

物格而後知至。
——《禮記》
楔子
OceanBase 最近發佈了 seekdb 數據庫,主打 “輕量 + 向量 + AI”。
在 seekdb 發佈之後,陸續收到了許多用户關於 seekdb 中向量索引在使用上的一些問題,比如:索引創建耗時慢優化問題,創建時對內存的要求,增量達到什麼規模需要重建,重建性能影響怎麼消除等等等等。

因此,向量索引的研發同學夏進大佬,今天就專門在這篇文章中,從 OceanBase / seekdb 向量索引的構建過程開始講起,為大家深入且詳細地分析上述問題。有任何疑問歡迎大家留言提問~🙋
向量索引的構建過程
很多同學會發現,只創建了一個向量索引,卻發現多出來一堆輔助表。
CREATE TABLE t1(
c1 INT,
c2 VECTOR(10),
PRIMARY KEY(c1),
VECTOR INDEX idx1(c2) WITH (distance=l2, type=hnsw, lib=vsag));
select
table_id,
table_name,
table_type
from oceanbase.__all_table
where database_id = 500001;
+----------+---------------------------------------------+------------+
| table_id | table_name | table_type |
+----------+---------------------------------------------+------------+
| 500055 | t1 | 3 |
| 500061 | __AUX_LOB_META_500061_ | 13 |
| 500062 | __AUX_LOB_PIECE_500062_ | 12 |
| 500056 | __idx_500055_idx1 | 5 |
| 500059 | __idx_500055_idx1_index_id_table | 5 |
| 500060 | __idx_500055_idx1_index_snapshot_data_table | 5 |
| 500057 | __idx_500055_rowkey_vid_table | 5 |
| 500058 | __idx_500055_vid_rowkey_table | 5 |
+----------+---------------------------------------------+------------+
8 rows in set (0.01 sec)
