

論文成果總結
2025 年度,學術界多個時序數據研究團隊圍繞時序數據庫 IoTDB 進行了多方面的科研創新,在數據庫領域 CCF-A 類國際期刊和會議上共發表論文 10 篇,包括:ACM TODS 1 篇、SIGMOD 3 篇、VLDB 2 篇、ICDE 4 篇,涵蓋引擎、存儲、查詢、分析等方面。
在引擎方面,通過原生 TsFile 格式和高效處理引擎,IoTDB 實現了高吞吐寫入與低延遲查詢。IoTDB 社區還設計了免遷移的彈性分佈式存儲方案,能夠在保障系統容災能力的同時,實現存儲均衡。
在存儲方面,通過引入基於離羣值分離的位打包技術(BOS)、面向編碼數據的 SIMD 向量化聚合管道以及創新的同態壓縮框架(CompressIoTDB),IoTDB 社區顯著提升了數據壓縮比和查詢性能。
在查詢方面,針對 LSM 樹存儲結構,IoTDB 社區提出了基於隨機摘要的分位數查詢方法以降低 I/O 開銷,並設計了迭代最大三角形採樣算法(ILTS)來優化時序數據的可視化質量與效率。
在分析方面,IoTDB 社區實現了數據庫內置的季節性趨勢分解方法(OneRoundSTL)和時序聚類方案,並提出了具有收斂性保證的多變量時序協同插補技術,從而為複雜時序分析提供了高效、可靠的原生支持。
這一系列創新性成果,為應對物聯網時代海量、高速、多樣化的時序數據管理挑戰提供了堅實的理論與性能支撐。

引擎
ACM TODS 2025: Apache IoTDB: A Time Series Database for Large Scale IoT Applications
🎯論文名稱:Apache IoTDB:面向大規模物聯網應用的時序數據庫
✍️第一作者:王晨
典型的工業場景涉及成千上萬的設備與數百萬個傳感器,持續生成數以十億計的數據點。這對時間序列數據管理提出了新的需求,而現有解決方案未能充分應對這些需求,包括:設備定義的持續演進模式、週期性的數據採集、強關聯的序列數據、不同程度延遲的數據到達,以及高併發的數據寫入。
本文詳細介紹了一種時間序列數據庫管理系統——Apache IoTDB。該系統包含一種原生時間序列文件格式 TsFile,採用專門設計的數據編碼方式;以及一個能夠高效處理延遲數據到達與查詢操作的 IoTDB 引擎。我們介紹了一種原生分佈式解決方案,利用並行算子優化分佈式查詢。同時,我們探索了高效的 TsFile 同步機制,確保無需 ETL 流程即可實現無縫數據整合。
該系統實現了 1000 萬數據點/秒的寫入吞吐量。對於 10 萬個數據點的單日數據查詢,以及 1000 萬個數據點的三年數據聚合查詢,均可在 100 毫秒內完成處理。與 InfluxDB、TimescaleDB、KairosDB、Parquet 及 ORC 基於真實數據負載的對比實驗,驗證了 IoTDB 與 TsFile 的優越性。
