

- 前言
- Chapter 3: Application Processing Unit 應用處理單元
- 3.1 Introduction 介紹
- 3.1.1Cortex-A53 MPCore Processor Features
- 3.2 Arm v8 Architecture Arm v8架構
- 3.3 APU Functional Units APU功能單元
- 3.3.1 Instruction Fetch Unit(指令取指單元)
- 3.3.2 Data Processing Unit(數據處理單元)
- 3.3.3 Advanced SIMD and Floating-point Extension(高級 SIMD 與浮點擴展)
- 3.3.4 Cryptography Extension(加密擴展)
- 3.3.5 Translation Lookaside Buffer (TLB,轉譯後備緩衝器)
- 3.3.6 Data-side Memory System (數據側內存系統)
- 3.3.6.1 Store Buffer 存儲緩衝器
- 3.3.6.2 Bus Interface Unit and SCU Interface 總線接口單元和SCU接口
- 3.3.6.3 Snoop Control Unit 窺探控制單元
- 3.3.7 L2 Memory Subsystem(L2 緩存子系統)
- 3.3.8 Cache Protection(緩存保護)
- 3.3.9 Debug and Trace(調試與跟蹤)
- 3.3.10 Generic Interrupt Controller(GIC,通用中斷控制器)
- 3.3.11 Timers(定時器)
- 3.4 APU Memory Management Unit APU內存管理單元
- 3.5 System Virtualization 系統虛擬化
- 3.5.1 APU Virtualization
- 3.5.2 Interrupt Virtualization
- 3.5.3 Timer Virtualization
- 3.6 System Coherency 系統一致性
- 3.6.1 I/O Coherency
- 3.7 ACE Interface ACE接口
- 3.8 ACP Interface ACP接口
- 3.9 APU Power Management 電源管理策略
- 3.9.1 Power Islands
- 3.9.2 Power Modes
- 3.9.2.1 Normal State
- 3.9.2.2 Standby State
- 3.9.2.2.1 MPCore Wait for Interrupt
- 3.9.2.2.2 MPCore Wait for Event
- 3.9.2.2.3 L2 Wait for Interrupt
- 3.9.2.3 Individual MPCore Shutdown Mode
- 3.9.2.4 Cluster Shutdown Mode with System Driven L2 Flush、
- 3.10 Clocks and Resets 時鐘與復位
- 3.11 Performance Monitors 性能監視器
- 3.12 System Registers 系統寄存器
- 3.13 System Memory Virtualization Using SMMU Address Translation 使用SMMU地址轉譯進行系統內存虛擬化
- 3.13.1 Translation Buffer Unit
- 3.13.2 Translation Control Unit
- 3.13.3 SMMU Architecture
- 3.13.3.1 Stage 1 SMMU Translation
- 3.13.3.2 Stage 2 SMMU Translation
- 3.1 Introduction 介紹
- 本章總結
前言
上一章講了ug1085MPSOC技術參考手冊的第二章,講了有關MPSOC信號和引腳功能的相關內容,這次我們來講第三章,MPSOC的核心器件之一的APU。事先聲明,由於我對ARM架構完全不熟悉,所以我用了AI工具來理解這些內容,後面我可能也會直接貼AI的回答。
Chapter 3: Application Processing Unit 應用處理單元
3.1 Introduction 介紹
Application Processing Unity也就是我們常説的APU,實際是就是MPSOC中的四核/雙核A53處理器,在這一小節中介紹了A53的一些特性,比如其基於Arm v8架構,無縫支持32和64位代碼,以及其流水線特性等,介紹性內容不多説了。
3.1.1Cortex-A53 MPCore Processor Features
這一小節介紹了Cortex-A53 MPCore處理器的一些特性,這些特性後面都會介紹到,我這裏也把這些特性列出來,方便先做個簡介。A53有下面的特性:
-
AArch32 and AArch64 execution states.
-
All exception levels (EL0, EL1, EL2, and EL3) in each execution state.(支持4中特權(異常)等級)
-
Arm v8-A architecture instruction set including advanced SIMD, VFPv4 floating-point extensions, and cryptography extensions. (浮點數和加解密擴展)
-
Separate 32 KB L1 caches for instruction and data.(每個核心獨立L1緩存)
-
Two-stage (hypervisor and guest stages) memory management unit (MMU).(兩個階段的地址管理)
-
CPU includes an in-order 8-stage pipeline with symmetric dual-issue of most instructions.
