait的最終使命就是將rdllist中的就緒fd返回給用户進程。

5.4. epoll總結
我們來梳理一下epoll的整個過程。
epoll_create創建了eventpoll實例,並對其中的就緒隊列rdllist、等待隊列wq以及紅黑樹rbr進行了初始化;epoll_ctl將我們感興趣的socket封裝成epitem對象加入紅黑樹,除此之外,還封裝了socket的sk_wq等待隊列項,裏邊保存了socket就緒之後的函數回調,也就是ep_poll_callback;epoll_wait檢查eventpoll的就緒隊列是不是有就緒的socket,有的話直接返回;否則就封裝一個eventpoll的等待隊列項,裏邊保存了當前的用户進程信息以及另一個回調函數default_wake_function,然後把當前進程投入睡眠;- 直到數據到達,內核線程找到就緒的socket,先調用
ep_poll_callback,然後ep_poll_callback又調用default_wake_function,最終喚醒eventpoll等待隊列中保存的進程,處理rdllist中的就緒fd; - epoll結束!
等下,還沒結束!在5.3.2節中還留了一個小坑,我説:eventpoll文件也可以被epoll本身監測,也就是説epoll實例可以監聽其他的epoll實例,這一點很重要。
怎麼個重要法,這就涉及到eventpoll實例中的另一個隊列了,叫做poll_wait。
struct eventpoll {
...
wait_queue_head_t wq;
/* 就是它!!!!!!! */
wait_queue_head_t poll_wait;
struct list_head rdllist;
struct rb_root rbr;
struct file *file;
};
如上圖所示
epollfd1監聽了2個普通描述符fd1和fd2epollfd2監聽了epollfd1和2個普通描述符fd3、fd4
如果fd1或fd2有可讀事件觸發,那麼就緒的fd的回調函數ep_poll_callback對將該fd放到epollfd1的rdllist就緒隊列中。由於epollfd1本身也是個文件,它的可讀事件此時也被觸發,但是ep_poll_callback怎麼知道該把epollfd1放到誰的rdllist中呢?
poll_wait來嘍~~
當epoll監聽epoll類型的文件的時候,會把監聽者放入被監聽者的poll_wait隊列中,上面的例子就是epollfd1的poll_wait隊列保存了epollfd2,這樣一來,當epollfd1有可讀事件觸發,就可以在poll_wait中找到epollfd2,調用epollfd1的ep_poll_callback將epollfd1放入epollfd2的rdllist中。
所以poll_wait隊列就是用來處理這種遞歸監聽的情況的。
到此為止,多路複用徹底結束~~~