









前言
我之前寫過兩篇如何構建 AI 應用 / AI Agent 的文章,裏面涵蓋了多個環節,多個領域的組件,整體的核心思路是想表達 AI 應用的本質是以 AI Agent 為表現層/推理指引層/業務入口層的一個有機系統,Sandbox,LLM,MCP,MEM,可觀測等都是這個系統裏重要的組成。
《萬字長文告訴你企業如何基於MCP實現AI應用架構新範式轉型》
《3個月,200+客户,4萬+字,和大家聊聊企業AI應用(AI Agent)的落地實踐》
但是目前鮮有客户完全落地了這套系統,而更多的是使用其中某幾個組件做 POC 和嘗試,最常見的組合就是普通服務 + LLM,進階一點的就是普通服務 + LLM + MCP(不帶MCP Registry)。使用 AI 網關和 MSE Nacos 也有比較成熟的落地方案,所以今天通過真實案例,向大家分享再進階一點的 Sandbox 的落地實踐。
AI Agent 試驗田
目前,LLM的使用被大眾最廣泛認知的還是以 Chat 模式為主,而 AI Agent 讓大家體感最強的,或者説目前應用最好的是在 Coding 場景,而且每家廠商幾乎都將 Coding 功能明顯的展現了出來。
- 通義千問:
- Minimax:
- Gemini:
- Kimi:展示的相對隱晦一些。
- Grok:算是為數不多不主打 Coding 的 LLM,但 Grok 4 Heavy 的 Coding 能力也不賴。
- ChatGPT:還是以 DeepSearch,任務推理為主,沒有明顯展現出其 Coding 能力。






之所以各個廠商都在 Coding 場景落地 AI Agent,我個人認為有這麼幾個因素:
- 人潛意識裏其實都有創造的慾望,但絕大多數人都只有想法,沒有實踐落地能力。大模型出來後,在某些場景下可以幫助人們實現想法,滿足了人們的部分慾望,但人的慾望是無限的,之前那些產物並不能變現,比如最早時期 SD 出來那會。LLM Coding + Vibe Coding 概念出來後更是引起了一股浪潮,最重要的是 LLM Coding + Vibe Coding 的產物是有機會變現的,甚至開公司創業。
- Coding 的產物可以被大眾的評判標準量化,從而直觀的體現出 LLM 能力的強弱。現在評測 LLM 能力的那些數據集的質量以及客觀公正性我在這裏就不贅述了,絕大多數人對那個是無感的。但是 LLM 寫出來的代碼至少是能被廣大開發工程師拿來檢驗的。
- Coding 的場景幾乎用到了AI Agent 系統的所有必備要素。Planning,Sandbox,LLM,MCP,MEM,可觀測等。需要將這些要素有機的結合起來,構成 Coding AI Agent 系統,才能讓 LLM 寫出相對成熟可用的代碼。
- 當 AI Agent 這套系統在 Coding 場景下驗證成熟後,整套 AI Agent 系統的架構可以很快複用到其他場景,只需要替換整體架構裏具象的組件即可,比如替換 LLM 版本,替換不同的 MCP 服務,替換不同的 Prompt,替換不同的 RL 評測方式等。
泛 Chat 類型 Coding AI Agent 整體架構
