

2025 年 3 月 18 日,Apache Kafka 4.0 正式發佈。 在此次版本更新中,相較於架構層面的升級,開發者們也應關注一個關鍵的細節變更:官方將生產者參數 linger.ms 的默認值,從沿用多年的 0ms 正式修改為 5ms。
這一調整直擊傳統性能調優的認知盲區,在傳統觀念中,linger.ms=0 意味着"零等待"和實時發送,通常被視為降低延遲的首選策略。然而,Kafka 4.0 的默認值變更揭示了一個更深層的性能邏輯:在複雜的網絡 I/O 模型中,單純追求發送端的實時性並不等同於全局的低延遲。通過引入微小的"人工延遲"來換取更高的批處理效率,往往能顯著降低系統的延遲。
以 Kafka 4.0 的默認值變更為契機,本文將深入分析 linger.ms 和 batch.size 這兩個核心參數背後的協同機制。幫助你在面對複雜的生產環境時,基於原理掌握linger.ms 和 batch.size 的最佳實踐。
概念拆解:linger.ms 和 batch.size 參數
為了透徹理解這次變更背後的深層邏輯,首先我們需要回歸基礎,準確理解這兩個核心參數的概念。
linger.ms:
生產者會將兩次請求傳輸之間到達的所有記錄組合成單一的批處理請求。這種攢批行為通常在記錄到達速率超過發送速率的高負載場景下自然發生,但在負載適中時,客户端也可通過配置 linger.ms 引入少量的"人為延遲"來主動減少請求數量。其行為邏輯類似於 TCP 協議中的 Nagle 算法:生產者不再立即發送每一條到達的記錄,而是等待一段指定的時間以聚合更多後續記錄。該設置定義了批處理的時間上限,發送行為遵循"先滿足者優先"原則------一旦分區積累的數據量達到 batch.size,無論 linger.ms 是否到期,批次都會立即發送;反之,若數據量不足,生產者將"逗留"指定時長以等待更多記錄。在 Apache Kafka 4.0 中,該參數的默認值已從 0ms 調整為 5ms,其依據在於更大批次帶來的效率增益通常足以抵消引入的等待時間,從而實現持平甚至更低的整體生產者延遲。
batch.size:
當多條記錄需發往同一分區時,生產者會將這些記錄聚合為批次(Batch)以減少網絡請求頻率,從而優化客户端與服務端的 I/O 性能。batch.size 參數定義了該批次的默認容量上限(以字節為單位),超過該閾值的單條記錄將不被納入批處理邏輯。發往 Broker 的單個請求通常包含多個批次,分別對應不同的分區。配置過小的 batch.size 會限制批處理的發生頻率並可能降低吞吐量(設置為 0 將完全禁用批處理);而過大的配置則可能因生產者總是基於此閾值預分配緩衝區而導致內存資源的輕微浪費。該設置確立了發送行為的空間上限:若當前分區積累的數據量未達到此閾值,生產者將依據 linger.ms(默認為 5ms)的設定進行等待;發送觸發邏輯遵循"先滿足者優先(Whichever happens first)"原則,即一旦數據量填滿緩衝區或等待時間耗盡,批次即會被髮送。需要注意的是,Broker 端的背壓可能導致實際的有效等待時間超過配置值。
通過對兩個維度的拆解,我們可以清晰地看到 linger.ms 和 batch.size 的協同工作模式:
- 它們共同決定了 RecordBatch(批次)的大小和 ProduceRequest(請求)的發送時機。
linger.ms和batch.size參數值較大 -\>RecordBatch 和 ProduceRequest 批處理效果越好 -\> Kafka 服務器需要處理的 RPC 數量更少 -\> Kafka 服務端 CPU 消耗越低。- 副作用:客户端在批處理上花費的時間增加,從而導致客户端的發送延遲變高。
這引出了一個關鍵的性能權衡問題:
"在服務端 CPU 資源充足的前提下,為了追求極致的低延遲,是否應當儘可能最小化linger.ms和batch.size?"
基於直覺的推斷,答案似乎是肯定的。然而,Kafka 4.0 的官方文檔指出了相反的結論:
"Apache Kafka 4.0 將默認值從 0 調整為 5。儘管增加了人為的等待時間,但更大批次帶來的處理效率提升,通常會導致相似甚至更低的生產者延遲。"
linger.ms=0 代表即時發送,為什麼在延遲的表現上反而不如"先等待 5ms"?
