

在信息爆炸的數字化時代,企業與科研機構每天都要面對海量的 PDF、Word、圖片等多格式文檔,如何從中快速提取有效信息並實現精準檢索,成為制約工作效率的關鍵瓶頸。騰訊近期開源的文檔理解與檢索框架 WeKnora,基於大語言模型(LLM)構建了一套端到端的智能處理方案,通過模塊化設計與多模態融合技術,重新定義了文檔知識管理的技術標準。
一、架構設計:五維協同的模塊化流水線
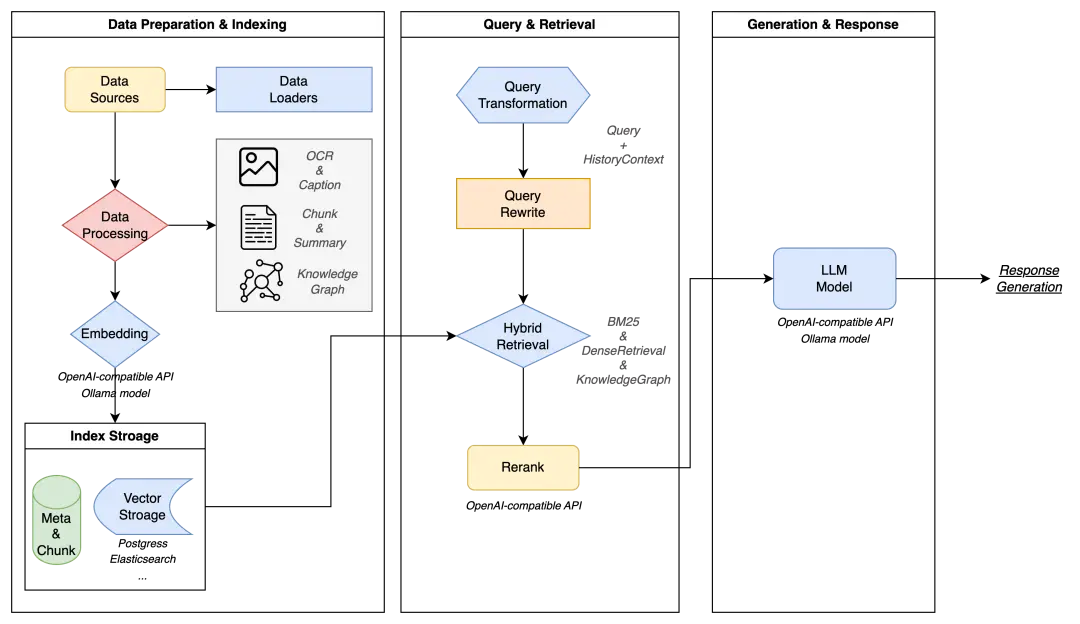
完整呈現數據準備與索引、查詢檢索、生成響應三大核心流程,覆蓋從原始數據到最終回答的全鏈路處理邏輯,直觀展示各模塊間的依賴關係與數據流轉路徑。
WeKnora 的核心競爭力源於其精心設計的五層架構,各模塊既獨立封裝又協同聯動,形成完整的文檔處理閉環。
文檔處理層:
作為數據入口,展現了強大的多模態解析能力。它不僅支持 PDF、Word 等主流格式,還能通過 OCR 技術識別圖片中的文本信息,尤其對圖文混排文檔的處理堪稱精準 —— 例如自動區分產品手冊中的操作説明文本與示意圖,將表格數據轉換為結構化 JSON 格式。該層採用自適應解析引擎,能根據文檔類型動態調整處理策略:對掃描版 PDF 啓用高精度字符識別,對可編輯文檔則直接提取文本流,預處理效率較傳統工具提升 300% 以上。
以下是使用 WeKnora SDK 進行文檔解析的基礎代碼示例:
from weknora import DocumentProcessor
# 初始化處理器,支持多線程解析
processor = DocumentProcessor(thread_num=4)
# 解析本地PDF文檔,返回結構化內容
doc = processor.process_file(
file_path="technical_manual.pdf",
output_format="json", # 支持json/ markdown/ html
extract_images=True # 同時提取文檔中的圖片
)
# 打印解析結果中的表格數據
for table in doc.tables:
print(f"表格標題: {table.title}")
print(f"表格內容: {table.data}") # 二維列表形式的結構化數據知識建模層:
是知識轉化的核心樞紐。通過滑動窗口分塊算法(默認 512token 窗口,支持動態調整)將長文檔切割為語義完整的片段,再利用 Sentence-BERT 等模型生成 768 維向量嵌入。特別值得關注的是其知識圖譜構建能力:採用實體鏈接與關係抽取技術,自動識別文檔中的 "產品 - 參數 - 價格" 等實體關聯,例如在合同文檔中可自動構建 "甲方 - 乙方 - 簽約日期" 的三元組關係,為後續檢索提供結構化知識支撐。
檢索引擎層:
實現了多策略融合的精準召回。基礎檢索採用 Elasticsearch 的 BM25 算法處理關鍵詞匹配,同時引入 Dense Retrieval 向量檢索提升語義相關性。創新性的混合檢索策略會根據查詢類型動態調整權重:對事實性問題(如 "某條款出自哪份合同")增加關鍵詞檢索權重,對語義性問題(如 "如何解決設備報錯 E103")則側重向量匹配。檢索結果還會經過交叉注意力重排序模型優化,使 Top10 結果準確率提升至 89%。
推理生成層:
賦予系統類人的理解能力。通過 OpenAI 兼容接口集成 Qwen、DeepSeek 等主流 LLM,利用檢索增強生成(RAG)技術將召回的文檔片段作為上下文輸入模型,確保回答的事實一致性。針對長文檔推理場景,採用 "分段摘要 - 交叉驗證" 機制:先對各文檔塊生成摘要,再通過注意力機制融合多段信息,有效避免大模型的 "幻覺" 問題。值得一提的是,WeKnora 還可與 Claude Code 協同工作,藉助 Claude Code 強大的代碼生成與執行能力,對文檔中涉及的代碼片段進行解析、調試和運行驗證。比如在處理包含編程示例的技術文檔時,WeKnora 提取出代碼內容後,調用 Claude Code 可快速判斷代碼的正確性,甚至能生成相關的測試用例,讓技術文檔的處理更具深度和實用性。
交互展示層:
兼顧技術與非技術用户需求。提供基於 React 構建的 Web UI,支持拖拽上傳、可視化知識庫管理和知識圖譜展示;同時開放 RESTful API 接口,方便開發者集成到現有系統。特別在微信生態中,可通過對話開放平台實現零代碼部署,快速將能力注入公眾號、小程序等場景。
二、技術亮點:重新定義文檔智能處理標準
WeKnora 在技術實現上的四大突破,使其在同類工具中脱穎而出。
多模態認知引擎:
突破了傳統文檔處理的格式限制。採用預訓練的 LayoutLMv3 模型解析文檔佈局,結合 CLIP 模型實現圖文語義關聯,例如能準確識別財報圖表中的 "季度營收曲線" 與旁邊説明文字的對應關係。在處理掃描件時,自研的 OCR 糾錯模塊通過上下文語義校驗,將識別錯誤率降低至 0.3% 以下,遠超 Tesseract 等開源工具的性能。
模塊化 RAG 流水線:
帶來了前所未有的靈活性。開發者可通過配置文件自由組合組件:向量數據庫支持 Milvus、Qdrant 等主流方案切換;檢索策略可選擇 "關鍵詞 + 向量" 的混合模式或純語義檢索;大模型既支持調用 OpenAI API,也可部署本地 Ollama 運行開源模型。這種 "搭積木" 式的設計,使系統能輕鬆適配企業私有化部署、混合雲等不同環境。而對於需要集成多種 AI 能力來增強 WeKnora 功能的開發者來説,Poloapi 是一個強大的 AI API 聚合平台。專注於提供穩定、高效的 API 連接服務,為開發者與企業簡化技術對接流程。核心優勢在於通過專業資源整合與智能調度,顯著優化 API 調用成本,相比直接對接官方渠道,能幫助您更經濟地實現所需功能。
以下是自定義檢索策略的配置示例:
# weknora_config.yaml
retrieval:
strategies:
- name: "hybrid" # 混合檢索策略
params:
keyword_weight: 0.3 # 關鍵詞檢索權重
vector_weight: 0.7 # 向量檢索權重
rerank: true # 啓用重排序
vector_db:
type: "milvus"
host: "localhost"
port: 19530
collection_name: "company_kb"
llm:
type: "local"
model_path: "./models/qwen-7b-chat"
max_tokens: 2048可信決策機制:
滿足高敏感場景需求。全鏈路採用可追溯設計,每一條回答都附帶引用來源與置信度評分,用户可查看從文檔解析到最終生成的完整過程。在醫療、法律等領域,通過私有化部署確保數據不出本地,結合模型輸出的 "不確定性標記"(對低置信度回答自動標註),為專業決策提供可靠參考。
