

背景
哈嘍,大家好,我是asong。今天我們一起來看看Go語言中的rune數據類型,首先從一道面試題入手,你能很快説出下面這道題的答案嗎?
func main() {
str := "Golang夢工廠"
fmt.Println(len(str))
fmt.Println(len([]rune(str)))
}運行結果是15和15還是15和9呢?先思考一下,一會揭曉答案。
其實這並不是一道面試題,是我在日常開發中遇到的一個問題,當時場景是這樣的:後端要對前端傳來的字符串做字符校驗,產品的需求是限制為200字符,然後我在後端做校驗時直接使用len(str) > 200來做判斷,結果出現了bug,前端字符校驗沒有超過200字符,調用後端接口確一直是參數錯誤,改成使用len([]rune(str)) > 200成功解決了這個問題。具體原因我們在文中揭曉。
Unicode和字符編碼
在介紹rune類型之前,我們還是要從一些基礎知識開始。 ------ Unicode和字符編碼。
- 什麼是
Unicode?
我們都知道計算機只能處理數字,如果想要處理文本需要轉換為數字才能處理,早些時候,計算機在設計上採用8bit作為一個byte,一個byte表示的最大整數就是255,想表示更大的整數,就需要更多的byte。顯然,一個字節表示中文,是不夠的,至少需要兩個字節,而且還不能和ASCII編碼衝突,所以,我國制定了GB2312編碼,用來把中文編進去。但是世界上有很多語言,不同語言制定一個編碼,就會不可避免地出現衝突,所以unicode字符就是來解決這個痛點的。Unicode把所有語言都統一到一套編碼裏。總結來説:"unicode其實就是對字符的一種編碼方式,可以理解為一個字符---數字的映射機制,利用一個數字即可表示一個字符。"
- 什麼是字符編碼?
雖然unicode把所有語言統一到一套編碼裏了,但是他卻沒有規定字符對應的二進制碼是如何存儲。以漢字“漢”為例,它的 Unicode 碼點是 0x6c49,對應的二進制數是 110110001001001,二進制數有 15 位,這也就説明了它至少需要 2 個字節來表示。可以想象,在 Unicode 字典中往後的字符可能就需要 3 個字節或者 4 個字節,甚至更多字節來表示了。
這就導致了一些問題,計算機怎麼知道你這個 2 個字節表示的是一個字符,而不是分別表示兩個字符呢?這裏我們可能會想到,那就取個最大的,假如 Unicode 中最大的字符用 4 字節就可以表示了,那麼我們就將所有的字符都用 4 個字節來表示,不夠的就往前面補 0。這樣確實可以解決編碼問題,但是卻造成了空間的極大浪費,如果是一個英文文檔,那文件大小就大出了 3 倍,這顯然是無法接受的。
於是,為了較好的解決 Unicode 的編碼問題, UTF-8 和 UTF-16 兩種當前比較流行的編碼方式誕生了。UTF-8 是目前互聯網上使用最廣泛的一種 Unicode 編碼方式,它的最大特點就是可變長。它可以使用 1 - 4 個字節表示一個字符,根據字符的不同變換長度。在UTF-8編碼中,一個英文為一個字節,一箇中文為三個字節。
Go語言中的字符串
基本概念
先來看一下官方對string的定義:
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string人工翻譯:
string是8位字節的集合,通常但不一定代表UTF-8編碼的文本。string可以為空,但不能為nil。string的值是不能改變的
説得通俗一點,其實字符串實際上是隻讀的字節切片,對於字符串底層而言就是一個byte數組,不過這個數組是隻讀的,不允許修改。
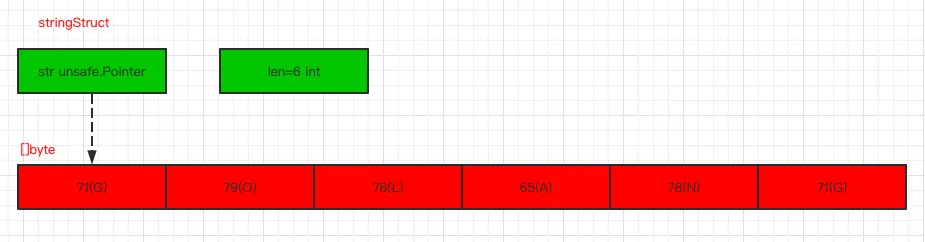
寫個例子驗證一下:
func main() {
byte1 := []byte("Hl Asong!")
byte1[1] = 'i'
str1 := "Hl Asong!"
