

導讀
百度MEG上一代大數據產品存在平台分散、易用性差等問題,導致開發效率低下、學習成本高,業務需求響應遲緩。為了解決這些問題,百度MEG內部開發了圖靈3.0生態系統,包括Turing Data Engine(TDE)計算&存儲引擎、Turing Data Studio(TDS)數據開發治理平台和Turing Data Analysis(TDA)可視化BI產品。依託圖靈3.0生態,我們引入了數據湖表格式:Apache Iceberg,利用其特性並在多種業務場景下進行優化實踐,解決圖靈數倉業務實時數據入湖,數據表歷史記錄更新效率低等多個痛點問題。
01 背景
1.1 圖靈3.0生態概述
由於百度MEG上一代大數據產品存在平台多、易用性差及數據流轉繁瑣等問題。這些問題導致開發人員研發效率低及多平台間高昂的學習成本;業務部門的感知則是需求交付遲緩、數據產出延遲及數據質量低等問題。為了解決上述問題,我們構建了新一代大數據解決方案——"圖靈3.0",旨在覆蓋數據全生命週期,支持全鏈路數據操作,提供高效敏捷且統一的強大數據生態系統,其中包括數據計算引擎、數據開發和數據分析三個核心部分:
1. TDE(Turing Data Engine):圖靈生態的計算引擎,包含基於Hive、Iceberg進行數據處理的Spark和ClickHouse高性能計算引擎。
2. TDS(Turing Data Studio):一站式數據開發治理平台。
3. TDA(Turing Data Analysis):新一代可視化BI產品。
本文主要介紹數據湖表格式Iceberg在圖靈3.0生態下的應用與實踐。
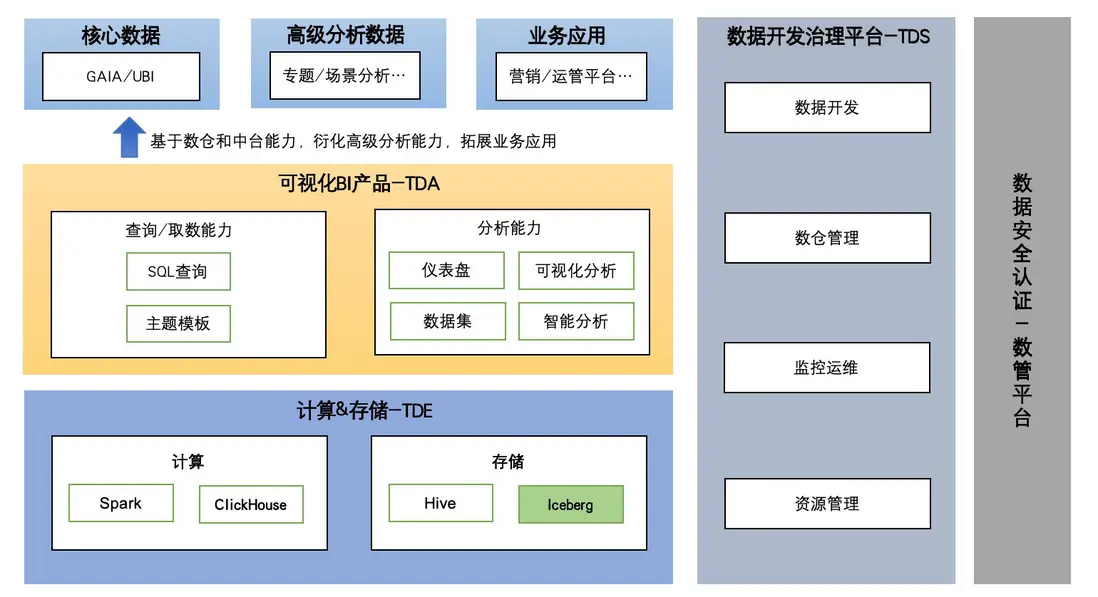
△圖靈3.0生態產品
1.2 問題
MEG數據中台基於Hive構建了離線數據倉庫,已支持手百,搜索,商業,貼吧,小説,用增架構,銷售等多個業務需求,但隨着業務的發展,業務對數據的實時性以及查詢性能等有更高要求,當前主要存在以下幾個問題:
1. 商業、電商、銷售等業務,週期性地更新行業等信息,單次更新數據量佔比小、字段少,但是基於Hive的數據更新(以下簡稱:數據回溯)只能通過全量覆蓋寫的方式實現,數據回溯週期長、效率低、成本高。
2. 由於Hive在實時數據更新以及事務支持上存在一定侷限性,無法有效滿足業務構建實時數倉的需求。
3. 在處理大規模數據集上,Hive的查詢性能受到如元數據的加載解析以及每次訪問數據都需通過分佈式文件系統listFile遍歷文件列表等問題的影響,導致性能降低。
基於上述問題,我們通過技術調研,最終引入了開源的數據湖表格式Iceberg,構建數據湖存儲服務,並藉助大數據生態的Spark、Flink等計算引擎來實現數據湖的分析,將其無縫集成到圖靈生態中,幫助業務提效降本,構建更快速、更高效、更低成本的數據中台產品。
1.3 Hive和Iceberg對比
Hive作為一個基於Hadoop生態系統的開源數據倉庫工具,主要用於對大規模結構化數據進行存儲、查詢和分析。而Iceberg作為新一代數據湖表格式,提供了類似傳統數據庫的事務性,保證和數據一致性,並支持複雜的數據操作,如行級更新和刪除等,更加適合實時更新,流批一體數據場景,下表列出Hive和Iceberg一些主要特性對比:
| 特性 | Hive | Iceberg |
|---|---|---|
| 行級更新 | 不支持 | 支持merge into、upsert等語法進行行級別更新能力 |
| 時效性 | 小時級別/天級 | 支持完整的ACID事務,同時使用多快照提供了讀寫分離的特性 |
| 事務 | 非完整的ACID事務 | 分鐘級 |
| 元數據管理方式 | 基於Mysql進行元數據存儲 | 通過文件組織管理,直接存儲數據文件元數據 |
| 數據版本控制 | 無 | 支持時間旅⾏(Time travel)特性,可基於快照進行歷史數據版本管理和訪問 |
1.4 Iceberg的組織結構
Iceberg文件組織分為元數據層和數據層,主要包含version-hint,metadata file、snapshot file、manifest file和data file文件類型,具體如下:
-
metadata元數據層
a. version-hint:該文件作為元數據索引初始文件,記錄了Iceberg表的版本號,通過版本號找到對應的metadata file。
b. metadata file:記錄了Iceberg表的schemas、properties以及快照等信息。
c. snapshot file(manifest-list):每次數據 commit 會生成一個新的快照,保存了該快照下每個manifest file路徑及對應的分區範圍。
d. manifest file:記錄數據文件元信息,包含每個數據文件的路徑、文件的大小等一系列統計信息(如文件每列的最大最小值、空值數等),實現元數據和數據文件的關聯。
-
data數據層
data file:實際的數據文件,以 parquet 等列存格式存儲數據。
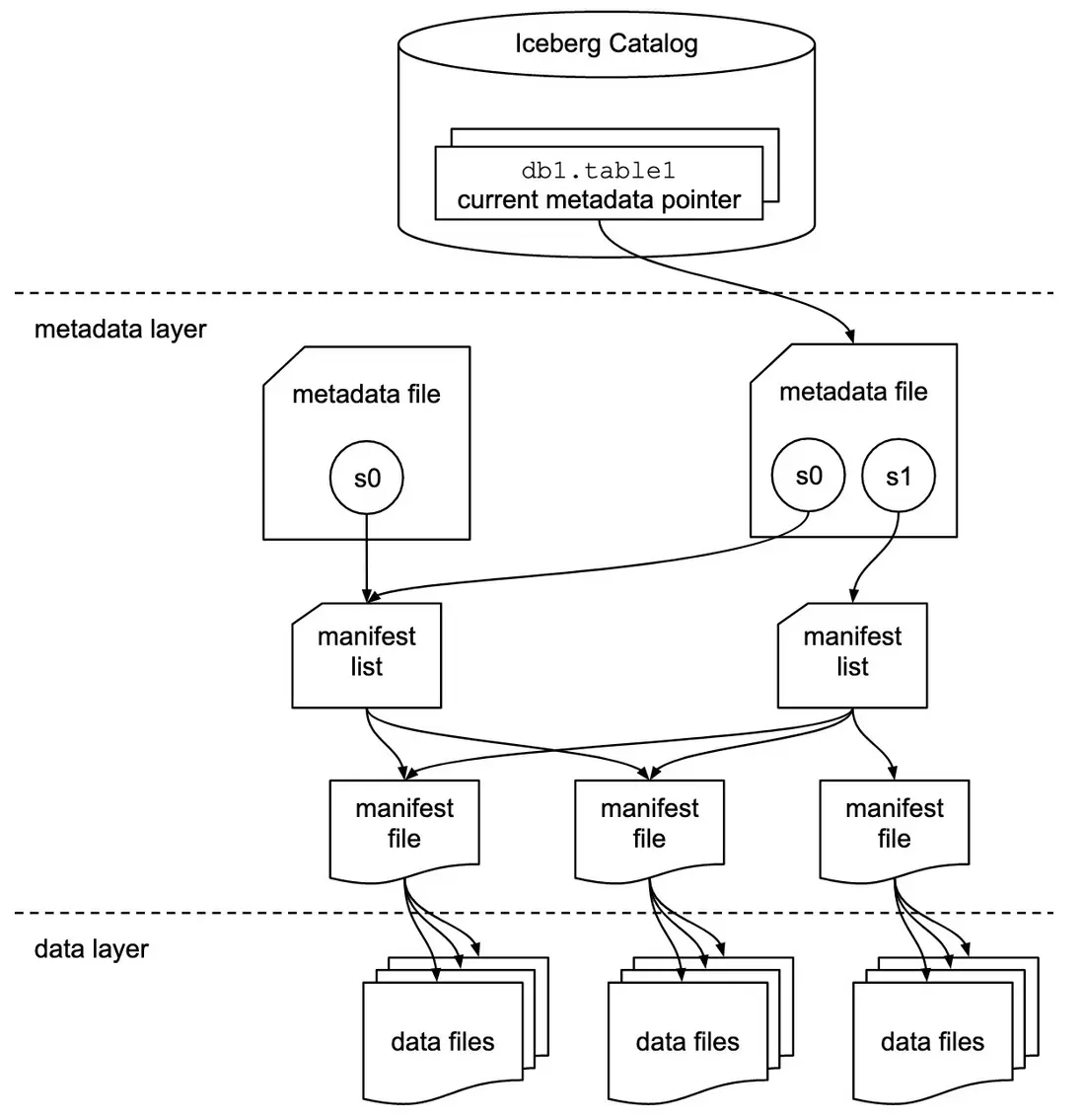
△Iceberg表結構

△Iceberg文件組織結構
通過上述Iceberg元數據文件組織結構,Iceberg實現了文件級的元信息統計及版本化管理。
02 Iceberg能力建設與應用
2.1 圖靈生態能力適配
2.1.1 統一元數據服務
由於原生iceberg缺少元數據的可視化管理能力,我們通過構建統一的元數據微服務,將Iceberg表和Hive表元數據進行管理,對應用層提供相關表和分區的增刪改查等接口,統一數據存儲的元數據操作入口。
該微服務主要包含常駐SparkSession模塊,EngineMetaService模塊和元數據模塊,通過將SparkSession常駐,為用户提供Iceberg表和Hive表元數據和分區數據的增刪改查功能,以及可視化的元數據管理界面。

△統一元數據服務架構
2.1.2 打通Iceberg和Hive聯邦查詢
為了兼容歷史業務存量Hive表,同時降低用户使用Iceberg的成本。我們在計算引擎層面打通Iceberg和Hive聯邦查詢能力,並保證了Iceberg表與原有方式語法一致。
