

1.資源
課件資料:https://github.com/stanford-cs336/spring2025-lectures
clone下來後,將var目錄移動到trace-viewer中的public目錄內,將images目錄也移動到public目錄內,然後cd trace-viewer,以此命令npm install和npm run dev,到瀏覽器打開如下鏈接來看第一章的課件:
http://localhost:5173?trace=/var/traces/lecture_01.json
這個鏈接只是示例,localhost後面的端口根據自己運行實際情況而定。不同的課程有對應的json。
相關中文博客:https://www.cnblogs.com/apachecn/p/19577358
其他可能參考的資料:https://datawhaler.feishu.cn/wiki/SBGEw3kFfipFQbkStGocaFVHnSf
2.為什麼要學Standford CS336?
- 理解大模型底層邏輯。
- 為你提供如何選擇、處理數據,以及如何建模的直覺。
- 糾正資源至上心態,優化算法能最大化資源利用效率。精度 = 算法效率 x 資源投入。

3.課程大綱

4.Tokenization概覽
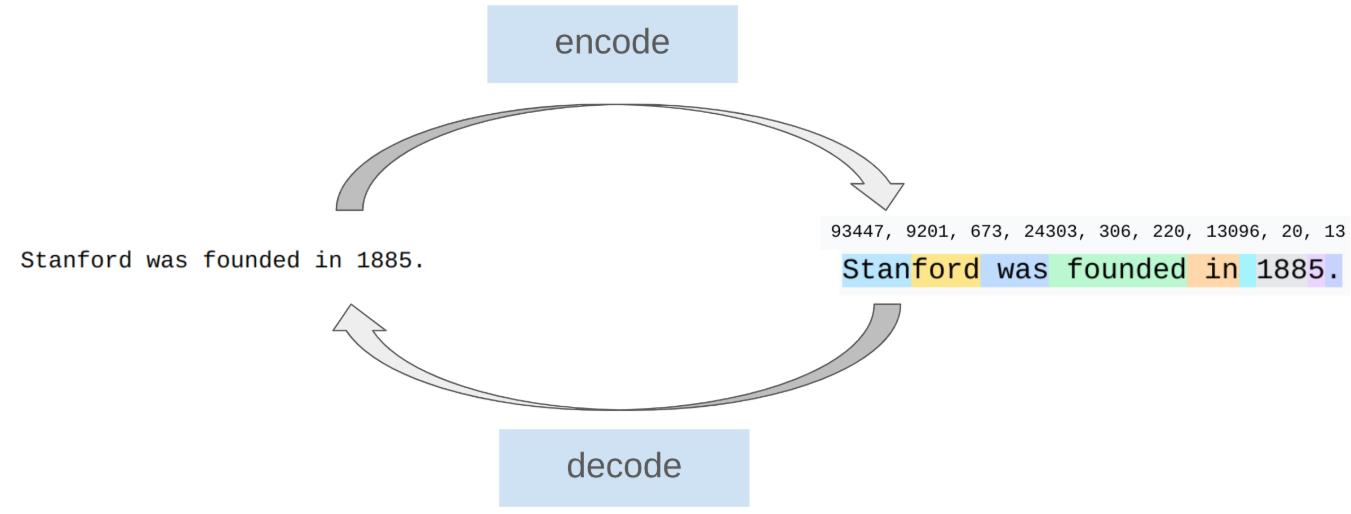