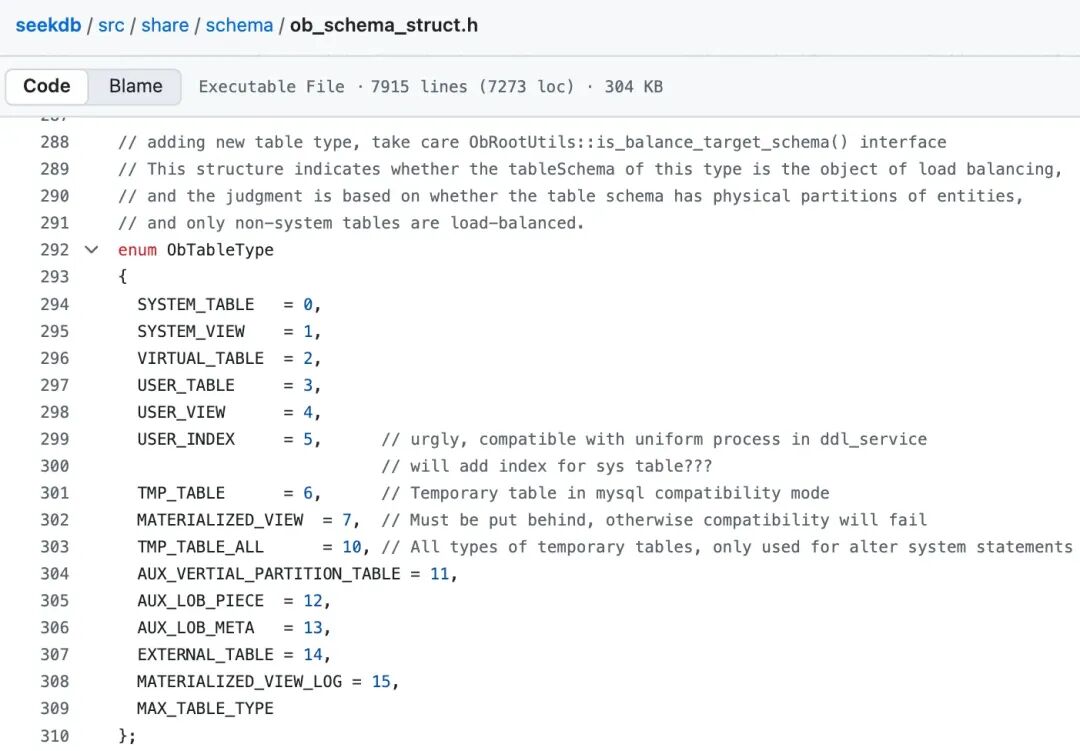
table_type 的含義詳見:seekdb 開源項目代碼[2],這裏只截一張圖,不再細説。
向量索引的組成
在瞭解向量索引構建過程前,需要先了解整個向量索引的組成部分,以 HNSW(Hierarchical Navigable Small World) 索引為例,包含內存索引和磁盤索引兩部分。
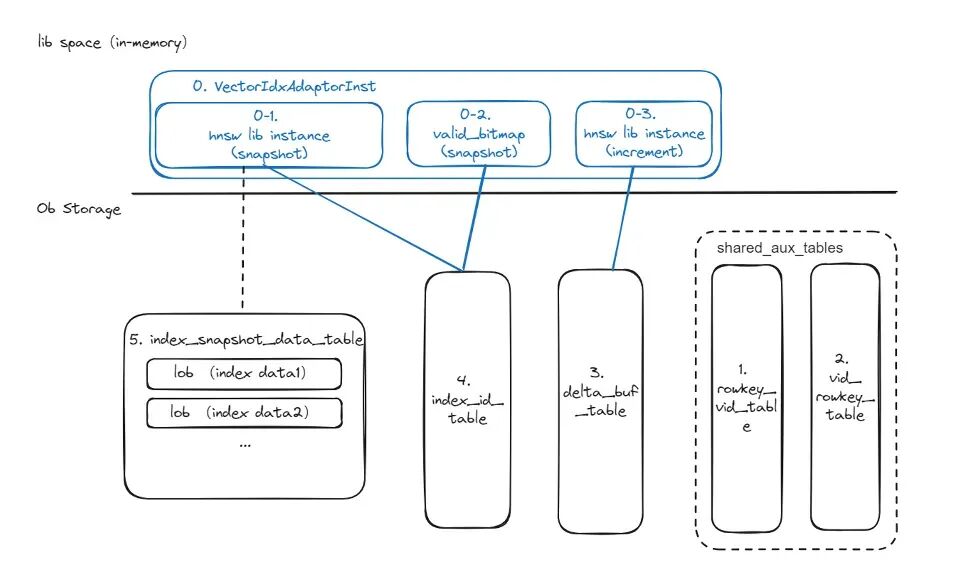
上圖的上半部分藍色的是內存索引的結構,由三部分組成,分別是 snapshot 快照索引(0-1)、increment增量內存索引(0-3)、valid_bitmap 內存結構(0-3),共同構成了向量索引的內存組成部分。
下半部分黑色的是磁盤索引,包含五個輔助表:
- 1 號表 rowkey_vid_table 用於保存 rowkey 和 vid 的映射關係。
小編理解,意思是 1 號表用於記錄主表主鍵和 vid 的對應關係,vid 的含義是 vector id,其實解釋成 vector index value id 會更清楚一些。
- 2 號表 vid_rowkey_table 保存的內容和 1 號表相同,存在的原因是在某些應用場景,例如查詢場景,為了便於得到 vid,並根據 vid 得到 rowkey。
小編理解,意思是 2 號表的作用是向量索引查詢完成後,通過 vector_id 找到 rowkey 進行回表。
1 號表和 2 號表都有兩個相同的列(rowkey + vid),區別是 1 號表的主鍵是主表主鍵 rowkey,2 號表的主鍵是 vid。
- 3 號表 delta_buffer_table 主要用於承接外部對主表進行 DML 操作的增量數據寫入,數據會直接寫到 3 號表中。
小編理解,3 號表主要是用於記錄發生更改的 VectorID 和 Type,Type 只有兩種:'I' 表示新增, 'D' 表示刪除,每個 ID 至多被寫入一次和刪除一次。
- 4 號表 index_id_table 實際上是 3 號表的超集,包含了不同時間段的三號表數據,會有一個後台用户定期將 3 號表的數據刷新到 4 號表中去,目的是為了提升在某些大數據量場景的查詢效率,例如賬單場景,由於歷史數據龐大,如果直接對 3 號表進行全表掃描,耗時會比較長,定期將 3 號表的存量數據導入到 4 號表後,3 號表會始終維持在一個比較穩定的低數據量水位,從而提升查詢效率。