📝全文鏈接:https://dl.acm.org/doi/10.1145/3726523
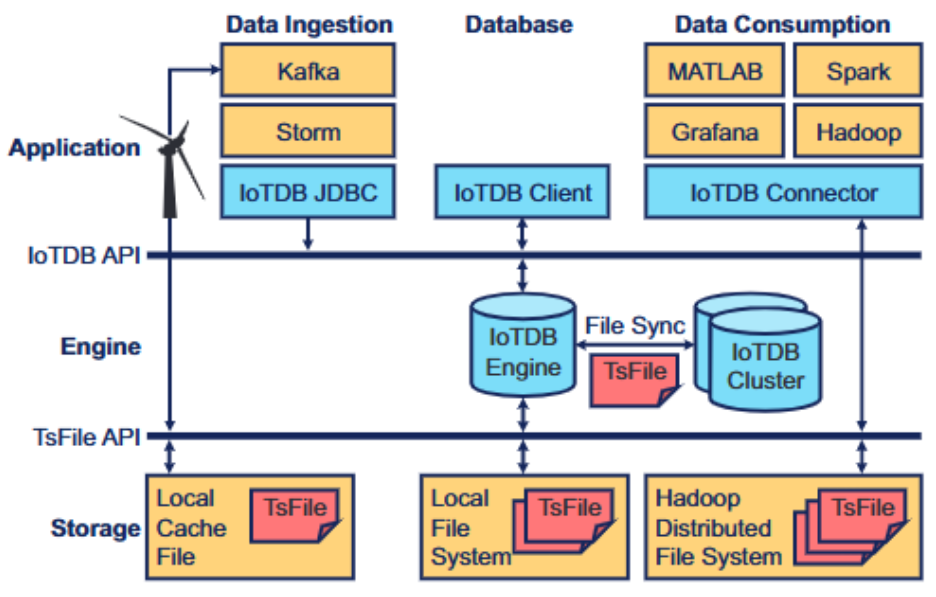
VLDB 2025: Migration-Free Elastic Storage of Time Series in Apache IoTDB
🎯論文名稱:Apache IoTDB 中免遷移的時間序列彈性存儲
✍️第一作者:陳榮釗
在分佈式時序數據庫(TSDB)中,時序數據通常按序列和時間進行分區。這些分區隨後被分配到分片,分片的副本決定了存儲位置,而領導者負責管理寫入負載。在物聯網(IoT)場景中,隨着傳感器數量的不斷增長,集羣也會隨之擴展,重新平衡存儲的一種常見方法是遷移現有分區,但這會產生額外的開銷。
通常,時序數據庫會通過生存時間(Time to Live,TTL)來自動卸載過期數據,因此動態擴展分片而不是遷移現有分區也可以恢復存儲平衡。同時,集羣的容災能力取決於副本放置方案,而集羣的擴展會使這個問題變得更加複雜。物聯網場景中的密集寫入負載需要平衡的領導者選擇,而容災放置方案使得該選擇變得困難。
論文中提出了一種具有可靠容災能力,且存儲均衡的副本放置算法,以及一種寫均衡的領導者選擇算法,以解決上述問題。該解決方案已在 Apache IoTDB 1.3 版本中成功部署,廣泛評估證明了其在可用性和性能方面的卓越性。
📝全文鏈接:https://dl.acm.org/doi/10.14778/3725688.3725706

存儲
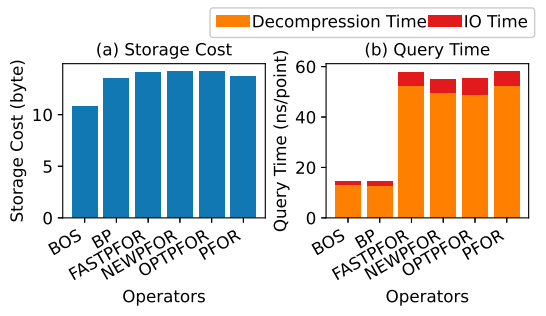
ICDE 2025: BOS: Bit-packing with Outlier Separation
🎯論文名稱:BOS:基於離羣值分離的位打包技術
✍️第一作者:肖今朝
位打包是多種數據編碼與壓縮方法的基礎操作,其核心思想是採用固定位寬來表示序列中所有經過處理的值。然而,某些極大值(稱為上界離羣值)會顯著增加所需位寬,導致大多數較小值存儲時的位浪費。值得注意的是,不僅是大值(上界離羣值),小值(下界離羣值)同樣可能引起位寬浪費。
本文提出通過分離上下界離羣值來優化存儲的方法(BOS):將離羣值單獨存儲後,剩餘中心值的分佈範圍變窄(即壓縮位寬),需要額外成本記錄離羣值位置。該問題的核心在於如何確定最優的上下界離羣值分離閾值,以實現最小化存儲成本。相較於使用搜索時間為 O(n²) 的全枚舉上下界閾值,我們創新性地採用位寬作為分離依據,將搜索時間降至 O(nlogn)。理論分析表明,基於位寬的分離策略在所有可能情況下都能獲得與值分離法相同的優化解,並進一步提出結合中位數與位寬的近似分離策略,搜索時間進一步降至 O(n)。
