
編者按: 當 AI 編程智能體宣稱能自動化一切時,我們是否在工具與概念的叢林中迷失了方向,反而忘記了如何最簡單、直接地解決問題?
本文的核心主張尖鋭而明確:與其追逐繁雜的“智能體套件”、子智能體(Subagents)、RAG 等概念,不如迴歸本質 —— 選擇一個強大且高效的模型,像與一位靠譜的工程師同事那樣,通過簡潔的對話和直覺性的協作來直接解決問題。作者直言不諱地批評了當前生態中許多“華而不實”的工具,認為它們不過是繞開模型本身低效的臨時補丁,並分享了他如何用多個終端窗口和經典工具(如 tmux)實現比許多專用工具更靈活、更可控的工作流。
本文系原作者觀點,Baihai IDP 僅進行編譯分享
作者 | Peter Steinberger
編譯 | 嶽揚
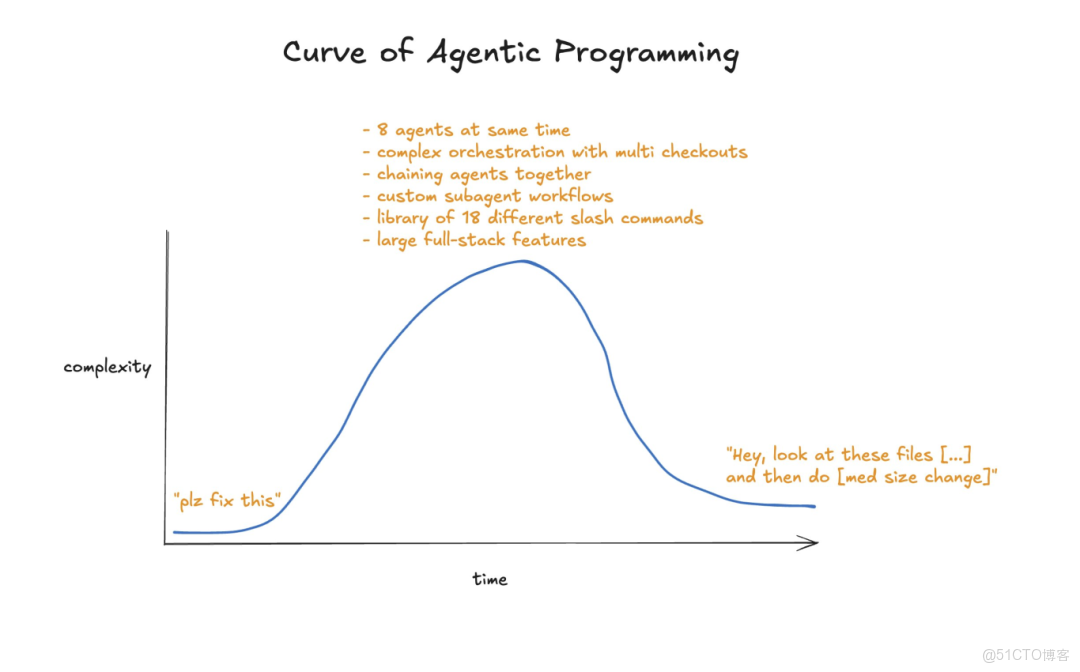
最近我沒怎麼在社交平台上活躍,因為我正全身心投入到最新的項目中。如今,智能體工程(Agentic engineering)已經變得非常強大,幾乎能編寫出我需要的 100% 的代碼。然而,我卻看到很多人還在費力解決本不該存在的問題,搞出一堆繁複的表演,而不是專注把事搞定。
這篇文章的部分靈感來自最近在倫敦參加的“Claude Code Anonymous”活動[1]上的對話,另一部分則是因為距離我上次更新工作流已經整整一年(還是 AI 年[2]😏)。是時候做個回顧了。
所有基礎理念依然適用,像上下文管理這類簡單內容本文不再贅述。想了解基礎內容,請閲讀我之前寫的《Optimal AI Workflow》[3]一文。
01 我的工作背景與技術棧
我是一名獨立開發者,當前開發的項目是一個約 30 萬行代碼的 TypeScript React 應用,外加一個 Chrome 擴展、一個 CLI 工具、一個基於 Tauri 的客户端應用,以及一個使用 Expo 的移動應用。網站託管在 Vercel 上,每次 PR 後大約兩分鐘就能測試新版本,其他應用尚未實現自動化部署。
02 我所使用的技術工具和處理開發任務的總體思路
我已完全改用 codex cli 作為主力工具。通常我會在一個 3x3 的終端網格中同時運行 3 到 8 個實例,它們大多位於同一目錄[4],部分實驗性任務則會放在獨立文件夾中。我嘗試過 worktrees、PR 等方式,但總會回到當前這套配置,因為它能最快地把事情做完。
我的智能體(agents)會自行執行原子化的 Git commits[5]。為了保持相對乾淨的 commit 歷史,我在 agent 配置文件[6]上反覆迭代優化。這樣一來,Git 操作更精準,每個智能體只提交它實際修改過的文件。
是的,用 Claude 你可以設置 hooks(譯者注:可能是 git commit hook),而 codex 目前還不支持 hooks,但大模型極其聰明 —— 一旦它們下定決心,沒有任何 hook 能攔得住[7]。
過去我曾因此被嘲諷為垃圾代碼製造機[8],如今看到並行運行智能體的做法逐漸成為主流[9],深感欣慰。
03 模型選擇
我幾乎所有的開發工作都交由 gpt-5-codex 在“medium 配置”下完成。它在智能程度與速度之間取得了極佳的平衡,還能自動調節思考深度。我發覺過度糾結這些設置並無明顯的回報,而且不用操心“超深度思考”(ultrathink)的感覺真的很輕鬆。
3.1 爆炸半徑 💥
每次工作時,我都會考量“爆炸半徑” —— 這個詞不是我發明的,但我非常喜歡。當構思某個改動時,我基本能預判其耗時及波及的文件範圍。我可以向代碼庫投擲多枚“小手雷”,或是一發“胖子”配幾顆小炸彈。但如果你同時扔下多個大炸彈,就幾乎不可能做出隔離良好的提交,一旦出錯也更難回滾。
