

深入理解 OpenMP 線程同步機制
前言
在本篇文章當中主要給大家介紹 OpenMP 當中線程的同步和互斥機制,在 OpenMP 當中主要有三種不同的線程之間的互斥方式:
- 使用 critical 子句,使用這個子句主要是用於創建臨界區和 OpenMP 提供的運行時庫函數的作用是一致的,只不過這種方法是直接通過編譯指導語句實現的,更加方便一點,加鎖和解鎖的過程編譯器會幫我們實現。
- 使用 atomic 指令,這個主要是通過原子指令,主要是有處理器提供的一些原子指令實現的。
- OpenMP 給我們提供了 omp_lock_t 和 omp_nest_lock_t 兩種數據結構實現簡單鎖和可重入鎖。
在本篇文章當中主要討論 OpenMP 當中的互斥操作,在下一篇文章當中主要討論 OpenMP 當中原子操作的實現原理,並且查看程序編譯之後的彙編指令。
自定義線程之間的同步 barrier
在實際的寫程序的過程當中我們可能會有一種需求就是需要等待所有的線程都執行完成之才能夠進行後面的操作,這個時候我們就可以自己使用 barrier 來實現這個需求了。
比如我們要實現下面的一個計算式:
$$ data = \frac{1! + 2! + ... + n!}{n} $$
現在我們計算 n = 16 的時候上面的表達式的值:
#include <stdio.h>
#include <omp.h>
int factorial(int n)
{
int s = 1;
for(int i = 1; i <= n; ++i)
{
s *= i;
}
return s;
}
int main()
{
int data[16];
#pragma omp parallel num_threads(16) default(none) shared(data)
{
int id = omp_get_thread_num();
data[id] = factorial(id + 1);
// 等待上面所有的線程都完成的階乘的計算
#pragma omp barrier
long sum = 0;
#pragma omp single
{
for(int i = 0; i < 16; ++i)
{
sum += data[i];
}
printf("final value = %lf\n", (double) sum / 16);
}
}
return 0;
}在上面的代碼當中我們首先讓 16 個線程都計算完成對應的階乘結果之後然後在求和進行除法操作,因此在進行除法操作之前就需要將所有的階乘計算完成,在這裏我們就可以使用 #pragma omp barrier 讓所有的線程到達這個同步點之後才繼續完成後執行,這樣就保證了在進行後面的任務的時候所有線程計算階乘的任務已經完成。
定義臨界區 critical
在併發程序當中我們經常會有這樣的需求,比如不同的線程需要對同一個數據進行求和操作,當然這個操作我們也可以通過 atomic constuct 來完成,但是在本篇文章當中我們使用臨界區來完成,在下一篇完成當中我們將仔細分析 OpenMP 當中的原子操作。
比如我們現在有一個數據 data,然後每個線程需要對這個數據進行加操作。
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main() {
int data = 0;
#pragma omp parallel num_threads(10) shared(data) default(none)
{
#pragma omp critical
{
data++;
}
}
printf("data = %d\n", data);
return 0;
}在上面的 critical 構造當中我們執行了 data ++ 這條語句,如果我們不使用 critical construct 的話,那麼就可能兩個線程同時操作 data++ 這條語句,那麼就會造成結果的不正確性,因為如果兩個線程同時讀取 data 的值等於 0,然後兩個線程同時進行++操作讓 data 的值都變成 1,再寫回,那麼 data 的最終結果將會是 1,但是我們期望的結果是兩個線程進行相加操作之後值變成 2,這就不對了,因此我們需要使用 critical construct 保證同一時刻只能夠有一個線程進行 data++ 操作。
我們知道臨界區的實現是使用鎖實現的,當我們使用 #pragma omp critical 的時候,我們默認是使用的 OpenMP 內部的默認鎖實現的,如果你在其他地方也使用 #pragma omp critical 的話使用的也是同一把鎖,因此即使你用 #pragma omp critical 創建多個臨界區你使用的也是同一把鎖,也就是説這多個臨界區在同一時刻也只會有一個線程在一個臨界區執行,其餘的臨界區是沒有線程在執行的,因為所有的臨界區使用同一把鎖,而一個時刻只能夠有一個線程獲得鎖。
為了解決上面所談到的問題,在 OpenMP 當中使用 critical 構造代碼塊的時候我們可以指定一個名字,以此用不同的鎖在不同的臨界區。
我們現在對上面的情況進行驗證,在下面的程序當中一共有 4 個 section ,首先我們需要知道的是不同的 section 同一個時刻可以被不同的線程執行的,每一個線程只會被執行一次,如果有線程執行過了,那麼它將不會再被執行。
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main()
