

作者:傅榕鋒,OceanBase 高級技術專家
AI 開發者需要什麼樣的數據庫
在開始正式話題前,我們不妨先思考一個問題: AI 時代下開發者需要什麼樣的數據庫?
自本世紀初以來數據庫需求的演變歷程。Web 2.0及業務在線化的時代,強調的是一個可靠、精確的記錄系統,能夠精準地記錄每一筆交易數據,滿足典型的事務處理(TP)需求。進入移動互聯網和數據智能化時代後,隨着數據量的爆發式增長,海量數據分析的需求成為主流。這時,分析型(AP)數據庫開始佔據重要位置。AI 時代的真正到來,驅動數據庫不僅要支持查詢和分析功能,更需具備理解和推理的能力。
快來關注我,獲取 OceanBase 第一手的產品信息和技術資源,與行業大咖 “嘮” 出真知!
AI 時代開發者的痛點
作為數據庫從業者,我們需要深入分析 AI 時代下開發者對數據庫的具體需求。
數據類型的多維化:在傳統數據庫中,圖片、視頻、音頻僅能被存儲而難以有效利用。藉助 AI 模型的幫助,這些非結構化數據可以轉化為可檢索的形式,如通過嵌入模型轉換為向量,或使用大語言模型提取文本描述和標籤,從而將非結構化數據轉變為結構化或半結構化數據以實現高效檢索。
性能與規模的極致化:鑑於向量數據對內存和磁盤資源的高佔用特性,在成本與性能之間尋求最佳平衡顯得尤為關鍵。為此,亟需採用高效的算法,以優化召回率與資源成本之間的權衡關係。
智能處理的內生化:例如,在 RAG 場景中,文檔需先進行切片並生成向量,這通常涉及向量數據庫、文檔型數據庫以及事務型數據庫的聯合使用。為了簡化這一流程,理想的解決方案是讓數據庫自身承擔更多的標準化數據處理任務,減少開發者的負擔。
開發流程的敏捷化:目標是讓開發者更加專注於業務邏輯本身,而非陷入複雜的數據處理流程之中。
AI 時代的理想數據庫
基於上述痛點,AI 時代的理想數據庫應具備以下四個特徵。
- 多模態支持:提供統一的平台,支持多種數據類型,包括但不限於向量、全文、標量、 JSON 格式。
- 高性能引擎:針對 AI 工作負載進行優化,確保在控制成本的前提下實現最優性能表現。
- 智能化集成:內置 AI 運行時環境,使數據庫可以直接執行復雜的智能處理任務,減少對外部系統的依賴。
- 簡易操作:設計直觀易用的界面和工具,降低非專業開發者的使用門檻,促進更多領域專家參與到數據處理工作中。
綜上所述, AI 時代我們期待的數據庫應該是強大、智能、一體化的,是數據與 AI 融合的平台。
AI原生的一體化數據庫是否存在
正所謂“需求決定市場”,契合AI時代理想數據庫特質的產品必然會出現。而就目前來看,OceanBase 新發布的 seekdb 已率先落地,不僅具備了相關核心能力,更在快速迭代中持續進化。
