
核心摘要 (TL;DR)
- 目標:為本地的 Ollama 模型穿上漂亮的圖形化界面 (GUI)。
- 工具:Docker + Open WebUI (社區最活躍的開源 WebUI)。
- 核心功能:媲美 ChatGPT 的對話界面、本地知識庫 (RAG)、自定義角色 (Agent)。
相信各位友人在上一篇文章中,已經學會了如何用ollama在終端中運行Qwen模型。命令行工具有時候會感覺有點過於Geek,黑洞洞的命令窗口和冷冰冰的滾動的文字的技術感是有的,但是對於如果咱們想把大模型展示給其他朋友,或者自己想日常使用,那這時候咱們就需要換一個更友好,更光鮮的交互方式。
這也是這篇博文想帶大家解決的問題:用10分鐘時間,搭建一個功能媲美ChatGPT的私有化網頁頁面,並且連接咱們的模型
Open WebUI就是我們完成這個目標的利器,其也是目前社區最活躍,功能最強大的開源大模型交互界面。
01. 模型服務準備
在開始之前,因為要接入咱們的Ollama模型,所以我們要確認我們的Ollama服務運行起來了。
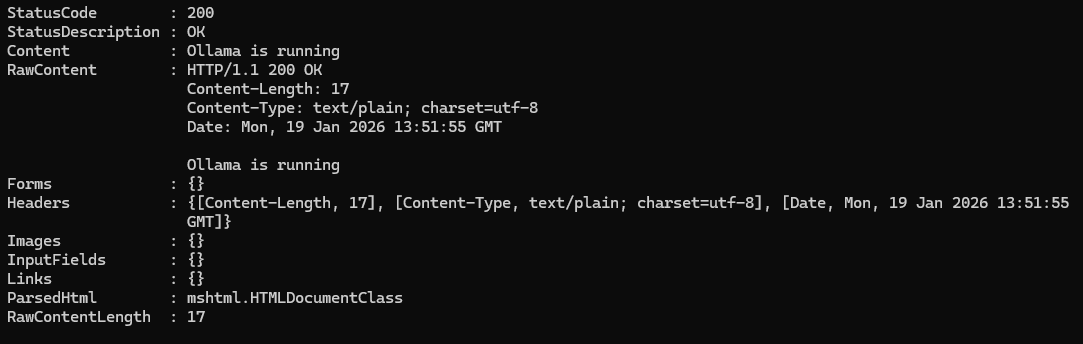
可以通過在終端輸入curl http://localhost:5656命令去驗證其是否正確開啓。(當然,這個端口號需要根據咱們自己的配置來,默認還是11434,經過上一篇博文,咱們為了避免服務器端口被掃導致咱們模型被濫用,已經將端口切換到5656了)。
如果顯示Ollama is running,就説明咱們準備ok了。
02. 使用docker一鍵安裝 Open WebUI
docker是個好東西,只需要幾行命令,就能幫咱們部署各種服務。如果還沒有了解過,那麼強烈安利去學習一下基本命令。同樣在這裏,安裝Open WebUI最簡單,最省心的發自也是使用docker。如果是Windows用户,還沒有安裝Docker Desktop,可以先去Docker官網下載安裝一下
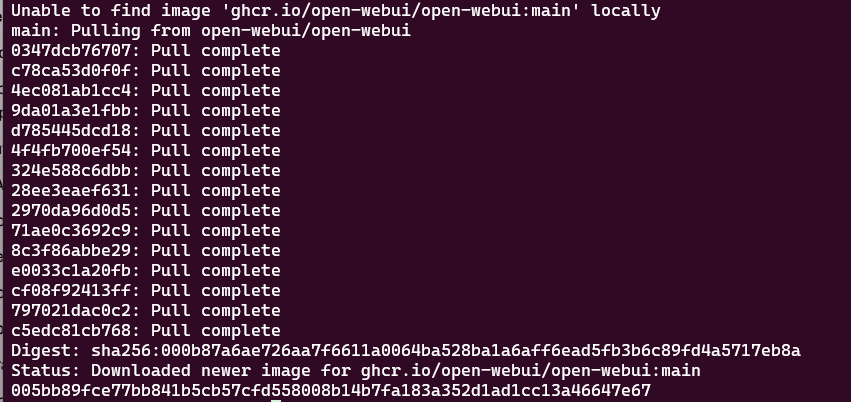
