

介紹
分析型業務通常需要對海量數據進行分析計算,這對數據庫的查詢能力,以及數據管理能力都有很高的要求。OceanBase通過分區技術,將一張表的數據按照分區鍵水平拆分成多個數據子集,有助於提升查詢效率和數據管理能力:
1.查詢效率提升:分區裁剪能減少無關數據的掃描
2.數據維護:支持按照分區粒度進行數據管理,比如數據歸檔、清理等
3.數據分佈:按照分區粒度進行數據分佈,能夠將數據打散到多個節點上,具備良好的可擴展性
本文首先對分區在 OceanBase 的作用進行介紹,接着描述了 OceanBase 中的基礎分區方式以及它們的適用場景,最後討論了 OceanBase 的靈活分區管理能力如何應用於數據維護、數據管理等業務場景。
OceanBase 中分區的作用
在 OceanBase 中,分區是水平分片的基本單位,是數據分佈、負載均衡和並行操作的最小物理單元。一張大表被邏輯地分割成多個更小、更易管理的獨立塊,每個分區(甚至分區的不同副本)都可以分散存儲在集羣中不同的 OBServer 節點上。
這種設計為分析型業務帶來了根本性的優勢:當單一節點的存儲或計算能力成為瓶頸時,可以通過增加節點並重新分佈分區的方式,實現近乎線性的水平擴展,從而處理 PB 級別的數據量。
分區裁剪提升查詢效率
使用分區後,指定分區列進行查詢時,在某些場景下能夠裁剪出滿足查詢條件的分區,使得查詢無須查詢那些不滿足條件的分區。
參考如下例子,我們在列 c2 上創建 hash 分區,指定 c2=1 的查詢條件,能夠裁剪出只需要查詢分區 p1。
-- 創建一張四個hash分區的表格t1,分區鍵為C2create table t1(c1 int, c2 int) partition by hash(c2) partitions 4;
-- 指定c2=1查詢,裁剪出分區p1explain select * from t1 where c2 = 1;+------------------------------------------------------------------------------------+| Query Plan |+------------------------------------------------------------------------------------+| =============================================== || |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| || ----------------------------------------------- || |0 |TABLE FULL SCAN|t1 |1 |3 | || =============================================== || Outputs & filters: || ------------------------------------- || 0 - output([t1.c1], [t1.c2]), filter([t1.c2 = 1]), rowset=16 || access([t1.c2], [t1.c1]), partitions(p1) || is_index_back=false, is_global_index=false, filter_before_indexback[false], || range_key([t1.__pk_increment]), range(MIN ; MAX)always true |+------------------------------------------------------------------------------------+
分區裁剪可以過濾掉不需要的數據,但分區數太多可能也會導致其他的問題,例如元數據量過多、分區裁剪的效率可能降低等等,因此,在 OceanBase 的列存表中建議單個分區的行數>=100W 行。
分區作為數據維護單元
在數據庫運維中,將分區作為基本的數據維護單元,能較大地簡化日常管理流程,例如數據清理場景、分區級收集統計信息等。以數據清理場景為例,當數據按時間進行分區後,清理過期數據就不再需要逐行刪除,而是直接通過刪除整個歷史分區來實現,這種操作僅僅只需要修改元數據,還能徹底釋放磁盤空間,避免了傳統的 DML 刪除操作產生的性能開銷。通過分區鍵(如時間) 將數據自然歸類,使維護操作從“逐行掃描”變為“批量處理”,極大地提升了管理效率,降低了運維的複雜度。
分區作為數據分佈單元
分區作為 OceanBase 的數據分佈單元,每個分區的副本可以放置在不同的 OBServer 節點,以實現存儲和計算的擴展。
1.存儲的擴展:當創建一個分區表時,這些分區及其副本可以根據集羣的資源情況,由 OceanBase 自動調度到不同的物理節點上。這意味着單張表的容量不再受限於單機磁盤,而是整個集羣的存儲容量,當集羣的存儲空間不足時,通過加節點就能夠實現擴展。