混搜架構的輕量級、多模態的AI原生數據庫
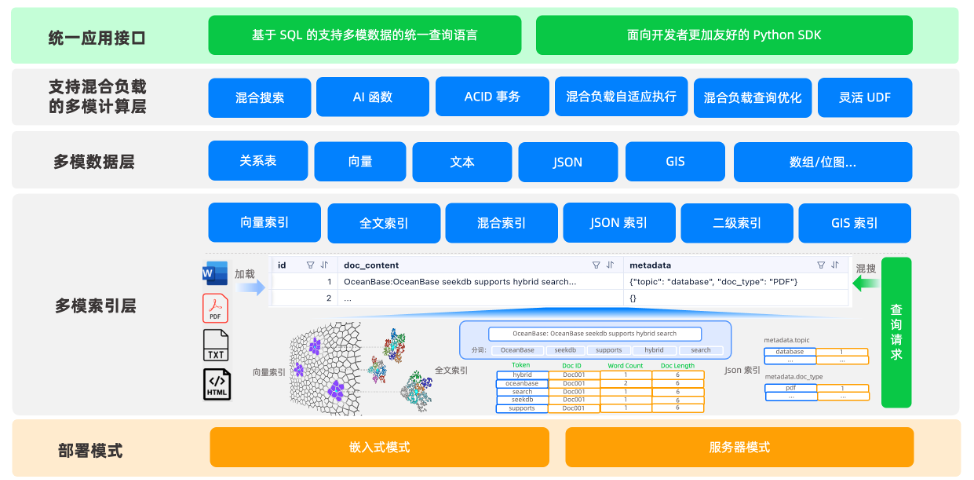
OceanBase seekdb 是一款面向 AI 場景的輕量級、多模態的原生數據庫,專為支持混合搜索、上下文理解與智能數據處理而設計。其整體架構分為五個核心層級,實現從數據存儲到查詢執行的全鏈路優化。
1. 統一應用接口層。
seekdb提供基於 SQL 的統一查詢語言,兼容標準 SQL 語法,支持多模態數據的聯合查詢。同時,提供面向開發者的 Python SDK,具備簡潔易用的 API 接口,支持 skip-by-list 等高效檢索模式,顯著降低開發者使用門檻。
2. 支持混合負載的多模計算層。
繼承自 OceanBase 的成熟優化器體系,seekdb具備強大的查詢規劃與執行能力,在混合檢索場景中,會自動進行自適應執行和查詢優化,能夠根據查詢條件自動選擇最優執行路徑。同時,支持混合負載自適應執行、AI 函數調用、ACID 事務保障及靈活 UDF 擴展,滿足複雜業務需求。
3. 多模數據層。
支持多種數據類型統一存儲,實現“存即能檢”,打破傳統系統中不同數據類型需分庫管理的侷限。包括:
- 關係表(傳統結構化數據)
- 向量(Embedding 向量)
- 文本(原始文本內容)
- JSON(半結構化數據)
- GIS(地理空間數據)
- 數組、位圖等擴展類型
4. 多模索引層。
構建業界領先的多模索引體系,支持的索引類型如下。
- 向量索引:高效支持近鄰搜索(ANN),兼顧精度與性能。
- 全文索引:支持中文分詞與語義匹配。
- 混合索引:結合向量與標量條件進行聯合檢索。
- JSON 索引:加速嵌套字段查詢。
- 二級索引、GIS 索引:滿足多樣化查詢需求。
支持多索引協同查詢,在一次請求中完成跨模態數據的融合檢索。
5. 部署模式層。
- 服務器模式:傳統集羣部署,適用於高併發、大規模生產環境。
- 嵌入式模式:以庫的形式內嵌於應用程序中,生命週期與應用一致,適合邊緣計算、AI 應用快速構建等輕量化場景。
OceanBase seekdb 通過“統一接口 + 多模存儲 + 智能索引 + 靈活部署”的一體化設計,實現了對 AI 工作負載的端到端支持,真正做到了“一個數據庫,搞定所有數據”。
快速構建:更靈活、更輕量、不止於 SQL
OceanBase seekdb 不僅具備強大的功能,更在易用性和部署靈活性上進行了深度優化,助力開發者快速構建 AI 應用。