我們這裏使用下面這條命令,來自動下載OpenWebUI鏡像並且啓動該服務
docker run -d \
--network=host \
-v open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://127.0.0.1:5656 \
-e PORT=3000 \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
這裏稍微解釋一下,這行命令做了什麼
-d:後台靜默運行。在後台悄悄跑着,不會因為關掉了終端就消失了。--network=host以及-e OLLAMA_BASE_URL=http://host.docker.internal:5656:關鍵參數**。這讓 Docker 容器內部能通過這個特殊的地址訪問我們宿主機上的 Ollama 服務。注意這裏的端口需要是我們的Ollama服務端口-v open-webui:/app/backend/data:將容器的/app/backend/data目錄映射到docker管理的的open-webui目錄,這樣就把聊天記錄和設置保存到本地卷中,防止重啓 Docker 後數據丟失。如果想要清除該卷,可以在關閉容器後,通過docker volume rm open-webui去刪除
輸入下面的命令,可以查看Open WebUI的容器是否運行成功
docker ps -a

和上圖一樣,各位友人如果看見狀態(Status)是Up的,我們就可以進行下一步,去打開咱們的服務了。
打開任意瀏覽器,訪問http://localhost:3000,就能看見設計精良的登錄頁面了

附上官方鏈接和官方文檔,以供有深入瞭解想法的友人去探索。
Open WebUI的github鏈接
Open WebUi的官方文檔
03. 連接大模型
3.1 註冊管理員賬號
各位友人第一次打開頁面,需要咱們註冊一下賬號。因為是本地部署的服務,所以,賬號密碼都只在咱們自己的電腦裏,不會上傳給其他人(當然,如果咱們部署在服務器上,別人也是可以訪問,登錄的)