2.計算的並行化:這是分析型業務實現高性能的關鍵因素之一,當一個查詢(特別是涉及全表掃描或大規模聚合的查詢)被執行時,OceanBase 的優化器會識別出查詢涉及的分區。查詢任務可以被分解成多個子任務,並下推到各個數據分區所在的節點上並行執行。例如,一個 SUM() 操作會在每個分區本地先計算小計,然後將中間結果彙總得到最終總和,這充分利用了多節點的計算能力,從而顯著加速查詢。
OceanBase 的基礎分區方式
目前 OceanBase 中支持三大類基礎的分區方式,包括 Hash/Key,Range/Range Columns 和 List/List Columns,三種分區方式各自的使用場景有所不同。
HASH/KEY 分區
一般適用於分區列 NDV(不同值的種類)較大,且難以劃分出明確範圍的情況。優點是容易讓沒有特定規則的數據也能夠在不同的分區內均勻分佈,缺點是在範圍查詢時難以進行分區裁剪。
適用場景舉例:無明顯查詢模式,需均勻分佈數據到多個節點(如用户ID、交易ID)。
設計要點:
- 分區鍵選擇:
- NDV(唯一值數量)遠大於分區數(如用户 ID 的 NDV 應遠大於分區數)。
- 優先選擇無傾斜(或只有少量傾斜)的整型/時間列(如 user_id, order_time,或者自增列)。
- 高頻查詢條件字段(如 user_id 作為 Join 關鍵字)。
- 分區數推薦:
- 確保分區數匹配集羣的機器數量,避免資源分配不均衡
示例場景(Hash 分區使用場景)
-- Hash分區,按user_id均勻分佈CREATE TABLE customer( user_id BIGINT NOT NULL, login_time TIMESTAMP NOT NULL, customer_name VARCHAR(100) NOT NULL, phone_num BIGINT NOT NULL, city_name VARCHAR(50) NOT NULL, sex INT NOT NULL, id_number VARCHAR(18) NOT NULL, home_address VARCHAR(255) NOT NULL, office_address VARCHAR(255) NOT NULL, age INT NOT NULL)PARTITION BY HASH(user_id) PARTITIONS 128;
Range/Range Columns 分區
一般適用於分區鍵容易劃分出明確的範圍的情況,例如可以把記錄流水信息的大表,根據表示信息時間的列做 RANGE 分區。
適用場景舉例:
- 數據按時間/數值範圍增長(如 order_time, price)。
- 需快速裁剪歷史數據(如僅查詢最近一個月數據)。
設計要點:
- 分區鍵選擇:
- 時間字段(如 order_time)或連續數值字段。
- 分區邊界需與業務查詢條件對齊(如按天/月劃分)。
- 分區數推薦:
- 根據數據增長設置分區,例如按照月份分區。
示例場景(ange/Range Columns分區示例)
-- 創建系統日誌表,按日誌時間進行月度RANGE分區,支持快速查詢與數據歸檔CREATE TABLE system_logs( log_id BIGINT, log_date TIMESTAMP NOT NULL, log_level VARCHAR(10), source_system VARCHAR(50), user_id BIGINT, log_message TEXT, client_ip VARCHAR(15))-- 主分區:按月RANGE分區,使用日期直接表達分區邊界PARTITION BY RANGE COLUMNS(log_date)( PARTITION p_202001 VALUES LESS THAN ('2020-02-01'), PARTITION p_202002 VALUES LESS THAN ('2020-03-01'), PARTITION p_202003 VALUES LESS THAN ('2020-04-01'), PARTITION p_202004 VALUES LESS THAN ('2020-05-01'), PARTITION p_202005 VALUES LESS THAN ('2020-06-01'), PARTITION p_202006 VALUES LESS THAN ('2020-07-01'), PARTITION p_202007 VALUES LESS THAN ('2020-08-01'), PARTITION p_202008 VALUES LESS THAN ('2020-09-01'), PARTITION p_202009 VALUES LESS THAN ('2020-10-01'), PARTITION p_202010 VALUES LESS THAN ('2020-11-01'), PARTITION p_202011 VALUES LESS THAN ('2020-12-01'), PARTITION p_202012 VALUES LESS THAN ('2021-01-01'), -- 默認分區處理未來數據或時間格式異常的記錄 PARTITION p_future VALUES LESS THAN (MAXVALUE));