-
1 MB L2 cache in CCI coherency domain.(具有緩存一致性的L2)
-
Accelerator coherency port (ACP).(這個接口會直接接到SCU上,實現對L2的直接訪問)
-
128-bit AXI coherency extension (ACE) master interface to CCI.(A53連接到CCI的接口)
-
Arm v8 debug architecture.
-
Configurable endianess. (可配置的大小端)
-
Supports hardware virtualization that enables multiple software environments and their applications to simultaneously access the system capabilities.
-
Hardware-accelerated cryptography—3-10x better software encryption performance.(硬件加解密器)
-
Large physical address reach enables the processor to access beyond 4 GB of physical memory.
-
TrustZone technology ensures reliable implementation of security applications.
3.2 Arm v8 Architecture Arm v8架構
這小節主要介紹了Arm v8架構的構成和功能,以及其從EL0-EL3的異常等級,這裏簡要提一嘴異常等級的概念,不過我也不是很熟悉所有可能有錯誤,所謂異常等級或者特權等級,就是ARM中軟件運行的等級,在這一等級中EL0中運行的軟件處於最低等級,不能夠直接操作內存和各種外設,必須將請求提供給EL1,而隨着等級提高,軟件所能操作的硬件權限就更高,EL1主要是操作系統的內核,到EL2就能進行虛擬化的相關設置,到EL3也就是安全狀態,就能夠操作有關安全設置的最高權限了,後面將虛擬化還會説到相關內容,這裏就不講了,貼一張ARM v8架構圖:
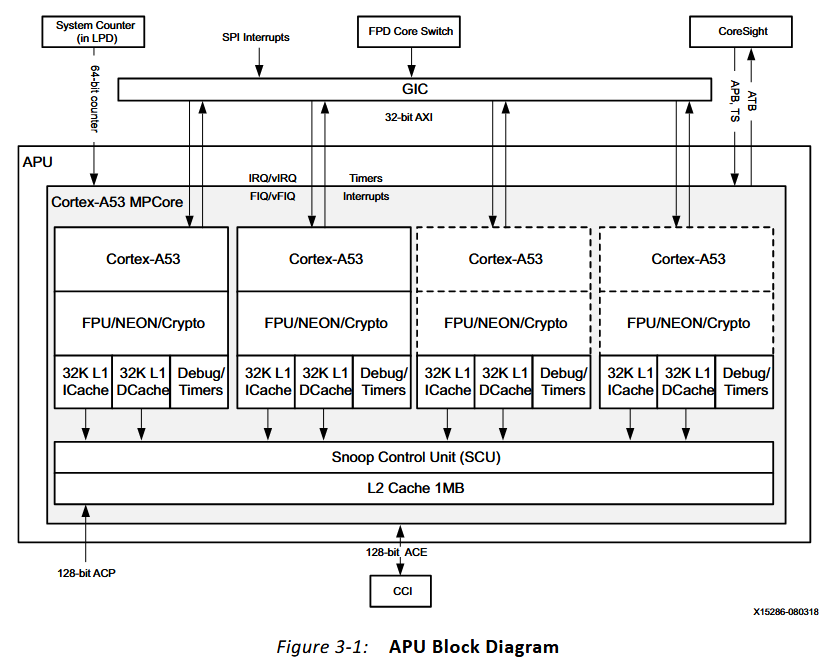
這張結構圖其實也值得説到,例如每個核心的私有部件以及貢獻的SCU,L2,以及與CCI通信的ACE總線,每個核心特有的中斷線等等。
3.3 APU Functional Units APU功能單元
這節講了APU中的各種功能單元,很多地方我都沒搞懂是啥,所以就問AI了,這裏我也貼下AI的回答,感覺比我自己總結的好,我這裏額外問了AI這些單元需不需要顯式的代碼調用,這裏也一併複製過來了。
3.3.1 Instruction Fetch Unit(指令取指單元)

我還要額外提一句DPU還負責對APU中寄存器中數據的操作。
3.3.2 Data Processing Unit(數據處理單元)