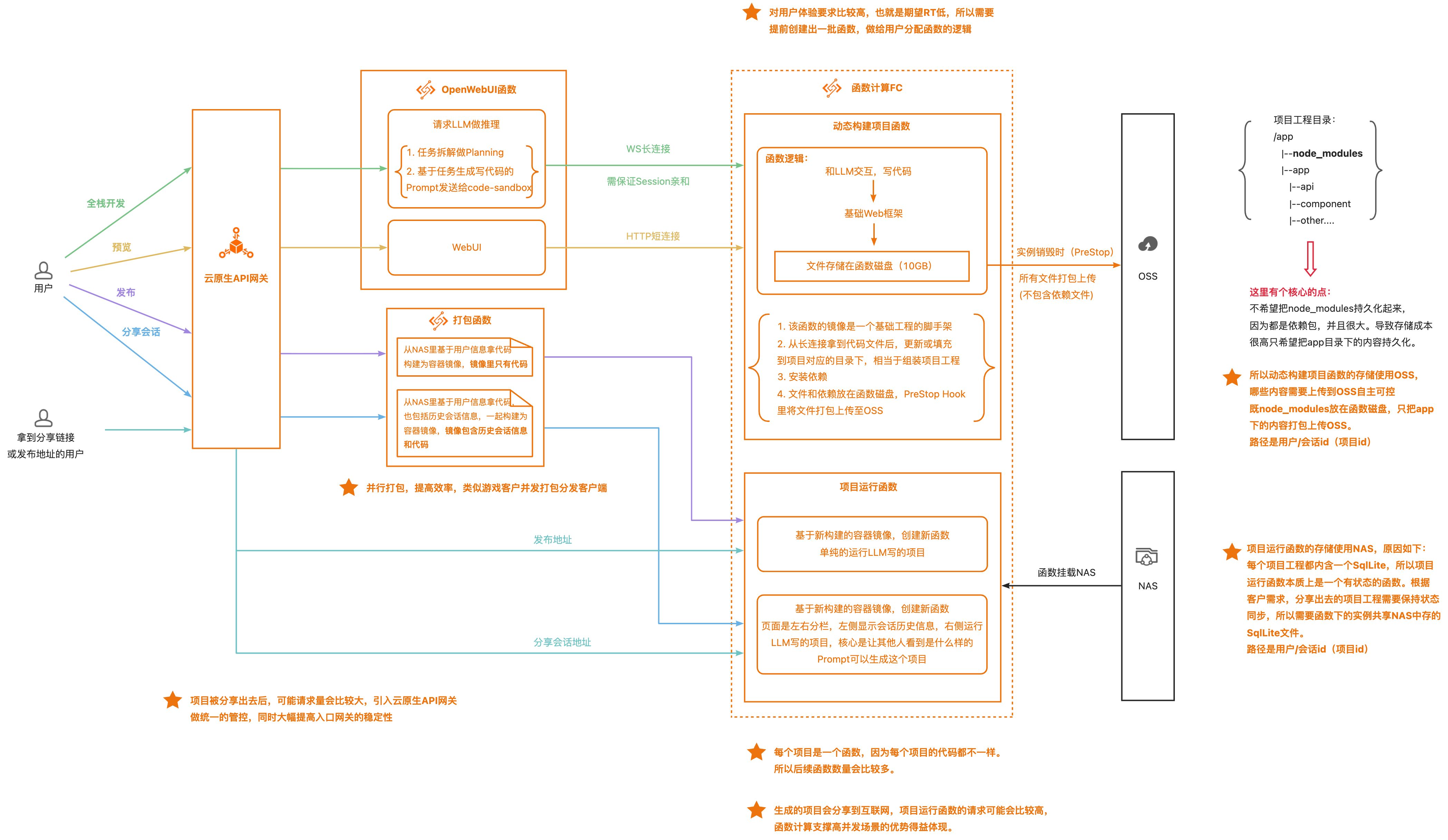
這裏我不對整體架構做解釋,我想通過落地過程中,或者説 AI Agent 場景中勢必會遇到的挑戰點以及解法的維度向大家做分享,然後你們再回頭來看這個架構圖,應該自然而然就可以理解了。
泛 Chat 類型 AI Agent 的挑戰點及解法
從目前看,無論是 Coding 場景,還是寫 PPT 啊,文本分析啊,文生圖/圖生圖啊等等,還是用 Chat 類型模型更加易用。包括互聯網其他客户的現存業務在融入 AI 能力時,基本也都是 Chat 模式,比如一些客户的智能點餐業務,一些 CRM/ERP 廠商的智能客服,智能問數,智能 BI 等等,都是 Chat 模式。
我錨定後續出現的其他 AI Agent 的場景,大概率也都是以泛 Chat 模式為主。整體的方案架構中,會因為 Chat 模式帶來額外的挑戰點,所以我將 Chat 模式和 AI Agent 作為一個整體系統架構來看挑戰點。
本文作為偏方案科普向文章,會盡可能用大白話表述,非常細節的內容就不在文章裏贅述了。有想要針對某個點做詳細討論的同學,可以聯繫我和我們的團隊(釘釘羣號:64970014484)。
會話親和性(Session 親和性)
這是 Chat 模式最具代表性的一個挑戰點。以 Gemini,Claude 為例,每次新建一個聊天/對話/ chat 就產生了一個新的會話:

會話發起後,你會和 LLM 進行交互,此時該會話底層就會有對應的計算資源實例在運行,提供運行環境(Runtime)。
在這個會話中,你和 LLM 的交互產生幾類數據:
- 你的文本輸入和 LLM 的文本輸出,就是各種文字。
- Coding 場景中,LLM 會產生各種代碼文件。
- Coding 場景中,為了可以運行程序,需要動態安裝各種依賴(比如 NodeJS 技術棧通過 npm 安裝的各種依賴,Python 技術棧通過 pip 安裝的各種依賴等),同樣也是各種文件。
- 計算資源實例,或者説 Runtime 的各種狀態,比如 OS 層面的環境變量值等。
上述第一類數據可以存在各類數據庫裏,但是後三類數據在計算資源實例還在存活時,只能在實例中。這時可能會有同學要問,掛載一個文件系統行不行呢?
- 存儲上述2,3類數據,是如果是一個非生產級,或者內部使用的系統,可以。
- 存儲上述2,3類數據,如果是 To C 場景的生產級系統,不建議。
因為在這個場景中,數據的隔離性是強訴求,掛載 NAS 並做不到絕對強隔離,除非一個實例掛載一個文件系統,這也不實現,因為在這個場景下計算資源實例會非常多。
上述第4類數據無論如何只能是在實例級別,因為和 OS,和容器文件系統相關。
綜上,在這種場景下,需要會話和計算資源實例通過某種方式綁定,每次打開這個會話,請求要路由到相同的實例,從而保證該會話生命週期裏所有數據、狀態的一致性。
阿里雲函數計算 FC 支持多種親和性方式
函數計算 FC 支持三種親和性:
- MCP SSE 親和。
- 基於 MCP SSE 協議規格,系統確保攜帶相同 SessionId 的客户端請求始終路由到同一個實例實現親和行為。
- HeaderField 親和。