核心原理:Kafka 服務端與客户端交互的底層規則
要透徹理解這一反直覺的性能表現,我們不能僅停留在客户端配置的表面,而必須深入 Apache Kafka 網絡協議的底層。延遲的產生,本質上源於客户端發送策略與服務端處理模型之間的交互機制。為了探究其根源,我們需要分別從服務端和客户端兩個維度,解析這套底層規則的運作邏輯。
1. 服務端視角:嚴格按序的"串行"模式
Kafka 的網絡協議在設計上與 HTTP 1.x 頗為相似,它採用的是一種嚴格的順序且串行的工作模式。這是理解所有延遲問題的基石:
- 順序性(Sequential): 對於來自同一個 TCP 連接的請求,服務端必須嚴格按照接收到的順序進行處理,並按同樣的順序返回響應。
- 串行性(Serial): 服務端只有在完全處理完當前請求併發送響應後,才會開始處理下一個請求。這意味着,即便客户端併發發送了 N 個 ProduceRequest,服務端也會嚴格執行'One-by-One'策略:必須等到前一個請求的數據完成所有 ISR 副本同步並返回響應後,才會開始處理下一個請求。
這意味着: 哪怕客户端一股腦地併發發送了 N 個 ProduceRequest,服務端也不會並行處理。如果前一個請求因為 ISR 同步卡頓了,後續的所有請求都只能在服務端排隊等候。
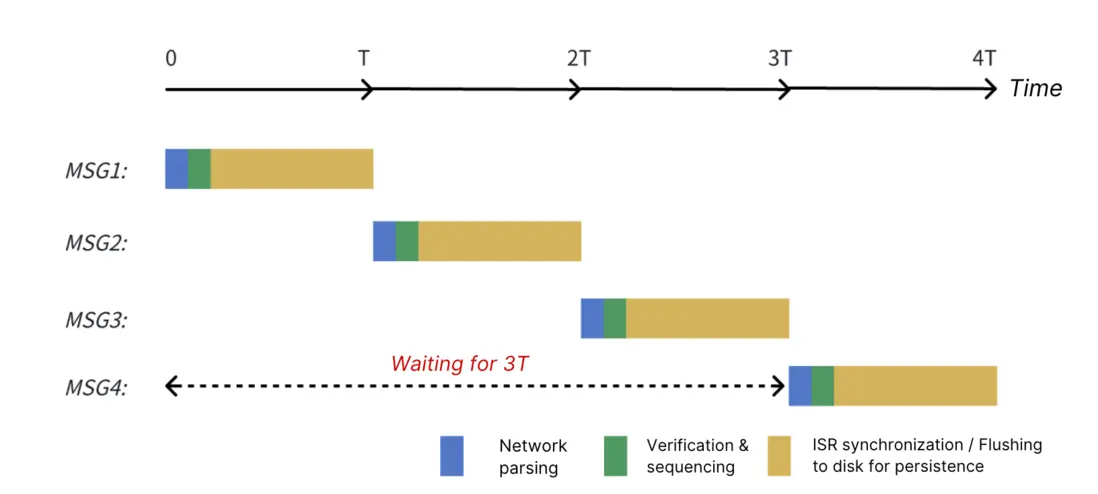
2. 客户端視角:化解擁堵的"Batch"原理
在客户端側,Producer 的批處理主要包含兩個核心模塊:RecordAccumulator 和 Sender,分別對應 RecordBatch 和 ProduceRequest。
- RecordAccumulator :負責將 RecordBatch 進行批處理。
KafkaProducer#send將記錄放入 RecordAccumulator 進行批處理。當分區內的 ProduceBatch 數據超過batch.size時,它會切換到下一個分區並創建一個新的 ProduceBatch 進行批處理。 -
Sender:負責維護與服務器節點的連接並分批發送數據。它會基於節點從 RecordAccumulator 中排幹就緒分區的數據,將它們打包成 ProduceRequest 併發送。排幹需要同時滿足以下條件:
- 連接上的在途請求數量小於
max.in.flight.requests.per.connection=5。 - 對應節點的任何 ProduceBatch 超過
linger.ms或超過batch.size
- 連接上的在途請求數量小於
場景推演:0ms 與 5ms 的性能對比
基於上述原理,我們需要進一步評估該機制在實際場景中的表現。當客户端配置 linger.ms=0 以執行即時發送策略,而服務端受限於串行處理模型時,供需兩側的處理節奏將產生錯配。為了準確判斷這種錯配究竟是降低了延遲還是引發了排隊積壓,僅憑定性分析不足以説明問題。接下來,我們將構建一個模型,通過場景化的定量推演,計算不同配置下的具體延遲數據。
場景假設:
- 部署一個單節點集羣,創建一個包含 10 個分區的 Topic
- 客户端 :單客户端,發送速率 1000 條記錄/秒,記錄 大小 1KB。
- 服務端 :處理一個 ProduceRequest 耗時 5ms。
-
對比組:
配置 A :
linger.ms=0,batch.size=16KB(Apache Kafka 4.0 之前的默認配置)配置 B :