通常在一條SQL執行過程中,主要可簡化以下Parse、Analyzer、Optimizer、CBO四個流程。通過在Analyzer和Plan階段進行改進優化,來打通Iceberg和Hive表聯邦查詢。
- Analyzer階段:該階段主要是將spark未解析的邏輯計劃進行解析,我們通過對SparkSessionCatalog加載方式改造,優先加載iceberg表使用的catalog類型,如果用户SQL使用的是Iceberg表,則對應會使用IcebergCatalog和iceberg數據源訪問,否則使用SessionCatalog與Hive數據源訪問。
- Optimizer階段:為加強數據安全管理,我們進一步打通Iceberg表鑑權能力,在基於邏輯計劃生成物理計劃階段,解析注入表、字段信息以及表操作類型規則,並與公司內數管平台交互,實現對Iceberg表和字段的鑑權
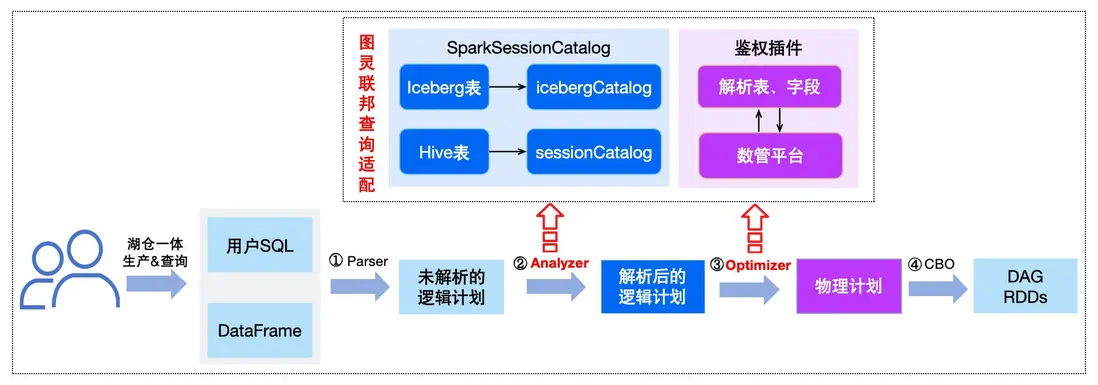
△Iceberg和Hive聯邦查詢適配流程
2.2 存量Hive低成本遷移Iceberg
現有數倉業務數據主要存儲於Hive表,為支持業務快速切換Iceberg應用新技術,我們建設了存量Hive表低成本遷移至Iceberg表的能力。
以下是在實踐過程中的兩種遷移方案對比:
方式1:使用Iceberg功能migrate進行原地遷移,通過社區提供的CALL migrate語法,直接執行如下示例的SQL語句,即可將Hive表升級為Iceberg表。
CALL catalog_name.system.migrate('db.sample', map('foo', 'bar'));
該方案操作簡單且可回滾,但這種方式在圖靈生態落地過程中也存在一些問題:
該方式會基於原Hive表的數據信息構建Iceberg元數據信息,並將原Hive表名重命名為sample\_backup\_,同時數據路徑也進行重命名。
- 下游無法讀:在執行遷移過程中,原Hive表對應的路徑已經被重命名,進而導致下游業務無法正常讀取正在遷移中的表。