- 基於 HTTP 請求頭中的指定字段值實現會話親和。
- Cookie 親和。
- 基於 HTTP Cookie 中的特性值實現會話親和。
在幫助客户落地時,大都使用了 HeaderFiled 親和方式,在每個會話裏發起請求時,Header 裏會帶着 UserID+會話 ID 作為 SessionID,實現了會話裏的每個請求都能路由到相同的實例中,從而保證了會話的所有數據、狀態的一致性。
除此以外,函數計算 FC 在函數級別還可以設置每個實例的 Session 併發度,即一個實例允許接幾個 Session 的請求,從而滿足更靈活的業務場景。

除了 AI Agent 場景,該能力在遊戲場景也有廣泛應用,比如 IGame 工作室的《第四紀元》遊戲底層遊戲服、平台服、WS 服全部使用函數計算 FC,實現遊戲底層完全 Serverless 化。
https://mp.weixin.qq.com/s/Iuh7uIBxFH2Jp8GFYKqVhw
會話級別的隔離性
在泛 Chat 類型的場景下,用户的不同會話之間,不同用户的會話之間都需要完全隔離,這是數據安全、用户隱私安全的的剛需訴求。
這裏包括了以下若干方面的隔離性:
- 運行會話的計算資源實例之間的網絡隔離。
- 運行會話的計算資源實例之間的存儲隔離。
- 運行會話的計算資源實例能否完全與外界隔離,既是否能允許訪問公網。
- 在 AI Agent Coding 場景是需要允許公網的,因為要動態安裝依賴。
- 但是很多依賴組件是從外網下載,網絡質量不可控,導致下載時間過長或者超時,所以有客户會窮舉某個技術棧的依賴組件,構建一個內網下載源,此時需要實例禁止訪問公網,做到更強的安全性。
- 運行會話的計算資源實例不能被公網訪問。
- 運行會話的計算資源實例只能被指定的內網服務訪問。
- 運行會話的計算資源實例和下游服務之間的互通管控。
- 有些場景下不允許實例訪問其他內網服務。
- 有些場景下需要允許實例訪問其他內網服務。
函數計算FC實例之間的隔離性
- 函數計算 FC 相同函數的每個實例之間,不同函數的實例之間都是網絡隔離的。
- 函數計算 FC 函數的每個實例有自己獨立的磁盤空間,實例之間的磁盤是隔離的。
- 函數計算 FC 函數可以設置是否可以允許訪問公網,可以根據具體業務場景開啓或關閉。
- 函數計算 FC 函數可以禁用被公網訪問。
- 函數計算 FC 函數可以設置只允許被指定的 VPC 內的資源訪問。
- 函數計算 FC 函數可以配置 VPC,可以和指定 VPC 打通網絡,實現靈活管控和內網其他服務之間的網絡。

會話存儲機制
從存儲機制和介質類型方面來説,無非就是兩種方式:
- 雲盤+OSS
- 掛載文件系統
以上兩類方式在這個場景中都會用到,會在合適的場景下使用合適的方案。這個場景的存儲機制包括4個核心問題:
- 存儲成本問題。
- 數據完整性問題。
- 動態掛載存儲問題。
- 限制每個路徑下上傳文件的總量。
存儲成本問題
這個問題主要源自 AI Agent Code Interptreter Sandbox 場景的不確定性特性之一,環境依賴的不確定性。既每個用户發起的 Coding 任務,都需要各種不同的依賴包,所以需要在執行任務的過程中動態安裝依賴。