{
#pragma omp parallel num_threads(4) default(none)
{
#pragma omp sections
{
#pragma omp section
{
#pragma omp critical
{
printf("tid = %d time stamp = %lf\n", omp_get_thread_num(), omp_get_wtime());
sleep(2);
}
}
#pragma omp section
{
#pragma omp critical
{
printf("tid = %d time stamp = %lf\n", omp_get_thread_num(), omp_get_wtime());
sleep(2);
}
}
#pragma omp section
{
#pragma omp critical
{
printf("tid = %d time stamp = %lf\n", omp_get_thread_num(), omp_get_wtime());
sleep(2);
}
}
#pragma omp section
{
#pragma omp critical
{
printf("tid = %d time stamp = %lf\n", omp_get_thread_num(), omp_get_wtime());
sleep(2);
}
}
}
}
return 0;
}上面的程序輸出結果如下所示:
tid = 3 time stamp = 22875738.972305
tid = 0 time stamp = 22875740.972508
tid = 2 time stamp = 22875742.974888
tid = 1 time stamp = 22875744.975045從上面程序的輸出結果我們可以知道,每一次程序的輸出都間隔了 2 秒,這就説明了,所有的打印都是在等之前的線程執行完成之後才執行的,這也就從側面説明了,同一個時刻只能夠有一個線程獲取到鎖,因為使用的是 #pragma omp critical 所有的臨界區都是用同一個鎖——默認鎖。
現在我們修改上面的程序,每一個 critical construct 都使用一個名字進行修飾,讓每一個臨界區使用的鎖不同:
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main()
{
#pragma omp parallel num_threads(4) default(none)
{
#pragma omp sections
{
#pragma omp section
{
#pragma omp critical(A)
{
printf("tid = %d time stamp = %lf\n", omp_get_thread_num(), omp_get_wtime());
sleep(2);
}
}
#pragma omp section
{
#pragma omp critical(B)
{
printf("tid = %d time stamp = %lf\n", omp_get_thread_num(), omp_get_wtime());
sleep(2);
}
}
#pragma omp section
{
#pragma omp critical(C)
{
printf("tid = %d time stamp = %lf\n", omp_get_thread_num(), omp_get_wtime());
sleep(2);
}
}
#pragma omp section
{
#pragma omp critical(D)
{
printf("tid = %d time stamp = %lf\n", omp_get_thread_num(), omp_get_wtime());
sleep(2);
}
}
}
}
return 0;
}上面的程序的輸出結果如下所示:
tid = 1 time stamp = 22876121.253737
tid = 3 time stamp = 22876121.253737
tid = 0 time stamp = 22876121.253737
tid = 2 time stamp = 22876121.253754從上面程序的輸出結果來看,幾乎在同一個時刻所有的 printf 語句被執行。也就是説這些臨界區之間並不互斥,這也就説名了不同的臨界區使用的鎖是不同的。
深入理解 barrier
在上一小節當中我們提到了 critical 可以使用一個名字進行命名,那麼就可以使得不同的臨界區使用不同的鎖,這樣可以提高程序的執行效率。那麼在 OpenMP 當中是否共享 barrier ,我們在前面介紹了 #pragma omp barrier 是否是全局所有的線程共享使用的呢?答案是不共享,因此 barrier 不需要指定名字,我們在使用 barrier 的時候每個並行域的線程組都有一個自己的 barrier 。我們可以通過下面的程序進行分析。
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main()
{
omp_set_nested(1);
#pragma omp parallel num_threads(2) default(none)