List/List Columns分區
一般適用於需要顯式控制各行數據如何映射到具體的某一個分區時,優點是可以對無序或無關的數據集進行精準分區,缺點是在範圍查詢時難以進行分區裁剪。
適用場景舉例:
- 離散型字段(如地區、渠道類型)。
- 需按固定類別快速裁剪數據(如查詢華東地區用户)。
設計要點:
- 分區鍵選擇:
- 離散值且數量有限(如 region 字段僅有 ['east','west','south','north'])。
- 分區值需覆蓋所有可能取值,避免遺漏。
- 分區數限制:
- 根據業務邏輯進行配置分區數
示例場景(List/List Columns 分區使用場景)
CREATE TABLE orders_by_region( order_id BIGINT COMMENT '訂單唯一標識', region_code INT NOT NULL PRIMARY KEY COMMENT '區域代碼(1=north/china, 2=east/china, 3=south/china, 4=west/china)', customer_id BIGINT COMMENT '客户ID', order_time DATETIME COMMENT '訂單創建時間', product_category VARCHAR(50) COMMENT '商品類別', order_amount DECIMAL(18,2) COMMENT '訂單金額', payment_status VARCHAR(20) COMMENT '支付狀態(如:PAID, UNPAID)')PARTITION BY LIST(region_code) -- 改為整數類型分區鍵( PARTITION p_north VALUES IN (1), -- 區域代碼1對應north/china PARTITION p_east VALUES IN (2), PARTITION p_south VALUES IN (3), PARTITION p_west VALUES IN (4), PARTITION p_other VALUES IN (DEFAULT) -- 默認分區處理未知區域);
靈活的分區管理能力
OceanBase 有非常靈活的分區管理能力,從數據管理的角度來看,它既有數據維護的功能,也有數據分佈的功能;從使用方式來講,它有手動管理和自動管理兩種方式;從分區的層次來考慮,它支持一級分區和二級分區組合使用,通過不同的組合,滿足用户對於數據管理的不同需求。
本節將從數據維護和數據分佈來個角度來展開,同時在兩個角度中考慮使用方式以及分區的層次的能力組合。
數據維護
業務層通常按照時間維度來管理分區,方便做數據的歸檔,清理等操作,我們從業務的完整的數據生命週期流程來結合來描述我們的手動分區管理能力。
1.業務建表:創建按照時間分區的表格,提前創建未來一段時間需要的分區
2.業務導數:導入數據
3.業務運行:隨着時間的推進,可能提前創建的分區不足,繼續提前創建未來一段時間需要的分區
4.定期數據清理:當數據積累到一定時間後,可能之前的數據就不需要了,此時可以刪除不需要的分區
以下是上述使用場景的具體例子:
-- 1. 創建分區表(按天分區,預創建未來7天分區)CREATE TABLE business_data( id BIGINT NOT NULL AUTO_INCREMENT, event_time DATETIME NOT NULL, metric_value DECIMAL(10,2), PRIMARY KEY (id, event_time)) PARTITION BY RANGE COLUMNS(event_time)( PARTITION p20231025 VALUES LESS THAN ('2023-10-26'), PARTITION p20231026 VALUES LESS THAN ('2023-10-27'), PARTITION p20231027 VALUES LESS THAN ('2023-10-28'), PARTITION p20231028 VALUES LESS THAN ('2023-10-29'), PARTITION p20231029 VALUES LESS THAN ('2023-10-30'), PARTITION p20231030 VALUES LESS THAN ('2023-10-31'), PARTITION p20231031 VALUES LESS THAN ('2023-11-01') -- 預創建未來7天分區);-- 2. 導入數據,這裏略過-- 3. 