









之前使用Ollama基於順序調用的場景比較了3090和4090的顯卡性能:
Ollama大模型推理場景下3090和4090性能實測
同時,又基於3090顯卡比較了Ollama和vLLM在順序調用和多併發推理場景下的性能差異:
Ollama和vLLM大模型推理性能對比實測
這裏再使用vLLM測試下大模型併發推理場景下3090和4090兩張顯卡的性能表現,看下4090是否在高併發場景下具備更高的擴展性。
在GPU算力租用平台 晨澗雲 分別租用3090顯卡和4090顯卡的vLLM雲容器進行測試。
大模型選擇
選擇 Qwen3的模型進行測試,考慮到都是24GB的顯存,選擇的是FP16精度的qwen3:8b模型進行測試。
藉助DeepSeek 生成測試腳本,調整腳本控制變量:
-
使用複雜度近似的N個prompts;
-
MAX_TOKENS配置256,讓每次請求需要一定的生成時長便於採樣顯卡的使用指標,減少波動; -
選擇
[1, 4, 8, 16]4種BATCH_SIZES測試不同併發度下的性能表現; -
每輪測試執行3次推理,指標取平均;
-
同時需要模型預熱,消除第一次推理響應延時過大的問題。
然後執行推理性能測試腳本,查看輸出結果。
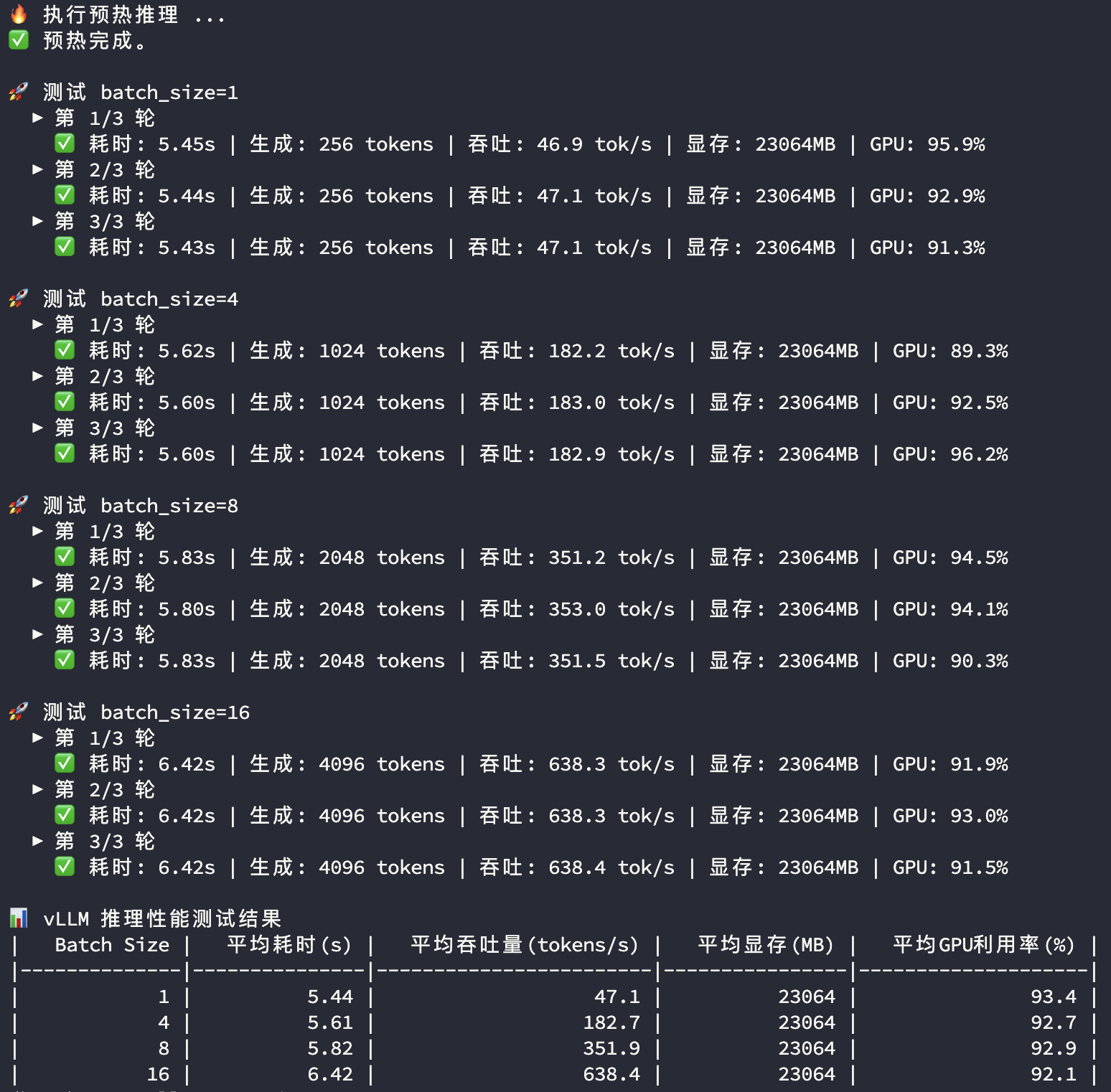
3090推理性能
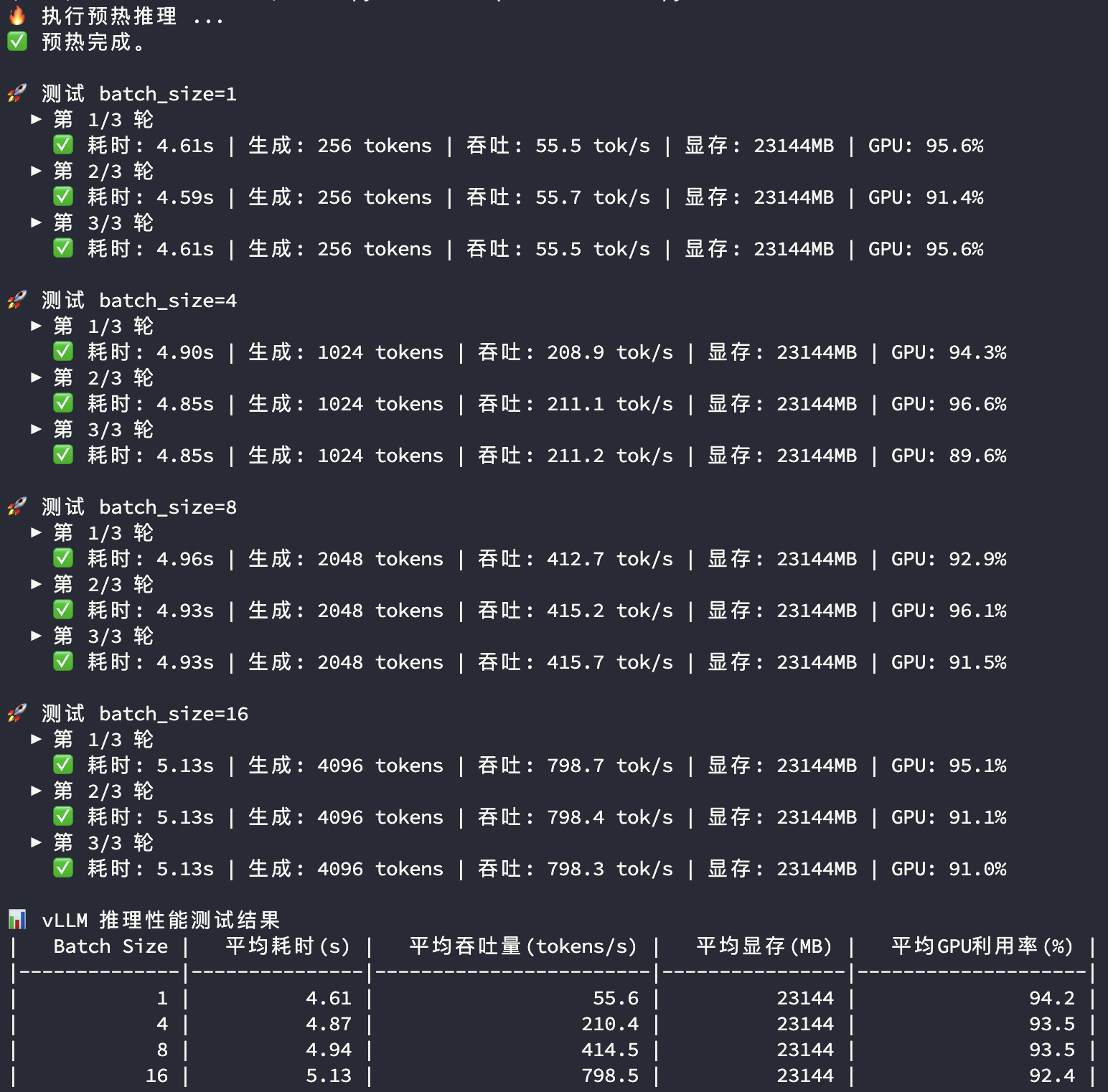
4090推理性能
測試結果解釋
-
Batch Size:一次推理調用的併發prompt數量