- 5 號表 index_snapshot_data_table 用於保存向量數據,這些向量數據首先會被寫到一個 Lob Meta 表中,Lob Meta 表寫完後,會將 Lob Meta 表對應的每一段的地址,存儲到 5 號表中。總而言之,5 號表用於保存索引的向量數據。
小編理解:
1 ~ 2 號表,因為和主表主鍵都有關係,所以是共享輔助表,由一張表上的所有向量索引共用。
3,4,5 號表,是每個向量索引獨佔的索引輔助表,也都有 vid 列。
後面這三張表,感覺大家不需要細究其作用,可以簡單理解成:向量數據維數限制很寬,所以需要用 LOB 這種大對象進行存儲。大對象不能反覆存儲,所以只在 5 號表裏存儲了一份,其他表都是用來保證向量索引中大對象的更新和查詢效率的。
向量索引構建流程
在瞭解完索引輔助表在內存和磁盤上的整體結構後,我們來了解下索引表的構建流程。
首先需要創建上文中提到的 5 個輔助表以及對應內容,當前在創建輔助表的過程中,使用的是 OceanBase DDL 框架,主要以 DDL task 的形式實現。對於一個 DDL task 來説,主要是以狀態機的形式進行實現,推進每一個狀態的執行以及切換,處理不同輔助表的創建過程。
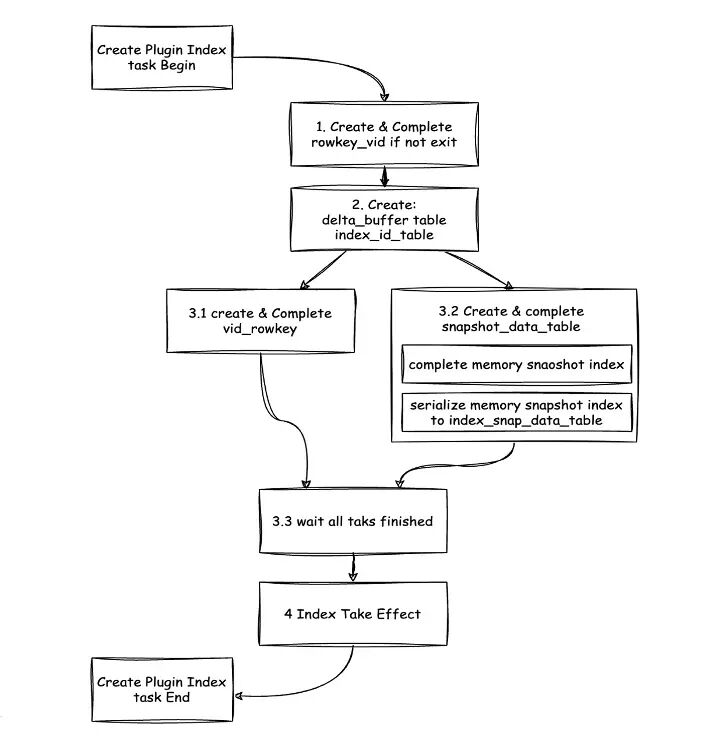
在狀態機中流程共有三步。
- 第一步,創建 1 號表 rowkey_vid table。如果該表已存在,可直接跳過,如果不存在,會直接創建 1 號表的 Schema、再在表中補全數據,該狀態結束後會進入到下一個狀態。
- 第二步,創建 3 號表 delta_buff_table 和 4 號表 index_id_table。在該創建過程中,不需要進行數據補全,因為後續創建 5 號表 index_snapshot_data_table 時,會將數據統一導入到 5 號表中,因此 3 號表和 4 號表不需要再進行補全數據操作。3 號表創建完成後,即可開始寫入外部 DML 操作的增量數據。
- 第三步,創建 2 號表 vid_rowkey_table 和 5 號表 index_snapshot_data_table。創建 2 號表的過程和創建 1 號表過程類似,需要先創建 Schema、再補全數據。創建 5 號表的過程和上述流程都不太一樣,需要同時創建內存索引和磁盤索引,會先將數據添加到內存增量索引中,數據補齊後,再將內存索引中的數據反序列化到 5 號表中,共包含了兩個步驟。
待上述流程全部完成後,即進入索引生效狀態,然後將索引創建流程結束,即可開始使用。
構建流程中的狀態推進
對於 DDL task 的執行流程,主要以狀態機的形式來進行流程處理。主要邏輯是根據當前的狀態,進行對應狀態的處理,以及對下一個狀態的轉移。可能會有用户感到疑惑,為什麼要引入索引狀態機?