- 多表掛載衝突:在業務的使用場景中,存在同一份物理數據被多個Hive表掛載可能,直接修改路徑會導致其他表失效。
方式2:基於上述問題,我們進一步對現有方案進行優化,不改變Hive表原有的數據路徑,來實現Hive低成本遷移Iceberg,具體流程如下:
- 構建Iceberg元數據:直接複用Hive的分區數據,新建同名的Iceberg表,並重建Iceberg元數據,最終新Iceberg表的元數據信息實際指向是Hive分區數據存儲位置。
- 數據校驗:當Iceberg元數據構建完成後,查詢Iceberg表中字段數據,和遷移之前Hive表字段數據,進行一致性校驗,驗證遷移是否符合預期。
- 讀寫切換:數據校驗完成後,我們只需要將對應表的屬性更新為Iceberg。因為我們已經打通了Iceberg和Hive的查詢,且遷移後表名未變,業務可正常使用原有表名及語法進行查詢和寫入,降低遷移成本。
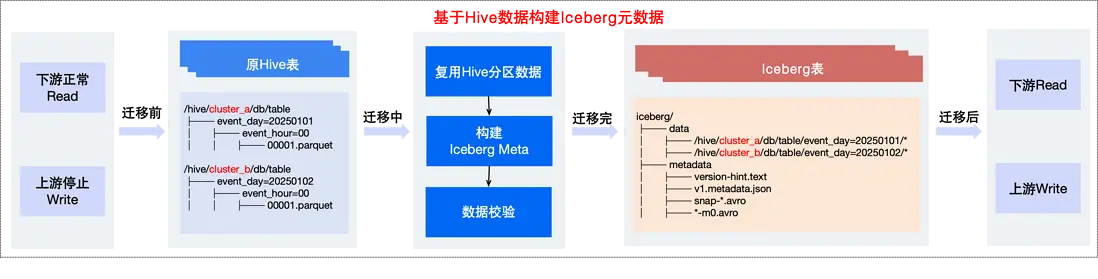
△Hive遷移Iceberg整體實現流程
2.3 Iceberg在圖靈的應用和性能優化
2.3.1 圖靈實時數倉應用
在圖靈數倉大部分場景中,用户主要依託天級或小時級運行的離線Spark任務來完成數據入倉。在這種模式下,難以滿足部分對數據實時性要求較高的需求。
為解決該問題,我們基於Iceberg+Flink構建的圖靈實時湖倉架構,整體重構流程如下圖所示。該架構模式實現了數據分鐘級別實時入倉,顯著提升了數據入倉的時效性。進一步擴展了整個圖靈的應用場景。
- 針對數據分析和case排查等場景,業務可基於圖靈常駐計算引擎進行實時查詢,快速獲取所需要的數據支持業務分析決策;
- 針對策略迭代、特徵生產以及機器學習等複雜計算場景,可基於spark例行任務進行加工生產;
- 針對策略數據調研分析、科學計算等複雜場景通過數據交互計算引擎Jupyter進行數據計算。通過構建圖靈實時湖倉架構,既保證了數據分析的時效性又兼顧了複雜計算任務的處理能力,有效提升了業務的數據處理效率和分析決策能力。
