

1. 前言
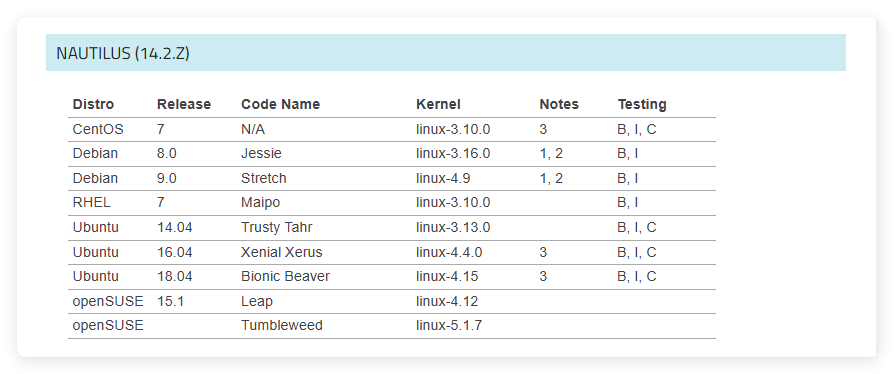
上表中是 Ceph 官方文檔給出的 Ceph 14 系列的系統和內核推薦,其中在centos 7、ubuntu 14.04、ubuntu 16.04、ubuntu 18.04上都做了完整的測試。本文將介紹如何在ubuntu 18.04中使用 ceph-deploy 部署 ceph 集羣,ceph 版本為14.2.22。
2. 準備
2.1. 集羣規劃
component name component type node ip node name
----------------------------------------------------------------------
[mon.node1] mon 192.168.3.11 node1
[mgr.node1] mgr 192.168.3.11 node1
[osd.0] osd 192.168.3.11 node1
[osd.1] osd 192.168.3.12 node2
[osd.2] osd 192.168.3.13 node3
[ceph-deploy] - 192.168.3.10 node0
在 ceph 集羣中,安裝了 ceph 軟件的並且部署了一系列 ceph 集羣服務的主機被稱之為 ceph 集羣節點。node0 雖然屬於管理節點,但它並不屬於 ceph 集羣,它沒有安裝任何 ceph 軟件,也沒有部署任何 ceph 集羣服務。
2.2. 新建用户
ceph-deploy 部署 ceph 到不同節點上,是通過 ssh 方式登錄到不同節點上,然後執行一系列指令。默認情況下,ssh 需要輸入對應的用户名和節點 ip。為了方便管理集羣中每一個節點,官方建議為 ceph 集羣中每一個節點都創建一個新的相同的用户名。由於 ceph-deploy 是完全自動化腳本,在部署 ceph 集羣時,是不支持交互式操作。當使用 ssh 登錄到集羣中某個節點時,要求輸入遠程節點的密碼,因此必須要設置 ssh 免密登錄。同時 ceph-deploy 中使用了大量的 sudo 權限的指令,因此必須要求當前用户免輸入密碼。
如果想直接將
root用户作為 ceph 集羣用户,可以直接忽略此步驟,本文就是使用的 root 用户,以下創建用户以及用户設置只是一個參考。
2.2.1. 創建一個新用户
在集羣所有節點(node1-node3)上執行以下命令:
useradd -d /home/cephtest -m cephtest
passwd cephtest
其中cephtest 為用户名,該命令將會在 node1、node2 和 node3 上創建名為 cephtest 的普通用户,用户密碼為 cephtest。
2.2.2. 獲取免密的 sudo 權限
在集羣所有節點(node1-node3)上執行以下命令:
echo "cephtest ALL = (root) NOPASSWD:ALL" > /etc/sudoers.d/cephtest
chmod 0440 /etc/sudoers.d/cephtest
其中cephtest為用户名,該命令將使得 node1、node2 和 node3 上名為 cephtest 的普通用户獲取免密的 root 權限。
2.2.3. 設置 ssh 免密登錄
生成 ssh key
在管理節點(node0)上執行ssh-keygen,一路回車,不要輸入任何東西。
將 ssh key 拷貝到所有節點上
在管理節點(node0)上執行以下命令:
ssh-copy-id cephtest@192.168.3.11
ssh-copy-id cephtest@192.168.3.12
ssh-copy-id cephtest@192.168.3.13
其中cephtest為用户名,192.168.3.11、192.168.3.12、192.168.3.13為集羣節點的 ip 地址,該命令將 ssh key 分發到集羣所有節點中。
以上 2 個步驟是設置免密登錄,以下的步驟是設置免用户登錄。由前述可知,ssh 遠程登錄需要指定用户名和節點 ip。當然 ceph-deploy 可以通過--username參數指定用户名。此處建議在~/.ssh/config文件中指定用户名,可以避免 ceph-deploy 部署時要求指定用户。
2.2.4. 設置 ssh 免用户登錄
2.2.4.1. 修改/etc/hosts
在集羣節點(node1-node3)和管理節點(node0)的/etc/hosts文件中追以下相同內容:
192.168.3.11 node1
192.168.3.12 node2
192.168.3.13 node3
2.2.4.2. 修改~/.ssh/config
在管理節點(node0)上,新建~/.ssh/config文件,並添加以下內容:
Host node1
Hostname node1
User cephtest
Host node2
Hostname node2
User cephtest
Host node3
Hostname node3
User cephtest
2.2.4.3. 修改 hostname
建議統一修改集羣節點的主機名,在集羣節點之間來回切換時,很容易通過終端主機名查看該主機是哪個節點。