BOS 方案可與現有所有基於位打包的壓縮方法兼容,目前已在 Apache IoTDB 和 Apache TsFile 中全面替代傳統位打包方法。大量真實數據集實驗表明,在各種壓縮方法中用 BOS 替代位打包後,壓縮比從約 2.75 顯著提升至 3.25。
📝全文鏈接:https://ieeexplore.ieee.org/document/11113092
ICDE 2025: Exploring SIMD Vectorization in Aggregation Pipelines for Encoded IoT Data
🎯論文名稱:面向編碼物聯網數據聚合管道中的 SIMD 向量化技術探索
✍️第一作者:康瑞
時序數據庫用於採集和分析工業設備傳感器發送的海量數據,在物聯網領域至關重要。無論是從網絡接收的數據還是數據庫存儲的數據,都經過高效編碼以減少 I/O 佔用和延遲。物聯網編碼器通過組合差分編碼、重複值壓縮和打包編碼算子,實現了比單獨使用任一方法更高的壓縮比。然而,因為處理查詢前必須進行串行解碼,高效的壓縮反而增加了查詢執行難度,而選擇性聚合(如降採樣)是時序分析查詢的核心操作。
本文提出了一套基於編碼數據數組的算子體系,用於加速物聯網聚合查詢處理,可擴展集成線程級和指令級設計,創新性地實現了無需解碼即可並行聚合編碼數據的能力,並能夠利用編碼統計信息減少冗餘計算。這些算子構建的管道式查詢引擎已集成至開源數據庫 Apache IoTDB 中。系統評估表明,該方案在選擇性聚合查詢效率上較現有工作實現了顯著提升。
📝全文鏈接:https://ieeexplore.ieee.org/document/11112860

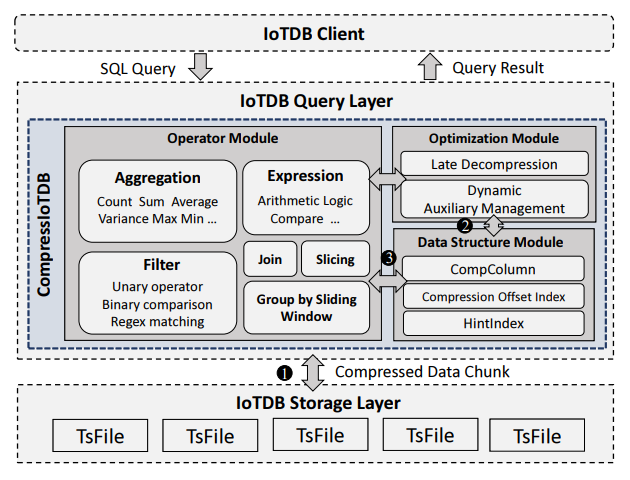
VLDB 2025: Improving Time Series Data Compression in Apache IoTDB
🎯論文名稱:提升 Apache IoTDB 的時間序列數據壓縮性能
✍️第一作者:Yuxin Tang
時間序列數據在各領域以前所未有的規模產生。儘管傳統壓縮技術能降低存儲成本,但它們通常需要在查詢前完全解壓數據,導致查詢延遲增加和資源消耗上升。同態壓縮(HC)技術允許直接對壓縮數據進行計算而無需解壓,展現出既能減少存儲成本又能提升查詢性能的潛力。然而,時間序列數據特有的複雜性給現有的 HC 方法帶來了無法充分應對的挑戰。