3.3.3 Advanced SIMD and Floating-point Extension(高級 SIMD 與浮點擴展)

3.3.4 Cryptography Extension(加密擴展)

3.3.5 Translation Lookaside Buffer (TLB,轉譯後備緩衝器)

3.3.6 Data-side Memory System (數據側內存系統)

數據側內存系統實際包含有好幾個子模塊,但是我理解不深,就只把這些模塊介紹的原文翻譯一下了。
數據緩存單元(DCU)由以下子塊組成。
- (L1)數據高速緩存控制器為associated embedded tag, data, and dirty RAMs生成控制信號,並在請求訪問存儲器資源的各個源之間進行仲裁。數據緩存是4路集關聯的,並使用物理索引物理標記(PIPT)方案進行查找,從而實現系統中的明確地址管理。
- 與DPU和主TLB接口的加載/存儲流水線。
- 系統控制器通過與IFU(指令取指單元)接口對指令進行高速緩存,又協同TLB(轉譯後備緩衝器)對數據進行高速緩存操作。
- 從窺探控制單元(SCU)接收一致性請求的接口。
3.3.6.1 Store Buffer 存儲緩衝器
當存儲操作離開加載/存儲流水線並由DPU提交時,存儲緩衝器(STB)將保存這些操作。STB可以請求訪問DCU中的緩存RAM、請求BIU啓動行填充或請求BIU在外部寫通道上寫出數據。外部數據寫入通過SCU進行。STB可以合併以下內容。
- 如果多個事務位於相同的128位對齊地址,則將它們存儲為單個事務。
- 多次寫入AXI或CHI寫突發。STB還用於在將維護操作廣播到Cortex-A53 MPCore中央處理器集羣中的其他核心之前對維護操作進行排隊。
Cortex-A53 MPCore L1內存系統由單獨的L1指令和數據緩存組成。它還由兩個級別的STB組成。
- 指令端和數據端都有單獨的微TLBs。
- 統一的主TSB處理微TLBs的缺失。
3.3.6.2 Bus Interface Unit and SCU Interface 總線接口單元和SCU接口
接口單元(BIU)包含SCU接口和緩衝區,用於將接口與緩存和STB分離。BIU接口和SCU始終以處理器頻率運行。
3.3.6.3 Snoop Control Unit 窺探控制單元
集成窺探控制單元(SCU)連接APU MPCore和MPSoCs中使用的加速器一致性端口(ACP)。SCU還具有L1數據緩存標籤的複製副本,用於一致性支持。SCU與處理器同步且頻率相同。
SCU包含的緩衝區可以處理處理器之間的髒緩存的緩存到緩存傳輸(髒緩存就是被一個處理器所使用的未同步緩存),而無需向外部存儲器系統讀取或寫入任何數據。緩存行遷移使髒緩存行能夠在處理器之間移動,並且不需要將傳輸的緩存行數據寫回外部存儲器系統(也就是不用經過DDR就能實現處理器間的緩存同步)。Cortex-A53 MPCore處理器使用MOESI協議來維護多個核心之間的數據一致性。
這部分我盡力校對了一下,如果發現有翻譯的很抽象的就是我也沒看懂的了。
3.3.7 L2 Memory Subsystem(L2 緩存子系統)

