

摘要:
本文介紹如何為開源個人AI助手 Moltbot(原 ClawdBot)集成基於 OceanBase 技術棧的長期記憶插件 PowerMem。通過 HTTP API 對接,PowerMem 為 Moltbot 提供智能信息抽取、艾賓浩斯遺忘曲線調度及多智能體隔離的記憶能力,顯著增強其上下文持久化與自主決策水平,實現更類人的“數字員工”體驗。
Moltbot 是什麼?

Clawdbot(後更名為 Moltbot,又更名為 OpenClaw)是一款開源、以通訊為核心的AI智能體項目,運行在你自己的設備上,通過你已有的渠道(WhatsApp、Telegram、Slack、Discord、Google Chat、Signal、iMessage、Teams、WebChat 等)和你對話,支持語音、Canvas、多代理路由等。
簡單點説:Moltbot 最大的特點是不僅能回答問題,更能真正“動手”操作你的電腦系統,執行命令、控制瀏覽器、管理文件,就像一個 7 x 24 小時在線的 “數字員工”。
官網 :https://www.molt.bot/
github 地址:https://github.com/moltbot/moltbot
Moltbot 部署
方式一:NPM 全局安裝
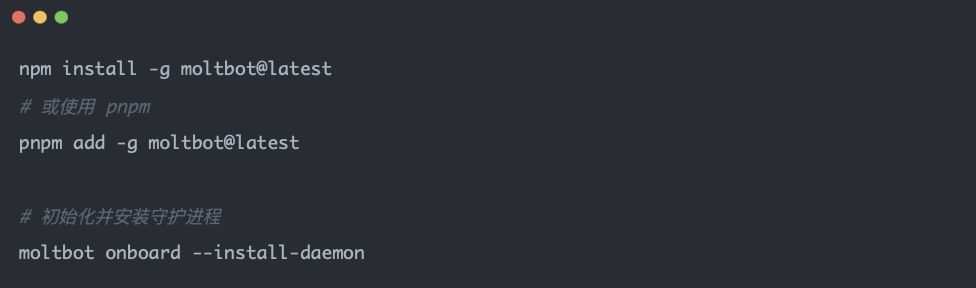