本文在時序數據領域引入 HC 理論,革新性地實現了時序數據庫查詢的同態壓縮。基於我們的理論,我們開發了 CompressIoTDB:一個集成於 Apache IoTDB 的新型同態壓縮框架。通過採用我們提出的 CompColumn 結構,該框架支持廣泛的查詢算子,包括過濾、聚合和窗口函數,同時全程保持數據的壓縮狀態。此外,我們還引入了延遲解壓和動態輔助管理等系統級優化,進一步提升查詢效率。
大量實驗表明,CompressIoTDB 顯著提升了時間序列數據的查詢處理性能,平均吞吐量提高了 53.4%,內存使用降低了 20%。
📝全文鏈接:https://dl.acm.org/doi/10.14778/3748191.3748204
查詢
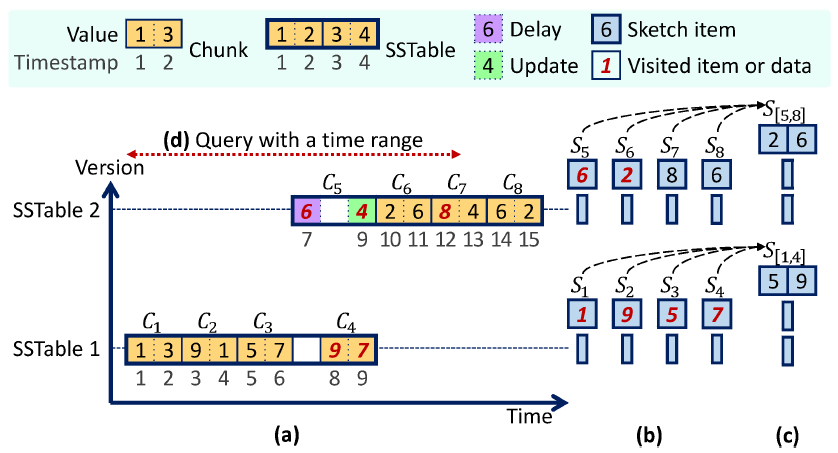
SIGMOD 2025: Randomized Sketches for Quantile in LSM-tree based Store
🎯論文名稱:基於 LSM 樹存儲的分位數隨機摘要
✍️第一作者:陳子陵
分位數的精確計算代價高昂,但可以通過分位數摘要進行高效估計。現有關於流數據彙總(如 KLL)的研究主要致力於在給定誤差控制下最小化內存開銷。然而在基於 LSM 樹的存儲系統中進行分位數估計時,流式處理方法會產生與數據量 N 成線性關係的昂貴 I/O 開銷。由於 LSM 樹中的磁盤組件(數據塊和 SSTable)一旦刷盤就不可改變,可以將分位數摘要作為一種預計算統計信息來降低 I/O 開銷並加速查詢。若要為查詢數據提供確定性的加性誤差 εN 保證,所有被查詢數據塊(單個大小為 Nc)的預計算確定性摘要都必須提供 εNc 誤差保證,導致線性 I/O 開銷無法改善。
本文提出預計算隨機摘要方案以提供隨機加性誤差保證,主要技術創新包括:(1) 針對刷盤構建的數據塊隨機摘要(經證明具有最優性,可實現與 √N 成正比的 I/O 開銷);(2) 針對壓縮構建 SSTable 分層隨機摘要,可進一步改善漸進 I/O 開銷;(3) 總結預計算的 KLL 摘要比總結流數據的 KLL 摘要更準確,可在與流數據相同的內存複雜度條件下實現次線性 I/O 開銷。在合成數據集和真實數據集上的大量實驗驗證了該技術的優越性,該方案已部署於基於 LSM 樹的時序數據庫 Apache IoTDB 中。
📝全文鏈接:https://dl.acm.org/doi/10.1145/3709717
SIGMOD 2025: Largest Triangle Sampling for Visualizing Time Series in Database
🎯論文名稱:面向數據庫時間序列可視化的最大三角形採樣方法
✍️第一作者:芮蕾