這裏有額外的説明,核心對L2的訪問是會被SCU單元仲裁的,而且當L2和SCU同時命中了核心的內存請求,核心會偏向於使用SCU來訪問這些內存數據。
3.3.8 Cache Protection(緩存保護)

3.3.9 Debug and Trace(調試與跟蹤)

3.3.10 Generic Interrupt Controller(GIC,通用中斷控制器)

3.3.11 Timers(定時器)

3.4 APU Memory Management Unit APU內存管理單元
APU是A53中比較重要的一個單元,這個單元的主要作用是實現從虛擬地址到物理地址的轉譯,我們後面會了解到為了實現應用程序到虛擬機以及虛擬機到物理地址的雙重地址轉譯,也就是VA(虛擬地址)->IPA(中間物理地址),IPA->PA(物理地址)的兩次轉譯,需要由OS和虛擬機向MMU提供頁表文件才能實現。而這種地址轉譯是為了實現兩重的地址虛擬化,也就是應用程序和虛擬機的地址虛擬化,從而將他們從物理地址中分隔開。具體的虛擬化內容我們後面再講。
3.5 System Virtualization 系統虛擬化
虛擬化是現代操作系統的一個重要功能,我淺顯的理解就是虛擬化能夠實現對內存空間的分割,防止不同應用程序或虛擬機去操作其他應用程序或虛擬機的地址,此外還能實現對內核以及外設的保護,同時實現多用户多操作系統的功能。
為了實現系統的虛擬化,A53核中提供了四種虛擬化組件:
-
APU虛擬化
-
中斷虛擬化
-
定時器虛擬化
-
使用SMMU地址轉譯的系統內存虛擬化
下面我們一個一個講。
3.5.1 APU Virtualization
APU虛擬化就是將APU中的核心共享到多個用户的OS中使用,這些OS的運行和對CPU的調度由虛擬機進行管理,所以虛擬機功能的核心就是在多個虛擬機上運行多個用户的操作系統,我們之前提到過異常等級或者特權等級的概念,有很大程度就是用於虛擬機系統的,在這一框架下,系統的最高級權限以及安全應用運行在EL3的安全世界中,而EL2運行虛擬機的程序,EL1運行用户OS,EL0運行OS上的應用程序,後三者都是運行於非安全世界,架構圖如下所示:
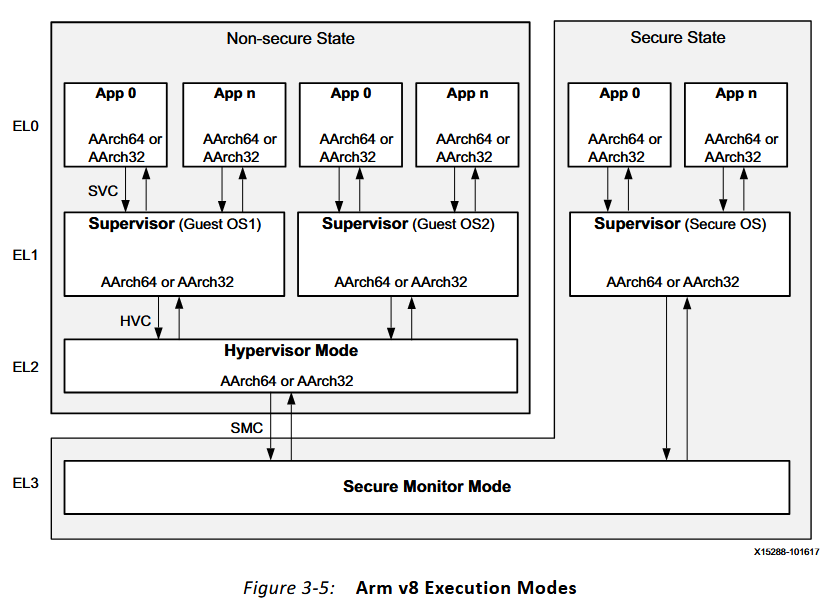
在虛擬機的框架下,地址轉譯的方式也會不同,當整個系統只運行一套OS,不使用虛擬機時,對內存的虛擬化只需要從有應用的虛擬化地址VA直接由OS轉為物理地址PA就可以被髮送給硬件進行執行了,但是在虛擬機系統中,各個虛擬機也需要進行內存空間的虛擬化以實現對不同虛擬機可使用內存空間的限定,因此地址虛擬化會多出一層IPA,也就是會分為兩個階段地址轉譯,具體示意圖如下:
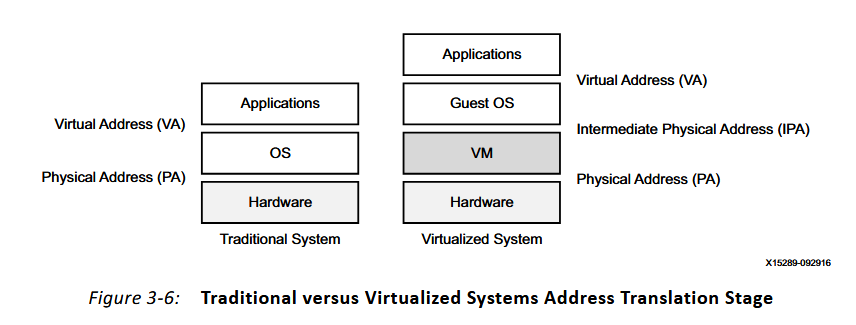
這個虛擬化過程還是比較複雜的,在講MMU的章節中描述了這種二階段虛擬化的過程,但是我也沒看懂,這裏就不展開説了,主要有這麼個概念。
3.5.2 Interrupt Virtualization
