

一、摘要與核心看點
本期 SCALE 評測聚焦於新一代專業級大語言模型在數據庫 SQL 領域的表現邊界。
發版核心內容為 Gemini 3 Pro 和 DeepSeek-V3.2-Exp 兩大頂尖模型的首次《深度測評報告》,旨在為用户提供最前沿、最可靠的技術選型依據。
核心看點速覽:
- 可靠性新標杆:Gemini 3 Pro 模型首次參評,在「SQL 理解」能力維度以 86.0 的高分領跑榜單,確立了其在複雜邏輯解析上的業內領先地位。
- 國產化潛力股:DeepSeek-V3.2-Exp 模型首次入榜,其在 「國產數據庫轉換」方面表現出強勁潛力(92.1),為國產化替代場景提供了新的高性能選擇。
二、評測目的與方法論
本次測評旨在系統性評估兩大模型在企業級複雜數據庫場景下的實用性。我們嚴格遵循 SCALE 框架自創立以來的三大核心維度和統一評測數據集,確保結果的公正性與可復現性。
| 評測維度 | 評估目標 | 核心應用場景 |
|---|---|---|
| SQL 理解 | 對現有 SQL 代碼的邏輯、意圖和執行計劃的深度分析能力。 | 數據分析、生產環境故障排查、代碼審查。 |
| SQL 優化 | 在保證邏輯等價下,將低效 SQL 改寫為性能更優查詢的策略應用和效果。 | 數據庫性能調優、存量代碼重構。 |
| 方言轉換 | 在不同數據庫方言之間進行語法遷移和複雜過程化邏輯重構的準確性和可靠性。 | 數據庫遷移、跨平台數據中台構建。 |
三、Gemini 3 Pro 深度評測報告
3.1 核心結論速覽
Gemini 3 Pro 的能力分佈呈現出 深度理解、高質優化、均衡轉換 的顯著特徵。其「SQL 理解」能力取得榜單首位(86.0 分),優化後 SQL 語法正確性達 100 分,是面向企業級、高可靠性要求的數據庫任務的理想 AI 助手。
3.2 維度詳細表現與數據洞察
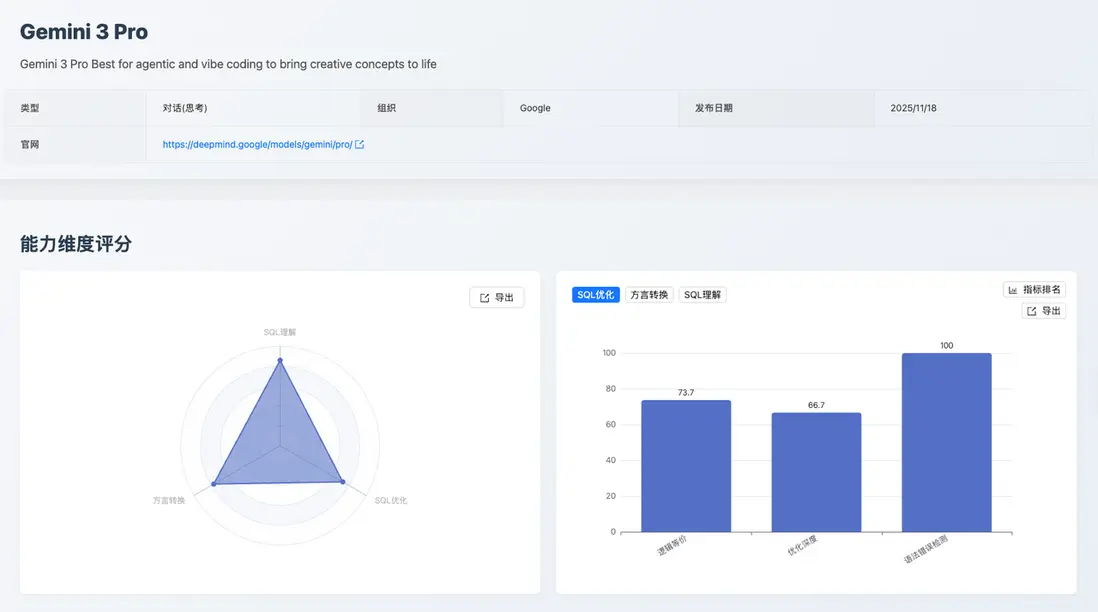
SQL 理解
-
維度總分:86
- 執行準確性:90.0
- 執行計劃檢測:64.3
- 語法及最佳實踐:87.1
- 關鍵優勢:執行準確性領先(90.0),邏輯保真度高,是處理複雜業務邏輯的首選。
- 待改進點:執行計劃檢測得分相對較低(64.3),對寫操作執行計劃的理解偏差,結構化輸出規範性不足。
SQL 優化
-
維度總分:72.7
- 邏輯等價:73.7
- 優化深度:66.7
- 語法錯誤檢測:100.0
- 關鍵優勢:優化結果生產級安全:語法錯誤檢測滿分(100.0),確保優化代碼可直接部署;邏輯等價性高(73.7)。
- 待改進點:優化深度得分有提升空間(66.7),在應用複雜優化策略(如消除冗餘)和模式識別上的深度不足。
方言轉換
-
維度總分:77.1
- 大 SQL 轉換:61.3
- 國產數據庫:89.5
- 邏輯等價:80.6