這同時也是我觀察智能體運行時的一個重要指標。如果某項任務耗時超出預期,我會直接按 Esc,然後問一句“當前狀態如何?”來獲取任務進度,再決定是幫模型調整方向、中止任務,還是繼續執行。別害怕在中途打斷模型 —— 文件修改是原子性的,它們非常擅長接續未完成的工作。
當我對改動的影響不確定時,會先讓模型“在修改前給我幾個選項”,以此評估影響範圍。
3.2 為何不用 Worktree?
我始終只運行一個開發服務器。在迭代項目時,我會通過實時操作界面,一次性測試多處改動。如果為每個功能變更都創建獨立的工作樹(worktree)或分支(branch),會嚴重拖慢我的測試流程。而同時啓動多個開發服務器又會帶來不必要的操作負擔。此外,我的項目受 Twitter OAuth 規則限制,只能註冊有限數量的回調域名,這從客觀上也不支持多環境並行的開發方式。
3.3 那 Claude Code 呢?
我曾經很喜歡 Claude Code,但如今實在受不了了(即便 codex 對其讚譽有加[10])。那種語言風格、那種斬釘截鐵的“絕對正確”[11]、那種測試明明失敗卻宣稱“100%滿足生產要求”的語氣——實在令人無法繼續。相比之下,codex 更像是那個內向但靠譜的工程師:默默推進,把事情做完。它在開始工作前會讀取更多文件,因此即使是簡短的提示詞,通常也能精準實現我想要的效果。
在我關注的信息流中,大家已普遍認為 codex 才是當前的首選[12-13]。
3.4 codex 的其他優勢
- 約 23 萬的可用上下文(context),而 Claude 只有 15.6 萬。 是的,如果你運氣好或願意按 API 定價付費,Sonnet 確實有 100 萬上下文,但現實中 Claude 在耗盡上下文之前就已經開始胡言亂語了,所以這個超長上下文實際上並不可用。
- 更高的 token 利用效率。 我不知道 OpenAI 做了什麼不同處理,但我的上下文空間在 codex 中消耗得明顯更慢。用 Claude 時我經常看到 “Compacting…” 提示,而在 Codex 中我極少觸及上下文上限。
- 消息隊列(Message Queuing)。 Codex 支持消息排隊[14]。Claude 以前也有這功能,但幾個月前改成了“消息會實時引導模型”的機制。如果我想引導 codex,只需按 Esc 再回車就能發送新消息。能同時選擇“排隊”或“即時干預”顯然更好。我經常一次性將多個相關功能任務放入隊列,它總能可靠地逐個完成。
- 速度。OpenAI 用 Rust 重寫了 codex,效果立竿見影 —— 響應速度快得驚人。 而用 Claude Code 時,我經常遇到數秒的卡頓,內存佔用動輒飆到幾個 GB。還有終端顯示的閃爍問題,尤其是在用 Ghostty 時。Codex 完全沒有這些問題,感覺極其輕量、流暢。
- 語言風格。 這點對我的心理健康真的很重要[15]。我曾無數次對 Claude 大吼大叫,但很少對 codex 發火。哪怕 codex 模型能力稍弱,光憑這一點我也願意用它。只要你兩個都用上幾周,就懂我在説什麼。
- 不會到處亂生成 markdown 文件[16]。懂的都懂(IYKYK)[17]。
3.5 為何不選用其他開發工具
在我看來,終端用户和大模型公司之間其實沒有太多中間空間。我目前通過訂閲獲得的性價比遠高於其他方式。我現在有 4 個 OpenAI 訂閲和 1 個 Anthropic 訂閲,每月總花費大約 1000 美元,基本可以享受“無限 token”的使用體驗。如果改用 API 調用,成本大概會高出 10 倍。別太較真這個數字——我用過像 ccusage 這樣的 token 統計工具,數據多少有些不精確,但即便只是五倍,也已是相當划算的交易了。