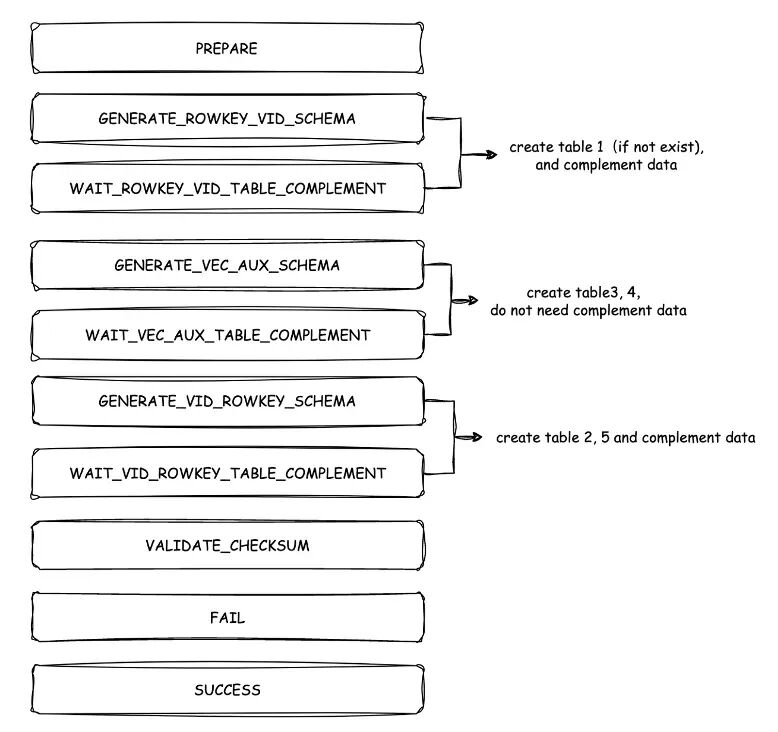
利用狀態機的好處主要有兩點:一是流程可視化,二是狀態持久化。
考慮到可能存在一些異常場景,例如 LS(LogStream) 切主,或者重啓、宕機等。在這些異常場景下,如果當前在進行 5 號表的補數據流程,在過程中發生了切主或重啓,在場景異常恢復正常後,只需要從五號表到進行中狀態繼續往下進行,而不需要從頭再進行一遍,以提高異常場景下的容錯能力。
構建性能和內存分析
耗時點分析
通過兩張圖,來分析一下索引構建過程中的耗時點。

圖中集羣的本地數據量為 2000 萬,在該集羣創建構建索引,通過查詢內部表 __all_rootservice_event_history 得出構建索引每個狀態的對應耗時,可以看出:
- WAIT_VID_RPWKEY_TABLE_COMPLEWEMT 的狀態耗時從 10 點 53 分一直到 14 點 28 分,中間經歷了約 3.5 小時。
- 其他狀態的耗時均為幾分鐘。
因此,整個構建索引過程大部分耗時都集中在 WAIT_VID_RPWKEY_TABLE_COMPLEWEMT 狀態中。

通過查詢內部表 __all_rootservice_event_history 的 WAIT_VID_RPWKEY_TABLE_COMPLEWEMT 狀態下對應表的構建子任務的狀態和耗時可以看出:耗時比較久的是 REDEFINITION 狀態,耗時為 3.5 小時,基本接近上文 WAIT_VID_RPWKEY_TABLE_COMPLEWEMT 狀態的耗時,也就是説WAIT_VID_RPWKEY_TABLE_COMPLEWEMT 狀態的耗時點在 REDEFINITION 狀態。
構建耗時分析
小編劃重點:
從這裏開始的內容,一定要看下!