中斷虛擬化主要是有GIC中斷控制器來完成的,理論上來説每個APU的核心以及外設都有着確定的中斷線,當一個虛擬機想要使用某個外設的中斷時,就需要GIC將這些外設的中斷送給對應的虛擬機,不過我沒用過虛擬機所以這部分內容可能不太準確
3.5.3 Timer Virtualization
由於每個APU的核心中只有一個定時器,當運行在該核心上的多個虛擬機都需要使用定時器時就需要進行定時器虛擬化,具體的在第14章定時器章節有更為詳細的描述。
3.6 System Coherency 系統一致性
一致性也是比較關鍵的內容,系統的一致性是指CPU多個核心之間或者CPU與外部設備需要共同處理同一批數據時出現的一致性問題,因為CPU的核心會將要處理的數據緩存到自己的私有緩存中從而加速處理,但當其他核心或者設備也需要處理這批數據時,就會出現當前數據未更新導致處理的數據不一致的問題。
通常有兩種處理該不一致的方法,一種是軟件上的,例如CPU核心要使用PL端邏輯加速處理DDR上的同一批數據,那麼在PS端在發送命令讓PL進行處理前,要首先刷新自己的緩存,強制將緩存寫回DDR中,同樣當PL端處理完這段數據前,要強制CPU緩存不讀取這段數據。
另一種方法則是硬件上的,這裏先不涉及CPU多核心間使用的緩存一致性的硬件,而是像PL端直接使用ACP總線由APU的SCU單元直接窺探核心的L1數據。
3.6.1 I/O Coherency
IO一致性就是使用具有一致性特性的數據接口,主要就是Accelerator coherency port (ACP)和Cache-coherent interconnect (CCI) ACE-Lite接口兩種,ACP剛剛介紹過了,ACE接口我的理解是其不像ACP接口一樣直接連接到APU,而是先連接到CCI上進行一致性的設置,具體的下一節講。
3.7 ACE Interface ACE接口
ACE就是一致性擴展的AXI接口,其本質上還是AXI協議,但是他從硬件層面上確保了緩存一致性以及傳輸的順序性,具體的實現內容這部分有一點解釋:
ACE一致性協議通過強制每當存儲到該位置時僅存在一個副本,確保所有主機在任何給定地址位置觀察到正確的數據值。每次存儲到某個位置後,其他主機可以為其自己的本地緩存獲取數據的新副本,從而允許存在多個副本
我感覺他的硬件緩存一致可能還是由CCI單元來做的,其可能有一些複雜的機制,我也不太懂。
3.8 ACP Interface ACP接口
剛剛講了不少了,具體的到等我看到第35章再説。
3.9 APU Power Management 電源管理策略
這部分主要講APU的電源域和電源管理策略,我們下面細説。
3.9.1 Power Islands
APU主要有三個電源域:

可以看到,APU把電源域分為了SCU和L2控制器,L2,CPU核心三部分,這樣的分法其實主要和電源管理策略有關。
3.9.2 Power Modes
電源管理策略主要是為了低功耗應用準備的,主要有5類:
- 常規模式
- 待機模式
- MPCore獨立關閉模式
- Cluster Shutdown Mode with System Driven L2 Flush(我沒翻譯主要是不知道要翻譯成啥)