-
平均耗時 (s):多次推理平均響應時長
-
平均吞吐量 (tokens/s):多次推理平均Token生成速度
-
平均顯存 (MB):多次推理平均顯存使用量
-
平均GPU使用率(%):多次推理平均GPU使用率
3090顯卡和4090顯卡在模型推理過程中的顯存和GPU使用率都比較接近,主要看平均耗時及平均吞吐量兩個指標:
| Batch Size | RTX 3090 | RTX 4090 | 對比 | |
|---|---|---|---|---|
| 1 | 平均耗時(s) | 5.44 | 4.61 | |
| 1 | 平均吞吐量(tokens/s) | 47.10 | 55.60 | 118.0% |
| 4 | 平均耗時(s) | 5.61 | 4.87 | |
| 4 | 平均吞吐量(tokens/s) | 182.70 | 210.40 | 115.2% |
| 8 | 平均耗時(s) | 5.82 | 4.94 | |
| 8 | 平均吞吐量(tokens/s) | 351.90 | 414.50 | 117.8% |
| 16 | 平均耗時(s) | 6.42 | 5.13 | |
| 16 | 平均吞吐量(tokens/s) | 638.40 | 798.50 | 125.1% |
1~8併發度場景下,3090和4090的推理性能均保持穩定,4090比3090高17%左右;在16併發度下3090開始遇到性能瓶頸,而4090顯然較3090有更充足的剩餘性能空間。