推薦收藏,以備不時之需~
GV$SESSION_LONGOPS 視圖用於展示集羣 DDL 操作的執行狀態和進度,從該視圖中可以得出構建過程的各個狀態。
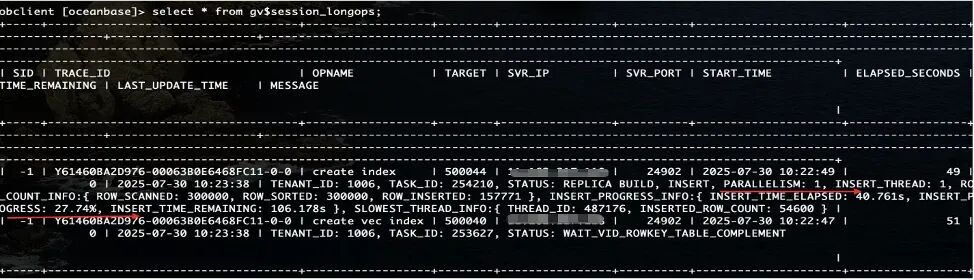
首先需要關注並行度。圖中的並行度 PARALLELISM 為 1,也就是説同時進行的構建過程只有一個,構建過程中的補數據操作的並行度也是 1,因此該場景下的後鍵過程是比較慢的,也就是説造成構建慢的很重要因素是沒有開並行。
第二個因素是補數據過程中的採樣點。
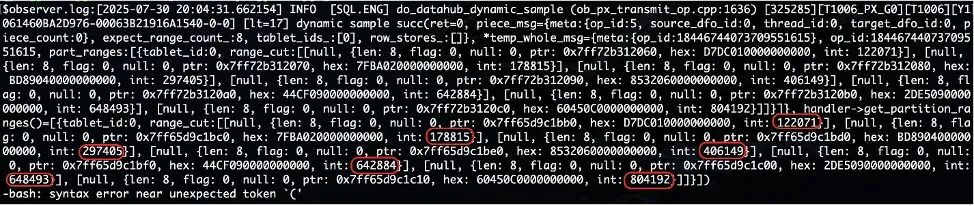
上圖是紅框為每個採樣點的數值,第一個採樣點是 122000,第二個採樣點是 178000,第三個採樣點是 297000,第四個採樣點是 406000,第五個採樣點是 642000,第六個採樣點是 648000。
第二個採樣點和第一個採樣點的值相差 5 萬左右,因此第一個分片有 5 萬左右的數據。
以此類推:第二個分片有 12 萬左右的數據,第三個分片有 11 萬左右的數據,第四個分片有 20 萬左右的數據,第五個分片只有 0.6 萬左右的數據,從第三個分片開始,採樣的數據量差距越來越大,到第五個分片卻只有 0.6 萬數據。
可以得出一個結論:採樣可能不均衡。
那麼這些分片是什麼意思,然後他在構建過程中是有什麼用呢?
OceanBase 在補數據的過程中,利用了 PX 並行框架,可在創建索引時指定使用的線程數。上文補數據過程中並行度為 1,可能是在創建索引時未加 Hint,未指定並行度,導致只使用了一個線程進行補數據操作。
假設開 10 個線程用於補數據,PX 框架中會先把一些數據採樣出來,由於每個分片大小不一樣,同時補數據是按照線程處理分配的,假設有十個數據,對應十個分片,每個線程處理一個分片的數據。如果採樣不均衡,可能會存在某個分片的數量特別大,某個分片的數量特別小。
例如現在有 100 萬的數據,指定 10 個線程數,分成 10 個分片。可能第一個分片處理了 99 萬數據,第二個分片或剩下的分片只處理了幾千的數據。最終導致大部分時間都消耗在了第一個線程中,造成整個構建效率索引不高,因此第二個創建索引耗時的影響因素是採樣不均。
第三個造成後鍵索引速度慢的原因是:單條寫入慢。如果表是非分區表,在對非分區表補數據時,相當於只有一個內存索引。假設內存索引存儲了 100 萬數據,在做補數據時,會將全部 100 萬的數據寫入一個分區內。HNSW 索引是 HNSW 的圖結構,插入索引時,如果圖的數據量越大,在搜圖的耗時就越長。可能在插入到 90 萬條數據後,插入速度已經變得非常緩慢。如果將表改為分區表,例如將 100 萬的數據平攤到 10 個分區中,相當於在使用並行,此時插入效率會比一個分區快很多。
因此,構建索引慢的優化方法有:加並行、提高採樣率、改分區表三種。
內存分析
通過查詢 __all_virtual_vector_index_info 類目表,可以得出幾個關鍵信息。

內存索引主要由三個部分組成,分別是:
- 增量索引內存
- 快照索引內存
- Vbitmap 內存
其中內存佔用大部分在增量索引內存和快照索引內存,因此主要需要優化這兩部分的內存佔用。
