

面試被問“系統架構選型”時,是否總被“去中心化”“主從架構”“HA(高可用)”繞暈?這三個概念看似複雜,實則邏輯清晰。本文用1個比喻+3張對比圖,幫你1分鐘理清關係,從此架構設計不踩坑!
一、核心概念速覽:用“開公司”比喻理解
假設你要開一家連鎖餐廳,需要設計一套“管理員工(服務節點)”的架構:
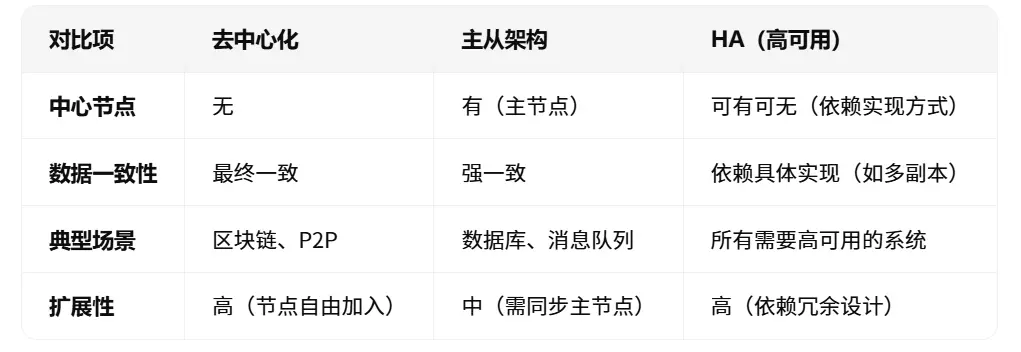
去中心化:沒有總店長,每家分店(節點)自主決策,互相協作(如P2P網絡)。
主從架構:設1個總店長(主節點)統籌,分店(從節點)執行指令(如MySQL主從複製)。
HA(高可用):確保“總店長”或“分店”出問題時,系統仍能運行(如雙機熱備)。
關鍵區別:
去中心化 vs 主從架構:有無中心節點;
主從架構 vs HA:HA是目標,主從是實現手段之一。
二、分場景拆解:3種架構的適用場景與優缺點
- 去中心化架構:無“老闆”的平等協作
典型場景:區塊鏈、P2P文件共享(如BitTorrent)、分佈式存儲(如IPFS)。
核心特點:
無單點故障:沒有中心節點,任意節點宕機不影響整體。
可擴展性強:新增節點直接加入網絡,無需中心協調。
一致性難保證:節點間通過協議協商(如Gossip協議),可能存在數據短暫不一致。
案例:
比特幣網絡:所有節點平等,交易需全網驗證,避免中心化操控。
IPFS存儲:文件碎片分散在多個節點,無中心服務器控制。
適用場景:
對容錯性要求極高(如金融交易);
需要快速擴展且成本敏感(如物聯網設備組網)。
缺點:
決策效率低(需全網共識);
開發複雜度高(需處理節點間通信與衝突)。 - 主從架構:1個“老闆”+N個“員工”
典型場景:數據庫讀寫分離(如MySQL主從)、消息隊列(如Kafka分區)、緩存集羣(如Redis主從)。
核心特點:
主節點負責寫操作,從節點同步數據並處理讀請求。
數據強一致:主節點寫入成功後,從節點必須同步完成。
單點瓶頸:主節點故障時,需手動或自動切換從節點為主(需配合HA)。
案例:
MySQL主從複製:主庫處理寫請求,從庫提供讀服務,減輕主庫壓力。
Kafka分區:每個分區有1個Leader(主)和多個Follower(從),確保數據不丟失。
適用場景:
讀多寫少的業務(如電商商品查詢);
需要數據強一致的場景(如訂單系統)。
缺點:
主節點性能壓力大;
故障切換需額外機制(如HA)。 - HA(高可用):讓系統“永不停機”
核心目標:通過冗餘設計,確保系統7×24小時運行,即使部分組件故障也不影響服務。
實現手段:
主從架構+故障自動切換(如MySQL自動failover);
多活架構(如異地多數據中心,如阿里雲多AZ部署);
負載均衡(如Nginx分流請求,避免單節點過載)。
案例:
AWS RDS多可用區部署:主數據庫在一個AZ,從數據庫在另一個AZ,主故障時自動切換。
Kubernetes集羣:通過Pod自動重啓與節點調度,確保服務不中斷。
關鍵指標:
RTO(恢復時間目標):故障後恢復服務的時間(越短越好);
RPO(恢復點目標):故障時丟失的數據量(越小越好)。
適用場景:
對可用性要求極高的業務(如支付、醫療系統);
無法接受停機損失的場景(如在線教育直播)。
三、3張對比圖:1秒看懂差異
四、面試高頻問題:如何回答?
Q1:去中心化架構是否比主從架構更優?
答:不一定。去中心化適合容錯性要求高、可接受短暫不一致的場景(如區塊鏈);主從架構適合需要強一致且讀多寫少的場景(如數據庫)。選擇需結合業務需求。
Q2:HA是否必須用主從架構?
答:不是。HA是目標,主從是手段之一。其他方式如多活架構、負載均衡也能實現HA。
Q3:如何設計一個高可用的去中心化系統?
答:需結合去中心化協議(如Gossip)與冗餘設計(如多副本存儲),同時通過共識算法(如Raft)保證數據一致性。
結語:架構設計沒有“最優解”,只有“最適合”
去中心化、主從架構、HA並非對立關係,而是解決不同問題的工具。理解它們的核心邏輯後,你就能根據業務需求(如一致性、可用性、成本)靈活組合,設計出“既穩定又高效”的系統!