在集羣所有節點(node1-node3)上執行以下命令:
hostname node1
hostname node2
hostname node3
其中node1、node2和node3是集羣節點的 hostname。
通過以上步驟,就可以直接用形如ssh node1方式直接遠程登錄集羣中其他節點上,而不用輸入用户名和密碼。
2.3. 設置時間同步
在 ceph 集羣中,osd 進程心跳機制,mon 進程維護集羣 map,要求每個主機之間時間同步,否則會影響集羣。在 ubuntu 系統上可以安裝 ntp 服務和 ntpdate 客户端工具實現時間同步。在集羣節點中只需要一個 ntp 服務,其他集羣節點安裝 ntpdate 客户端工具即可。
2.3.1. 安裝 ntp 服務
在集羣節點(node1)上執行以下命令:
apt install ntp
2.3.2. 安裝 ntpdate 客户端
在集羣節點(node2-node3)上執行以下命令:
apt install ntpdate
以上將 node1 作為 ntp 服務端,node2-node3 為 ntp 客户端,node2-node3 通過 ntpdate 工具實現與 node1 時間同步。
2.4. 安裝 ceph-deploy
使用 ceph-deploy 部署 ceph 集羣,需要下載安裝 ceph-deploy 工具。ubuntu 自帶 ceph-deploy 安裝包,但該版本不一定支持 ceph-14.2.22 版本,需要從 ceph 官方下載 ceph14.2.22 對應版本的 ceph-deploy 工具。
2.4.1. 配置 ceph-14.2.22 軟件源
為了加快下載速度,此處使用阿里雲開源鏡像站,在管理節點(node0)上執行以下命令:
echo "deb https://mirrors.aliyun.com/ceph/debian-nautilus/ bionic main" > /etc/apt/sources.list.d/ceph.list
2.4.2. 添加 release key
在管理節點(node0)上執行以下命令
wget -q -O- 'https://mirrors.aliyun.com/ceph/keys/release.asc' | apt-key add -
2.4.3. 安裝 ceph-deploy
在管理節點(node0)上執行以下命令:
apt install ceph-deploy
3. 集羣部署
如果之前已經安裝了 ceph,無論是哪個版本的,請按照集羣卸載步驟執行卸載操作。
3.1. 創建臨時目錄
ceph-deploy 在部署 ceph 集羣過程中會產生一些日誌文件、配置文件以及 ceph 必備的文件。為了方便管理,建議創建一個臨時目錄來存放這些文件。
在管理節點(node0)上執行以下命令:
mkdir cluster
上述命令創建一個名為 clustre 的臨時文件夾,之後所有的關於 ceph-deploy 的操作都必須在cluster目錄下執行。
3.2. 初始化集羣
在管理節點(node0)上執行以下命令:
ceph-deploy new node1
其中 node1 為集羣 MON 節點的 hostname,該命令將初始化 Ceph 集羣 conf 和 keyring 文件並初始化 MON 名字,可以同時指定多個 MON 節點 hostname。
3.3. 安裝 ceph 軟件
在管理節點(node0)上執行以下命令:
ceph-deploy install node1 node2 node3 \
--repo-url=https://mirrors.aliyun.com/ceph/debian-nautilus \
--gpg-url=https://mirrors.aliyun.com/ceph/keys/release.asc
其中node1 node2和node3為集羣節點。--repo-url是 ceph 軟件倉庫的地址,--gpg-url是 ceph 軟件倉庫中 key 的地址。默認情況下,ceph-deploy 安裝腳本中指定的是 ceph13 版本的地址,所以需要重新指定為 ceph14 版本的地址。上述命令將在 node1、node2 和 node3 上安裝 ceph 相關軟件,可以同時指定多個 hostname。
3.4. 創建和初始化 mon 進程
在管理節點(node0)上執行以下命令:
ceph-deploy mon create-initial
上述命令將會初始化所有的 mon 進程。
3.5. 創建 mgr 進程
在管理節點(node0)上執行以下命令:
ceph-deploy mgr create node1
上述命令將在 node1 上創建 mgr 進程。
3.6. 創建 osd 進程
ceph 支持 2 種存儲引擎:bluestore和filestore。filestore 模式下,可以看到數據存在哪個目錄下,而 bluestore 則無法看到。filestore 是一個過時的技術,在後續版本中逐漸被 Ceph 棄用,filestore 已經沒有任何研究價值,因此本文默認以 bluestore 為準。
在管理節點(node0)上執行以下命令:
ceph-deploy osd create --data /dev/sdb node1