str1[1] = 'i'
}對於byte的操作是可行,而string操作會直接報錯:
cannot assign to str1[1]
所以説string修改操作是不允許的,僅僅支持替換操作。
根據前面的分析,我們也可以得出我們將字符存儲在字符串中時,也就是按字節進行存儲的,所以最後存儲的其實是一個數值。
Go語言的字符串編碼
上面我們介紹了字符串的基本概念,接下來我們看一下Go語言中的字符串編碼是怎樣的。
Go 源代碼為 UTF-8 編碼格式的,源代碼中的字符串直接量是 UTF-8 文本。所以Go語言中字符串是UTF-8編碼格式的。
Go語言字符串循環
Go語言中字符串可以使用range循環和下標循環。我們寫一個例子,看一下兩種方式循環有什麼區別:
func main() {
str := "Golang夢工廠"
for k,v := range str{
fmt.Printf("v type: %T index,val: %v,%v \n",v,k,v)
}
for i:=0 ; i< len(str) ; i++{
fmt.Printf("v type: %T index,val:%v,%v \n",str[i],i,str[i])
}
}運行結果:
v type: int32 index,val: 0,71
v type: int32 index,val: 1,111
v type: int32 index,val: 2,108
v type: int32 index,val: 3,97
v type: int32 index,val: 4,110
v type: int32 index,val: 5,103
v type: int32 index,val: 6,26790
v type: int32 index,val: 9,24037
v type: int32 index,val: 12,21378
v type: uint8 index,val:0,71
v type: uint8 index,val:1,111
v type: uint8 index,val:2,108
v type: uint8 index,val:3,97
v type: uint8 index,val:4,110
v type: uint8 index,val:5,103
v type: uint8 index,val:6,230
v type: uint8 index,val:7,162
v type: uint8 index,val:8,166
v type: uint8 index,val:9,229
v type: uint8 index,val:10,183
v type: uint8 index,val:11,165
v type: uint8 index,val:12,229
v type: uint8 index,val:13,142
v type: uint8 index,val:14,130根據運行結果我們可以得出如下結論:
使用下標遍歷獲取的是ASCII字符,而使用Range遍歷獲取的是Unicode字符。
什麼是rune數據類型
官方對rune的定義如下:
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32人工翻譯:
rune是int32的別名,在所有方面都等同於int32,按照約定,它用於區分字符值和整數值。
説的通俗一點就是rune一個值代表的就是一個Unicode字符,因為一個Go語言中字符串編碼為UTF-8,使用1-4字節就可以表示一個字符,所以使用int32類型範圍就可以完美適配。
答案揭曉
前面説了這麼多知識點,確實有點亂了,我們現在就根據開始的那道題來做一個總結。為了方便查看,在貼一下這道題:
func main() {
str := "Golang夢工廠"
fmt.Println(len(str))
fmt.Println(len([]rune(str)))
}這道題的正確答案是15和9。
具體原因:
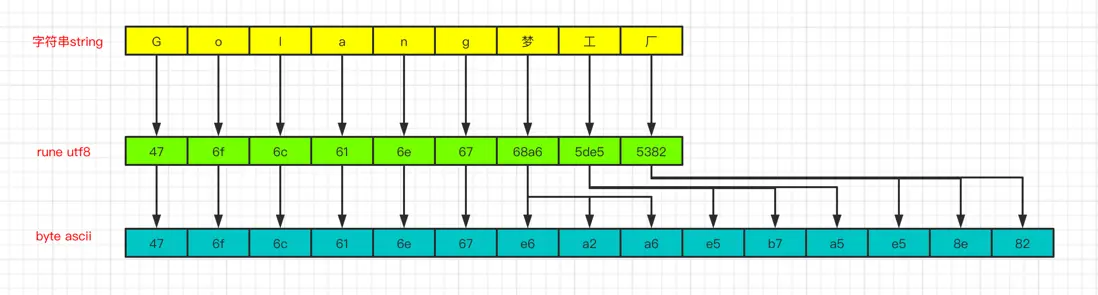
len()函數是用來獲取字符串的字節長度,rune一個值代表的就是一個Unicode字符,所以求rune切片的長度就是字符個數。因為在utf-8編碼中,英文佔1個字節,中文佔3個字節,所以最終結果就是15和9。
貼個圖,方便理解:
unicode/utf8庫
如果大家對rune的使用不是很明確,可以學習使用一下Go標準庫unicode/utf8,其中提供了多種關於rune的使用方法。比如上面這道題,我們就可以使用utf8.RuneCountInString方法獲取字符個數。更多庫函數使用方法請自行解鎖,本篇就不做過多介紹了。
總結
針對全文,我們做一個總結:
- Go語言源代碼始終為
UTF-8 Go語言的字符串可以包含任意字節,字符底層是一個只讀的byte數組。Go語言中字符串可以進行循環,使用下表循環獲取的acsii字符,使用range循環獲取的unicode字符。Go語言中提供了rune類型用來區分字符值和整數值,一個值代表的就是一個Unicode字符。Go語言中獲取字符串的字節長度使用len()函數,獲取字符串的字符個數使用utf8.RuneCountInString函數或者轉換為rune切片求其長度,這兩種方法都可以達到預期結果。
好啦,這篇文章就到這裏啦,素質三連(分享、點贊、在看)都是筆者持續創作更多優質內容的動力!
創建了一個Golang學習交流羣,歡迎各位大佬們踴躍入羣,我們一起學習交流。入羣方式:關注公眾號獲取。更多學習資料請到公眾號領取。
我是asong,一名普普通通的程序猿,讓我們一起慢慢變強吧。歡迎各位的關注,我們下期見~~~

推薦往期文章:
- Go看源碼必會知識之unsafe包
- 源碼剖析panic與recover,看不懂你打我好了!
- 空結構體引發的大型打臉現場
- Leaf—Segment分佈式ID生成系統(Golang實現版本)
- 面試官:兩個nil比較結果是什麼?
- 面試官:你能用Go寫段代碼判斷當前系統的存儲方式嗎?
- 如何平滑切換線上Elasticsearch索引