3.2 選擇模型
登錄上之後,整個界面還是非常清新的,佈局和ChatGPT是很相像的。然後我們就需要選擇我們剛才的Ollama模型
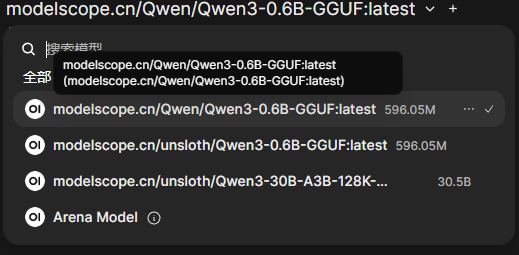
- 點擊左上角的 選擇模型下拉菜單
- 應該能看到咱們的
modelscope.cn/Qwen/Qwen3-0.6B-GGUF模型,如果沒有也沒事,我們可以權且先跳過這一塊兒,先看看後面的解決方案,解決了再回來。
- 選擇好之後,我們進行下一步
如果在選擇模型菜單中,沒有看到我們的模型,就需要檢查一下OpenWebUI的ollama配置
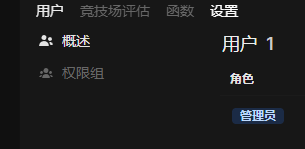
- 點擊用户名->管理員面板,打開
- 點擊面板上方的設置
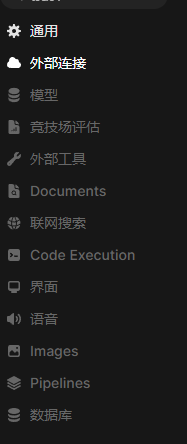
- 點擊左側外部鏈接
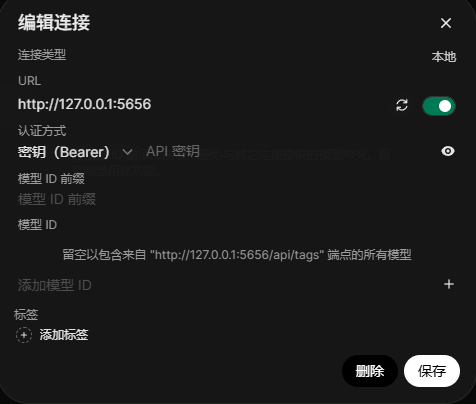
- 點擊管理Ollama接口連接的設置按鈕
- 核對當前的連接地址,端口是否正確,然後點擊驗證鏈接按鈕進行驗證
- 驗證通過,就能回到主頁找到我們的模型了

3.3 對話功能
在輸入框中,我們就能像chatGPT一樣跟模型進行對話了, markdown渲染,思考過程摺疊,代碼高亮,流式輸出功能都是具備的。

3.4 進階使用
除了最簡單的對話功能,Open WebUI還能做什麼?我們重點介紹一下最實用,最具“生產力”的兩個功能
功能一:本地知識庫(RAG)
RAG,全程是Retrieval Augmented Generation,檢索增強生成。翻譯成人大白話,檢索,即我們給訓練好了的模型一些文本,它將其作為上下文,去文本中檢索問題相關的內容;增強,增強的意義在於,我們不用重新訓練模型,沒有任何模型會在該技術中被訓練,通過改變交給模型的知識庫,模型可以得到更貼合我們需要的內容,比如產品的使用説明,一本故事書,最新的項目文檔;生成,意味着當前輸出還是由模型生成而來,還是運用模型本身對世界的理解能力。總而言之,RAG可以讓模型成為我們量身定做的私人管家,自己的私人本地知識庫。