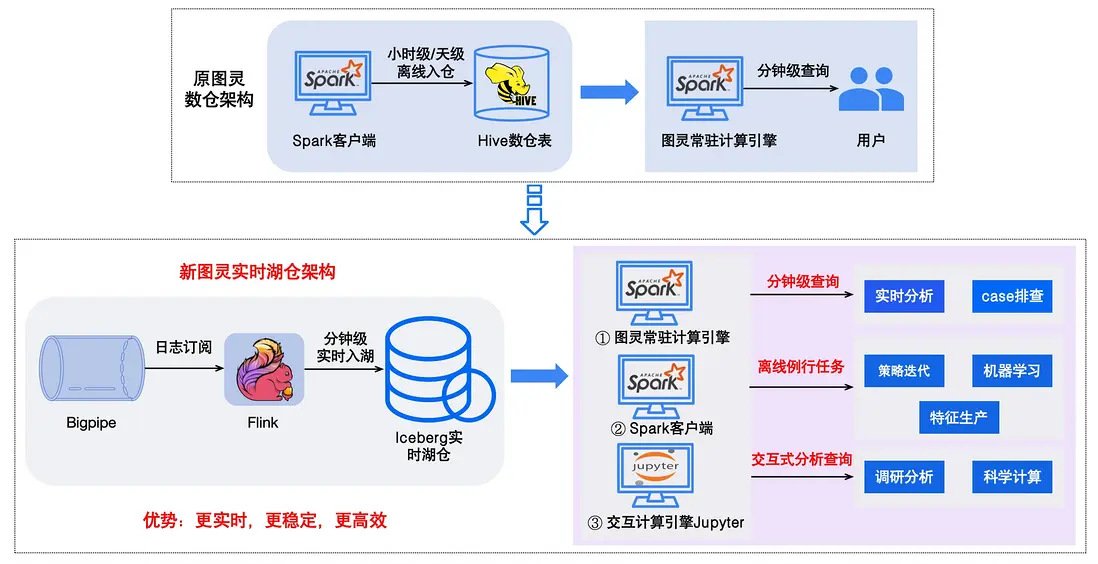
△圖靈實時湖倉架構演變
2.3.2 行級更新策略
在圖靈數倉業務場景下,商業、搜索、電商、銷售等業務,週期性地更新行業等信息。而Hive在該場景下支持相對較弱,需通過全量覆蓋寫方式刷新數據,這種方式在大數據量場景下,回溯數據週期長,消耗資源大,所需要的人力時間成本也高。我們通過利用Iceberg行級更新的特性,基於update、merge into等方式回溯進行字段變更,能夠很大程度的提高回溯效率,降低資源和人力成本。
針對數據行級更新,Iceberg提供了兩種策略,分別為COW(Copy on Write: 寫時複製) 或 MOR (Merge on Read:讀時合併),其中MOR根據其標記刪除文件的區別又細分了兩種方式(Equality Delete File和Position Delete File)。
| 更新策略 | 更新後的讀取效率 | 更新時寫入效率 | 適用場景 | 備註 |
|---|---|---|---|---|
| COW | 最快 | 最慢 | 讀多寫少場景 | |
| MOR 標記條件刪除(Equality Delete File) | 較快 | 最快 | 寫入多、讀取少場景 | 讀開銷:每次讀取數據需要額外讀取標記刪除列數據進行比較。寫開銷:只需要存儲標記過濾數據的條件,寫入成本極低。 |
| MOR 標記位置刪除(Position Delete File) | 快(依賴更新數據量) | 較快 | 少量數據更新、讀取少場景 | 讀開銷:加載每個文件需過濾的數據行號。(刪除行過多,影響性能)寫開銷:需要掃描一遍原數據,找出待刪除數據的行號。 |
關於COW和MOR更新策略的文件表現形式如下圖所示,我們針對不同場景採用不同更新策略:
- 對於日常數據查詢分析場景,小時級&天級離線例行生成加工場景,由於查詢次數會遠多於數據更新次數,可默認採用COW策略;