{
int parent_id = omp_get_thread_num();
printf("tid = %d\n", parent_id);
sleep(1);
#pragma omp barrier
#pragma omp parallel num_threads(2) shared(parent_id) default(none)
{
sleep(parent_id + 1);
printf("parent_id = %d tid = %d\n", parent_id, omp_get_thread_num());
#pragma omp barrier
printf("after barrier : parent_id = %d tid = %d\n", parent_id, omp_get_thread_num());
}
}
return 0;
}上面的程序其中的一個輸出如下所示:
tid = 0
tid = 1
parent_id = 0 tid = 0
parent_id = 0 tid = 1
after barrier : parent_id = 0 tid = 0
after barrier : parent_id = 0 tid = 1
parent_id = 1 tid = 0
parent_id = 1 tid = 1
after barrier : parent_id = 1 tid = 0
after barrier : parent_id = 1 tid = 1根據上面的程序輸出結果我們可以知道,首先 omp_set_nested(1) 啓動並行嵌套,外部並行域有兩個線程,這兩個線程回分別創建兩個新的並行域,每個並行域裏面都會有一個新的線程組,每個線程組都會有屬於自己的 barrier 變量,也就是説和其他的線程組中的 barrier 是無關的,因此當並行域2中的兩個線程都到達 barrier 之後就會立馬執行最後一個 printf 語句,而不需要等待並行域3中的線程 sleep 完成,而上面的程序的輸出結果也印證了這一點。在上面的代碼當中並行域2中的線程只需要 sleep 1 秒,並行域3中的線程需要 sleep 2 秒,因此並行域2中的線程會先打印,並行域3中的線程會後打印。
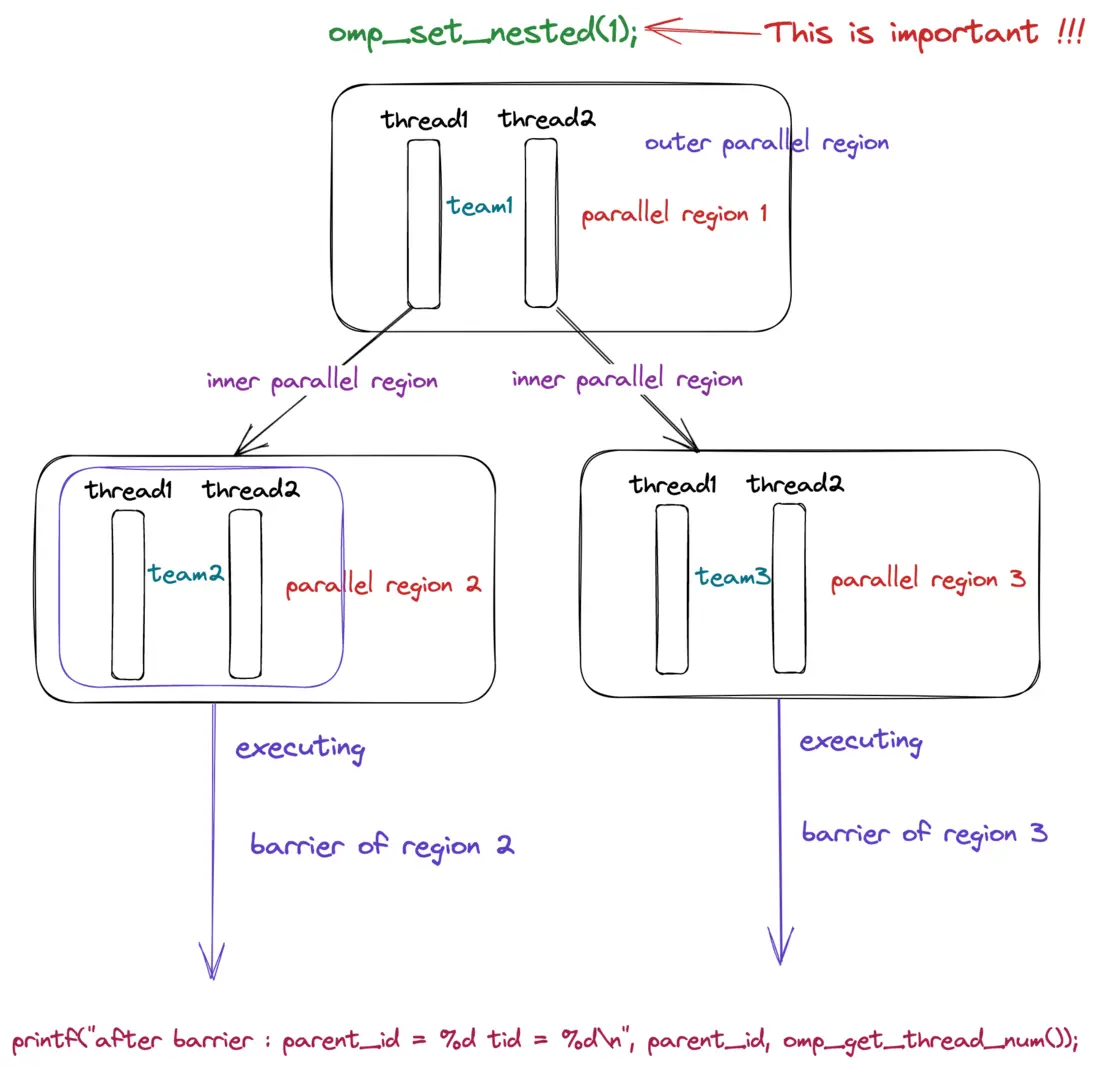
根據上面的分析和圖解大致説明了上面的關於 barrier 代碼的執行流程,更多關於 barrier 的實現細節我們在後面進行 OpenMP 源碼分析的時候再進行分析。
master construct
在 OpenMP 當中還有一個比較實用的指令 master 這個指令的含義主要是代碼塊只有 master 線程才會執行,其餘線程都不會執行。所謂 master 線程就是一個線程組當中線程號等於 0 的線程。
你可能會覺得這個和 single 比較相似,但是和 single 不同的是這個指令最後並沒有一個同步點,而 single 會有一個隱藏的同步點,只有所有的線程到同步點之後線程才會繼續往後執行,我們分析下面的代碼。
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main()
{
#pragma omp parallel num_threads(4) default(none)
{
#pragma omp master
{
sleep(1);
printf("In master construct tid = %d timestamp = %lf\n", omp_get_thread_num(), omp_get_wtime());
}
printf("Out master construct tid = %d timestamp = %lf\n", omp_get_thread_num(), omp_get_wtime());
}
return 0;
}上面的程序的輸出結果如下所示:
Out master construct tid = 3 timestamp = 22892756.871450
Out master construct tid = 2 timestamp = 22892756.871457
Out master construct tid = 1 timestamp = 22892756.871494
In master construct tid = 0 timestamp = 22892757.871576
Out master construct tid = 0 timestamp = 22892757.871614從上面的輸出結果我們可以看到,非 master 線程的時間戳幾乎是一樣的也就是説他們幾乎是同時運行的,而 master 線程則是 sleep 1 秒之後才進行輸出的,而且 master 中的語句只有 master 線程執行,這也就印證了我們所談到的內容。
single construct
在使用 OpenMP 的時候,可能會有一部分代碼我們只需要一個線程去執行,這個時候我們可以時候 single 指令,single 代碼塊只會有一個線程執行,並且在 single 代碼塊最後會有一個同步點,只有 single 代碼塊執行完成之後,所有的線程才會繼續往後執行。我們現在來分析一下下面的程序:
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main()