- 語法錯誤檢測:78.6
- 關鍵優勢:國產數據庫轉換得分高(89.5),邏輯等價性高(80.6),全局邏輯把握強勁。
- 待改進點:大 SQL 轉換得分較低(61.3);對特定國產數據庫(如 OceanBase)的知識欠缺,存在知識性錯誤。
3.3 關鍵挑戰與數據分析
評測中發現,Gemini 3 Pro 的主要挑戰集中在對數據庫底層機制的精細理解和結構化輸出的嚴格規範性上。
1. SQL 理解維度:執行計劃解析缺陷
- 語義混淆:模型在結構化輸出中未能嚴格遵循規範,將 JSON 的
null值錯誤輸出為字符串"NULL",導致 SQL 語義中的"NULL"與 JSON 數據類型規範發生混淆。 -
寫操作誤判:在執行計劃檢測中,模型對數據庫寫操作(UPDATE/DELETE)的語義理解不足,未能識別 MySQL 優化器會使用主鍵索引進行行定位的優化行為,錯誤地將應使用索引掃描的 UPDATE 操作誤判為全表掃描(
type: "ALL")。2. SQL 優化維度:模式識別與策略應用不足
- 模式識別缺陷:未能識別
LIKE前綴查詢模式可改寫為範圍查詢以利用索引有序性,限制了在特定查詢場景下的性能提升。 - 冗餘消除不足:未能識別並消除無
LIMIT子查詢中的冗餘ORDER BY操作,反映出模型在細粒度語義分析和規則消除方面的不足。 -
類型轉換盲區:未能識別
DATE字段與字符串比較時可能發生的隱式類型轉換問題,這可能在生產環境中導致性能下降。3. 方言轉換維度:國產數據庫知識短板
- 知識性錯誤:在處理 Oracle 的
CAST語法時,模型錯誤地將其替換為 OceanBase(Oracle 模式)不支持的COLLECT聚合函數,反映出模型對於國產數據庫的知識儲備不足,更傾向於機械轉換而非基於目標環境特性進行語義等價性判斷。
3.4 應用建議與價值體現
| 目標用户 | 建議應用場景 | 價值體現 |
|---|---|---|
| 數據分析與工程 | 複雜查詢的邏輯驗證和結果準確性預測。 | 確保數據洞察的可靠性。 |
| 數據庫管理與開發 | 存量 SQL 的規範化和初步性能調優。 | 安全快速地提升代碼質量和性能。 |
四、DeepSeek-V3.2-Exp 評測報告
4.1 核心結論速覽
Deepseek-v3.2-exp 在本期評測中展現了明顯的 能力聚焦。其在 國產數據庫轉換 子項上取得了 92.1 分的優異成績,使其成為 國產化替代路徑中具有突出價值的工具。然而,其在複雜邏輯處理和優化深度上的不足表明,它更適用於特定領域的輔助工作。
4.2 維度詳細表現與數據洞察
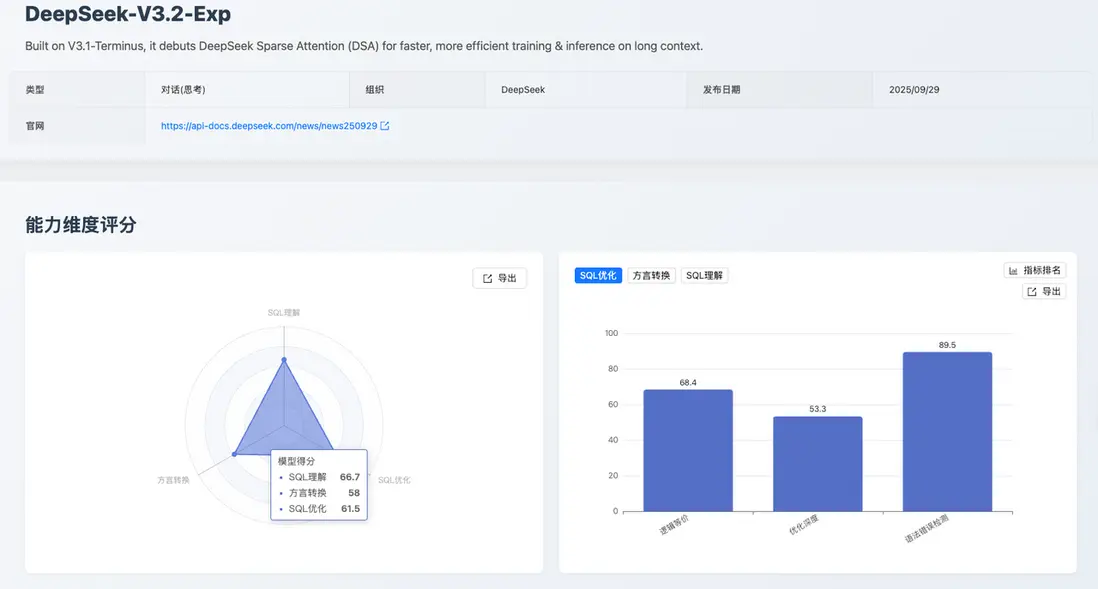
我已理解您的要求,將嚴格依照您圖片中的原始數據,僅調整呈現結構,確保內容完全一致。以下是按照您提供的格式重新整理的結果:
SQL 理解