3.9.2.1 Normal State
常規模式就是A53所有功能都啓用的模式。
3.9.2.2 Standby State
待機模式有好幾種不同的模式
3.9.2.2.1 MPCore Wait for Interrupt
這一小節描述了v8架構處理器的Wait for Interrupt (WFI)特性,這個模式下整個MPCore都會處於低功耗模式並等待中斷喚醒。在處理器進入WFI模式前,需要使用WFI指令並等待處理器進行一些操作,例如寄存器和指令的退回。
還有一點,在這個模式下。似乎L2緩存系統還會響應一些特殊的指令,例如要求L2加載指令的操作,進行數據緩存和TLB維護的操作,以及存放專有指令的操作。
3.9.2.2.2 MPCore Wait for Event
Wait for Event (WFE)等待事件特性我感覺有點類似於WFI,區別在於一個等待中斷一個等待事件寄存器置位,但是WFE有着更多的特點,我覺得一個比較重要的是這個模式下有些操作可以讓處理器暫時的使能而不退出其待機狀態,原文如下:
當MPCore處於WFE低功耗狀態時,當檢測到以下任何事件時,MPCore中的時鐘將暫時啓用(而不會導致MPCore退出WFE低功耗狀態)。
- 必須由MPCore L1數據緩存服務的L2窺探請求
- 必須由MPCore L1指令高速緩存、數據高速緩存或TLB進行服務的高速緩存或TLB維護操作
- APB訪問駐留在MPCore電源域中的調試或跟蹤寄存器
3.9.2.2.3 L2 Wait for Interrupt
這個狀態比較簡單,就是所有核心以及L2緩存系統都進入WFI模式。
3.9.2.3 Individual MPCore Shutdown Mode
這個模式我對比了一下WFI和WFE模式,總結下來就是該模式會直接將MPCore關閉,或者説是關閉之前APU電源域提到的PDCPU電源域,但不連同L2緩存系統,這個模式不像WFI和WFE還存在待機功耗,好像就是直接關了。這裏有很長的一段操作來進行MPCore的斷電和重新上電,具體不講了。
3.9.2.4 Cluster Shutdown Mode with System Driven L2 Flush、
這個名字很奇怪的模式就是直接把APU的三個電源域PDCORTEXA53, PDL2, and PDCPU全部關了,這節講了下關閉的具體操作,也不再講了。這裏額外提到APU的電源管理和動態功耗管理都是是由運行在PMU中的電源管理軟件控制的。
3.10 Clocks and Resets 時鐘與復位
這節稍微講了下APU的復位操作,APU的每個核心都可以進行單獨的復位操作這些復位操作可以由FPD域的看門狗或者從軟件上寫寄存器來實現,具體的有兩個寄存器可以實現復位操作,一個是PMU中的PMU_GLOBAL.REQ_SWRST_INT_EN寄存器的[APUx]位,另一個是REQ_SWRST_TRIG寄存器的[APU{0:3}]位(我沒看到這個寄存是哪的)。
3.11 Performance Monitors 性能監視器
這裏懶得寫了就貼下原文:
Cortex-A53 MPCore處理器包括實施Arm PMUv 3架構的性能監視器。性能監視器可以收集有關處理器及其內存系統在運行時操作的各種統計數據。它們提供有關處理器行為的有用信息,供調試或分析代碼時使用。性能監視器提供六個計數器。每個計數器都可以對處理器中可用的任何事件進行計數。
3.12 System Registers 系統寄存器
這部分列出來APU的系統控制寄存器,描述也寫在表裏了:
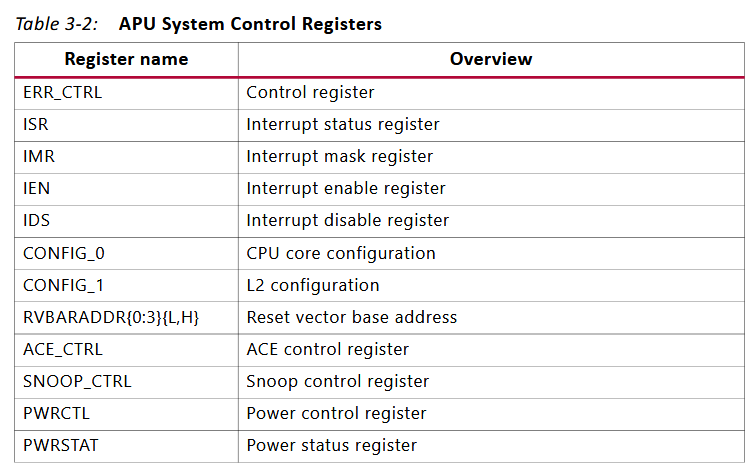
他這裏沒詳細介紹剛剛寄存器的作用,在別的章節可能會有關聯
3.13 System Memory Virtualization Using SMMU Address Translation 使用SMMU地址轉譯進行系統內存虛擬化
這個章節的內容也很多,我這裏先簡要介紹下這個很長的標題是什麼意思。我們之前説過,虛擬機系統需要進行兩個階段的內存虛擬化,一個是由應用程序的VA轉為操作系統的IPA,另一個是有操作系統的IPA轉為物理地址的PA,但是要注意,這些內存轉換在中APU是由APU的MMU單元實現的,MMU單元受到OS和虛擬機的頁表控制實現這兩階段的地址轉譯,但是對於一個獨立的外設呢,例如對於一個在PL端實現的數據處理邏輯,為了保障安全性,這個外設也需要被設定內存範圍並且進行內存虛擬化,但是這個外設並沒有APU中的MMU單元,為了給這些沒有MMU的單元實現虛擬地址化,就需要使用這裏所説的SMMU(System MMU),所以本質來説,SMMU也是MMU,我這裏把原文翻譯一下來解釋一階段和二階段的轉譯:
虛擬化多客户操作系統的第一階段硬件地址轉換。虛擬地址(VA)到中間物理地址(IPA)。
- 管理程序軟件對第一級地址轉換單元編程以虛擬化除處理器之外的總線主控器的地址,例如,DMA單元和PL主機。
- 將每個公交主機與其操作系統的中間虛擬內存空間關聯。
多應用程序操作系統的第二階段硬件地址轉換。中間物理地址(IPA)到物理地址(PA)。
- Guest OS軟件對第二階段翻譯單元進行編程,以管理每個應用程序的內存映射資源的編址。
- 將中間虛擬內存地址與系統的物理地址空間關聯。
不過我這裏懷疑原文可能有問題,這裏的兩個階段的轉譯其控制和MMU那部分內容中的兩階段轉譯其控制源不同,這裏寫的是一階段由虛擬機,二階段由OS控制,但是實際上應該是寫反了,一階段由VA到IPA才應該有OS控制,二階段的IPA到PA才由虛擬機控制,這裏注意。
3.13.1 Translation Buffer Unit
SMMU有兩個部件,一個就是這個Translation Buffer Unit轉譯緩衝單元,作用就是緩存了地址轉譯表,這個表就標誌了什麼地址應該被準換到什麼地址去,TBU是由translation control unit (TCU)轉譯控制單元來維護的。
3.13.2 Translation Control Unit
TCU維護TBU中的地址轉譯表,而且使用了一個私有的AXI-stream接口來更新這些表。這裏沒什麼內容了,主要就是有一種SMMU在系統中作用的示意圖:
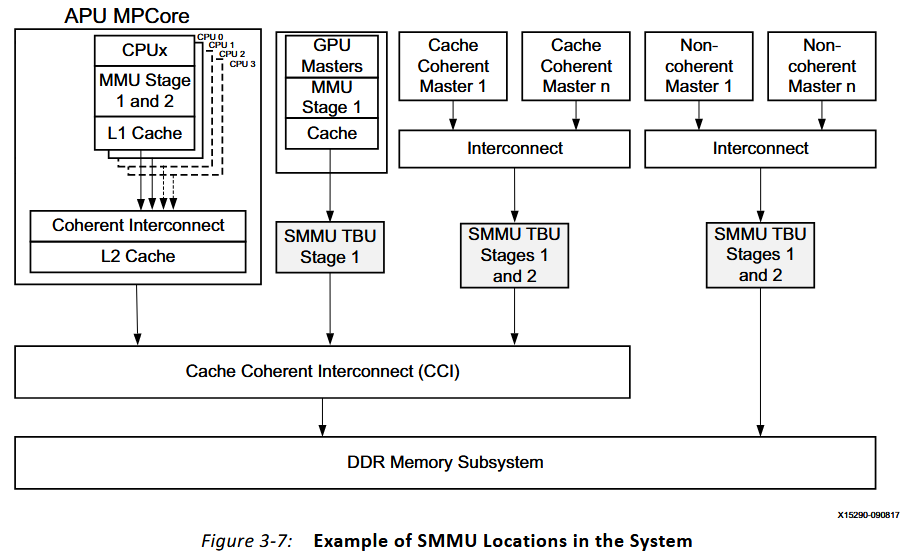