{
#pragma omp parallel num_threads(4) default(none)
{
double start = omp_get_wtime();
#pragma omp single
{
printf("In single tid = %d ", omp_get_thread_num());
sleep(5);
printf("cost time = %lf\n", omp_get_wtime() - start);
}
printf("Out single tid = %d cost time = %lf\n", omp_get_thread_num(), omp_get_wtime() - start);
}
return 0;
}上面的程序的輸出結果如下所示:
In single tid = 3 cost time = 5.000174
Out single tid = 3 cost time = 5.000229
Out single tid = 0 cost time = 5.000223
Out single tid = 2 cost time = 5.002116
Out single tid = 1 cost time = 5.002282從上面的程序的輸出結果我們可以看到,所有的打印語句輸出的時候和 start 都相差了差不多 5 秒鐘的時間,這主要是因為在 single 代碼塊當中線程 sleep 了 5 秒中。雖然只有一個線程執行 single 代碼塊,但是我們可以看到所有的線程都話費了 5 秒鐘,這正是因為在 single 代碼塊之後會有一個隱藏的同步點,只有並行域中所有的代碼到達同步點之後,線程才能夠繼續往後執行。
ordered construct
odered 指令主要是用於 for 循環當中的代碼塊必須按照循環的迭代次序來執行。因為在循環當中有些區域是可以並行處理的,但是我們的業務需要在某些代碼串行執行(這裏所談到的串行執行的意思是按照循環的迭代次序,比如説 for(int i = 0; i < 10; ++i) 這個次序就是必須按照 i 從 0 到 9 的次序執行代碼),這樣才能夠保證邏輯上的正確性。
比如下面的例子:
#include <stdio.h>
#include <omp.h>
int main()
{
#pragma omp parallel num_threads(4) default(none)
{
#pragma omp for ordered
for(int i = 0; i < 8; ++i)
{
#pragma omp ordered
printf("i = %d ", i);
}
}
return 0;
}上面的程序的輸出結果如下所示:
i = 0 i = 1 i = 2 i = 3 i = 4 i = 5 i = 6 i = 7 上面的程序的輸出結果一定是上面的樣子,絕對不會發生任何順序上的變化,這正是因為 ordered 的效果,他保證了線程的執行順序必須按照循環迭代次序來。
OpenMP 中的線程同步機制
在這一小節當中主要分析 OpenMP 當中的一些構造語句中的同步關係—— single, sections, for ,並且消除這些指令造成的線程之間的同步。
Sections 使用 nowait
在 OpenMP 當中 sections 主要是使不同的線程同時執行不同的代碼塊,但是在每個 #pragma omp sections 區域之後有一個隱藏的同步代碼塊,也就是説只有所有的 section 被執行完成之後,並且所有的線程都到達同步點,線程才能夠繼續執行,比如在下面的代碼當中,printf("tid = %d finish sections\n", omp_get_thread_num()) 語句只有前面的 sections 塊全部被執行完成,所有的線程才會開始執行這條語句,根據這一點在上面的 printf 語句執行之前所有的 section 當中的語句都會被執行。
#include <omp.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
#pragma omp parallel num_threads(4) default(none)
{
#pragma omp sections
{
#pragma omp section
{
int s = omp_get_thread_num() + 1;
sleep(s);
printf("tid = %d sleep %d seconds\n", s, s);
}
#pragma omp section
{
int s = omp_get_thread_num() + 1;
sleep(s);
printf("tid = %d sleep %d seconds\n", s, s);
}
#pragma omp section
{
int s = omp_get_thread_num() + 1;
sleep(s);
printf("tid = %d sleep %d seconds\n", s, s);
}
#pragma omp section
{
int s = omp_get_thread_num() + 1;
sleep(s);
printf("tid = %d sleep %d seconds\n", s, s);
}