Tokenization的作用是將字符串分割為若干片段,這些片段稱為token,併為這些片段逐個賦予一個數字,這個過程稱為Tokenization的編碼。而這些編碼片段也可以通過解碼得到原來的字符串。
課程將以BPE(Byte-Pair Encoding)Tokenization為例進行tokenization技術的講解,並要求你在無AI Tools和少量Pytorch API調用的情況下實現一個BPE。
另外可以提到也有無Tokenization技術,主要通過直接讀取字節來實現語言建模。然而在現在的前沿模型中,Tokenization技術已經十分常見,課程暫且不論無Tokenization的方法。
5.最大化硬件效率
在訓練的時候,加快訓練速度,最大化硬件資源效率的一個Trick是,最大化GPU的利用率。
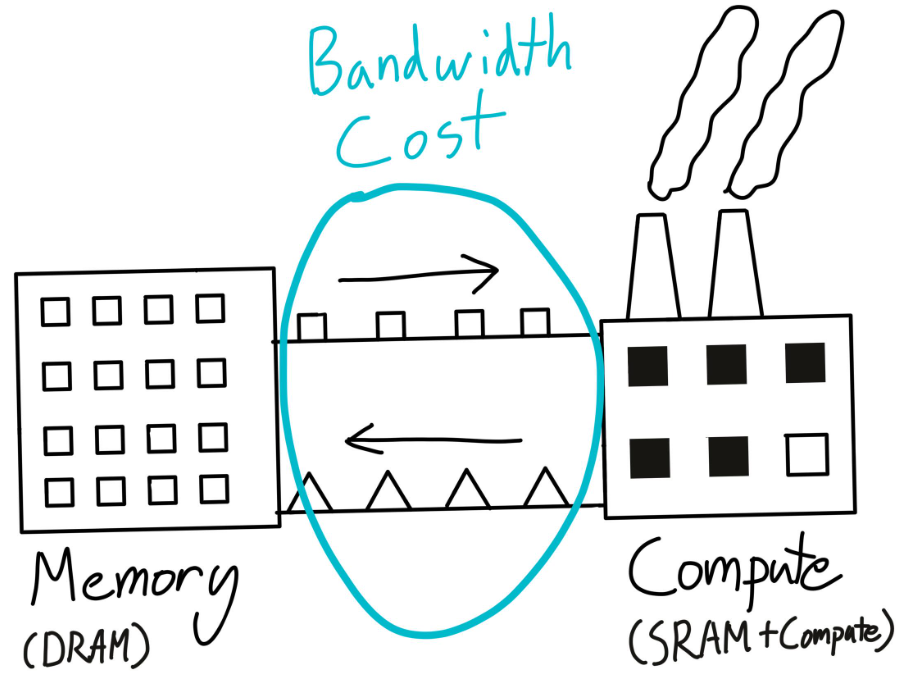
在訓練模型的過程中,GPU的作用是負責計算和模型訓練,CPU的職責是負責將模型參數、optimizer參數以及其他超參從外存運到內存,從內存運到GPU中。GPU的速度是相當快的,CPU則在進行數據傳輸中疲於奔命。因此常常會遇到GPU利用率低的問題,這通常是發生在GPU等待CPU數據傳輸的情況。所以處理好數據傳輸,能很好地提高訓練速度,最大化硬件資源效率,即最大化硬件資源效率等價於最小化數據傳輸。
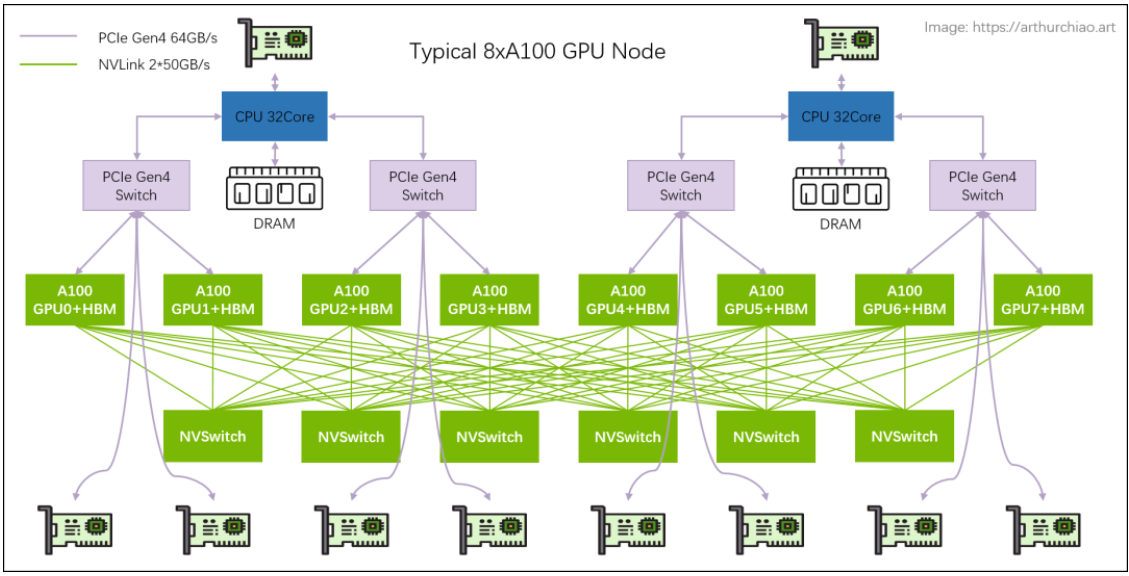
當進行多個GPU並行訓練時,數據之間的傳輸更加慢,最大化硬件資源效率等價於最小化數據傳輸依然正確。