所以,以 NodeJS 為例,會在構建項目的過程中在node_modules文件裏生成大量的各種組件、依賴的文件,並且不同項目的組件、依賴重複度較高。如果每個項目的node_modules文件都保存下來,那麼存儲成本壓力會非常大。
大部分客户在解決這個問題時使用了函數計算FC函數磁盤+OSS 的方式。
- 項目構建過程中生成的所有文件,都先保存在函數磁盤中。
- 在函數
PreStop生命週期方法中(函數實例銷燬時調用),將除了node_modules文件的所有其他文件打包上傳到 OSS。
通過這種方式用户只需要持久化保存項目的主幹工程即可,不需要將依賴都保存下來,並且在實現過程中,也不需要特意去考慮刪除node_modules文件的工作,因為函數實例只要釋放了,實例磁盤裏的數據也就都刪除了,所以用户只需要實現簡單的選擇文件打包上傳 OSS 的邏輯即可。
但這種不存依賴的方案再恢復會話時有一定時延的弊端,這問題在下文對應章節會解釋如何優化。
數據完整性問題
數據完整性問題指的是當計算資源實例出現非預期的 Crash 時,是否能最大程度的保存下來當時的各種數據。在這個前提下無疑掛載文件系統的方式是最有效的,因為整個 IO 操作都是通過文件路徑實時寫入文件系統的,所以在實例 Crash 的一瞬間,可能只有極少數的文件會丟失。
而云盤+OSS 的方式,因為上傳 OSS 並不是實時的,所以在實例 Crash 的一瞬間,可能會丟失相對更多的文件。但是經過我們反覆的技術調研、測試以及和客户的推演討論,最終認為在 Sandbox 場景下,還是雲盤+OSS 的方式是最適合的。
文件系統不適合 Sandbox 場景的核心原因主要有2個:
- 上述存儲成本的問題。
- 如果所有文件都存在文件系統,又想只選擇部分持久化,那麼勢必要實現一個非常複雜的文件刪除邏輯,一旦文件刪除邏輯設計有缺陷,那麼可能會造成更大的問題。
- 存儲安全或者説隔離性的問題。
- 雖然系統在運行代碼時已經禁用了執行
mount權限,但在使用 WebShell 登錄計算資源實例(僅限於神龍)時,給到用户的是root權限, 可以成功執行mount指令,掛載到文件系統的任意目錄。 - 由於 NFS 協議需要在可信網絡環境中(配置 VPC)允許文件訪問,所以只要計算資源實例在可信 VPC 下,就可以通過掛載點來訪問指定路徑的文件,無需任何身份授權。
- 所以,Sandbox 實例若對外暴露代碼片段執行能力,允許 C 端執行自定義代碼,會被攻擊者構造惡意指令來訪問文件系統中的文件,不需要任何身份權限校驗。
- 雖然系統在運行代碼時已經禁用了執行
所以再次印證了為什麼 Code Interptreter Sandbox 推薦使用函數磁盤+ OSS 的方案。
動態掛載存儲問題
這個問題源自 AI Agent Code Interptreter Sandbox 場景的另一個不確定性的特性。那就是掛載存儲的路徑是動態的,是不確定的。只有請求到了實例裏後,才知道要掛載的路徑是什麼。