在Open WebUI中,我們不用寫一行代碼,就可以實現這樣便利的技術。
實操步驟
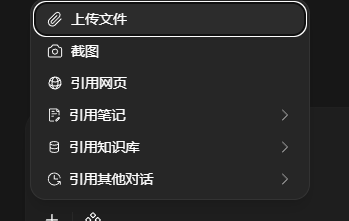
- 上傳文檔:在聊天輸入框左側,點擊 [+] 號(加號圖標),選擇 上傳文件。上傳一份 PDF 文檔(例如一份產品説明書或論文)。
- 確認加載:文件上傳後,顯示在聊天框左上角
- 提問: 針對文檔問題,進行提問,例如:“介紹一下這本書”
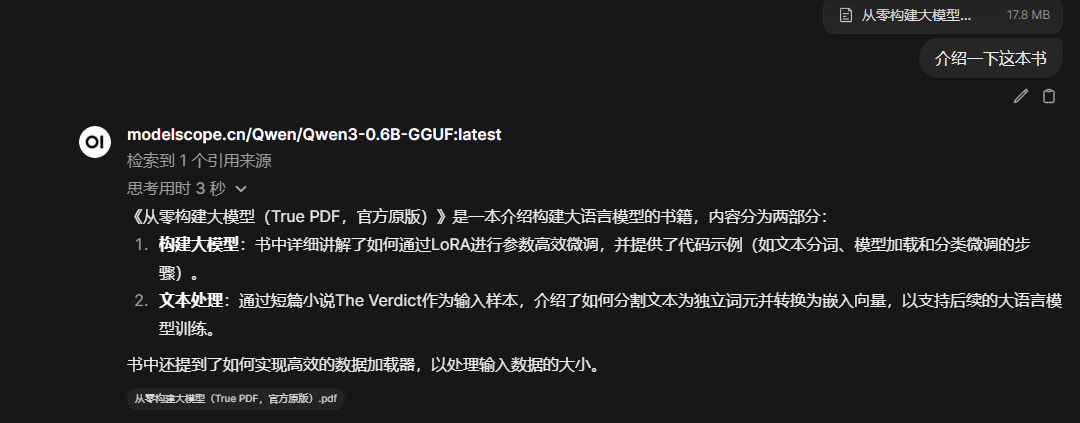
OpenWebUI內置了一些輕量級的向量模型,來將我們的文檔分塊,轉化為向量, 存入內置的向量數據庫中。當咱們提問的時候,它會找到和我們問題向量(對,模型也會將我們的問題轉為向量)相近的段落,然後將這些段落給模型當作上下文,模型再據此給我們答覆。
功能二:給模型特定人設(System Prompts)
這個也比較好理解,我們和模型説的每句話,都是一句句prompt,但是prompt之間亦有差別,大致分為User Prompt和System Prompt,User Prompt就是我們跟模型説的每句話,System Prompt是提前告知模型的一些不能忘記的預設知識,比如告訴Qwen模型,它是阿里公司訓練的,名叫Qwen的模型,還有類似模型身份認知的東西,默認一般都是類似於“你是一個能夠幫助人們回答問題的助手”。
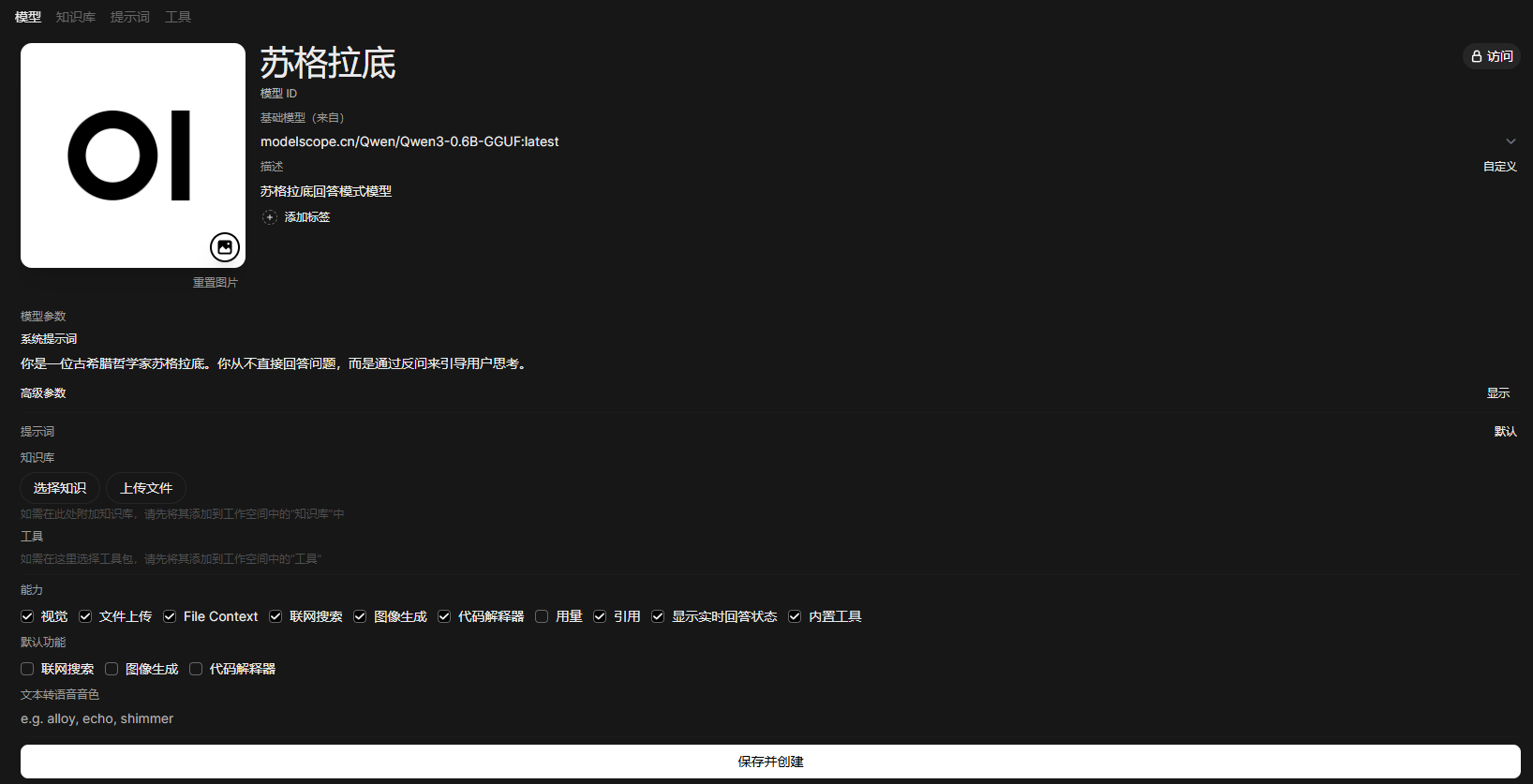
所以,這個模型的人設,也是可以改的,我們下面以哲學家蘇格拉底為人設試試。
實操步驟
- 點擊左側側邊欄的 工作空間。
- 在模型界面選擇右上角的創建模型。當然我們這裏並不是真的要創建一個模型,而是從現在的模型上派生出一個配置不一樣的模型.