我很欣賞像 amp 或 Factory 這樣的工具,但我不認為它們能長期存活。無論是 codex 還是 Claude Code,每個版本都在變得更強,而且功能理念正在快速趨同。某些工具可能在待辦列表、引導控制或細微的開發者體驗(DX)上暫時領先,但我不覺得它們能真正超越大型 AI 公司。
amp 已經不再以 GPT-5 為核心驅動,轉而稱其為“Oracle”(神諭)[18]。而我直接使用 codex,本質上就是一直在和那個更聰明的模型——也就是“Oracle”——打交道。是的,有各種基準測試[19],但考慮到使用場景的巨大不同,我不太信任那些結果。實際體驗中,codex 給我的輸出遠優於 amp。不過我得承認,他們在會話共享方面確實做了些有趣的創新。
Factory?我還沒被説服。他們的演示視頻有點尷尬,雖然我在信息流裏確實聽到一些正面評價 —— 儘管目前還不支持圖像(至少現在還不行),而且也有標誌性的閃爍問題[20]。
Cursor……如果你還在親手寫代碼,那它的 Tab 補全模型確實是業界領先。我主要用 VS Code,但確實欣賞他們在瀏覽器自動化和計劃模式(plan mode)等方面的探索。我試過 GPT-5-Pro,但 Cursor 依然存在那些從五月起就讓我煩躁的 bug[21]。聽説他們正在修復,所以它還留在我的程序塢裏。
像 Auggie 這樣的工具,只在我的信息流上曇花一現,之後就再沒人提過。歸根結底,它們底層無非是封裝了 GPT-5 和/或 Sonnet,完全可以被替代。RAG 對 Sonnet 或許有點用,但 GPT-5 本身在代碼檢索上已經強到根本不需要額外的向量索引。
目前最有希望的是 opencode 和 crush,尤其是搭配開源模型使用時。你當然也能通過它們使用 OpenAI 或 Anthropic 的訂閲(得益於一些巧妙的技術手段[22]),但這是否合規仍存疑,況且為何要為一個專為 Codex 或 Claude Code 優化的模型,配上一個能力較弱的“外殼”呢。
3.6 關於開源模型
基準測試只能説明一半的問題。在我看來,智能體工程(agentic engineering)大約在 Sonnet 4.0 發佈的五月,才真正從“這玩意兒真爛”邁入“這還不錯”的階段;而隨着 gpt-5-codex 的出現,我們又迎來了一次更大的進步 —— 從“不錯”直接進入“這簡直太棒了”的境界。
3.7 計劃模式(Plan Mode)與方法
基準測試所忽略的,是模型與工具在接到指令後所採取的策略。codex 要謹慎得多 —— 它會在決定行動前讀取你代碼庫中更多的文件。當你提出一個荒謬請求時,它也更傾向於明確反對[23]。相比之下,Claude 或其他智能體會更急切地直接動手嘗試。雖然可以通過“計劃模式”(plan mode)和嚴謹的結構化文檔來緩解這個問題,但對我而言,這感覺像是在給一個有缺陷的系統打補丁。
如今我幾乎不再為 codex 使用大型的計劃文件。其實 codex 甚至沒有專門的計劃模式(plan mode) —— 但它對提示詞的理解和遵循能力實在太強,我只要寫一句“我們先討論一下”或“給我幾個選項”,它就會耐心等待我確認後再行動。完全不需要那些花裏胡哨的東西,直接跟它對話就行。
3.8 但 Claude Code 現在有插件了
你聽見遠處那聲嘆息了嗎?那是我在嘆氣。這真是徹頭徹尾的胡扯。Anthropic 的這一舉動讓我對他們的產品方向感到非常失望。他們試圖用插件[24]來掩蓋模型本身的低效。當然,為特定任務維護優質文檔是個好主意 —— 我自己就在一個 docs 文件夾裏存了大量有用的 Markdown 文檔。
3.9 但是!子智能體呢