方式二:源代碼安裝

上面兩種安裝方式二選一,因為我是走的源代碼安裝:
- pnpm moltbot onboard --install-daemon 初始化
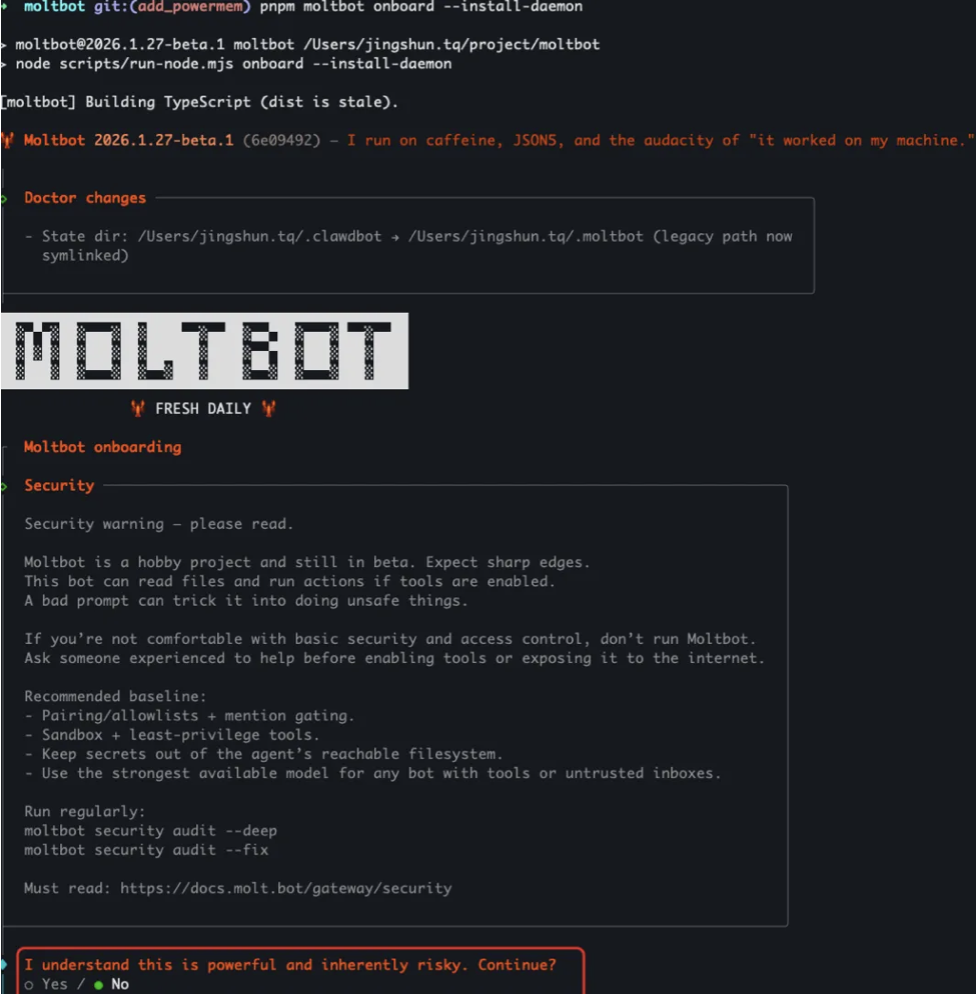
- 同意風險提示
這裏會讓你確認風險。Moltbot 功能強大,能執行系統命令、讀寫文件、控制瀏覽器,但這也意味着如果配置不當或被濫用,可能會帶來安全風險,請謹慎使用。
![]()
- 選擇快速開始
- 配置 AI 模型授權,我手裏頭有qwen的
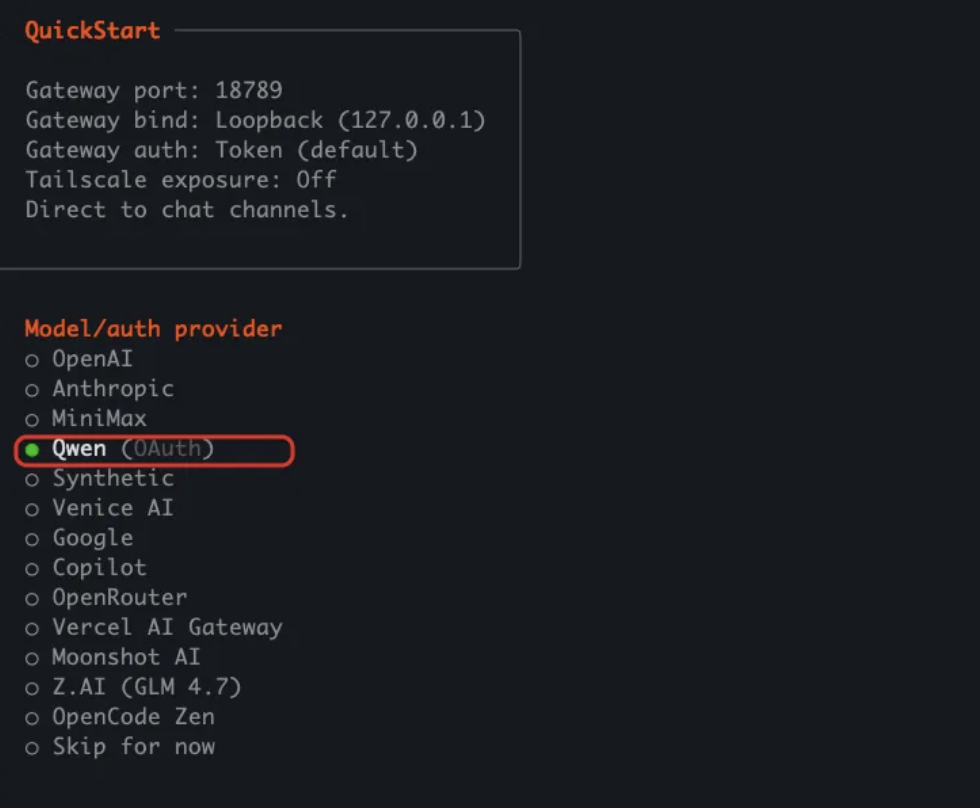
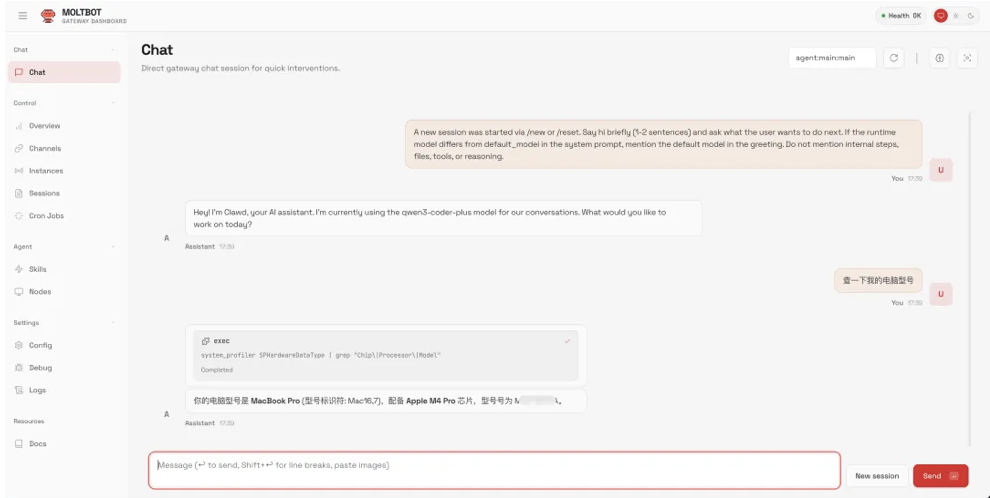
- 啓動web
問個小問題:“查一下我的電腦型號”,很快 moltbot 回覆了我機器的具體型號,雖然任務非常簡單,但是還是挺驚喜的,距離“賈維斯”又進了一步了。
Moltbot 的原生記憶解讀
Moltbot 的持久記憶可以概括為:「Markdown 文件為單一事實來源 + 可選向量/混合檢索」。
存儲形態:純 Markdown 文件
事實來源:模型「記得」的內容 = 寫入磁盤的 Markdown;不依賴模型內部狀態。
默認佈局(在 workspace 下,如 ~/clawd):
memory/YYYY-MM-DD.md:按日期的日誌,僅追加;會話開始時讀「今天 + 昨天」。