1. 更靈活:雙運行模式,適配多樣場景。
- 服務器模式:適用於企業級、高可用、分佈式部署。
- 嵌入式模式:直接集成到 #Python 應用中,無需獨立部署數據庫服務,極大簡化開發流程,特別適合 RAG、Agent、智能問答等輕量級 AI 應用。
2. 更輕量:極簡資源佔用,輕鬆跑起基準測試。
單實例僅需 1C2G 內存即可運行 VectorDBBench 基準測試,相比傳統數據庫,資源消耗更低,啓動更快,非常適合本地調試、原型驗證和邊緣部署。
3. 不止於 SQL:引入 Schemaless SDK。
引入 Schemaless SDK,開發者無需定義表結構即可直接插入和查詢數據,提升開發靈活性。
使用seekdb快速創建RAG應用
下面我們演示一下如何使用 seekdb 快使創建一個 RAG 應用。
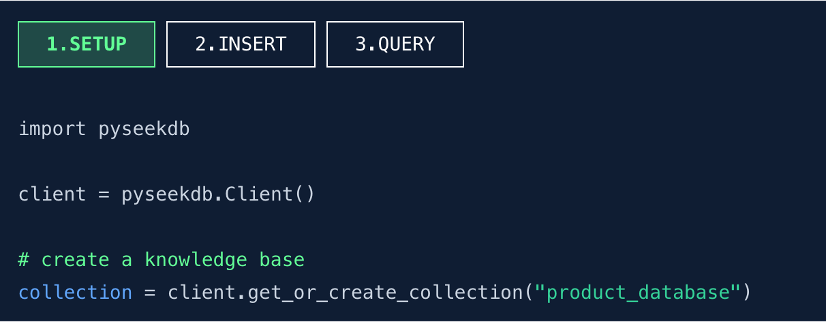
第一步:三行代碼快速創建一個知識庫(SETUP)
- 導入 pyseekdb 模塊,啓用 seekdb 的 Python SDK。
- 初始化客户端實例,參數為空表示採用嵌入式模式,數據庫生命週期與應用綁定,無需獨立部署服務。
- 創建知識庫並定義為 Collection。
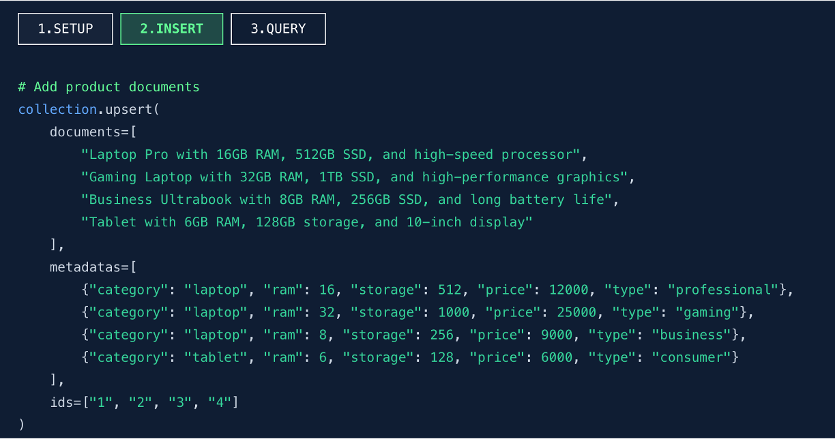
第二步:批量插入文檔片段(INSERT)
功能説明:
- 調用 upsert() 函數批量插入文檔內容(documents)。
- 同時關聯元數據(metadatas),包括分類、內存、存儲、價格等結構化信息。
- 顯式指定文檔 ID(ids),便於後續檢索與更新。
關鍵特性:
- 用户僅需提供原始文本和元數據,無需手動調用嵌入模型生成向量。
- 數據庫內部自動調用內置的嵌入模型,將文本轉換為向量並存儲。
AI 能力下沉至數據庫,開發者無需關注向量化過程,seekdb 自動完成文本 → 向量的轉換,實現“透明化”處理。
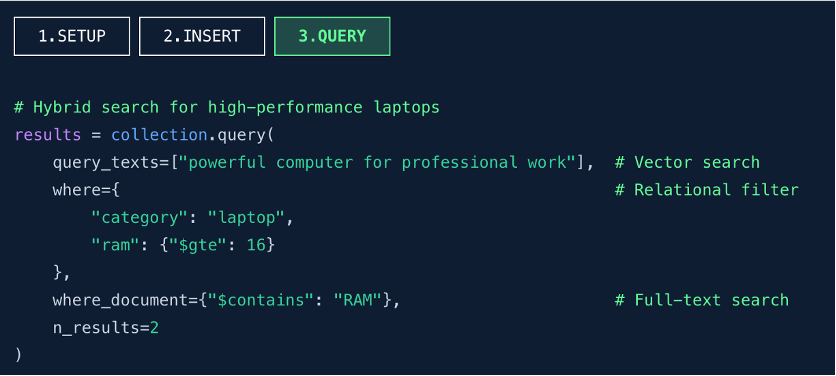
第三步:混合檢索,精準召回(QUERY)
查詢維度分析:
- query_texts:輸入自然語言文本,觸發向量檢索,用於語義匹配。
- where:設置關係型過濾條件,如 category == laptop 和 ram >= 16,實現精確篩選。
- where_document:基於全文索引進行關鍵詞匹配,要求文檔內容包含 “RAM”。
- n_results:限制返回結果數量為 2 條。
實現機制:
- 查詢時,seekdb 內部自動將 query_texts 輸入傳遞給嵌入模型,生成查詢向量。