但關於這場“子智能體”(subagents)的盛宴,我有些話不吐不快。今年五月時,這還叫“子任務”(subtasks),主要是當模型不需要完整上下文時,把任務拆出去單獨處理——比如並行執行,或避免把冗長的構建腳本塞進主上下文造成浪費。後來他們重新包裝並升級為“子智能體”,讓你可以帶着指令“優雅地”打包並分派任務。
但使用場景本質上沒變。別人用子智能體乾的事,我通常用多個終端窗口就搞定了。 如果我想調研某個問題,可能會在一個終端窗格里操作,再把結果粘貼到另一個窗格。這種方式讓我對上下文工程擁有完全的控制權和可見性,而子智能體反而讓上下文變得難以查看、引導或控制。
還有 Anthropic 博客裏推薦的那個子智能體 —— 你去看看他們那個所謂的“AI Engineer”智能體[25]。那簡直就是一鍋大雜燴:一邊吹集成了 GPT-4o 和 o1,一邊堆砌一堆自動生成的空洞詞彙,試圖顯得有邏輯。裏面根本沒有能讓智能體真正變成更好“AI 工程師”的實質內容。
這到底有什麼用?如果你希望獲得更好的輸出,光告訴模型“你是一位專精於生產級 LLM 應用的 AI 工程師”是沒用的。真正有用的是提供文檔、示例,以及明確的“該做什麼/不該做什麼”。 我敢打賭,你讓智能體去“搜索 AI 智能體構建的最佳實踐”並加載幾個網頁,效果都比那堆廢話強得多。你甚至可以説,這種胡扯本身就是一種上下文污染(context poison)[26]。
04 我的提示詞撰寫之道
以前用 Claude 時,我(當然不是手打,而是靠語音)會寫非常詳盡的提示詞,因為那個模型“給越多上下文,越懂我”。雖然所有模型多少都這樣,但我發現換用 codex 後,提示詞明顯變短了 —— 常常就一兩句話,外加一張圖。這個模型讀代碼庫的能力極強,就是能精準理解我的意圖。有時候我甚至又願意打字了,因為 codex 根本不需要太多上下文就能明白。
添加圖片是個絕妙的技巧,能快速補充上下文。 模型非常擅長精準定位你截圖中的內容 —— 無論是字符串還是界面元素,它都能迅速匹配並跳轉到你提到的位置。我至少有一半的提示詞都包含截圖,雖然添加標註效果更佳但效率更低,而直接拖拽截圖到終端僅需兩秒。
帶語義糾錯的 Wispr Flow[27] 仍是當前最優方案。
05 Web 端智能體新體驗
最近我又重新嘗試了一些 Web 端智能體:Devin、Cursor 和 Codex。Google 的 Jules 界面美觀,但配置流程繁瑣,且 Gemini 2.5 現在已經算不上好模型了。不過一旦 Gemini 3 Pro 上線[28],情況或許會有所轉變。目前唯一留下來的只有 codex web。雖然它也存在配置複雜的問題,而且現在還有 Bug(終端目前就無法正確加載),但我靠一箇舊版環境讓它跑起來了,代價是啓動速度更慢。
我把 codex web 當作臨時的問題追蹤器。在外突發靈感時,就用 iOS App 發一條一行字的提詞詞,回頭在 Mac 上再仔細處理。當然,我完全可以在手機上做更多事,比如審查、合併代碼,但我刻意保持克制。我的工作已經夠讓人上癮了,所以當我出門或和朋友聚會時,不想被進一步拉回工作狀態。説這話的人,可是曾花將近兩個月專門開發了一款便於使用手機編程的工具啊。
codex web 上的任務原本不計入使用額度,可惜這樣的好日子恐怕快到頭了。
06 The Agentic Journey
聊聊那些工具吧:Conductor[29]、Terragon[30]、Sculptor[31] 等數以千計的同類產品。有些是個人愛好項目,有些則被 VC 投來的錢淹得喘不過氣。我試過太多太多,沒一個能讓我長期用下去。在我看來,它們都是在繞開當前模型的低效,推行一種並不真正高效的工作流。而且大多數還藏起終端,不讓你看到模型的全部輸出。
絕大多數不過是 Anthropic SDK 的淺層封裝 + 工作樹管理,毫無技術護城河可言。我甚至懷疑:我們真的需要在手機上更方便地調用編程智能體嗎?這些工具的有限應用場景,現在 codex web 已經完全覆蓋了。