在時間序列可視化中,降採樣技術用於減少數據點數量,並保留原始時間序列的視覺特徵。基於面積的最大三角形採樣法(LTS)在保留感知關鍵點方面表現優異。然而,通過順序採樣局部最大三角形面積的點的啓發式解決方案(即 LTTB 算法)存在次優解和查詢效率低下的問題。
針對這些缺陷,我們提出了一種創新的迭代最大三角形採樣算法(ILTS),通過凸包加速技術進行優化。該算法可以迭代優化採樣結果,通過在每次迭代中集成更多數據點以獲取更廣闊的視角。我們證明了在預先計算的凸包中始終可以找到最大的三角形,從而保證了迭代採樣過程的高效性。實驗結果表明,相較於現有的最優基線,新算法顯著提升了視覺質量,與蠻力方法相比,速度有顯著提升。
📝全文鏈接:https://dl.acm.org/doi/10.1145/3709699
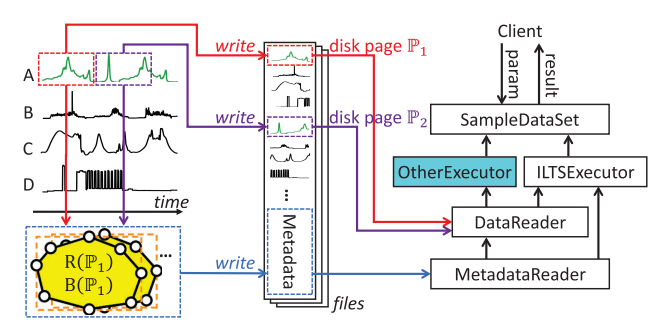
分析
ICDE 2025: OneRoundSTL: In-Database Seasonal-Trend Decomposition
🎯論文名稱:OneRoundSTL:數據庫內置的季節性趨勢分解方法
✍️第一作者:陳子傑
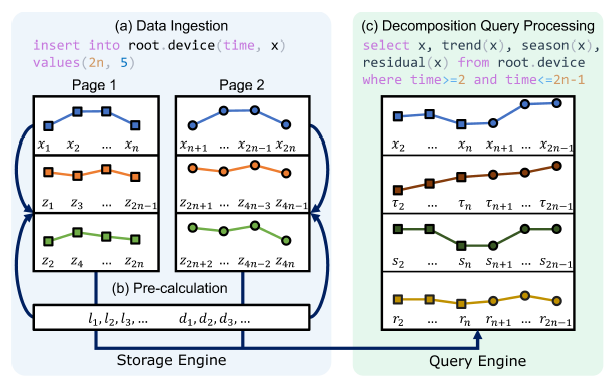
季節性趨勢分解方法在時序分析中應用廣泛,例如時間序列預測和異常檢測。現有的季節性趨勢分解方法(如 STL 及其變體)通常假設時間序列是完整且按時間戳排序的。然而,主流時序數據庫多采用基於 LSM 樹的存儲結構,其數據頁中的存儲順序往往與時間順序不一致。此外,數據庫中的時序數據常因傳感器故障等原因存在數據缺失,進一步破壞了數據的完整性。常規解決思路是先合併排序不同數據頁的內容再進行分解,但這會導致沉重的在線計算負擔和多次查詢時的重複計算,且仍無法處理殘留的缺失數據。
本文提出 OneRoundSTL 方法,通過在離線階段預計算各獨立數據頁的結果,在查詢時拼接這些預計算結果即可獲得分解結果。該方案已在開源時序數據庫 Apache IoTDB 中實現並作為內置功能部署。系統在合成數據集和真實數據集上的實驗表明,OneRoundSTL 在保持分解效果的同時,其執行效率遠超現有最優方法。
📝全文鏈接:https://ieeexplore.ieee.org/document/11112870
SIGMOD 2025: In-Database Time Series Clustering
🎯論文名稱:數據庫內的時序聚類
✍️第一作者:蘇雲祥
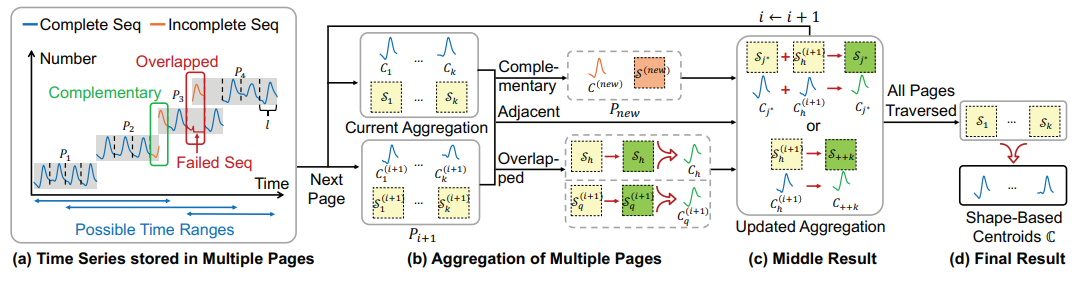