ceph-deploy osd create --data /dev/sdb node2
ceph-deploy osd create --data /dev/sdb node3
其中/dev/sdb是磁盤設備,node1、node2和node3是集羣節點的 hostname。
3.7. 分發 key
ceph 通過 ceph 命令來管理集羣,如果想要使用 ceph 命令,需要將相關的 key 文件和 ceph.conf 文件放到指定路徑下。
在管理節點(node0)上執行以下命令:
ceph-deploy admin node1 node2 node3
其中node1、node2和node3是集羣節點 hostname,該命令將 key 文件和 ceph.conf 文件分發到 node1、node2 和 node3 上,可以同時指定多個 hostname。
3.8. 修改 ceph.client.admin.keyring 權限
普通用户對/etc/ceph/ceph.client.admin.keyring文件沒有讀權限,在執行 ceph 相關命令的時候,需要讀取該文件中的 key 值信息,因此需要為該文件添加普通用户讀權限。
在集羣所有節點(node1-node3)上執行以下命令:
chmod +r /etc/ceph/ceph.client.admin.keyring
3.9. 查看集羣狀態
在上述分發的任意的一個集羣節點(node1、node2、node3)上執行ceph -s便可以查看到集羣的狀態信息。
ceph -s
---------
cluster:
id: 4a7760d1-22b6-49d3-8236-31962c941632
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
services:
mon: 1 daemons, quorum node1 (age 3m)
mgr: node1(active, since 3m)
osd: 3 osds: 3 up (since 80s), 3 in (since 80s)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 12 GiB / 15 GiB avail
pgs:
4. 集羣卸載
刪除集羣很簡單,但也容易刪除不乾淨,主要包括:卸載 ceph 軟件、清楚磁盤數據、刪除邏輯卷。
4.1. 刪除 ceph 軟件
在管理節點(node0)上執行以下命令:
ceph-deploy purge node1 node2 node3
其中node1、node2和node3是集羣節點的 hostname,該命令將會刪除 node1、node2 和 node3 中 ceph 相關的所有軟件,可以同時指定多個 hostname。
4.2. 刪除數據
在管理節點(node0)上執行以下命令:
ceph-deploy purgedata node1 node2 node3
其中node1、node2和node3是集羣節點的 hostname,該命令將會清除 node1、node2 和 node3 中 ceph 所有配置文件和數據文件,可以同時指定多個 hostname。
4.3. 刪除密鑰
在管理節點(node0)上執行以下命令:
ceph-deploy forgetkeys
4.4. 刪除邏輯卷
ceph-deploy 在創建 osd 時,會將每個 osd 對應的硬盤以邏輯卷的形式掛在到系統中。有時候會遇到,如果不刪除 osd 對應的邏輯卷,下次再部署相同 id 的 osd 時,會發現 osd 對應的邏輯卷已經存在,直接導致 osd 創建失敗,所以有必要刪除 osd 邏輯卷。
4.4.1. 查看 osd 邏輯卷
在部署 osd 的集羣節點上執行以下命令:
vgdisplay -s | grep ceph
-----------------------------------------------------------------------------------------------------------------------
"ceph-7d7f39a3-f9f1-47ba-88ea-1f9b1c53e7a4" 9.00 GiB [9.00 GiB used / 0 free]
"ceph-310bbc06-b539-42aa-a7d6-ed430310f95f" 9.00 GiB [9.00 GiB used / 0 free]
"ceph-4258b146-2d7d-4132-985d-63a2148e6d4a" 9.00 GiB [9.00 GiB used / 0 free]
其中ceph-7d7f39a3-f9f1-47ba-88ea-1f9b1c53e7a4 就是 vg name。
4.4.2. 刪除 osd 邏輯卷
在部署 osd 節點上執行以下命令:
vgremove ceph-7d7f39a3-f9f1-47ba-88ea-1f9b1c53e7a4
5. 參考資料
-
https://docs.ceph.com/en/octopus/start/os-recommendations
-
https://docs.ceph.com/en/nautilus/start/