- 結合向量索引、全文索引、二級索引等多種索引執行混合檢索。
- 最終返回滿足所有條件的最相關結果。
第四步:效果展示
輸入檢索條件為:需要一個 12 GB 內存以上的高性能筆記本。運行後輸出結果如下圖所示,
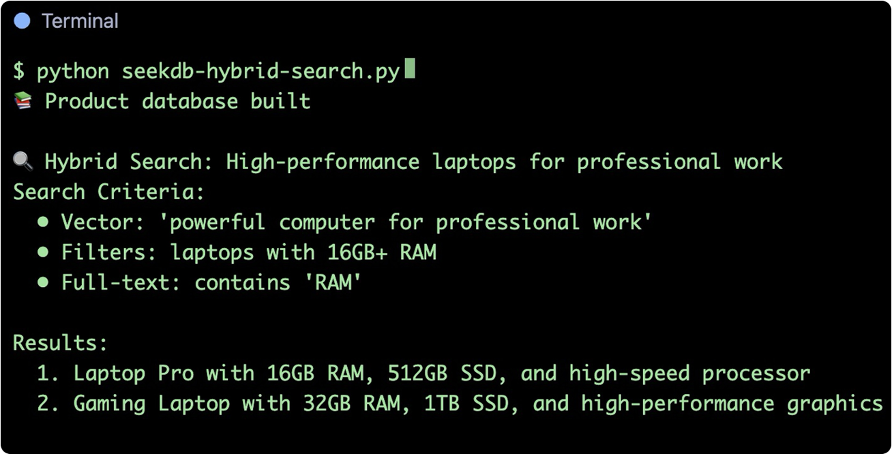
召回結果分析如下。
- 第一條:16GB 內存、512GB 固態的專業筆記本,完全滿足“高性能 + 16GB 以上內存”的要求。
- 第二條:32GB 內存、1TB 固態的遊戲本,雖非專業用途但性能卓越,符合語義意圖。
該案例模擬了典型的 RAG 場景,用户只需輸入自然語言問題,系統即可自動完成文本向量化、多條件聯合檢索、高精度召回。全流程由數據庫內核統一處理,極大簡化了開發複雜度,真正實現“讓開發者專注於業務,而非數據處理”。
歡迎親自上手試用:https://github.com/oceanbase/seekdb。當前版本支持 Linux 平台下的嵌入式模式運行,Windows 和 macOS 版本將在近期和大家見面。可訪問 oceanbase.ai 獲取樣例代碼,支持本地測試與快速驗證。
SQL 直接調用 AI 的原生體驗
OceanBase seekdb 不僅是一個支持多模態數據存儲與混合檢索的數據庫,更致力於將 AI 能力深度集成於數據庫內核,實現“SQL 直接調用 AI”的原生體驗。
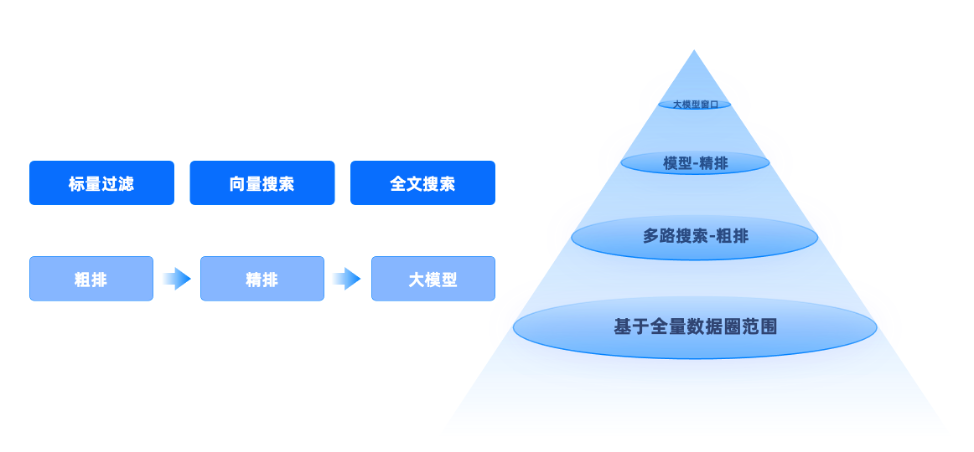
seekdb AI Inside 的內置處理除了 AI_EMBED 方法外,還引入 AI_RERANK 和 AI_COMPLETE,可以實現數據分析自動化、特徵提取、智能內容生成、語義搜索增強、結果優化等效果。在 seekdb 中使用可以構建從粗排到精排的高效分層混合檢索處理流程。該流程分為四個階段。
階段1:標量過濾(Scalar Filtering)。在全量數據集上首先執行關係型條件過濾(如 category = 'laptop', ram >= 16),縮小候選集過濾範圍。
階段2:向量搜索(Vector Search)。對過濾後的候選集執行向量相似度檢索,基於語義匹配找出最相關的文檔,使用近鄰搜索算法(ANN)高效完成高維向量比對。
階段3:全文搜索(Full-text Search)。在候選集中進一步執行關鍵詞匹配,確保結果包含用户關心的關鍵信息(如 "RAM"),支持中文分詞與模糊匹配,提升召回精度。其中標量、向量、全文的過濾順序取決於優化器。