時序數據常需在不同時間範圍內反覆聚類,以挖掘不同時段頻繁出現的子序列模式,從而為下游應用提供支持。當前最先進的時序聚類方法(如 K-Shape)能有效根據形態特徵進行聚類,但在數據量龐大、效率要求高的物聯網場景中,數據庫內的時序聚類問題始終未被充分研究。多數時序數據庫採用基於 LSM 樹的存儲架構應對高頻寫入,但這會導致底層數據點產生亂序時間戳。因此,若直接應用現有的數據庫外時序聚類方法,必須將所有數據完全加載到內存中,並重新按時間排序,且每次處理跨不同時間範圍的查詢時都需從頭開始聚類,效率低下。
本文提出數據庫內適配的時序聚類方法 K-Shape 改進方案,並針對長時序數據處理問題,提出 Medoid-Shape 方法及其數據庫內適配方案,以進一步提升使用速度。大量實驗證明,該方案在同等效果下顯著提升了效率。所有技術已在開源商用時序數據庫 Apache IoTDB 中實現。
📝全文鏈接:https://dl.acm.org/doi/10.1145/3709696
ICDE 2025: Collaborative Imputation for Multivariate Time Series with Convergence Guarantee
🎯論文名稱:具有收斂性保證的多變量時間序列協同插補
✍️第一作者:孫宇
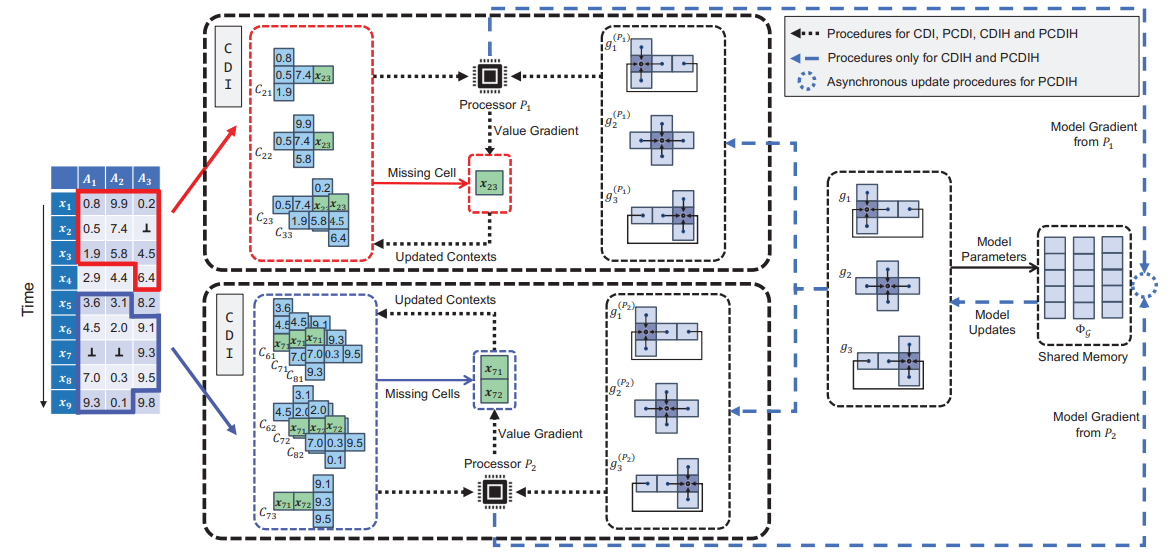
缺失值在多變量時間序列中經常出現,這影響了數據分析和應用。現有研究通常使用完整數據來訓練插補模型,然後用其填補缺失值。然而在實踐中,缺失值可能出現在不同的單元格中,這種多樣性阻礙了插補模型的性能,甚至在缺乏收斂保證(即無法確保在迭代趨於無窮時獲得最優解)的情況下使填補無法進行。原因在於:(1) 多個單元格的插補值在滿足模型一致性方面可能相互影響;(2) 從完整數據中獲得的依賴關係可能不足以準確插補大量未觀測值,這給收斂性帶來了更嚴峻的挑戰。
本論文中,我們研究了具有收斂性保證的協同插補方法。所謂“協同”,我們指的是:(1) 所有缺失單元格能夠以協同方式被插補,並保證符合模型一致性;(2) 插補模型也能根據填補值實現優化。我們的主要技術亮點包括:(1) 引入基於似然最大化的、具有統計可解釋性的協同插補方法;(2) 設計一種針對多個缺失單元格的協同插補算法,並將其等效擴展為並行版本;(3) 以協同方式並行優化插補值和模型,並在此過程中保證算法的收斂性;(4) 設計流式插補和自適應參數確定策略。
在真實不完整數據集上的實驗表明,我們的方法在插補準確性和下游應用性能上均優於十二種基線方法。
📝全文鏈接:https://ieeexplore.ieee.org/document/11112895
添加歐歐小助手(微信號:apache_iotdb),併發送“2025 論文”,可免費獲得“2025 IoTDB 論文合集”!