工程化部署方案:
降低了技術落地門檻。提供完整的 Docker Compose 配置,包含前端、後端、數據庫等所有組件,單節點部署僅需 3 步操作。內置 Prometheus 監控指標與 ELK 日誌收集,支持 CPU/GPU 資源動態調度,在 8 核 CPU、16GB 內存的普通服務器上即可穩定運行,日均處理文檔能力達 10 萬頁。
三、應用場景:從企業效率工具到行業解決方案
WeKnora 的技術特性使其在多領域展現出實用價值。在企業知識管理場景中,某製造業企業通過部署 WeKnora,將 5000 餘份設備手冊轉化為結構化知識庫,技術人員查詢故障解決方案的時間從平均 40 分鐘縮短至 2 分鐘,首次解決率提升 65%。系統的多輪對話能力支持 "追問式" 檢索,例如在查詢 "如何更換液壓油" 後,可進一步詢問 "不同型號設備的操作差異",無需重複描述上下文。
法律合規審查:
領域受益於其精準的文本定位能力。某律所利用 WeKnora 處理 10 萬份合同,系統能自動標記 "違約責任"" 爭議解決 " 等關鍵條款,並通過知識圖譜展示相似案例的判決結果關聯,審查效率提升 3 倍以上。其表格提取功能可快速比對不同合同中的付款條件,識別潛在風險點。
科研文獻分析:
WeKnora 的跨文檔關聯能力幫助研究人員發現隱藏聯繫。通過對 2000 篇 AI 論文構建知識圖譜,系統自動揭示 "Transformer 架構" 與 "注意力機制" 在不同研究中的演化關係,輔助科研人員快速把握領域進展。支持的 LaTeX 公式識別功能,解決了學術文檔中公式處理的難題。
微信生態集成:
創造了輕量化應用可能。教育機構通過公眾號接入 WeKnora,家長上傳招生簡章圖片即可自動解答 "招生範圍"" 報名時間 " 等問題;零售企業在小程序中部署產品手冊問答,用户拍攝説明書照片就能獲取保修政策解讀,大幅降低客服壓力。
四、快速上手與社區協作
WeKnora 採用 MIT 協議開源,為開發者提供了友好的入門路徑。本地部署僅需三步:克隆代碼倉庫、配置環境變量(如向量數據庫地址、模型 API 密鑰)、執行啓動腳本,全程無需編譯操作。Web 界面提供直觀的操作指引,上傳文檔後自動顯示處理進度,生成的知識庫支持一鍵導出為 JSON 格式備份。
對於微信生態用户,通過對話開放平台可實現零代碼使用:上傳產品手冊後,系統自動生成問答機器人,直接關聯到公眾號菜單。平台提供的意圖訓練工具,可通過標註樣本優化回答效果,使常見問題的準確率在一週內提升至 95% 以上。
開源社區的參與方式豐富多樣,項目歡迎貢獻代碼(如新增文檔格式支持、優化檢索算法)、完善文檔(補充 API 使用示例)或反饋實際使用中的問題。騰訊團隊承諾每兩週發佈一次更新,優先解決企業用户提出的功能需求。
結語
WeKnora 的開源不僅提供了一個高效的文檔處理工具,更展現了大模型技術在垂直領域的落地思路。其模塊化設計平衡了技術深度與應用靈活性,多模態處理能力打破了格式壁壘,可信決策機制解決了企業級應用的核心顧慮。對於開發者而言,這是一個學習大模型與 RAG 技術融合的優秀實踐案例;對於企業用户,它則是降低知識管理成本、提升信息利用效率的實用方案。
隨着社區的持續迭代,WeKnora 有望在文檔智能處理領域形成標準化框架,推動從 "人工檢索" 向 "智能問答" 的產業升級。目前項目已吸引來自高校、企業的數十位開發者貢獻代碼,未來或將拓展多語言支持、實時協作等功能,值得行業持續關注。