預創建未來7天分區ALTER TABLE business_data ADD PARTITION( PARTITION p20231101 VALUES LESS THAN ('2023-11-02'), PARTITION p20231102 VALUES LESS THAN ('2023-11-03'), PARTITION p20231103 VALUES LESS THAN ('2023-11-04'), PARTITION p20231104 VALUES LESS THAN ('2023-11-05'), PARTITION p20231105 VALUES LESS THAN ('2023-11-06'), PARTITION p20231106 VALUES LESS THAN ('2023-11-07'), PARTITION p20231107 VALUES LESS THAN ('2023-11-08'));-- 4. 定期數據清理,例如數據到期後,刪除7天的數據ALTER TABLE business_data DROP PARTITION p20231025, p20231026, p20231027, p20231028, p20231029, p20231030, p20231031;
由於數據在不停地寫入,手工維護預創建分區和定期清理分區還是比較麻煩的。為了簡化這個流程,OceanBase 提供了動態分區功能,支持按固定時間分區,預創建多長時間的分區和保留多久的歷史分區等功能,對於上面的例子,假如我們需要保留 30 天數據,每次預創建 7 天的分區,那麼使用如下語法來進行創建:
-- 1. 創建分區表,設置動態分區策略CREATE TABLE t1( id BIGINT NOT NULL AUTO_INCREMENT, event_time DATETIME NOT NULL, metric_value DECIMAL(10,2), PRIMARY KEY (id, event_time))DYNAMIC_PARTITION_POLICY( ENABLE = true, TIME_UNIT = 'day', PRECREATE_TIME = '7day', EXPIRE_TIME = '30day')PARTITION BY RANGE COLUMNS(event_time)( PARTITION p20231025 VALUES LESS THAN ('2023-10-26'));
除了 Range 分區模式外,業務也可以按照業務需求選擇其他基礎分區方式。
數據分佈
分區也可以作為數據據分佈管理的單元,通常情況下為了數據打散,一般使用 HASH 分區的方式,它有如下優勢:
- 它通常能實現比較好的數據打散的需求,也能夠做比較準確的分區裁剪;
- 對於需要 join 的多張表格,如果按照 join 鍵進行 hash 分區,並且分區數也保持一致,此時配合 OceanBase table group 能力,能夠實現相同 hash 規則的對應下標的分區綁定在一起,從而使得 join 時能夠使用 Partition Wised Join,避免數據 shuffle。
Hash 分區也存在部分問題:
- Hash 分區的分區數設置之後,修改分區數是一個比較重的操作,涉及到整張表的數據重寫,所以,一般設置好 Hash 分區的分區數之後,就一般不再變化,比較難以實現可擴展;
- 對於分區鍵上的範圍查詢,無法裁剪出分區,需要訪問所有的分區,可能會存在讀放大。
為了解決 HASH 分區可擴展性以及範圍查詢的問題,OceanBase 已經支持行存表的自動分區分裂能力,在未來版本中還將提供兩種列存表自動分區分裂的模式:堆表分區分裂模式和聚集索引(clustering key)表分區分裂模式。
堆表分區分裂模式基於堆表的隱藏主鍵列進行自動分區,由於隱藏主鍵在分區分裂模式下是隨機生成的,並且當租户的機器資源擴展或縮容時,會自動擴充或者縮減對應的分區數,使得該模式能夠自動地進行擴展,具備比較好的可擴展性。不過,該模式下數據行是隨機分佈在任意一個分區的,因此是無法進行分區裁剪的,所以查詢性能上可能不是最優,該模式適合對性能要求不高,且不希望提供手動分區或者自動分區鍵的情況,但又希望表能夠自動地擴展。
聚集索引表分區分裂模式基於用户指定的聚集鍵進行自動分區,按照數據量進行自動地切分合適大小的分區,當租户的機器資源擴展或者縮容時,由於分裂的分區數已經足夠多時,就可以將這些分區重新進行均衡。該模式由於按照聚集鍵進行自動拆分,當查詢能夠指定聚集鍵查詢,無論是點查還是範圍查詢,能夠進行分區裁剪,查詢性能是比較優的,並且也能夠根據機器資源進行自適應地擴展或者縮容。同時聚集索引表自動分裂也能夠對支持多張需要 join 的表配置 table group,其中自動分裂的鍵可以配置為 join鍵,也能實現 Partition Wised Join。
為了方便大家理解,Hash、堆表分區分裂和聚集索引表分區分裂三種方式的特點對比如下:
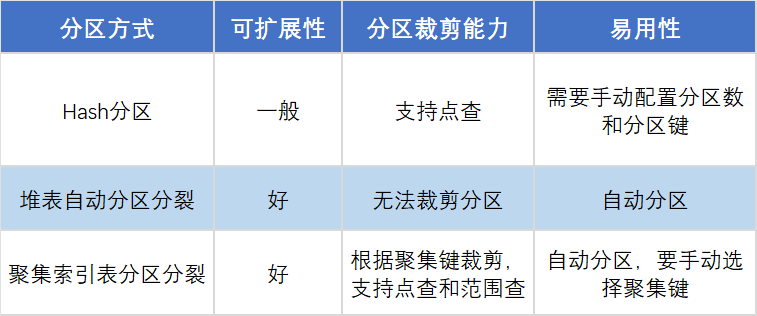