導致內存佔用高的階段主要可能有構建過程中的內存佔用和建完後的 DML 和持久化操作。
內存佔用分析及優化建議
關於內存佔用分析,有如下幾個場景的優化建議。
- 場景一:增量內存佔用高。
- 定期 Rebuild 重建索引。例如構建索引已經創建完成,並持續進行了較長時間的 DML 操作,此時如果發現內存索引的佔用率比較高,即增量內存佔用高,可以手動觸發定期 Rebuild 重建索引。如果不手動觸發,後台會默認每 24 小時進行一次。Rebuild 重建索引是一個比較好的降低內存使用的手段。
- 場景二:Follower 副本內存佔用(不支持弱讀場景)。
- 如果場景不需要支持弱讀,可以通過調整參數將 Follow 副本的內存佔用刪除。假設有多個節點,包含 Leader 副本和 Follower 副本,如果不需要在 Follower 副本查數據,可以直接把 Follower 副本上的加載內存索引關掉,從而節省一半的內存空間。
- 場景三:使用非 BQ 索引。
- 建議使用 HNSW BQ 索引替換原生 HNSW 索引,相當於把 float(32 位浮點數)改成 Bit 存儲,使得實際上的向量內存佔用大大降低,從而解決HNSW 索引內存佔高的問題。
除此之外,建議使用內存預估提前規劃好內存。針對目前一些客户的反饋問題,例如在後期過程中,如果發現內存不足導致報錯、卡住等現象,可以在建內存索引前使用工具預估內存,例如 OceanBase 官方提供的 DBMS 工具,進行預估內存、提前規劃,即可避免後續出現相關報錯。

內存預估能力會在 OceanBase V4.3.5_BP3 之後的版本支持。
構建性能和內存優化建議
綜上所述,構建速度優化和構建內存優化的方式總結如下。
構建速度優化
- 禁止每日合併(合併會佔用大量的 CPU 資源) alter system set major_freeze_duty_time = 'disable';
- 調高 DDL 補數據的執行優先級(默認 2,最高 8): alter system set ddl_thread_score = xxx;
- 調大 PX 執行線程池線程數(設置比並行度大) set global parallel_servers_target = xxx;
- 提高 PX 補數據採樣階段採樣數(默認 200,上限是 100000,如果數據量比較大,可以調整為 5000,但並非越大越好,可能會增加時間開銷) alter system set _px_object_sampling = 5000;
構建內存優化
- 多副本下,禁止 Follower 節點加載內存索引 alter system set load_vector_index_on_follower = false;
- 禁止構建時創建內存索引 構建時只創建索引輔助表,不創建內存索引,在其他的後台任務或第一次查詢的時加載回來。 alter system set vector_index_memory_saving_mode = true;
重建原理和內存分析
重建目的
隨着 DML 操作帶來的更新數據變多,查詢內存增量索引和 valid_bitmap 的代價變大,重建的目的是減少增量索引的內存佔用和查詢代價。