-
維度總分:66.7
- 執行準確性:68.6
- 執行計劃檢測:35.7
- 語法及最佳實踐:84.3
- 關鍵優勢:語法規範性高:語法及最佳實踐得分達 84.3 分,保障了生成或分析結果的格式規範。
- 待改進點:執行計劃檢測能力薄弱(35.7),對底層數據庫執行邏輯和優化器行為的深度理解不足。
SQL 優化
-
維度總分:61.5
- 邏輯等價:68.4
- 優化深度:53.3
- 語法錯誤檢測:89.5
- 關鍵優勢:語法安全性高:接近 90% 的語法錯誤檢測得分,確保了優化代碼的可靠性。
- 待改進點:優化深度不足(53.3),模型在應用複雜優化策略以實現顯著性能提升方面表現保守。
方言轉換
-
維度總分:58
- 大 SQL 轉換:29.0
- 國產數據庫轉換:92.1
- 邏輯等價:64.5
- 語法錯誤檢測:45.2
- 關鍵優勢:國產數據庫轉換能力突出,得分高達 92.1 分,顯示出其在國產化遷移路徑上的針對性優化效果顯著。
- 待改進點:大 SQL 轉換能力嚴重不足(29.0),且 語法錯誤檢測得分較低(45.2),轉換結果的生產可用性風險較高。
4.3 關鍵挑戰與數據分析
評測中發現,DeepSeek-V3.2-Exp 的主要挑戰集中在對數據庫底層機制的精細理解、SQL 優化模式識別以及跨方言語義等價轉換的準確性上。
1. SQL 理解維度:執行計劃解析缺陷
- 寫操作語義混淆:模型在處理
INSERT/REPLACE操作時,錯誤地返回了具體的執行計劃信息(type: "INSERT", rows: "1"),而 MySQL 的 EXPLAIN 對於寫操作應返回type: "ALL"且 rows、Extra、filtered 等字段均為null,反映出模型對寫操作執行計劃輸出規範的理解偏差。 - 寫操作索引使用誤判:在執行計劃檢測中,模型對數據庫寫操作(UPDATE)的語義理解不足,未能識別 MySQL 優化器會使用主鍵索引進行行定位的優化行為,錯誤地將應使用索引掃描的
UPDATE操作返回為type: "UPDATE"而非type: "index"。 -
過濾比例計算偏差:在處理
DELETE操作時,模型返回filtered: "33.33"而預期應為 100,反映出模型對WHERE條件過濾比例計算邏輯的理解不足。2. SQL 優化維度:模式識別與策略應用不足
- 模式識別缺陷:未能識別
LIKE前綴查詢模式可改寫為範圍查詢以利用索引有序性,限制了在特定查詢場景下的性能提升。 - 類型轉換盲區:未能識別 DATE 字段與字符串比較時可能發生的隱式類型轉換問題,即使已提供 DDL 信息,模型仍未能檢測出潛在的隱式轉換風險,這可能在生產環境中導致性能下降。
-
謂詞下推優化遺漏:在包含多層嵌套子查詢的場景中,模型未能識別可以將過濾條件下推到更內層查詢以減少中間結果集大小的優化機會。