除了上述分區方式,業務也可以按照業務需求選擇其他的基礎分區方式。
混合數據維護和數據分佈管理
我們也可以以二級分區的方式,同時支持數據維護和數據分佈的需求,通常使用比較多的場景為一級分區用於數據維護的需求,二級分區用於數據分佈的需求,每種需求可以使用對應需求所支持的方式進行組合。
典型的手動分區管理方式
- 一級分區:
- 類型選擇:使用 Range 或者 List 分區,匹配高頻查詢條件(如時間範圍、地區)。
- 分區數建議:根據查詢條件時間分佈、數據維護的需求設置合理範圍(如按月分區保留 12 個月,或按地區分為 4 個 List 分區)。
- 二級分區:
- 類型選擇: 使用Hash分區,保證數據打散。
- 分區數推薦:
- 如果只有一個一級分區寫入,那麼一級分區的二級分區數需要滿足寫入打散的資源訴求
- 如果有多個一級分區能夠寫入,那麼能寫入的一級分區數 * 二級分區數滿足寫入打散的資源訴求即可
以下是 Range + Hash 和 List + Hash 的兩個場景案例:
1.Range + Hash:一級選擇 Range 分區,指定 order_date 後,可以快速過濾掉不需要掃描數據的分區,也能夠通過分區管理操作快速進行數據維護,二級選擇 Hash 分區,可以將當月的寫入或者讀取打散到 8 個分區中,避免熱點。
CREATE TABLE orders( user_id BIGINT NOT NULL COMMENT '用户ID(二級分區鍵)', order_date DATE NOT NULL COMMENT '下單日期(一級分區鍵)', amount DECIMAL(10,2) NOT NULL COMMENT '訂單金額', status TINYINT NOT NULL COMMENT '狀態: 0-取消 1-待支付 2-已支付 3-已發貨 4-已完成', region_code CHAR(6) NOT NULL COMMENT '地區編碼(前2位省碼)', product_id INT NOT NULL COMMENT '商品ID', payment_method VARCHAR(20) COMMENT '支付方式', created_at TIMESTAMP(6) DEFAULT CURRENT_TIMESTAMP(6) COMMENT '記錄創建時間')PARTITION BY RANGE COLUMNS(order_date)SUBPARTITION BY HASH(user_id) SUBPARTITIONS 8( PARTITION p202501 VALUES LESS THAN ('2025-02-01'), PARTITION p202502 VALUES LESS THAN ('2025-03-01'), ... PARTITION p202601 VALUES LESS THAN ('2026-02-01'));
2.List + Hash:一級選擇 List 分區,指定省份能夠裁剪到相應的分區,也可以按照省維度進行數據維護,二級選擇 Hash/Key 分區,可以將省的讀寫流量打散到多個分區中,實現負載均衡。
-- 一級分區:LIST按省劃分(31個省級行政區)CREATE TABLE social_insurance_records( record_id BIGINT, province_code INT NOT NULL, -- 省級編碼(如11北京,31上海) payment_date DATE NOT NULL, user_id VARCHAR(32) NOT NULL, amount DECIMAL(10,2)) PARTITION BY LIST(province_code) -- 一級LIST分區SUBPARTITION BY KEY(user_id) SUBPARTITIONS 16 -- 二級HASH分區( PARTITION p_beijing VALUES IN (11), PARTITION p_shanghai VALUES IN (31), PARTITION p_tianjin VALUES IN (12), ... PARTITION p_xizang VALUES IN (54));
典型的自動分區管理方式
- 一級分區:選擇動態分區,配置按固定時間分區,預創建多長時間的分區和保留多久的歷史分區等參數;
- 二級分區:選擇自動 Range 分區分裂,能夠自動地進行分裂,無須配置分區個數或者分區規則。
總結
目前 OceanBase 支持了常見的基礎分區方式,通過基礎分區方式的組合使用,能夠滿足業務的數據維護、數據分佈以及提升查詢效率等需求。動態分區對按照時間進行分區數據維護的通用需求提供了標準的自動化管理能力,減少用户對數據維護的代價,未來我們將加強自動分區的管理能力,支持列存表的自動分區分裂,減少當前數據分佈手工維護的代價、可擴展性等問題,進一步提升列存表的數據管理自動化管理能力,使得分析型業務場景能更容易使用OceanBase。