MEMORY.md(可選):長期、人工可維護的記憶;只在 main 私聊 session 加載,羣聊不加載。
也就是説:
短期、按天的記錄 → memory/YYYY-MM-DD.md
長期、精選事實 → MEMORY.md
持久化完全靠「寫進這些文件」,而不是靠對話歷史本身。
寫入時機與「記憶沖刷」(Memory Flush)
平時:模型通過 工具(如 write、edit)或技能,把要記住的內容寫到 MEMORY.md 或 memory/YYYY-MM-DD.md。
自動沖刷:當 session 快觸發自動 compaction 前,Moltbot 會跑一輪 靜默的 agent 回合,專門提醒模型「把該持久化的東西寫進記憶文件」,並鼓勵用 NO_REPLY 不回覆用户,避免用户看到這次內部回合。
觸發條件由 agents.defaults.compaction.memoryFlush 控制,例如在「剩餘 token ≈ softThresholdTokens」時觸發;每輪 compaction 只做一次 flush,並在 sessions.json 裏記 memoryFlushCompactionCount 等,避免重複。
相關代碼在 src/auto-reply/reply/memory-flush.ts:
shouldRunMemoryFlush():根據當前 token、context 上限、reserve、softThreshold 判斷是否該 flush。
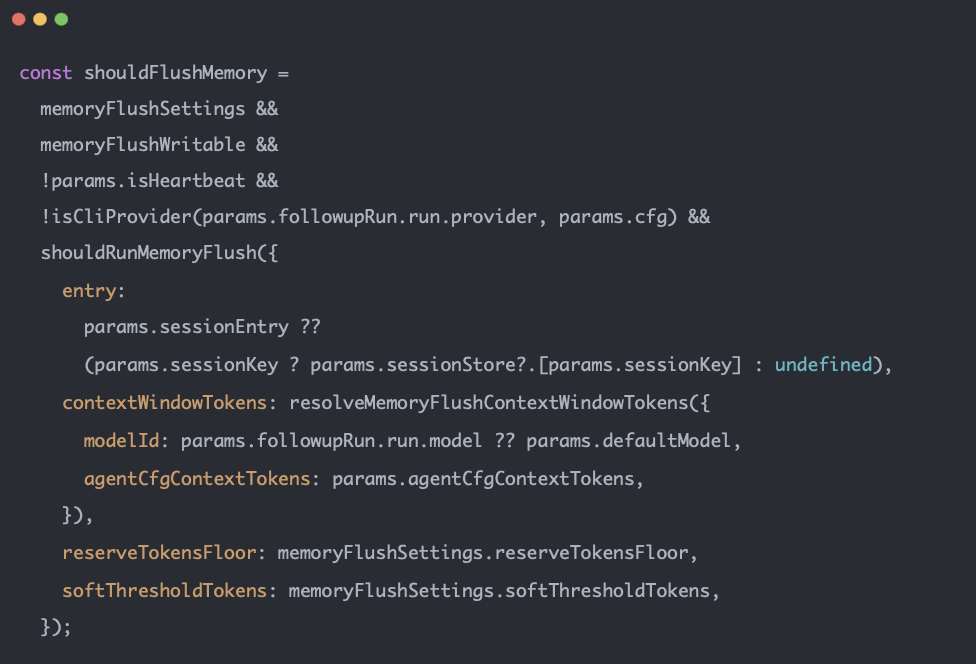
若 workspace 只讀(如 sandbox workspaceAccess: "ro"),則不做 flush。
檢索層:向量 + 可選 BM25 混合檢索
數據流

實現方式
插件控制:默認使用 memory-core 插件(可設 plugins.slots.memory = "none" 關掉)。
工具:
memory_search:對 MEMORY.md 和 memory/*.md 做語義檢索(按 ~400 token 分塊、80 token 重疊),返回片段 + 文件路徑 + 行號;可選開啓 BM25 + 向量 的混合檢索。
memory_get:按路徑(及可選 from/lines)讀取 MEMORY 或 memory 下的文件片段,供在檢索後精確拉取,控制上下文長度。
向量索引:
對MEMORY.md 和 memory/*.md 建索引;索引按 agent 存於 ~/.clawdbot/memory/.sqlite(路徑可配)。
支持遠程 embedding(OpenAI、Gemini 等)或本地模型(如 GGUF);可選 sqlite-vec 做向量加速。