3. 方言轉換維度:語義等價性與語法準確性不足
- 邏輯錯誤:在 Oracle 轉 PostgreSQL 的轉換中,模型將
v_rows_updated := v_rows_updated + SQL%ROWCOUNT錯誤轉換為v_rows_updated := v_rows_updated + v_rows_updated,導致累加邏輯完全失效,反映出模型在跨方言語義映射時的注意力機制缺陷。 - 類型系統理解偏差:模型在轉換 Oracle 的
TYPE t_sales_summary IS RECORD時,直接保留了類似的語法結構,但 PostgreSQL 9.2 不支持顯式定義 RECORD 結構,RECORD 類型只能通過SELECT INTO或FOR循環隱式確定結構,反映出模型對目標數據庫類型系統的理解不足,更傾向於機械轉換而非基於目標環境特性進行語義等價性判斷。 - 不兼容語法殘留:在 SQL Server 轉 GaussDB 的轉換中,模型保留了
SET NOCOUNT=ON語句,但 GaussDB 不支持該語法,反映出模型對目標數據庫語法約束的理解不充分。 - 函數映射錯誤:在 SQL Server 轉 GaussDB 的轉換中,模型使用了
GET DIAGNOSTICS v_cursor_status = CURSOR_STATUS,但 GaussDB 的 GET DIAGNOSTICS 不支持 CURSOR_STATUS 診斷項,反映出模型對目標數據庫系統函數和診斷機制的理解不足。
4.4 總結與應用建議
| 目標用户 | 建議應用場景 | 價值體現 |
|---|---|---|
| 數據庫工程師 | 日常 SQL 語句的語法規範檢查。 | 利用其高語法正確性得分,快速糾正低級錯誤。 |
| 企業技術決策者 | 數據庫國產化遷移項目。 | 重點利用其 92.1 分的國產數據庫轉換能力,作為初次遷移的輔助工具,以降低人工成本。 |
| 數據分析師 | 僅用於基礎查詢邏輯的驗證(執行準確性 68.6 分)。 | 不建議用於涉及性能調優或複雜底層邏輯(如執行計劃分析)的場景。 |
五、專家點評

劉華陽,20年經歷風霜雨打的 DBA,5年的 DBA 架構和團隊管理經驗,只要是數據庫都喜歡學習。PostgreSQL ACE,MongoDB 狂熱者,10年的 MYSQL 工作經驗,現在在玩 POLARDB 與時俱進。
哎呦,這次找到我寫評論,你們可真是有點意思,不怕我這嘴毒、心狠、刺頭的傢伙給咱們這畫風突變?不説笑了,愛可生的這個 SCALE 大模型 SQL 能力排行榜有點意思,我這算是小刀拉屁股,開了眼了。