不過我確實觀察到一個普遍現象:幾乎每個工程師都會經歷一個“自己造工具”的階段 —— 主要是因為好玩,也因為現在做這件事確實太容易了。既然如此,還有什麼比造一個“(我們以為)能讓造工具變得更簡單的工具”更自然呢?
07 但 Claude Code 能處理後台任務!
確實如此。codex 目前缺少一些 Claude 有的小功能,其中最讓人頭疼的就是後台任務管理。 雖然理論上應該有超時機制,但我確實多次遇到它卡在不會自動結束的 CLI 任務上,比如啓動開發服務器,或者死鎖的測試。
這曾是我一度切回 Claude 的原因之一。但鑑於那個模型在其他方面實在太不靠譜,我現在改用 tmux。tmux 是一個老牌工具,能在後台持久化運行 CLI 會話,而且模型裏早就內置了大量相關知識 —— 你只需要説一句“用 tmux 運行”,就能搞定,無需任何複雜的智能體配置流程。
08 那 MCPs 呢?
關於 MCP(Model Context Protocol),其他人已經寫了很多。在我看來,大多數 MCP 本質都只是市場部門用來打勾炫耀的工具。幾乎所有 MCP 其實都應該做成 CLI。這話出自一個自己寫過 5 個 MCP[32] 的人之口。
我可以直接按工具名字調用一個 CLI,根本不需要在 agent 配置文件裏寫任何説明。模型第一次調用時可能會試一些亂七八糟的命令($randomcrap),CLI 會自動返回幫助菜單,上下文立刻就擁有了完整的使用信息 —— 從此一切順利。我不用為任何工具付出額外代價,而 MCP 卻是持續的成本,還會污染我的上下文。試試 GitHub 的 MCP,瞬間吃掉 23k tokens。好吧,他們後來優化了 —— 剛上線時可是接近 5 萬 tokens!換成 gh CLI 呢?功能基本一樣,模型本來就認識它,還完全不用交“上下文税”。
我自己開源了一些 CLI 工具,比如 bslog[33] 和 inngest[34]。
我現在確實在用 chrome-devtools-mcp[35] 這個工具來做最終驗證[36],它已經取代了 Playwright,成為我進行網頁調試時的首選 MCP 工具。雖然我不常用它,但一旦需要,它就能幫我完成從“代碼修改”到“驗證結果”這個關鍵閉環,非常有用。我還專門設計了我的網站,讓模型能通過 curl 查詢任意接口(通過我生成的 API key)——這在幾乎所有場景下都比 MCP 更快、更省 token。所以就連這個 MCP,我也不是每天都需要。
09 但生成的代碼太糟糕了!
我約 20% 的時間[37]投入在重構上。當然,這些全由智能體完成,我絕不會手動浪費時間幹這種事。當我不太需要高度專注或感到疲憊時,“重構日”就特別有用 —— 即使狀態一般,也能取得顯著進展。
典型的重構工作包括:用 jscpd 找重複代碼,用 knip[38] 清理死代碼,運行 eslint 的 react-compiler 和棄用插件(譯者注:一類 ESLint 插件,用於檢查代碼中是否使用了已過時的 API、方法或特性,並提示你改用現代、推薦的替代方案。),檢查是否有可合併的 API 路由,更新文檔,拆分過大的文件,為複雜邏輯補充測試和註釋,更新依賴項,升級工具鏈,調整目錄結構,找出並重寫慢測試,引入現代 React 模式(比如你可能根本不需要 useEffect)等等。總有做不完的事。
有人可能會説這些應該在每次提交時就做完。但我發現,先快速迭代、再集中維護和優化代碼庫——即階段性償還技術債務——這種方式不僅效率更高,而且整體上有趣得多。
10 你採用規範驅動開發(spec-driven development)嗎?