3.13.3 SMMU Architecture
這小節內容講SMMU的兩階段轉譯的內容,具體的原理我們上一部分就討論了,這裏我就主要把原文翻譯了一下,可能還有一點註釋。
3.13.3.1 Stage 1 SMMU Translation
第1階段翻譯旨在協助操作系統,無論是在本地運行還是在虛擬機管理程序中運行。第1階段翻譯的工作原理與傳統(單級)CPU的MMU類似。通常,操作系統通過連續為內核和應用程序分配和釋放堆上的內存空間來導致物理內存碎片。由於此問題,不建議使用包括IPA和PA空間之間的碎片模型的虛擬化系統(其中多個客户操作系統共享相同的物理內存)。
分配大型連續物理內存的典型解決方案是預分配此類緩衝區。這非常低效,因為僅在運行時需要緩衝區。此外,在虛擬化系統中,預分配的解決方案需要虛擬機管理程序將任何連續的緩衝區分配給客户操作系統,這可能需要虛擬機管理程序修改。
對於在碎片化物理內存上運行的DMA設備,通常會使用DMA分散-聚集(SG-DMA)機制,這會增加軟件複雜性並增加性能負載。此外,某些設備無法訪問完整內存範圍,例如64位系統中的32位設備。一種解決方案是提供反彈緩衝區-位於低地址的內存中間區域,充當橋樑。操作系統在設備可見的地址空間中分配頁面,並將它們用作往返操作系統的DMA的緩衝頁面。I/O完成後,操作系統將緩衝頁的內容複製到其最終目的地。此操作存在大量的額外費用,可以通過使用SMMU來避免。I/O虛擬化可以通過使用階段1(對於本地操作系統)以及階段1或2(對於客户操作系統)來實現。
3.13.3.2 Stage 2 SMMU Translation
SMMU第2階段轉換無需管理程序管理影子轉換表,從而簡化了管理程序並提高了性能。通過第2階段地址轉換,SMMU使客户操作系統能夠直接配置系統中支持DMA的設備。(應該是第二階段的頁表可以共用MM的頁表的意思)
SMMU還可以配置為確保防止代表一個客户操作系統運行的設備損壞另一個客户操作系統的內存。
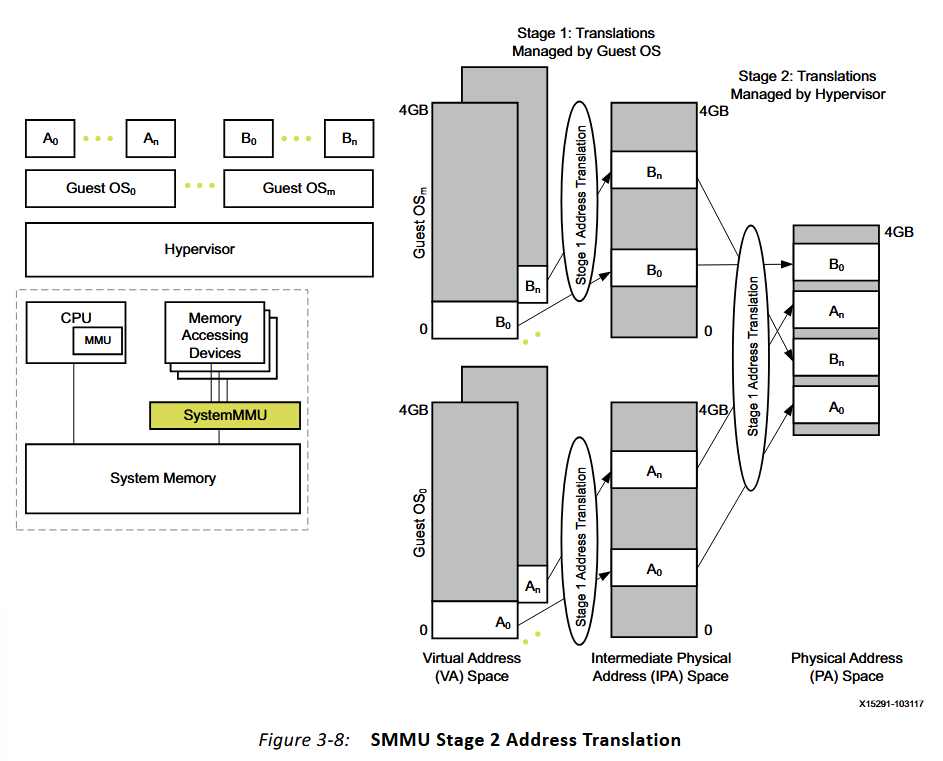
在地址轉換的兩個階段之間提供硬件分離允許明確定義客户操作系統(階段1)和管理程序(階段2)之間兩個不同階段的所有權。翻譯錯誤被路由到適當級別的軟件。管理功能(TLB管理、MMU啓用、寄存器配置)在翻譯過程的適當階段處理,通過減少虛擬機中的條目數量來提高性能。
安全和非安全翻譯上下文都支持第1階段翻譯。第2階段翻譯僅支持非安全翻譯上下文。對於非安全操作,兩階段地址轉換的典型使用模型如下。
- 非安全操作系統定義了應用程序和操作系統級操作的第1階段地址翻譯。操作系統這樣做就好像它在定義從VA到PA的映射一樣,但它實際上是在定義從VA到IPA的映射。
- 虛擬機管理程序定義將IPA映射到PA的階段2地址轉換。它將其作為一個或多個非安全客户操作系統虛擬化的一部分。
本章總結
這一章是我寫的最難過的一章,因為ARM處理器的很多內容我都不太懂,寫這一章的同時也相當於是新學了,但也正是越難的東西越有收穫。下一章還是設計處理器的一章,將RPU,我們下一章再見。