階段4:粗排 → 精排 → 大模型重排。經過以上過濾後得到粗排的結果,此時再去調用 AI_RERANK,數據庫會直接調用 RERANK 模型進行精排,精排結束後,通過調用 AI_COMPLETE 即可調用大模型,大模型會直接進行回答。以上所有的 AI 標準操作流程都在數據庫中進行,開發者只需在查詢中添加相應函數,即可讓數據庫自動調用大模型對數據進行處理,顯著提升用户體驗。
OceanBase seekdb 適用場景
OceanBase seekdb 作為一款輕量級、多模態、AI 原生的數據庫,憑藉其統一存儲、混合檢索、內嵌 AI 能力 和嵌入式部署支持,在多個新興與傳統智能化場景中展現出顯著優勢。以下是其典型的適用場景。
1.替代“三庫並行”,降本增效
在 RAG 架構中,傳統方案通常需要同時維護三類數據庫。
- 向量數據庫存儲文本嵌入向量。
- 文檔數據庫保存原始文本內容。
- 關係型數據庫管理元數據(如分類、時間、權限等)。
這種“三庫並行”模式不僅帶來高昂的運維複雜度,還導致資源重複佔用(三份獨立實例),難以在資源受限的本地或邊緣環境中落地。seekdb 通過單一數據庫統一承載向量、文本與結構化元數據,實現一次寫入,多路索引(向量索引 + 全文索引 + 二級索引)、統一查詢接口,支持混合條件過濾、極低資源開銷(1C2G 即可運行),適合個人本地知識庫、中小企業內部知識管理系統、邊緣側智能問答應用等。
2.語義搜索引擎,打破模態壁壘
seekdb 的多模態能力使其天然適配跨模態語義搜索場景。無論是文本、圖片、音頻還是視頻,均可通過嵌入模型轉化為統一的向量表示,並結合元數據進行聯合檢索,通過統一向量 + 元數據 + 全文的混合檢索框架,打破模態壁壘。典型應用包括:以圖搜圖、音頻內容檢、視頻片段語義匹配、多媒體資產管理系統。
3.Agentic AI 應用,保證數據一致性
在 Agentic AI(智能體)場景中,Agent 需要頻繁執行上下文感知的混合檢索,比如結合用户歷史行為(標量過濾)、匹配任務目標語義(向量搜索)、檢索相關文檔片段(全文匹配)。seekdb 的原生混合檢索引擎與內嵌 AI 函數能夠高效支撐此類複雜查詢,避免外部服務調用帶來的延遲與一致性問題。適用於任務型對話系統、自主決策機器人、智能工作流引擎等應用場景。
4.AI 輔助編程,提升質量,降低成本
AI 編程助手存在雲端 + 客户端雙端檢索需求,傳統方案面臨兩大挑戰。
- 架構割裂:雲端使用多源召回(向量+全文+語法樹),客户端依賴輕量插件(如 SQLite + 向量擴展),兩套系統邏輯不一致。
- 性能瓶頸:通用數據庫缺乏專業向量索引與優化器,召回效果與效率受限。