- 針對一些業務更新少量字段進行長週期回溯場景,以及實時場景,寫入頻繁,通過使用MOR策略,來支持用户進行數據回溯變更字段信息,以提升數據更新效率並節省資源。
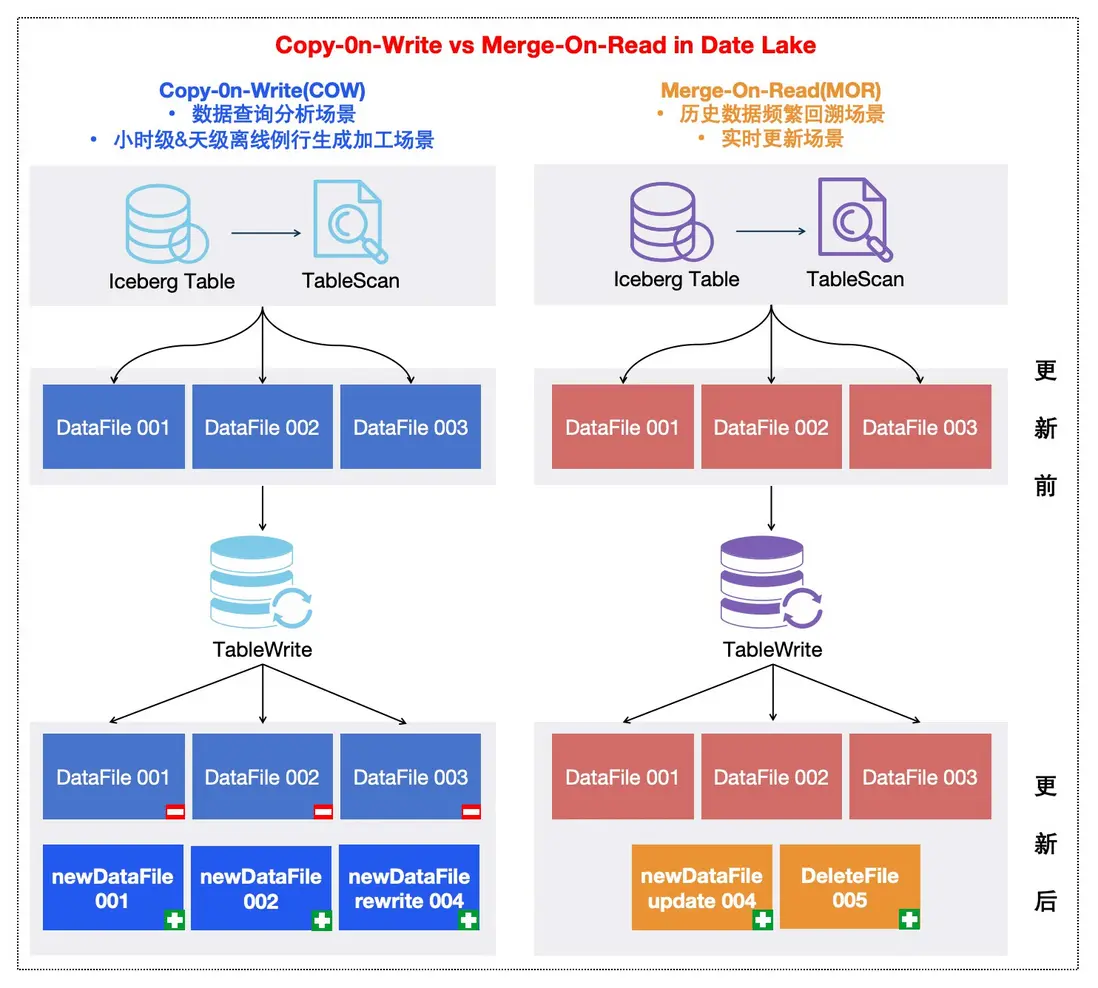
△COW和MOR兩種更新策略對比

△MOR兩種刪除文件類型&更新字段示例
在業務進行數據回溯應用過程中,我們採用MOR(Position Delete File)進行行級數據更新,通過原Hive回溯和新Iceberg回溯兩種方式對比,在一天24小時不同分區上,驗證了Hive和Iceberg新舊的回溯效率,如下圖所示,業務回溯效率整體可平均提升50%+;進一步地對比單次回溯一年數據消耗的計算資源量對比,平均整體降低70%+的計算資源消耗,整體上極大提升回溯效率,並降低資源成本。

△ Hive 和 Iceberg 回溯效率對比
2.3.3 Iceberg表生命週期管理和性能優化
在Iceberg應用實踐的過程中,針對不同業務場景遇到的問題,我們彙總如下:
- 小文件過多:在實時湖倉業務場景,為了要保證數據的時效性,通常是分鐘級別的commit操作,在這種場景下,單個作業執行一天,則需要1440 個 commit,如果執行時間更長,則會產生更多的commit,隨着時間的累積,元數據以及數據文件等都會產生大量的小文件,對於整體查詢的性能會產生一定的影響。
- 存儲資源增加:如果iceberg表的快照不及時進行清理,可能會造成數據存儲增加,導致存儲賬號資源緊張。
- 缺乏分區數據統一管理:在一些業務場景,只需要保存一定天數的分區數據,針對無用數據需要進行刪除處理。
- 數據文件組織不均衡且無序:由於表數據寫入是隨機無序,且針對表數據文件大小會存在不均衡的情況。
針對上述問題,我們通過對Iceberg表進行全生命週期管理,並結合Iceberg特性優化表查詢性能,保障整個數據鏈路的穩定性,整體框架如下圖所示:
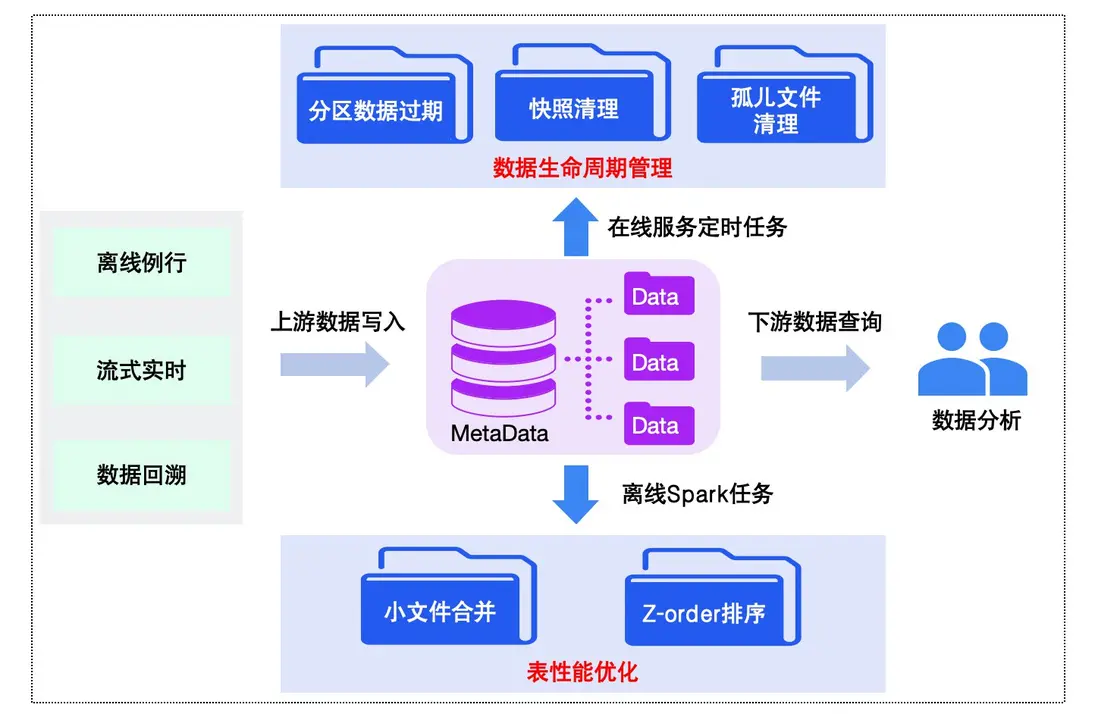
△Iceberg表生命週期管理和性能優化流程
以上流程主要包含表數據生命週期管理和表性能優化兩部分。