這時候有若干並行性方法去應對這個問題,比如data parallelism,tensor parallelism等。
6.推理
推理成本>訓練成本:
隨着時間的推移,推理上的成本要超過訓練上的成本,這是因為訓練的成本通常是一次性的,而推理是按次數而言的,隨着用户量增大,使用率提高,推理次數將指數級上升。
推理的兩個階段:
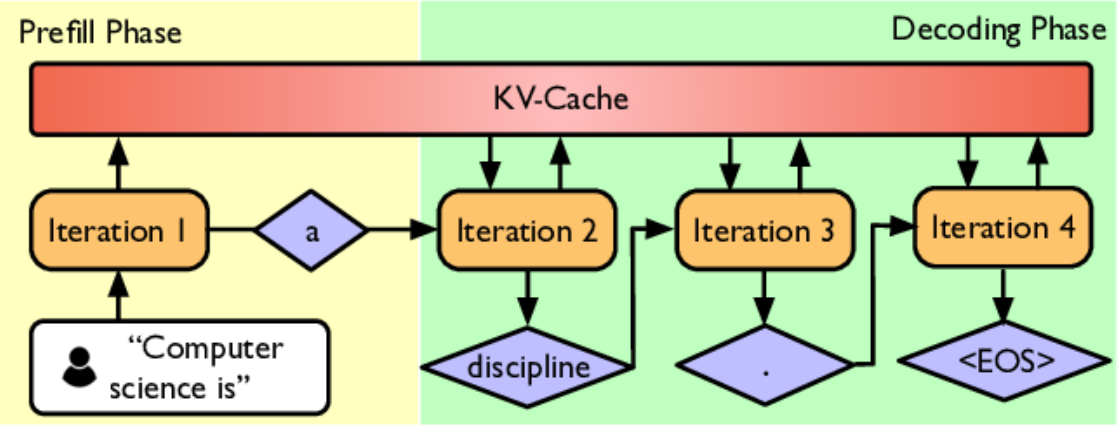
分為預填充(Prefill)和解碼(Decode)階段。預填充一次性將用户提供的prompt tokens等上下文處理完畢,包括計算每個位置的隱藏狀態以及最後一個位置的logits然後存儲KV-Cache,而解碼則是在生成過程中逐步追加新 token,每生成一個 token,上下文就變長一點,模型需要用“舊的 KV 緩存 + 新 token”再算一次下一個 token 的分佈,這個過程將會重複直到生成結束。
因此時間上來講,預填充是很快的,耗時主要集中於解碼。因此有一些手段來加速解碼,比如使用小一些的模型進行推理(模型蒸餾、模型剪枝、模型量化),或者是一些特別的策略(先用小而快的模型連續生成一段候選 token,然後由大的模型一次性驗證這段候選合理性以決定是否採納),又或者是在系統方面進行優化(優化KV-Cache等)。
7.Scaling laws
有時候為大模型做實驗時,會遇到這樣的問題:在算力預算C是固定的情況下,模型參數N應該選多大,數據tokens數D應該為多少,才能最小化自己模型的困惑度?