文件變更有 watcher(debounce),索引異步更新;若 embedding 模型/端點等變化,會整庫重建索引。
混搜權重分配

最終分數的計算公式非常簡單(src/memory/hybrid.ts):

這意味着:
向量搜索和文本三七開:最終得分 = 0.7×向量分 + 0.3×文本分(歸一化後),偏重語義。
候選池放大 4 倍:先取 maxResults × 4 的候選再合併、排序、截到 maxResults,提高最終 Top‑N 質量。
Moltbot + powermem 方案

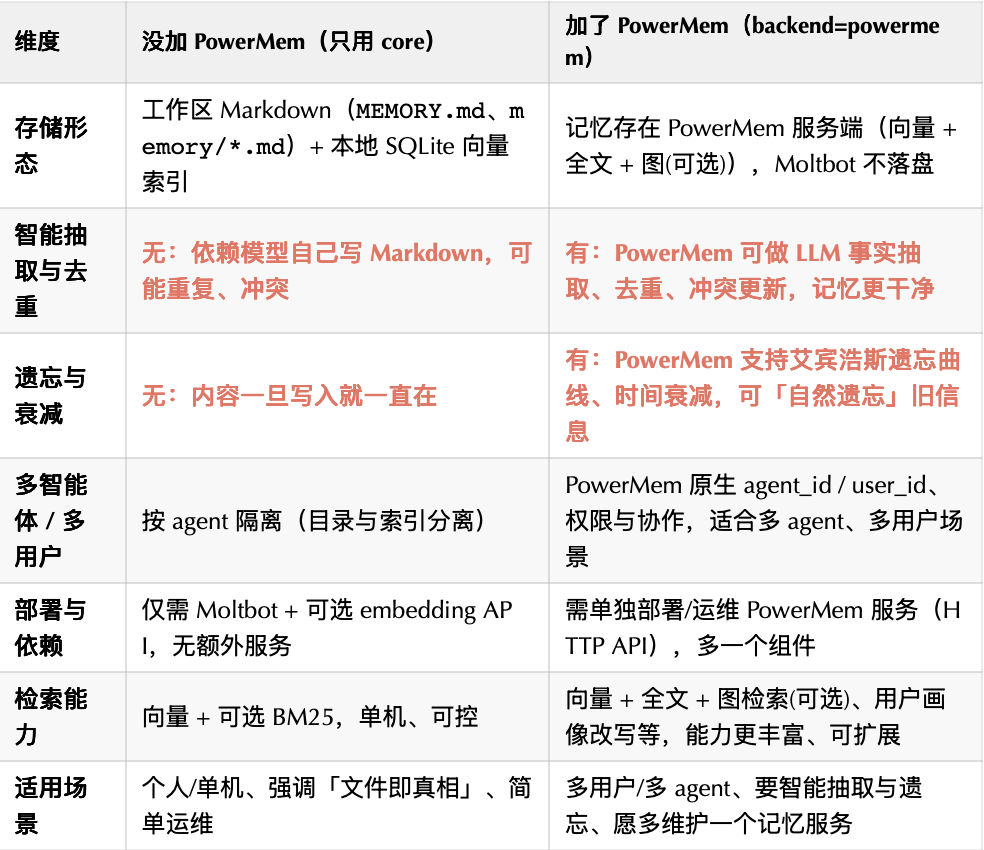
有 PowerMem VS 沒有 PowerMem
集成 powermem 方案
集成方式:已插件的方式進行集成
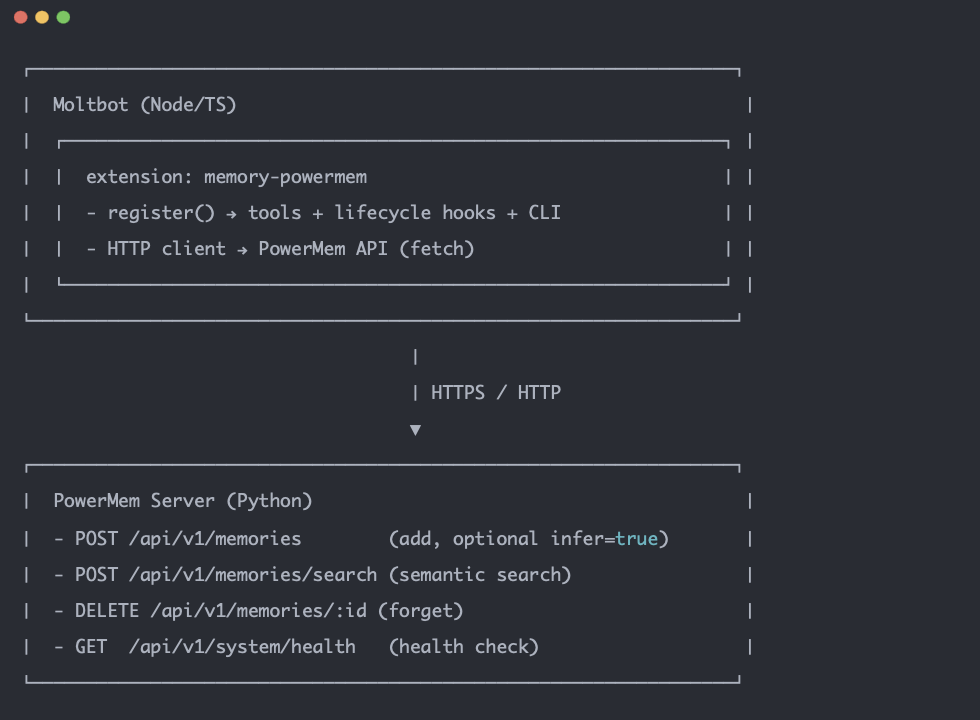
集成方式:新增插件 extensions/memory-powermem,通過 HTTP 調用 PowerMem 已啓動的 API 服務;不把 PowerMem 作為庫嵌入 Moltbot 進程。
部署:用户需單獨啓動 PowerMem(如 powermem-server --host 0.0.0.0 --port 8000 或 Docker),並在 Moltbot 配置中填寫 baseUrl(及可選 apiKey)。