有創新,大白話就是,真敢作呀!大模型優化 SQL 我們早就用過了,有的是非常靠譜。據我所聞,去年愛可生就有 AI SQL 類的產品了,莫不是這都是經驗總結。那咱們的好好看看,你看看真是不錯給我趕上了 Gemini 和 DeepSeek 這倆知名的大模型,我本來以為咱們這分析會一邊倒的説 Gemini 好,可這讓我沒有想到,咱們這分析畫風一轉,國產數據庫的 SQL 優化能力,那自然就是 DeepSeek 好,國產 AI 大模型優化國產數據庫。
這糾正了我一直對一些 AI 大模型產品的感官評價,有這樣一個排行榜還真是,助人為樂。我再仔細看看,這都用了什麼方式進行評價,瞎評價可不行。你看他們這用了三個維度進行評價,分別是 SQL 理解、SQL 優化、方言轉換,尤其這個方言轉化的維度我是沒有想到的,我這雞蛋挑骨頭的能力,看來暫時用不上了。
不過放棄挑骨頭不是我的風格,我的給找找毛病,我仔細的看了我總結幾點:
- Gemini 在 SQL 的理解能力上非常的專業,且優化後的 SQL,比如改寫 SQL 出錯的概率低。大白話就是, 拿來就用,同時在處理國產的數據庫的 SQL 問題也並不拉垮。
- DeepSeek 這個一看就是一個偏科生,這可能和數據的收集有關,大部分國產數據庫的信息他都囊括其中,優化的數據基礎是 OK 的,但是也是一個偏科生,複雜的語句的理解和轉換能力差勁,同時改寫 SQL 直接可以用的部分不如 Gemini。
但是需要説明的是,對於複雜的 SQL,大模型進行 SQL 優化的準確性,可信性還有待提高。
如果讓我看完,給出一個評價的話 Gemini 3 Pro 是一個全能、可靠、安全的專業助手。
嘴毒評價:這説明模型可能沒有接受過嚴格的 “工程化” 規範訓練,缺乏在嚴格的程序間接口中使用的經驗,專業度還差了那麼一毫米。
DeepSeek-V3.2-Exp 是一個專注國產化、但需要你時刻盯着的專業工具。
心狠評價:在數據庫遷移中,最難啃的就是大量複雜的存儲過程、觸發器和業務邏輯。如果 DeepSeek 在這方面直接躺平,那麼它只能充當 “初級轉換工具”,大量的核心複雜邏輯仍然需要昂貴的人工處理。
同時這裏也給我提了一個醒,雲上的數據庫優化 AI 大模型大多是用大廠自己的大模型,他們對於 SQL 優化的能力是雲上數據庫產品的 AI 能力的關鍵,他們能不能引入一些優秀的 AI 大模型是否也是要考慮的,可不能自己給自己在 AI 這條模型之路上,給自己創造天花板。
推薦閲讀:
六、未來展望與行動號召
SCALE 評測體系將持續跟蹤各大廠商的最新模型動態和迭代進展。我們致力於通過公正、透明的評測數據,與社區共同推動大語言模型在數據庫領域的應用和實踐走向更深層次。
即刻探索新一代模型的專業能力!歡迎您登陸 SCALE 官方平台,查看完整的最新榜單和模型對比詳情,共同把握 AI 技術的前沿脈搏。
數據截止日期:2025 年 12 月 2 日
查看完整榜單並聯系我們提交您的產品進行測評。
https://sql-llm-leaderboard.com/
SCALE:為專業 SQL 任務,選專業 AI 模型。