}
printf("tid = %d finish sections\n", omp_get_thread_num());
}
return 0;
}
上面的代碼其中的一種輸出結果如下所示:
tid = 1 sleep 1 seconds
tid = 2 sleep 2 seconds
tid = 3 sleep 3 seconds
tid = 4 sleep 4 seconds
tid = 3 finish sections
tid = 2 finish sections
tid = 0 finish sections
tid = 1 finish sections上面的輸出結果是符合我們的預期的,所有的 section 中的 printf 語句打印在最後一個 printf前面,這是因為 sections 塊之後又一個隱藏的同步點,只有所有的線程達到同步點之後程序才會繼續往後執行。
從上面的分析來看,很多時候我們是不需要一個線程執行完成之後等待其他線程的,也就是説如果一個線程的 section 執行完成之後而且沒有其他的 section 沒有被執行,那麼我們就不必讓這個線程掛起繼續執行後面的任務,在這種情況下我們就可以使用 nowait ,使用的編譯指導語句是 #pragma omp sections nowait ,具體的代碼如下所示:
#include <omp.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
#pragma omp parallel num_threads(4) default(none)
{
#pragma omp sections nowait
{
#pragma omp section
{
int s = omp_get_thread_num() + 1;
sleep(s);
printf("tid = %d sleep %d seconds\n", s, s);
}
#pragma omp section
{
int s = omp_get_thread_num() + 1;
sleep(s);
printf("tid = %d sleep %d seconds\n", s, s);
}
#pragma omp section
{
int s = omp_get_thread_num() + 1;
sleep(s);
printf("tid = %d sleep %d seconds\n", s, s);
}
#pragma omp section
{
int s = omp_get_thread_num() + 1;
sleep(s);
printf("tid = %d sleep %d seconds\n", s, s);
}
}
printf("tid = %d finish sections\n", omp_get_thread_num());
}
return 0;
}上面的程序的輸出結果如下所示:
tid = 1 sleep 1 seconds
tid = 0 finish sections
tid = 2 sleep 2 seconds
tid = 1 finish sections
tid = 3 sleep 3 seconds
tid = 2 finish sections
tid = 4 sleep 4 seconds
tid = 3 finish sections從上面的輸出結果我們可以看到,當一個線程的 section 代碼執行完成之後,這個線程就立即執行最後的 printf 語句了,也就是説執行完成之後並沒有等待其他的線程,這就是我們想要的效果。
Single 使用 nowait
在 OpenMP 當中使用 single 指令表示只有一個線程執行 single 當中的代碼,但是需要了解的是在 single 代碼塊最後 OpenMP 也會幫我們生成一個隱藏的同步點,只有執行 single 代碼塊的線程執行完成之後,所有的線程才能夠繼續往後執行。比如下面的示例程序:
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main()
{
double start = omp_get_wtime();
#pragma omp parallel num_threads(4) default(none) shared(start)
{
#pragma omp single
sleep(5);
printf("tid = %d spent %lf s\n", omp_get_thread_num(), omp_get_wtime() - start);
}
double end = omp_get_wtime();
printf("execution time : %lf", end - start);
return 0;
}在上面的代碼當中啓動了 4 個線程,在 single 的代碼塊當中需要 sleep 5秒鐘,因為上面的代碼不帶 nowait,因此雖然之後一個線程執行 sleep(5),但是因為其他的線程需要等待這個線程執行完成,因此所有的線程都需要等待 5 秒。因此可以判斷上面的代碼輸出就是每個線程輸出的時間差都是 5 秒左右。具體的上面的代碼執行結果如下所示:
tid = 2 spent 5.002628 s
tid = 3 spent 5.002631 s
tid = 0 spent 5.002628 s