代碼結構
代碼地址:https://github.com/ob-labs/moltbot-extension-powermem

在 Moltbot Agent 裏會暴露這些能力:
memory_recall — 按查詢搜索長期記憶
memory_store — 寫入一條記憶(可選是否智能抽取)
memory_forget — 按記憶 ID 或按搜索條件刪除
使用 powermem 插件
Step1: 前置條件
已安裝 Moltbot(CLI + gateway 能正常用)
PowerMem 服務:需要單獨安裝並啓動(見下文兩種方式,任選其一)
若用 PowerMem 的「智能抽取」:需在 PowerMem 的 .env 裏配置好 LLM + Embedding 的 API Key(如通義千問 / OpenAI)
Step2:把本插件裝進 Moltbot
在你本機執行(路徑改成你實際克隆的目錄):
安裝成功後,可用 moltbot plugins list 確認能看到 memory-powermem。
Step3:配置 Moltbot 使用本插件
編輯 Moltbot 的配置文件(常見位置:~/.clawdbot/config.json 或項目裏的 moltbot.json),在 根級 增加或合併 plugins 段,並把記憶槽指向本插件,並寫上 PowerMem 的地址。
示例(JSON):
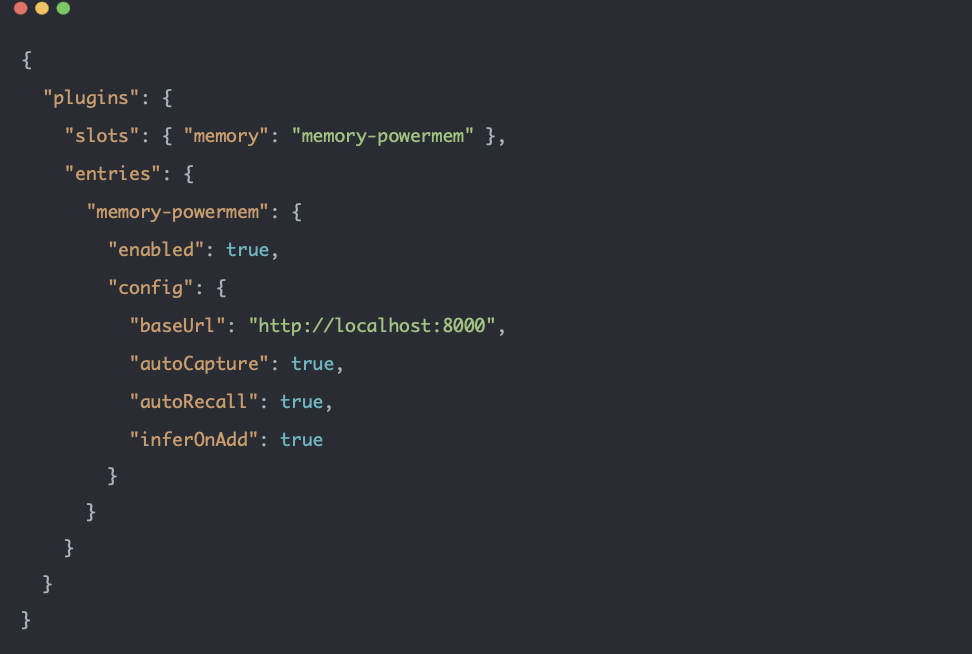
説明:
baseUrl:PowerMem 的 HTTP 地址,不要加 /api/v1,就寫 http://localhost:8000 或你的實際主機/端口。
若 PowerMem 開了 API Key 鑑權,在 config 裏增加 "apiKey": "你的key"。
改完配置後重啓 Moltbot gateway(或重啓 Mac 菜單欄應用),配置才會生效。
Step4:驗證插件與 PowerMem 連通
在終端執行:

若輸出裏沒有報錯、能看到健康狀態,説明插件已連上 PowerMem。
Step5: 測試手動寫入 + 搜索
我們來簡單測試一下,用手動寫入驗證數據庫是否有數據

若搜索能返回剛寫的那條(或類似內容),説明「安裝 PowerMem → 安裝插件 → 配置 Moltbot」全流程已打通。
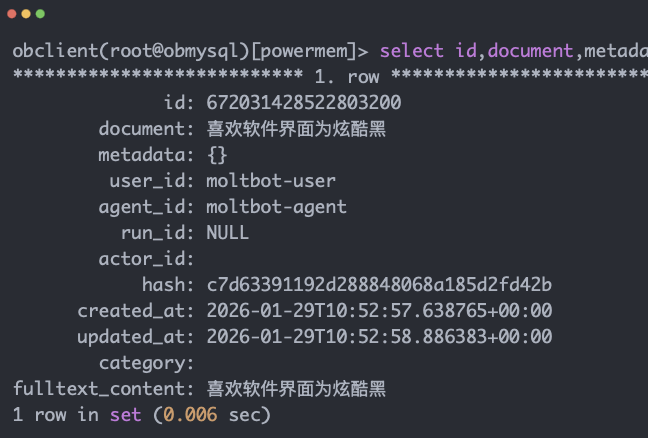
下面是執行結果:
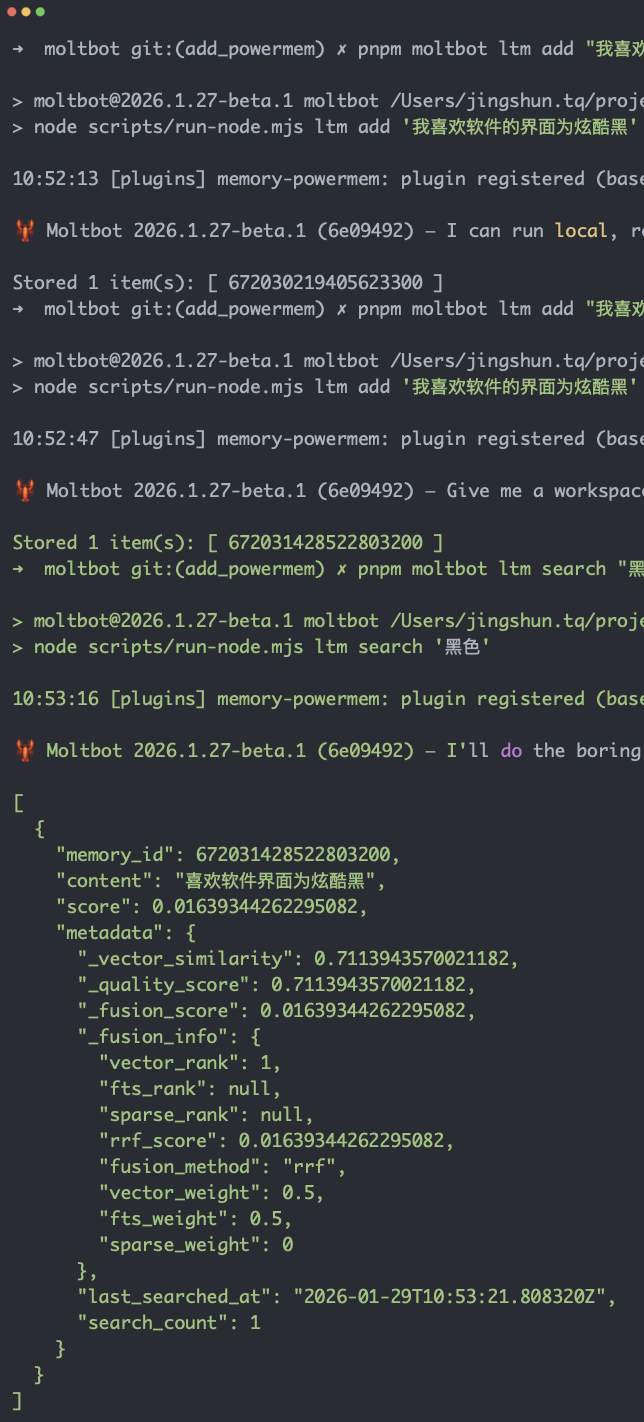
看一眼數據庫,妥妥的已經寫入了
歡迎訪問 OceanBase 官網獲取更多信息:https://www.oceanbase.com/