因為通常路徑都是用户ID/會話ID/[任務ID],如果是新創建的會話,只有該會話的第一個請求進了實例,才知道完整的路徑是什麼。所以這就需要計算資源實例可以動態掛載存儲介質,而不是先掛載路徑後啓動實例。並且每個實例掛載的路徑都是不同的。
函數計算 FC 的在持久化方面,原本就支持在函數維度設置 NAS 或 OSS 的掛載路徑,在這種情況下,該函數的所有實例都會共享該掛載路徑。而現在,我們又支持了可以在實例維度動態的掛載 NAS 和 OSS 路徑的能力,實現了同一個函數的不同實例,可以掛載同一個文件系統/ OSS Bucket 的不同路徑。

限制路徑級別的文件總量 Quota 文件
在 AI Agent Coding 或者 Vibe Coding 場景下 ,用户可以隨便寫個類似雲盤的項目,或者論壇的項目。所以可以隨意上傳文件,如果被非法利用,可能會引起被白嫖存儲的問題。所以需要對每個項目可上傳文件總量大小做限制。
目前文件系統雖然支持路徑級別設置 Quota,但是 AI Agent Coding 這個場景下路徑數量會非常多,可預見性的會有幾萬,十幾萬個甚至更多,所以需要另尋解決方案。
目前的方案有 2 個:
- 基於函數計算 FC 特性實現的。(短期臨時方案)
- PolarFS 支持給幾乎沒有上限的路徑設置 Quota。(長期成熟方案)
目前函數計算 FC 正在和 PolarFS 做產品間集成,集成後這塊會直接換成 PolarFS 方案。我在這裏和大家分享一下當前是如何基於函數計算 FC 的特性做的臨時實現。
上文中我有提到,函數計算 FC 函數的每個實例都有自己的磁盤,最小是 512MB,也有更大的額度。當超過磁盤大小後會報錯。所以目前寫好的項目運行在函數計算 FC 實例中,寫文件的操作是先寫進函數實例的磁盤中,寫入成功後,再 CP 到文件系統裏。當函數實例磁盤寫滿報錯後,就不會再對文件系統做交互。相當於用函數實例的磁盤做了一層中轉,但是依賴函數磁盤 Quota 的強限制,變相解決了路徑配額的問題。
會話恢復機制
會話恢復的邏輯本質上是比較簡單的,但是這部分涉及到效率問題也涉及到記憶問題,所以結合函數計算 FC 的特性和大家作以分享和探討。
上文中提到了,會話底下的 Code Interpreter Sandbox 這部分使用的是函數實例磁盤+OSS 的存儲方式,所以當會話需要恢復時,需要有2部分的數據需要恢復:
- LLM 輸出的一大堆文本,也就是該會話裏的上下文。
- 代碼工程文件和依賴組件。
LLM輸出的這一大堆文本(上下文),可以選擇使用一些記憶組件,也可以選擇關係性數據庫做存儲。
代碼工程文件自然是從 OSS 中下載解壓做恢復,但是前文中説了node_modules並沒有存儲,所以在會話恢復過程中,有一部分耗時的地方就是要重新下載安裝依賴。這也是我説的效率問題。
這部分如果想要從根本解決效率問題,就得把所有的依賴文件都存下來,但是面臨巨大的存儲成本壓力,多金土豪的客户自然可以用這種方式。但我相信絕多大數客户還是會在效率和成本之間尋找一個平衡的解決方案。
我們目前的做法限制用户可以在1小時內快速恢復會話,超過1小時後就會慢一些:
- 函數計算 FC 函數實例的存活時長(Idle Time)可由用户自行設置。目前實例存活時長為1小時,所以在這1小時內,依賴文件都在函數的臨時磁盤裏,從而達到高效恢復會話的效果。當在1小時內沒有任何請求進來,那麼實例才會被釋放,所以當用户超過1個小時後再打開會話,就會重新拉起實例,從 OSS 下載代碼文件,重新安裝依賴,整體會話恢復時間就會較長。
- 默認情況下,當函數實例在5分鐘內沒有請求,實例就會被銷燬。
- 因為客户可以自行控制函數實例的 Idle Time,所以可以對客户做付費分類,比如 SVIP 用户對應的函數實例 Idle Time 為24小時,VIP 用户對應的函數實例 Idle Time 為10小時,普通用户對應的函數實例 Idle Time 為1小時。
會話網絡管理
會話網絡管理本質上就是會話底層計算資源實例的網絡管理,最核心的其實就是 IP 分配的問題。
- 有限的 IP 與 PodCIDR 模型:K8s 在 IP 管理分配方面有集羣 CIDR,節點 PodCIDR 分配,Pod IP 分配三個維度,這種設計確保了不同節點上的 Pod IP 地址不會衝突,並且簡化了路由。然而,它也引入了一個關鍵的制約因素:Pod 密度,即每個節點上運行的 Pod 數量。當一個節點上的 Pod 密度很高時,即便整個集羣的 CIDR 地址空間還很充裕,該節點自身的 PodCIDR 也可能被迅速耗盡 。
- 企業安全組最大支持關聯的 IP 地址數量是65535,在這個場景中實例數是很有可能超過65535的。
函數計算 FC 作為 Serverless 計算產品,自己有足夠大的資源池,函數實例不會使用用户的 IP,並且底層容器的調度和 K8s 也是完全不一樣的,而且在安全組方面,相同的 uid+role+vsw+vpc+sg 是複用一個 IP 的,和函數數量沒關係,和實例數量也沒關係,所以無需客户做任何事情,可以完美解決上述的問題。
項目分享/會話分享機制(Sandbox轉傳統Server)
在 Vibe Coding 環境中,當一個完全不懂編程的人,只靠一些想法,通過一些平台就可以完完全全實現出來,我覺得除了自己很興奮外,應該會立馬想把自己實現的產物分享給自己身邊的朋友,無論是以什麼目的做的分享,我相信這份成就感是無與倫比的,這也正是 Vibe Coding 性感的地方之一。
現在很多 AI Agent 產品主打的就是生成完整的項目,可以直接運行的項目,分享出去後可直接使用的項目,所以都會有類似發佈分享的功能。大家可以想象一下,當一個由 LLM 寫出來的項目,被髮布了以後,其實它和什麼 AI Agent,Sandbox 就沒有任何關係了,運行這個項目的底層計算資源其實就是一個傳統的 Server。
但這個傳統 Server 面臨着不普通的挑戰點:
- 在這個場景下,由 LLM 生成的項目會非常多,底層計算資源池準備多少合適?
- 分享出去的項目突然成爆款,QPS 巨大,底層計算資源能否快速擴容,接住這潑天富貴?
- 那麼多項目,大概率99.5%的項目沒什麼人訪問,但有可能有0.5%的項目稱為了爆款,在這種情況下,底層計算資源準備多了浪費,準備少了接不住這種出爆款的現象,該怎麼辦?
- 每個項目使用的資源要隔離,爆款項目不影響整個系統(類似熱點接口將整個系統拖垮的邏輯)。
- 分享出去的項目該用什麼樣的存儲機制?