seekdb 提供統一的 SDK 與查詢接口,可使雲端與客户端使用同一套 API,且客户端在嵌入式模式下仍具備專業級向量檢索能力。seekdb還支持代碼語義搜索、API 推薦、錯誤修復建議等高級功能。通過這些能力統一技術棧,提升召回質量,降低雙端開發與維護成本。
5.企業應用智能化絲滑升級
對於大量仍在使用 MySQL 的傳統企業應用,seekdb 提供了一條平滑演進路徑:
- 高度兼容 MySQL 協議,現有應用可無縫遷移。
- 遷移後即可獲得 向量檢索、全文搜索、JSON 支持等 AI 原生能力。
- 為未來引入 RAG、智能報表、自動化分析等 AI 功能奠定數據基礎。
因此,MySQL 到 OceanBase 的遷移是“最絲滑”的路徑之一。seekdb 作為其輕量化延伸,進一步降低了企業智能化轉型的技術門檻。
6.端側應用智能化的理想選擇
隨着終端設備算力提升,越來越多智能應用向端側遷移。seekdb 的嵌入式部署能力使其成為端側智能數據庫的理想選擇:
- 資源佔用極低(1C2G 可運行)。
- 支持離線向量檢索與語義理解。
- 生命週期與應用綁定,無需獨立服務進程。
- 讓端側應用具備“本地大腦”,減少對雲服務的依賴。
典型場景包括:
- 智能家居設備中的本地知識問答。
- 工業機器人中的實時故障診斷。
- 移動端個人助理的上下文記憶管理。
- 車載系統的本地語義導航。
從輕到重、從簡到繁: AI 應用快速迭代的理想基礎設施
在 AI 應用快速迭代的背景下,開發者面臨從原型驗證、開發測試到生產部署的多階段需求。OceanBase 與 seekdb 的深度融合,構建了一套覆蓋全生命週期、支持平滑演進的彈性數據庫架構,能夠滿足不同階段、不同規模場景下的靈活部署需求。
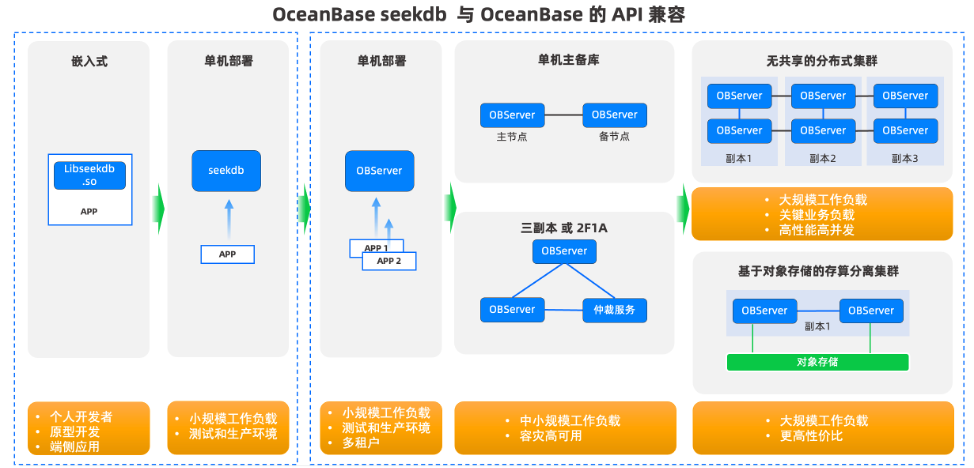
原型驗證與開發測試階段:嵌入式模式(seekdb)
在項目初期,開發者通常需要快速驗證 AI 模型效果或構建最小可行產品(MVP)。此時可採用 seekdb 嵌入式模式:
- 將 libseekdb.so 動態庫直接集成至應用中,作為本地數據庫運行。
- 數據庫生命週期與應用綁定,啓動即用,關閉即銷燬。
- 無需獨立部署服務,極大簡化環境搭建流程。
- 支持向量、文本、JSON 等多模態數據存儲與混合檢索。
嵌入式模式適用於個人開發者快速原型開發、端側智能應用(如移動端、機器人)、本地調試與算法驗證等場景。
測試與小規模生產環境:單機部署模式
當應用進入測試或小規模上線階段,可遷移到單機部署模式:
- 啓動獨立的 seekdb 進程,提供服務端接口。
- 支持多客户端連接,適合團隊協作開發。
- 可通過配置文件管理數據路徑、內存參數等。
- 仍保持與嵌入式模式的 API 兼容性,代碼無需變更。
單機部署模式適用於小型工作負載、測試環境與生產環境、多租户需求等場景。
生產環境:多租户與高可用架構
隨着業務穩定運行,需考慮資源隔離、高可用性和容災能力,此時可選擇以下兩種生產級部署方式。
- 單機多租户模式(OceanBase 單機部署) :
- 使用 OceanBase 單機實例,通過多租户機制實現多個業務之間的資源隔離。
- 適用於多個業務共享同一數據庫實例但需獨立管理資源的場景。
- 支持獨立的配額控制、備份策略和監控告警。
- 主備模式 / 三副本模式(OceanBase 高可用架構):
- 採用主備架構或三副本(2F1A)架構,保障數據高可用。
- 支持自動故障切換與讀寫分離。
- 適用於對穩定性要求較高的中小規模業務系統。
多租户與高可用架構適用於中小規模工作負載、對容災和高可用有明確要求的業務、多租户共用數據庫的 SaaS 平台等場景。
大規模與高性能場景:分佈式集羣架構
當業務持續增長,數據量和併發請求激增時,可進一步擴展為分佈式集羣架構。
- 無共享分佈式集羣 :
- 由多個 OBServer 節點組成,支持水平擴展。
- 支持大規模工作負載、關鍵業務高併發訪問。
- 具備強一致性、線性可擴展性與動態擴容能力。
- 基於對象存儲的存算分離集羣:
- 存儲層使用對象存儲(如 OSS),計算層由 OBServer 提供。
- 實現“冷熱數據分離”,降低存儲成本。
- 適用於海量非敏感數據分析場景(如日誌分析、歷史歸檔)。
- 提供更高的性價比與更強的擴展能力。
分佈式集羣架構適用於大規模工作負載、關鍵業務系統、高性能高併發、更高性價比的大數據處理任務等場景。
OceanBase 與 seekdb 的組合形成了一個 “從輕到重、從簡到繁” 的完整彈性架構體系,核心優勢有如下三點。
- API 完全兼容:無論選擇哪種部署模式,業務代碼無需修改;
- 配置驅動升級:只需更改連接地址與配置參數,即可完成架構遷移;
- 平滑演進路徑:支持從個人開發到企業級生產的無縫過渡。
這使得 OceanBase + seekdb 成為 AI 應用快速迭代的理想基礎設施,真正實現了“一次開發,全棧適配”,助力企業在 AI 時代加速創新落地。
當然,在AI時代,AI數據庫不足以支撐應用所需的完整基礎設施能力,因此,OceanBase構建了上下文工程體系中的關鍵能力。讓我們敬請期待下一篇文章。