linger.ms=5,其餘不變(4.0 新版默認)
推演 A:當 linger.ms = 0
- 1,000 records/s 意味着每 1ms 調用一次
KafkaProducer#send; - 由於
linger.ms=0,前 5 條記錄會立即轉換為 5 個 ProduceRequest,分別在時間戳 T=0ms, T=0.1ms, ..., T=0.4ms 發送。 - Apache Kafka 順序且串行地處理這 5 個 ProduceRequest:
a.T=5ms :Apache Kafka 完成第 1 個 ProduceRequest 的請求,返回響應,並開始處理下一個 ProduceRequest;
b.T=10ms :第 2 個 ProduceRequest 處理完畢,開始處理下一個;
c.以此類推,第 5 個 ProduceRequest 在 T=25ms 時處理完畢。 - T=5ms :客户端收到第 1 個 ProduceRequest 的響應,滿足
inflight.request < 5的條件,從 RecordAccumulator 排幹數據。此時,內存中已積累了 (5 - 0.4) / 1 ~= 4K 的數據,這些數據將被放入一個 ProduceRequest 中,Sender 將其打包成第 6 個請求發出。 a.T=30ms:Apache Kafka 在 T=25ms 處理完第 5 個請求後,接着處理第 6 個請求,並在 T=30ms 返回響應。 - T=10ms:同樣地,收到第 2 個 ProduceRequest 的響應後,客户端積累了 (10 - 5) / 1 = 5K 的數據併發送給 Broker。Apache Kafka 在 T=35ms 返回響應。
- 以此類推,後續的 ProduceRequest 都會在 T1 時刻積累 5K 數據併發送給 Broker,Broker 會在 T1 + 25ms 響應請求。平均生產延遲為 5ms / 2 + 25ms = 27.5ms。(5ms / 2 是平均批處理時間)
推演 B:當 linger.ms = 5
- T=5ms :由於
linger.ms=5,客户端會先積攢數據直到 5ms,然後發出第一個ProduceRequest。服務端會在 T=10ms 時對該請求做出響應。 - T=10ms :由於
linger.ms=5,客户端會繼續積攢新數據達 5ms,隨後發出第二個ProduceRequest。服務端會在 T=15ms 時做出響應。 - 以此類推: 後續的請求都會在 T1 時刻攢夠 5K 數據後發往 Broker,Broker 會在 T1 + 5ms 時做出響應。此時的平均生產延遲 計算如下: 5ms / 2 + 5ms = 7.5ms*(注:5ms / 2 代表平均攢批的時間)*
在這個假設場景中,雖然我們將 linger.ms 從 0 ms 增加到 5 ms,但平均生產延遲反而從 27.5 ms 降到了 7.5 ms。由此可見,"linger.ms 越小,延遲越低"這一説法並不絕對成立。
linger.ms 與 batch.size 配置最佳實踐
通過對比 linger.ms 為 0ms 和 5ms 的情況,我們可以得出結論:客户端的主動批處理,將 在途請求控制在 1 及以內,要比快速把請求發出然後在網絡層排隊,更能降低生產延遲。
那麼如何在千變萬化的生產環境中,精準設定這兩個參數的閾值?