tid = 1 spent 5.005032 s
execution time : 5.005076從上面的輸出結果來看正符合我們的預期,每個線程花費的時間都是 5 秒左右。
現在我們使用 nowait 那麼當一個線程執行 single 代碼塊的時候,其他線程就不需要進行等待了,那麼每個線程花費的時間就非常少。我們看下面的使用 nowait 的程序的輸出結果:
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main()
{
double start = omp_get_wtime();
#pragma omp parallel num_threads(4) default(none) shared(start)
{
#pragma omp single nowait
sleep(5);
printf("tid = %d spent %lf s\n", omp_get_thread_num(), omp_get_wtime() - start);
}
double end = omp_get_wtime();
printf("execution time : %lf", end - start);
return 0;
}上面的代碼執行結果如下所示:
tid = 2 spent 0.002375 s
tid = 0 spent 0.003188 s
tid = 1 spent 0.003202 s
tid = 3 spent 5.002462 s
execution time : 5.002538可以看到的是線程 3 執行了 single 代碼塊但是其他的線程並沒有執行,而我們也使用了 nowait 因此每個線程花費的時間會非常少,這也是符合我們的預期。
For 使用 nowait
for 的原理其實和上面兩個使用方式也是一樣的,都是不需要在同步點進行同步,然後直接執行後面的代碼。話不多説直接看代碼
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main()
{
double start = omp_get_wtime();
#pragma omp parallel num_threads(4) default(none) shared(start)
{
#pragma omp for
for(int i = 0; i < 4; ++i)
{
sleep(i);
}
printf("tid = %d spent %lf s\n", omp_get_thread_num(), omp_get_wtime() - start);
}
double end = omp_get_wtime();
printf("execution time : %lf", end - start);
return 0;
}在上面的程序當中啓動的一個 for 循環,有四個線程去執行這個循環,按照默認的調度方式第 i 個線程對應的 i 的值就是等於 i 也就是説,最長的一個線程 sleep 的時間為 3 秒,但是 sleep 1 秒或者 2 秒和 3 秒的線程需要進行等待,因此上面的程序的輸出結果大概都是 3 秒左右。具體的結果如下圖所示:
tid = 0 spent 3.003546 s
tid = 1 spent 3.003549 s
tid = 2 spent 3.003558 s
tid = 3 spent 3.003584 s
execution time : 3.005994現在如果我們使用 nowait 那麼線程不需要進行等待,那麼線程的話費時間大概是 0 秒 1 秒 2 秒 3 秒。
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main()
{
double start = omp_get_wtime();
#pragma omp parallel num_threads(4) default(none) shared(start)
{
#pragma omp for nowait
for(int i = 0; i < 4; ++i)
{
sleep(i);
}
printf("tid = %d spent %lf s\n", omp_get_thread_num(), omp_get_wtime() - start);
}
double end = omp_get_wtime();
printf("execution time : %lf", end - start);
return 0;
}查看下面的結果,也是符號我們的預期的,因為線程之間不需要進行等待了。
tid = 0 spent 0.002358 s
tid = 1 spent 1.004497 s
tid = 2 spent 2.002433 s
tid = 3 spent 3.002427 s
execution time : 3.002494總結
在本篇文章當中主要給大家介紹了一些經常使用的 OpenMP 用於線程之間同步的指令,並且用實際例子分析它內部的工作機制,以及我們改如何使用 nowait 優化程序的性能,以上就是本篇文章的所有內容希望大家有所收穫!
更多精彩內容合集可訪問項目:https://github.com/Chang-LeHu...
關注公眾號:一無是處的研究僧,瞭解更多計算機(Java、Python、計算機系統基礎、算法與數據結構)知識。