我去年六月還在用這種方式:先寫一份詳盡的規格文檔,然後讓模型去實現,理想情況下能連續跑上好幾個小時。但現在我覺得,這種“先設計後構建”的思路已經是過時的軟件開發範式了。
我現在的做法通常是:先直接和 codex 展開討論,貼一些網站鏈接、初步構想,讓它解讀現有代碼,然後我們一起把新功能逐步梳理出來。如果問題比較棘手,我會讓它把思路整理成一份規範文檔,然後交給 GPT-5-Pro(通過 chatgpt.com)做評審,看看是否有更好的建議 —— 出乎意料的是,這經常能大幅優化我的方案!接着,我會把其中我覺得有用的部分粘回主上下文,用於更新實際文件。
現在我對不同任務消耗多少上下文已經有不錯的直覺,而 codex 的上下文容量也相當充足,所以很多時候我乾脆直接開幹。有些人很“虔誠”,總喜歡為每個新計劃新開一個上下文窗口 —— 我覺得這在 Sonnet 時代還有點用,但 GPT-5 處理長上下文的能力強得多,如果還這麼做,每次都會白白多花 10 分鐘,因為模型得重新慢慢加載所有構建功能所需的文件。
更有趣的方式是做基於 UI 的開發。我經常從一個非常簡單的東西開始,故意把需求寫得極其模糊,然後一邊看模型編碼,一邊在瀏覽器裏實時看到效果。接着我再排隊加入更多調整,逐步迭代這個功能。很多時候我自己也不確定最終該長什麼樣,這種方式讓我能邊玩邊試,看着想法慢慢成形。有時 codex 甚至會做出一些我根本沒想到但很妙的設計。我從不重置進度,只是一步步迭代,把混沌慢慢塑造成我覺得對的形狀。
開發過程中,我也常會冒出一些關聯功能的新點子,順勢對其他部分也做些調整 —— 這部分工作我會放到另一個智能體裏處理。通常我主攻一個核心功能,同時並行處理一些次要但相關的任務。
就在我寫這段文字時,我正在給 Chrome 擴展開發一個新的 Twitter 數據導入器,為此我正在重構 graphql 導入模塊。因為還不確定這個方案是否合理,我把這部分代碼放在一個單獨的文件夾裏,這樣可以通過 PR 預覽來判斷思路是否成立。主倉庫則在做重構,讓我能專心寫這篇文章。
11 請分享您的斜槓命令!
我只有少數幾個斜槓命令,而且很少用:
- /commit(自定義説明文本,用於協調多智能體在同一目錄協作時僅提交自身修改。這樣能保持提交信息乾淨,也能防止 GPT 因看到其他改動而 panic,比如 linter 報錯時亂 revert(譯者注:Git 版本控制中的常用術語,撤銷某次或某幾次提交(commit)所引入的更改。))
- /automerge(一次處理一個 PR:響應機器人評論、回覆、等 CI 通過後自動 squash 合併(譯者注:Git 版本控制中的常用術語,將多個連續的提交記錄合併成一個單一的、乾淨的提交。))
- /massageprs(和 automerge 類似,但不用 squash,方便在有大量 PR 時並行處理)
- /review(內置命令,偶爾用 —— 因為 GitHub 上已有 review bot,但有時還是有用)
即便如此,大多數時候我其實就直接打 “commit” 兩個字。除非我知道當前有太多髒文件,擔心智能體在沒有引導的情況下出錯。如果我確信簡單指令就夠了,就絕不會搞那些花哨的表演或浪費上下文。這種直覺是慢慢練出來的。到目前為止,我還沒見過其他真正有用的斜槓命令。
12 其他實用技巧
與其費盡心思寫出完美的提示詞去“激勵”智能體完成一個長期任務,不如用點偷懶的變通方法。 比如進行大型重構時,Codex 常會在中途暫停響應。這時候,只要提前排好幾條 “continue” 消息,你就可以走開,等回來時活兒就幹完了。如果 codex 已經完成了任務,再收到更多消息,它也會愉快地忽略掉。
每次完成一個功能或 Bug 修復後,請讓模型在同一上下文中順手寫點測試用例。 這樣做不僅能產出質量高得多的測試用例,還常常能暴露代碼實現中的 bug。如果是純 UI 調整,可能測試意義不大。但對於其他情況,我強烈建議這麼做。AI 寫測試用例總體上還是不太行,但已經比沒有強多了 —— 而且説實話,你自己每次改代碼都會寫測試用例嗎?