一方面,對於表數據生命週期管理,我們通過在線服務執行定時任務,來實現對錶數據和元數據進行全生命週期監控,具體如下:
- 數據分區過期:基於用户配置的表生命週期,進行分區數據刪除,保證數據文件按期清理。
- 元數據快照清理:為用户提供按照時間維度天級別和按照個數維度小時級別兩種快照過期策略,精細化元數據快照過期處理,實現存儲資源的高效利用。
- 元數據孤兒文件清理:通過天級例行任務來觸發清理由於計算引擎執行任務失敗等情況產生的一些沒有被引用的孤兒文件,避免元數據累積影響性能。
另一方面,在表性能優化方面,我們結合圖靈數倉表使用情況,並基於Iceberg原生特性,為用户在平台側提供Iceberg表優化算子(如下圖示例),主要包含以下兩種能力:
- 小文件合併:通過制定合併文件大小,對錶數據文件進行重寫合併,避免產生大量小文件。
- z-order排序優化:實現對錶相關字段進行重排序,提升查詢性能。
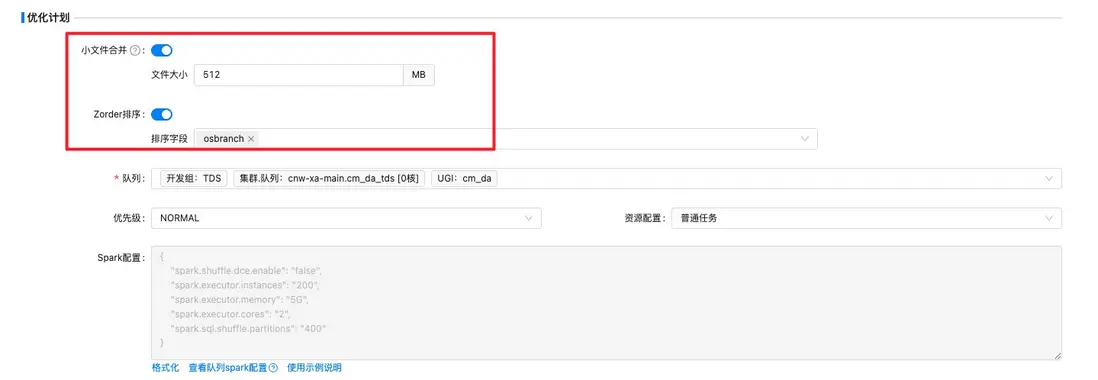
△Iceberg表優化算子任務創建示例
我們通過對Iceberg表整體的生命週期管理,實現了數據和元數據的統一治理,表元數據小文件數萬個降低到數百級別,合理控制了元數據產生的數量,並解決了數據頻繁回溯場景下存儲快速增加的問題。而在表查詢優化方面,通過在一些表的數據重分佈和字段重排序應用,在部分業務表查詢性能提速50%。
03 未來規劃
Iceberg作為圖靈3.0生態中的重要組成部分,基於其高時效性、行級更新能力、小文件合併以及Z-order等成體系的數據優化的技術解決方案,為MEG數據中台業務提供構建湖倉一體,解決數據回溯等痛點問題的能力。目前Iceberg的應用已覆蓋搜索,商業,銷售,用增架構等多個業務線,通過低成本助力業務將存量Hive遷移Iceberg表,為業務提供高性能數據查詢,同時實現對業務的降本增效。此外,我們也在不斷完善Iceberg數據存儲引擎的各項能力,包含表數據智能治理、查詢優化、智能索引以及特定場景的性能問題等,並不斷擴大Iceberg的業務覆蓋範圍。