我們需要一套科學的計算公式,根據服務端的實際處理能力,倒推客户端的最佳配置。以下是針對最小化生產延遲的定向配置建議:
- linger.ms \>= 服務端處理耗時。
如果 linger.ms 小於網絡耗時和服務端的處理時間,根據 Kafka 網絡協議的串行處理模式,發出的 ProduceRequests就會在網絡層產生積壓。這違背了我們前面提到的"將網絡在途請求數控制在 1 及以內"的原則。
- batch.size \>= (單個客户端最大寫入吞吐量) * (linger.ms / 1000) / (Broker 數量)。
如果 batch.size 未設置為大於或等於此值,則意味着在達到 linger.ms 之前,由於 ProduceBatch 超過 batch.size,將會被迫提前發送請求。同樣,這些 ProduceRequest 無法及時處理,將在網絡中排隊,違反了 "將網絡在途請求數控制在 1 及以內"的原則。
- 建議將
batch.size設置得儘可能大(例如 256K):
linger.ms 是基於服務端的平均 生產延遲來設定的。一旦服務端出現性能抖動(Jitter),更大的 batch.size允許我們在單個 RecordBatch 中積攢更多數據,從而避免因為拆分成多個小請求發送而導致整體延遲升高。
以單節點集羣為例,假設服務器處理一個 ProduceRequest 需要 5ms。那麼我們需要將 linger.ms 設置為至少 5ms。如果我們預期單個生產者的發送速度能達到 10MBps,那麼 batch.size 應設置為至少 10 * 1024 * (5 / 1000) = 51.2K。
創新實踐:從"客户端攢批"走向"服務端流水線"
Apache Kafka 4.0 對默認值的調整,驗證了一個核心的技術共識:在處理大規模數據流時,適度的批處理是平衡吞吐與延遲的有效手段。這是一種基於客户端視角的成熟優化策略**。**
然而,性能優化的路徑不止一條**。**既然瓶頸在於服務端的"串行處理",那麼除了一味調整客户端參數外,我們是否可以從服務端本身尋求突破?正是基於這一思考,作為雲原生 Kafka 的探索者,AutoMQ 嘗試從服務端視角尋找新的突破:在完全兼容 Kafka 協議語義的前提下,AutoMQ 引入了"Pipeline(流水線)機制"。這一機制並非改變協議本身,而是優化了服務端的模型,使得在保證順序性的同時,能夠充分利用雲原生存儲的併發能力,將 ProduceRequest 的處理效率提升了 5 倍。

這意味着什麼?讓我們回到之前的推演場景:
即便在 linger.ms=0 導致多個在途請求積壓的情況下,AutoMQ 的流水線機制允許服務端同時處理這些請求,顯著降低了排隊延遲:
- Apache Kafka :由於串行排隊,平均延遲達 27.5ms。
- AutoMQ :憑藉流水線機制,平均延遲降至 7.5ms。
因此,當使用 AutoMQ 作為服務端時,你可以享受服務端處理效率的 5 倍提升,客户端不再需要通過長時間的"逗留"來遷就服務端,從而獲得更低的延遲體驗。你可以將參數配置為原建議值的 1/5,linger.ms 的配置策略會與 Apache Kafka 略有不同:
linger.ms >=(服務端處理耗時 / 5)batch.size >=(單個客户端最大寫入吞吐量) * (linger.ms / 1000) / (Broker 數量)
(注:同樣建議在內存允許範圍內,將 batch.size 儘可能調大,如 256K)
這種配置上的差異,揭示了性能優化視角的轉變:要做到性能調優,不能僅依賴於客户端的適配。AutoMQ 通過架構層面的創新實踐,讓用户無需在"低延遲"和"高吞吐"之間做艱難的權衡,而是以更低的門檻實現了兩者的兼得。技術總是在不斷演進的。從參數調優走向架構演進,不僅是 AutoMQ 的選擇,也是雲原生時代消息中間件發展的方向。
結語
感謝您讀到這裏。
本文回顧了 Apache Kafka 4.0 中 linger.ms 與 batch.size 參數的配置,指出了在傳統串行網絡模型下,客户端進行性能調優時所面臨的"延遲與吞吐"權衡難題。隨後,我們深入解析了 AutoMQ 的 Pipeline 機制,它通過服務端 I/O 模型的重構,解除了順序處理與串行執行的強綁定。
Pipeline 機制是 AutoMQ 雲原生架構的核心特性之一,無需依賴繁瑣的客户端參數調整,即可在保證數據嚴格順序的前提下,實現 5 倍於傳統架構的處理效率。結合對雲原生存儲的深度適配,AutoMQ 致力於通過底層架構的演進,助力企業以更簡的運維構建極致性能的流數據平台。