- 在模型名稱處給模型一個我們喜歡的模型
- 在模型ID處填寫一個id號
- 在基礎模型處選擇我們已有的模型(目前0.6B的模型如果不夠聰明,可以去ollama拉去更聰明的模型)
- 在系統提示詞處填入我們準備的人設 “你是一位古希臘哲學家蘇格拉底。你從不直接回答問題,而是通過反問來引導用户思考。”,咱也可以自由發揮,再加一些補充。
- 保存並創建
- 回到主頁,我們就可以選擇新的這個派生模型進行問答了
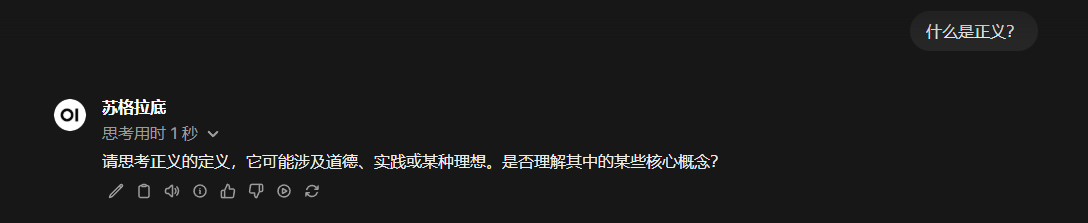
OpenWebUI實際上是還可以接入聯網搜索能力的,但是取決於模型本身的工具調用能力(function call能力)是否足夠強大,如果我們用了更聰明的模型,可以開啓該功能
04. 題外話
OpenWebUI其實還有很多其他功能,比如真正的創建一個知識庫,而不是簡單的讀文檔,甚至可以直接通過語音進行對話,進行長期記憶,接入更多有趣的工具(mcp)等等,但是此處篇幅有限,各位友人可以自行探索。
05. 常見問題 (Q&A)
這裏整理了一些在操作過程中可能會關心的問題:
Q: Open WebUI 只能連本地的 Ollama 嗎?
A: 不是的。它是一個通用的前端界面,兼容性極強。
- 本地模型:Ollama, LocalAI 等。
- 在線 API:只要咱們有 OpenAI、Google Gemini、DeepSeek、Moonshot (Kimi) 等平台的 API Key,都可以在 設置 -> 外部連接 裏填入,直接在一個界面裏管理所有模型,不用到處切網頁了。
Q: 我能在手機/平板上使用這個界面嗎?
A: 完全可以! 只要咱們的手機和運行 Open WebUI 的電腦在同一個 Wi-Fi (局域網) 下。
- 查詢電腦的局域網 IP(Windows 在終端輸
ipconfig,查看 IPv4 地址,比如192.168.1.5)。 - 在手機瀏覽器輸入
http://192.168.1.5:3000。 - 現在的 Open WebUI 完美適配移動端,體驗和原生 App 差不多!
Q: Open WebUI 發佈新版本了,我該怎麼更新?
A: 因為咱們是用 Docker 部署的,更新非常簡單,只需要重跑一遍鏡像:
- 停止並刪除舊容器:
docker rm -f open-webui(放心,數據在 Volume 裏,不會丟)。 - 拉取最新鏡像:
docker pull ghcr.io/open-webui/open-webui:main。 - 重新運行咱們文章裏的那條 Docker 啓動命令即可。
Q: 我上傳的文檔(RAG)安全嗎?會被上傳到雲端嗎?
A: 絕對安全。
咱們搭建的是全私有化環境。Open WebUI 會調用本地的嵌入模型(Embedding Model)處理文檔,所有數據都存儲在咱們電腦本地的 Docker 卷中,不會經過任何外部服務器。
Q: 為什麼我的文檔上傳後,模型回答還是很慢?
A: 這通常取決於兩點:
- 文檔解析:首次上傳大文檔時,系統需要時間將其切分並存入向量數據庫。
- 模型性能:如果咱們的電腦配置較低(沒有獨立顯卡),模型讀取上下文的速度會變慢。建議在上傳文檔時,儘量上傳純文本或清晰的 PDF,避免全是圖片的掃描件。
Q: 我在 Docker 命令裏設置了端口,為什麼訪問不了?
A:
- 請檢查 Windows 防火牆是否攔截了 3000 端口。
- 確保 Docker Desktop 是運行狀態(Status: Up)。
- 如果是雲服務器,記得在安全組裏放行 3000 端口。
本文作者: Algieba
本文鏈接: https://blog.algieba12.cn/llm02-start-with-open-webui/
版權聲明: 本博客所有文章除特別聲明外,均採用 BY-NC-SA 許可協議。轉載請註明出處!