讓模型“保留你的原始意圖”,並“在複雜邏輯處添加代碼註釋”,這對您和後續模型理解代碼都大有裨益。
當遇到棘手難題時,在提示詞中加入一些觸發詞,比如 “take your time”(慢慢來)、“comprehensive”(全面一點)、“read all code that could be related”(讀所有可能相關的代碼)、“create possible hypothesis”(提出可能的假設) —— 這些都能讓 codex 解決最棘手的問題。
13 你的 Agents/Claude 配置文件是什麼樣的?
我創建了一個名為 Agents.md 的主配置文件,然後為它創建了一個符號鏈接(譯者注:Linux 操作系統中一個特殊的文件,內容存儲指向目標文件或目錄的路徑字符串),這個鏈接的名字叫 claude.md。我這麼做是因為開發 Claude 的 Anthropic 公司沒有采用和其他工具(比如 Codex)統一的配置文件命名標準。我承認這很麻煩也不理想 —— 畢竟 GPT-5 和 Claude 偏好的提示詞風格差異很大[39]。如果你還沒看過它們各自的提示詞指南,建議現在就去讀一讀。
Claude 對那種 🚨 全大寫咆哮式命令 🚨[40](比如“如果你執行 X 命令,後果將極其嚴重,100 只小貓會死掉!”)反應良好,但這會讓 GPT-5 直接崩潰(也確實該崩潰)。所以,請徹底放棄這種寫法,像正常人一樣用平實的語言就行。這也意味着這些配置文件很難被最優地共享。不過對我來説問題不大,因為我主要用 codex,即使偶爾讓 Claude 上場,我也接受這些指令對它來説可能強度不足。
我的 Agent 配置文件目前大約 800 行,感覺就像一堆“組織創傷”留下的疤痕組織。這不是我手寫的,而是 codex 自己生成的。每次出了狀況,我都會讓它在文件里加一條簡潔備註。我應該找個時間清理一下配置文件,但儘管文件很長,它卻運行得極其可靠 —— GPT-5 也確實幾乎總是遵守裏面的規則。至少比 Claude 以前強太多了。(當然也得承認,Sonnet 4.5 在這方面確實有進步)
除了 Git 操作説明,文件裏還包含產品説明書、我偏好的命名規範和 API 模式、關於 React Compiler 的注意事項等等 —— 很多內容甚至比模型的“世界知識”還新,因為我的技術棧相當激進。我預計隨着模型更新,這部分內容還能進一步精簡。例如,Sonnet 4.0 當年需要大量指導才能理解 Tailwind 4,而 Sonnet 4.5 和 GPT-5 已經內置了相關知識,所以我直接刪掉了所有冗餘的相關説明。
文件裏很大一塊內容專門描述我偏好的 React 模式、數據庫遷移管理策略、測試規範,以及如何使用和編寫 ast-grep 規則。(如果你還不知道 ast-grep,或者沒把它用作代碼庫的 linter,請立刻停下來,讓模型幫你把它設為 Git hook,用來攔截不符合規範的提交。)
我還嘗試過一種基於文本的“設計系統”,用來規定 UI 應該長什麼樣 —— 不過這個實驗目前還沒下定論。
14 那麼 GPT-5-Codex 是完美的嗎?