我用大白話將上述挑戰點翻譯成客户的需求:分享出去的項目對應的資源要相互隔離,互相不影響,項目沒請求的時候不要給我拉起資源,有請求時再拉起資源,而且資源可以根據 QPS 量快速橫向擴容,而且擴出來的實例可以共享存儲,保持項目的狀態一致。
從最根本上講,就是成本的問題。這是標準的 Serverless 形態計算資源解決的問題,所以函數計算可以 FC 完美的解決這個變態的場景。
- 每一個項目對應函數計算 FC 中的一個函數,函數設置多實例多併發,函數規格1C1G,函數掛載文件系統(/用户 ID/項目 ID)。
- 絕大多數項目都是沒有請求的,或者請求量非常小的。對應到函數計算 FC,那就是大多數函數壓根不會拉起實例,只有少部分函數只需要拉起一個1C1G 的實例,就可以支撐少量的請求。
- 爆款項目對應的函數在流量高峯期可以快速拉起多個實例,低峯期又可以釋放多餘的實例,始終保持實例數和 QPS 在比較貼合的情況。
- 爆款項目,或者請求量比較大的項目,對應的函數會拉起多個實例,每個實例共享掛載的文件系統路徑,所以每個對項目的操作產生的數據變更、狀態變更都可以保持一致。
爆款項目這個場景很類似我們以前做的一些RTA場景(某客户RTA場景高峯期70w QPS,低峯期30w QPS,QPS 方差達到 40w),或者像高德這種 QPS 有明顯波峯波谷且方差比較大的場景。
不同會話配置不同的資源規格(Sandbox實例 VPA 機制)
這個需求本質是因為 AI Agent 場景下的 Sandbox 執行什麼樣的任務是不可控的,比如有的任務就是簡單的推理、查詢等,對 CPU 和內存的消耗不高。但有些任務是處理文件、處理音視頻,這一類的任務就是 CPU 密集型的場景,要求更高的 CPU 和內存規格。
如果是在同一個函數下的話,就需要函數的實例可以縱向擴容,函數計算 FC 的基礎架構底層是支持的,但是沒有對應的計費邏輯,或者説這樣對客户來説計費邏輯會很複雜,所以目前函數計算 FC 從對外透出的產品能力上並不支持 VPA。
目前給推薦客户的方案如下:

- 引入一個小參數 LLM 做意圖識別,類似聯網搜索裏的意圖識別,將任務類型做分類。
- 不同任務類型對應不同的函數,每個函數可以設置不同的資源規格。
- 使用函數計算 FC 的 Destination 功能做兜底。
發佈分享項目的訪問管控機制
項目做分享這個功能需要涉及到以下幾個核心的點:
- 自定義域名的管理,如何和 Sandbox 實例做打通和映射。
- 即使 Sandbox 實例有能力快速橫向擴容,但依然需要對訪問鏈路做限流、降級、熔斷等管控策略,防止一些非法行為。
- 如果引入項目 A/B 測試或灰度能力,需要入口做管控策略。
- 需要支持多種認證鑑權機制。
基於以上這些核心需求,引入了雲原生 API 網關做統一的南北向流量入口管控。
- 雲原生 API 網關側可以做域名、路由的統一管理。上圖中看到的分享地址(URL),就是管理在網關側的,並且背後有對應的路由。
- 雲原生 API 網關和函數計算 FC 做了深度產品集成,在創建路由時可以方便的選到對應的函數。
- 雲原生 API 網關支持豐富的管控策略和自定義插件機制,所以限流、降級、熔斷、各種鑑權認證、 A/B 測試、灰度測試等都可以快速的通過配置來實現。
通過 Sandbox 與 Serverless 的深度融合,AI Agent 不再是“黑盒”實驗,而是可被企業精準掌控的生產力工具。這種架構不僅適配當前 AI Agent 的動態交互特性,更為未來多模態 Agent、跨系統協作等複雜場景提供了可複用的技術底座。
若您的企業正面臨 AI Agent 規模化落地的挑戰,不妨從 Sandbox 架構入手,結合函數計算 FC 的Serverless能力,快速驗證並構建安全、高效、可擴展的AI應用系統。
更多內容關注 Serverless 微信公眾號(ID:serverlessdevs),彙集 Serverless 技術最全內容,定期舉辦 Serverless 活動、直播,用户最佳實踐。