我們通常會覺得,如果模型越大,其能表達更復雜的規律,但如果給它喂的數據太少就“吃不飽”。數據量越大,越能讓模型充分地學習,但對於小模型會“吃不下”。所以存在一個“compute-optimal”的平衡點。
假設訓練一個Transformer的FLOPs量大致可以寫成:C≈kND
- C:總訓練FLOPs
- N:參數量
- D:訓練tokens數
- k:與架構細節有關的常數
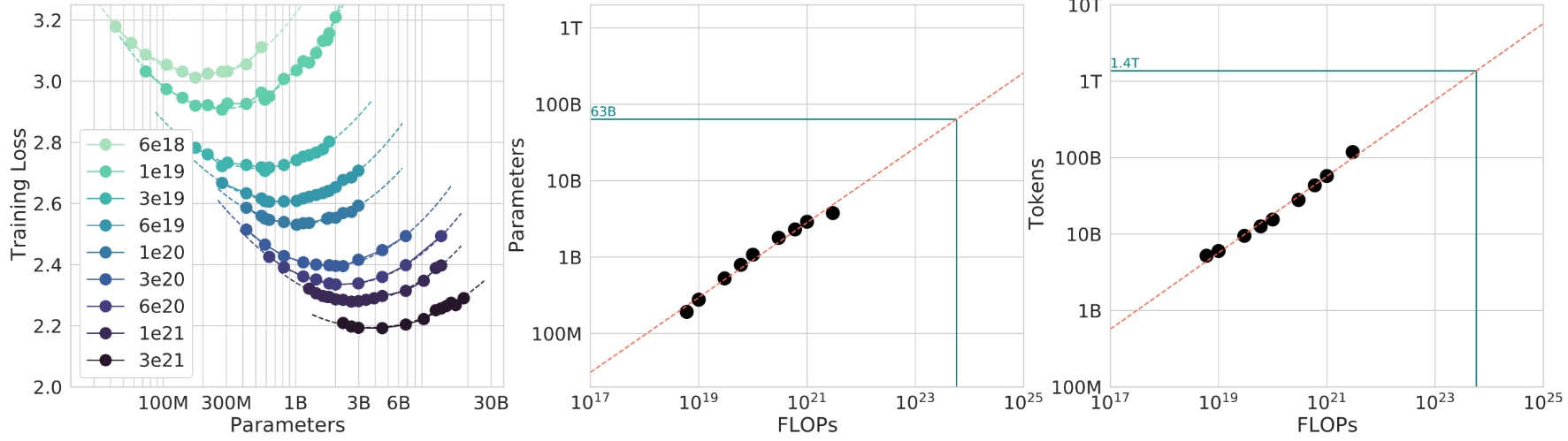
左圖的每一條曲線都存在一個臨界值,在臨界值左邊,模型太小,表達能力不夠,損失較高。右邊則是模型太大,訓練效率不足導致的損失上升。將上面公式變形後有:D / N ≈ C / (kN²)。這個公式代表着單個參數所需訓練的tokens數,即在固定FLOPs下隨着模型參數N變大,每個參數見到的tokens變少,因此訓練效率變低。
中間的圖表示給定一個算力值FLOPs,模型大概需要多少參數。而右邊的圖則表示給定一個算力值FLOPs,模型大概需要多少tokens來訓練。
Scaling Laws for Neural Language Models 和 Training Compute-Optimal Large Language Models 這兩篇文章揭示了這樣一個結論:如果你想讓模型在當前算力下達到最優,那N和D大概滿足 D ≈ 20 N。這是一種scaling law。
然而,具體的模型和實驗,有自己的scaling laws。上面兩篇論文的工作旨在啓發我們要在小規模實驗中尋找自己模型的scaling laws,得到相關規律後預測在大規模實驗和應用情境下的表現。
8.對齊
對齊方式:
簡單講一下Alignment。大模型可以分成兩種,一種是基礎大模型,另一種是指令微調大模型。一般來説,蒐集大量數據,用大量顯卡訓練許久的基礎大模型,它能夠很好地完成預測下一個token的任務,但有時候他所生成的內容並非我們用户想要得到的。
比如,GPT-4從大量的網絡數據中訓練得來,未經對齊你就向其發送這樣的字符串:“法國的首都是?”那麼其實很有可能GPT-4會回覆:“法國首都的經緯度是?”類似這樣與回答無關的內容。這是因為它可能是從一個有關法國首都的問題清單中訓練的,當你詢問其中一個問題時,大模型會返回這個問題後面最後可能出現的內容。
這並非用户想要得到的回答。因此就有了指令微調大模型。基礎大模型擁有了強大的預測tokens的能力,便可以用指令-回答對進行微調,以能夠得到強大的問答能力。這是一種對齊方式。
另外還有其他的對齊方式,比如:微調大模型的回答風格(回答格式、回答長度以及回答語氣等),還有一些安全性的因素(監督大模型生成的有害、錯誤的回答)。
相關的對齊方法有監督微調(supervised_finetuning),從反饋中學習(learning_from_feedback)。
監督微調:
又稱SFT。給大模型微調的數據格式通常是一問一答:

數據除了一部分是合成數據,大多是人工標註的數據,獲取成本和難度較高。