當然不是。有時候它會花半個小時重構代碼,然後突然 panic,把所有改動全 revert 掉 —— 這時候你得重新運行,並像哄小孩一樣安撫它:“你有足夠的時間,慢慢來。” 有時它會忘記自己其實能執行 bash 命令,需要你鼓勵一下。偶爾它還會用俄語或韓語回覆。更離譜的是,有時候這個“怪物”一滑手,直接把內部思考過程原樣扔進了 bash 終端。但總體而言,這些情況相當罕見,而它在其他幾乎所有方面都強到離譜,讓我完全可以忽略這些小毛病。畢竟,人類也不是完美的。
我對 codex 最大的不滿是它會“丟失文本行” —— 快速向上滾動時,部分文本會莫名其妙消失。真心希望 OpenAI 把這個 Bug 放在修復清單的最頂端,因為這是目前唯一迫使我放慢操作速度的原因,就怕消息突然不見了。
15 結論
別在 RAG、子智能體(subagents)、Agents 2.0 或其他華而不實的花架子上浪費時間了。直接跟它對話,動手試,慢慢培養直覺。你和智能體合作得越多,結果就會越好。
Simon Willison 的文章[41]説得特別到位:管理智能體所需的許多技能,其實和管理工程師非常相似 —— 而這些能力,幾乎全都是資深軟件工程師的特質。
而且沒錯,寫出好軟件依然很難。我不再親手寫代碼,並不意味着我不再深入思考架構、系統設計、依賴關係、功能實現,或者如何讓用户感到驚喜。使用 AI 只意味着:大家對你交付成果的期望值變高了。
PS: 本文 100% 原創手寫。我熱愛 AI,但也清楚有些事用老辦法反而更好。保留這些筆誤,保留我的聲音。🚄✌️
PPS: 文章頭圖由 Thorsten Ball 提供[42],特此致謝。
END
本期互動內容 🍻
❓文中哪個觀點你極度認同?或者,哪個地方你持保留意見?
文中鏈接
[1]https://x.com/christianklotz/status/1977866496001867925
[2]https://x.com/pmddomingos/status/1976399060052607469
[3]https://steipete.me/posts/2025/optimal-ai-development-workflow
[4]https://x.com/steipete/status/1977771686176174352
[5]https://x.com/steipete/status/1977498385172050258
[6]https://gist.github.com/steipete/d3b9db3fa8eb1d1a692b7656217d8655
[7]https://x.com/steipete/status/1977119589860601950
[8]https://x.com/weberwongwong/status/1975749583079694398
[9]https://x.com/steipete/status/1976353767705457005
[10]https://x.com/steipete/status/1977072732136521836
[11]https://x.com/vtahowe/status/1976709116425871772
[12]https://x.com/s_streichsbier/status/1974334735829905648
[13]https://x.com/kimmonismus/status/1976404152541680038
[14]https://x.com/steipete/status/1978099041884897517
[15]https://x.com/steipete/status/1975297275242160395
[16]https://x.com/steipete/status/1977466373363437914
[17]https://x.com/deepfates/status/1975604489634914326
[18]https://ampcode.com/news/gpt-5-oracle
[19]https://x.com/btibor91/status/1976299256383250780
[20]https://x.com/badlogicgames/status/1977103325192667323
[21]https://x.com/steipete/status/1976226900516209035
[22]https://x.com/steipete/status/1977286197375647870
[23]https://x.com/thsottiaux/status/1975565380388299112
[24]https://www.anthropic.com/news/claude-code-plugins
[25]https://github.com/wshobson/agents/blob/main/plugins/llm-application-dev/agents/ai-engineer.md
[26]https://x.com/IanIsSoAwesome/status/1976662563699245358
[27]https://wisprflow.ai/
[28]https://x.com/cannn064/status/1973415142302830878
[29]https://conductor.build/
[30]https://www.terragonlabs.com/
[31]https://x.com/steipete/status/1973132707707113691
[32]https://github.com/steipete/claude-code-mcp
[33]https://github.com/steipete/bslog
[34]https://github.com/steipete/inngest
[35]https://developer.chrome.com/blog/chrome-devtools-mcp
[36]https://x.com/steipete/status/1977762275302789197
[37]https://x.com/steipete/status/1976985959242907656
[38]https://knip.dev/
[39]https://cookbook.openai.com/examples/gpt-5/gpt-5_prompting_guide
[40]https://x.com/Altimor/status/1975752110164578576
[41]https://simonwillison.net/2025/Oct/7/vibe-engineering/
[42]https://x.com/thorstenball/status/1976224756669309195
本文經原作者授權,由 Baihai IDP 編譯。如需轉載譯文,請聯繫獲取授權。
原文鏈接:
https://steipete.me/posts/just-talk-to-it