重建原理
重建索引的原理其實很簡單,即新建一個同名索引表,完成數據導入後,再刪除舊索引,再交換索引名,使新索引生效。下圖是重建索引的框架圖,如圖所示,是從 RS 中做驅動,執行 DDL 任務的流程,最終完成索引的創建。
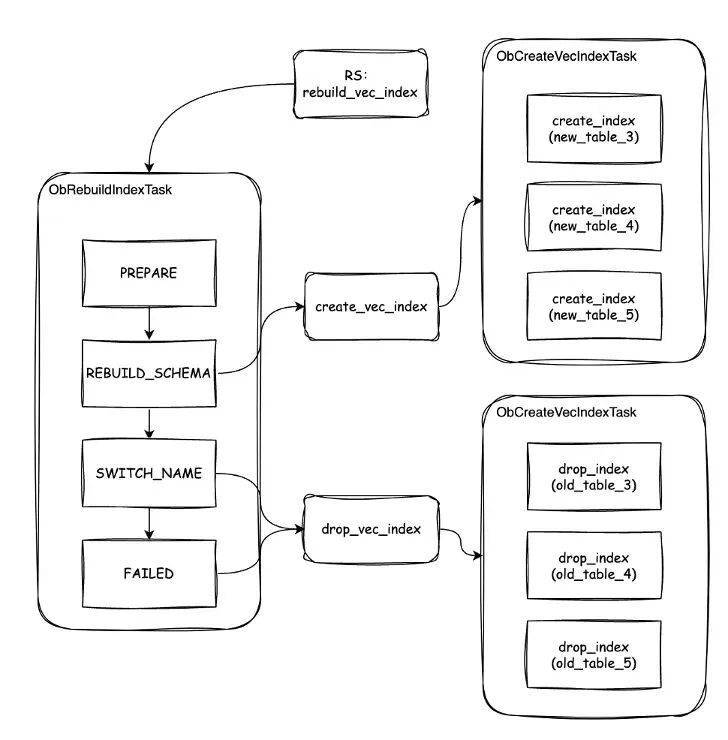
重建語法
REBUILD_INDEX 過程用於全量刷新(即重建)向量索引,觸發重建索引的語法為(不設置並行度):call dbms_vector.rebuild_index('idx1','t1','c2')。

更多介紹可參見文檔:OceanBase 官方文檔 —— REBUILD_INDEX[3]。
重建場景
重建索引是表級別的 Rebuild,較為耗時,一般建議增量數據佔比超過快照數據的 20%,或者查詢時出現 3 號表的數據訪問熱點時,選擇重建。建議在 CPU 和內存空閒的時間段進行。
重建過程中的內存佔用
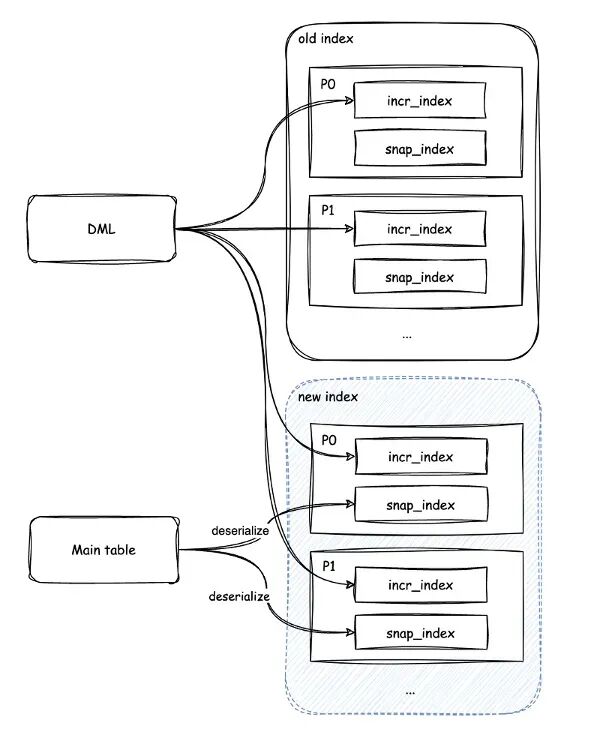
由於重建索引過程中會同時存在新舊兩個索引,因此內存佔用最大可能會是原來索引的 2 倍,重建完成後內存下降新索引內存水位。該過程有一些可用的優化手段,因為在做構建索引時,補數據是按照分區進行的,即不是一下補所有分區,而是一個分區一個分區進行,可以在某個分區重建索引好,立即將原內存索引刪除。例如有一個分區表,有 10 個分區,原索引佔用了 10G 內存,在資源有限的情況下,可以只預留 11G 或 12G 的內存空間,每次只進行單分區的索引重建及重建後刪除,整體不會佔用太多的磁盤和內存空間。
重建後的內存絕大部分集中在 snap_index 快照索引,但若重建過程中有 DML 操作,重建後的incr_index 增量索引也會有新的內存開銷,因此建議在 Rebuild 索引時,將 DML 流量關掉。
未來展望
關於 seekdb 和 OceanBase 向量索引未來的能力有如下 3 點展望:
- 實現分區級自動並行重建。 目前 OceanBase V4.3.5_BP3 已經支持了分區級自動重建,默認開啓。但自動重建是單分區、單線程進行補數據,不支持並行,因此寫入效率相對比較慢。未來希望支持並行重建,加快一個分區級自動重建效率。
- 增量內存索引優化。 除了分區級自動重建之外,希望向量索引自己本身能做到內存優化。例如將增量內存索引的數據遷移到其他地方,或直接降低內存索引的內存佔用。
- 構建性能優化。 構建性能優化是後續會持續提升,以達到給用户提供更好的使用效率。
參考資料
[1] 在線體驗環境: https://www.oceanbase.com/demo/ob-hybrid-search-quick-start
[2] seekdb 開源項目代碼: https://github.com/oceanbase/seekdb/blob/develop/src/share/schema/ob_schema_struct.h
[3] OceanBase 官方文檔 —— REBUILD_INDEX: https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980771