因為基礎大模型已經具備了強大的tokens預測能力,因此用SFT進行微調的時候不必需要大量的數據,LIMA: Less Is More for Alignment這篇文章表明大概只需要1000對數據即可,SFT主要做的只是讓大模型能夠從預測tokens轉向回答和完成用户的問題和要求。
從反饋中學習:
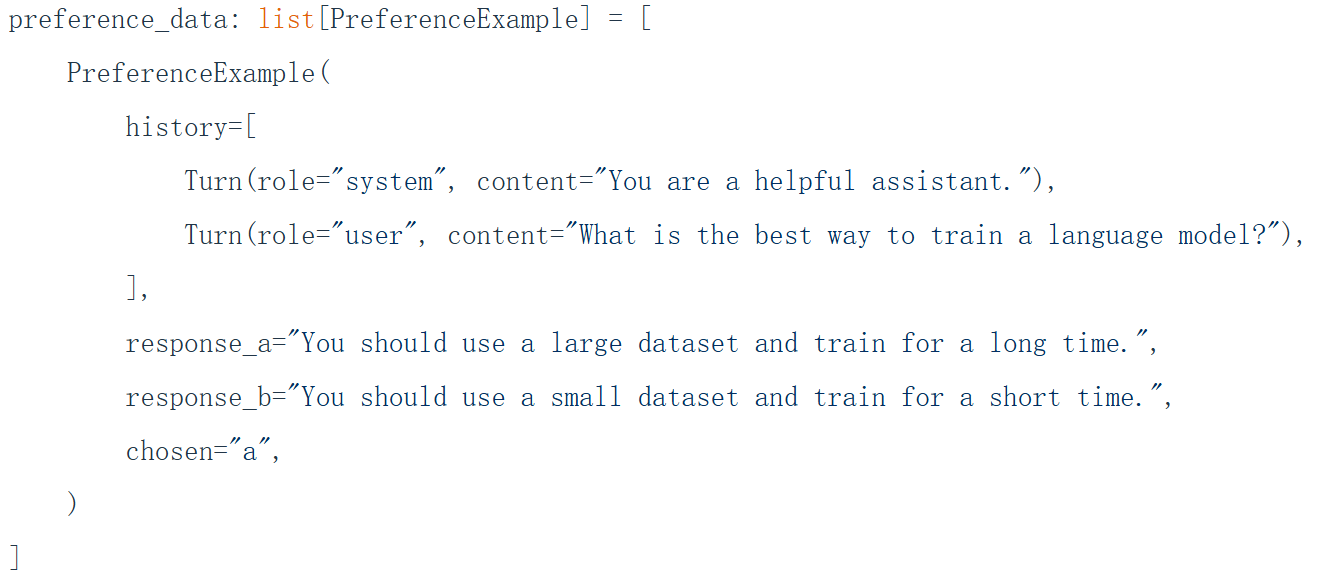
從反饋中學習指的是,給大模型一些基本的例子,在這些例子中問題的回答有兩種風格,由人選擇其中一個偏愛的回答來微調模型的輸出偏好。
可以用一些形式驗證器(適用於代碼或者數學的輸出)或者訓練過的驗證器(訓練一個LLM對抗器)對結果是否符合偏好進行驗證。
9.Tokenization詳解
給一個字符串"I love LLM",對每一個Unicode字符,UTF-8編碼可以將其轉換為8位二進制序列,得到:
01001001 00100000 01101100 01101111 01110110 01100101 00100000 01001100 01001100 01001101
這樣的indices序列長度是80,即tokens長度是80。因為是8位二進制序列,因此這樣的序列字節數是10,壓縮比是1 / 8。也就是説每一個token只能代表 1 / 8 個字節。這樣的序列太長了,太長的序列,LLM處理所需的時間就更久,我們當然希望一個token能代表儘可能多的字節信息,使得序列長度儘可能低。
Byte Tokenization:
在上面的例子中,用來表示字符的token只有0和1兩種。將token的種類彙總為字典,字典的大小為2。因此這種基於二進制位的tokenization方式,特點是序列長,字典小。效率更高的方式應該讓序列更短,因此通常用字典大小換序列長。
將8位二進制轉換為整數,得到:
73 32 108 111 118 101 32 76 76 77
一個整數代表一個字節的信息,一個token就是一個字節。整數的範圍是0-255。因此字典大小為256。indices的長度是token的長度,因為像73這樣的數字在字典中算一個token,所以indices長度是10。可以計算一下壓縮比為1。這樣的序列其實還是太長,效率還不夠。
Character Tokenization:
那麼可以考慮將Unicode字符表當成token字典,一個字符就是一個token。ASCll字符是單字節字符,也就是一個字節一個字符,因此全為ASCll字符的字符串,壓縮比為1。對於非ASCll字符,比如emoji和中文或者其他語言,通常是多個字節一個字符,因此這時一個token能表示多個字節的信息,此時壓縮比通常大於1。Unicode 字符大約有 15 萬個(150K),因此token字典大概也有15萬個。讓我們來計算一下這裏的壓縮比。壓縮比是一個token能表達的字節信息量。因此壓縮比也是1。
然而,CharacterTokenization的問題是詞表(token表)太大,實際高頻使用的只有一小部分,如此巨大的詞表使得embedding矩陣相當大,佔顯存,拖訓練和推理速度。對於一些冷門的字符,其與其他高頻的字符佔用相同的空間大小。更何況,壓縮比也不算十分高。
Word Tokenization:
這個tokenization的想法是把一整段字符串按詞分開,一個詞或者一個標點當作一個token,然後給這些不同的詞分配整數id,當作詞表的一個條目。
通常這種簡單的切分方法可以用regex.findall(r"\w+|.", string)實現,string是需要切分的字符串,\w+分出一個詞,點號分出一個標點。比如“I love LLM”會被分成“I”、“love”、“LLM”。
GPT-2的做法是把單詞前面的空格也算在切分的單詞裏,比如“I love LLM”會被分成“I”、“ love”、“ LLM”。這樣能更好處理數字、標點和空白等情況。
切分完畢後,收集訓練語料的所有非重複segement,然後為它們分別分配一個整數id。
計算一下壓縮比。可以知道這時token只有3個,壓縮比為 10 / 3 ≈ 3.33。壓縮比較前面的大大提高了。
然而,問題也很明顯。由於自然語言中單詞非常多,因此詞表也還是很巨大。訓練時,語料都能在詞表字典中找到以映射為整數餵給大模型。但是如果在測試遇到了詞表字典中沒見過的新詞(新造詞或者錯別字),就會發生未登錄詞(OOV)問題,只能將這些詞映射為統一的UNK,這會增加困惑度。
Byte-Pair Encoding(BPE) Tokenization:
BPE在Byte Tokenization基礎上做了進一步優化,它在indices進行合併同類項的操作,把高頻的詞或詞片段作為一個 token。
以“the cat in the hat”為例,首先將字符串按Byte Tokenization的方式編碼為字節,得到整數序列:116 104 101 32 99 97 116 32 105 110 32 116 104 101 32 104 97 116。這是保證不會發生OOV的基礎,這是因為無論什麼字符(包括中文、emoji),都能拆成 byte,被覆蓋到。
詞典範圍依然是0-255,長度為256。
統計相鄰token對的頻率,然後選出頻率最高的一對。比如(116,104)出現了2次,(104,101)出現了2次,(32,99)出現了1次,選擇頻率最高的(104,101),雖然(116,104)也是最高的,但並沒有什麼影響。説明104和101可能是某個有意義的子單元,於是將它們進行同類項合併。
為這個頻率最高的Pair分配一個新整數id,然後在indices中將這個Pair替換為這個新整數。比如將(104,101)分配為256,這個數字正好是詞典當前長度。然後在indices中將所有(104,101)替換為256。
重複執行以上操作多次,就能優化序列長度。比如執行3次,得到258 99 97 116 32 105 110 32 258 104 97 116,具體是將(116,104)合併為256,將(256,101)合併為257,(257,32)合併為258。
上面的例子,最終的indice長度為12,原先為18。計算一下壓縮比,壓縮比為 18 / 12 ≈ 1.5。
看起來不是很高?上面的合併還不算是最優的結果,畢竟只執行了3次循環。你需要訓練一個BPE,使得壓縮比儘可能高。
GPT-4,LLaMA等主流模型都在用BPE或其變體,BPE確實在詞表大小、序列長度、魯棒性之間做了很好的均衡。