

本文又是一篇餵飯級教程,為大家展示通過 OceanBase seekdb 構建 RAG(檢索增強生成)系統的詳細步驟。

RAG 系統結合了檢索系統和生成模型,可根據給定提示生成新文本。系統首先使用 seekdb 的原生向量搜索功能從語料庫中檢索相關文檔,然後使用生成模型根據檢索到的文檔生成新文本。
前提條件
- 已安裝 Python 3.11 或以上版本
- 已安裝 uv
- 已準備好 LLM API Key
準備工作
克隆代碼
git clone https://github.com/oceanbase/pyseekdb.git
cd pyseekdb/demo/rag
設置環境
安裝依賴
基礎安裝(適用於 default 或 api embedding 類型):
uv sync
本地模型(適用於 local embedding 類型):
uv sync --extra local
提示:
local額外依賴包含sentence-transformers及相關依賴(約 2-3 GB)。- 如果您在中國大陸,可以使用國內鏡像源加速下載:
- 基礎安裝(清華源):
uv sync --index-url https://pypi.tuna.tsinghua.edu.cn/simple - 基礎安裝(阿里源):
uv sync --index-url https://mirrors.aliyun.com/pypi/simple - 本地模型(清華源):
uv sync --extra local --index-url https://pypi.tuna.tsinghua.edu.cn/simple - 本地模型(阿里源):
uv sync --extra local --index-url https://mirrors.aliyun.com/pypi/simple
- 基礎安裝(清華源):
設置環境變量
步驟一:複製環境變量模板
cp .env.example .env
步驟二:編輯 .env 文件,設置環境變量
本系統支持三種 Embedding 函數類型,您可以根據需求選擇:
default(默認,推薦新手使用)
- 使用 pyseekdb 自帶的
DefaultEmbeddingFunction(基於 ONNX) - 首次使用會自動下載模型,無需配置 API Key
- 適合本地開發和測試
local(本地模型)
- 使用自定義的
sentence-transformers模型 - 需要安裝
sentence-transformers庫 - 可配置模型名稱和設備(CPU/GPU)
api(API 服務)
- 使用 OpenAI 兼容的 Embedding API(如 DashScope、OpenAI 等)
- 需要配置 API Key 和模型名稱
- 適合生產環境
以下使用通義千問作為示例(使用 api 類型):
# Embedding Function 類型:api, local, default
EMBEDDING_FUNCTION_TYPE=api
# LLM 配置(用於生成答案)
OPENAI_API_KEY=sk-your-dashscope-key
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_MODEL_NAME=qwen-plus
# Embedding API 配置(僅在 EMBEDDING_FUNCTION_TYPE=api 時需要)
EMBEDDING_API_KEY=sk-your-dashscope-key
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_MODEL_NAME=text-embedding-v4
# 本地模型配置(僅在 EMBEDDING_FUNCTION_TYPE=local 時需要)
SENTENCE_TRANSFORMERS_MODEL_NAME=all-mpnet-base-v2
SENTENCE_TRANSFORMERS_DEVICE=cpu
# seekdb 配置
SEEKDB_DIR=./data/seekdb_rag
SEEKDB_NAME=test
COLLECTION_NAME=embeddings
環境變量説明:
| 變量名 | 説明 | 默認值/示例值 | 必需條件 |
|---|---|---|---|
| EMBEDDING_FUNCTION_TYPE | Embedding 函數類型 | default (可選:api , local , default ) |
必須設置 |
| OPENAI_API_KEY | LLM API Key(支持 OpenAI、通義千問等兼容服務) | 必須設置 | 必須設置(用於生成答案) |
| OPENAI_BASE_URL | LLM API 基礎 URL | https://dashscope.aliyuncs.com/compatible-mode/v1[1] | 可選 |
| OPENAI_MODEL_NAME | 語言模型名稱 | qwen-plus | 可選 |
| EMBEDDING_API_KEY | Embedding API Key | - | EMBEDDING_FUNCTION_TYPE=api 時必需 |
| EMBEDDING_BASE_URL | Embedding API 基礎 URL | https://dashscope.aliyuncs.com/compatible-mode/v1[2] | EMBEDDING_FUNCTION_TYPE=api 時可選 |
| EMBEDDING_MODEL_NAME | Embedding 模型名稱 | text-embedding-v4 | EMBEDDING_FUNCTION_TYPE=api 時必需 |
| SENTENCE_TRANSFORMERS_MODEL_NAME | 本地模型名稱 | all-mpnet-base-v2 | EMBEDDING_FUNCTION_TYPE=local 時可選 |
| SENTENCE_TRANSFORMERS_DEVICE | 運行設備 | cpu | EMBEDDING_FUNCTION_TYPE=local 時可選 |
| SEEKDB_DIR | seekdb 數據庫目錄 | ./data/seekdb_rag | 可選 |
| SEEKDB_NAME | 數據庫名稱 | test | 可選 |
| COLLECTION_NAME | 嵌入表名稱 | embeddings | 可選 |
提示:
- 如果使用
default類型,只需配置EMBEDDING_FUNCTION_TYPE=default和 LLM 相關變量即可。 - 如果使用
api類型,需要額外配置 Embedding API 相關變量。 - 如果使用
local類型,需要安裝sentence-transformers庫,並可選擇配置模型名稱。
主要使用的模塊
初始化 LLM 客户端
我們通過加載環境變量來初始化 LLM 客户端:
def get_llm_client() -> OpenAI:
"""Initialize LLM client using OpenAI-compatible API."""
return OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL"),
)
創建數據庫連接
def get_seekdb_client(db_dir: str = "./seekdb_rag", db_name: str = "test"):
"""Initialize seekdb client (embedded mode)."""
cache_key = (db_dir, db_name)
if cache_key not in _client_cache:
print(f"Connecting to seekdb: path={db_dir}, database={db_name}")
_client_cache[cache_key] = Client(path=db_dir, database=db_name)
print("seekdb client connected successfully")
return _client_cache[cache_key]
自定義嵌入模型的工廠模式
在 .env 文件中可以通過配置 EMBEDDING_FUNCTION_TYPE 使用不同的 embedding_function。您也可以參考這個例子自定義您的 embedding_function。
from pyseekdb import EmbeddingFunction, DefaultEmbeddingFunction
from typing import List, Union
import os
from openai import OpenAI
Documents = Union[str, List[str]]
Embeddings = List[List[float]]
class SentenceTransformerCustomEmbeddingFunction(EmbeddingFunction[Documents]):
"""
A custom embedding function using sentence-transformers with a specific model.
"""
def __init__(self, model_name: str = "all-mpnet-base-v2", device: str = "cpu"):# TODO: your own model name and device
"""
Initialize the sentence-transformer embedding function.
Args:
model_name: Name of the sentence-transformers model to use
device: Device to run the model on ('cpu' or 'cuda')
"""
self.model_name = model_name or os.environ.get('SENTENCE_TRANSFORMERS_MODEL_NAME')
self.device = device or os.environ.get('SENTENCE_TRANSFORMERS_DEVICE')
self._model = None
self._dimension = None
def _ensure_model_loaded(self):
"""Lazy load the embedding model"""
if self._model isNone:
try:
from sentence_transformers import SentenceTransformer
self._model = SentenceTransformer(self.model_name, device=self.device)
# Get dimension from model
test_embedding = self._model.encode(["test"], convert_to_numpy=True)
self._dimension = len(test_embedding[0])
except ImportError:
raise ImportError(
"sentence-transformers is not installed. "
"Please install it with: pip install sentence-transformers"
)
@property
def dimension(self) -> int:
"""Get the dimension of embeddings produced by this function"""
self._ensure_model_loaded()
return self._dimension
def __call__(self, input: Documents) -> Embeddings:
"""
Generate embeddings for the given documents.
Args:
input: Single document (str) or list of documents (List[str])
Returns:
List of embedding vectors
"""
self._ensure_model_loaded()
# Handle single string input
if isinstance(input, str):
input = [input]
# Handle empty input
ifnot input:
return []
# Generate embeddings
embeddings = self._model.encode(
input,
convert_to_numpy=True,
show_progress_bar=False
)
# Convert numpy arrays to lists
return [embedding.tolist() for embedding in embeddings]
class OpenAIEmbeddingFunction(EmbeddingFunction[Documents]):
"""
A custom embedding function using Embedding API.
"""
def __init__(self, model_name: str = "", api_key: str = "", base_url: str = ""):
"""
Initialize the Embedding API embedding function.
Args:
model_name: Name of the Embedding API embedding model
api_key: Embedding API key (if not provided, uses EMBEDDING_API_KEY env var)
"""
self.model_name = model_name or os.environ.get('EMBEDDING_MODEL_NAME')
self.api_key = api_key or os.environ.get('EMBEDDING_API_KEY')
self.base_url = base_url or os.environ.get('EMBEDDING_BASE_URL')
self._dimension = None
ifnot self.api_key:
raise ValueError("Embedding API key is required")
def _ensure_model_loaded(self):
"""Lazy load the Embedding API model"""
try:
client = OpenAI(
api_key=self.api_key,
base_url=self.base_url
)
response = client.embeddings.create(
model=self.model_name,
input=["test"]
)
self._dimension = len(response.data[0].embedding)
except Exception as e:
raise ValueError(f"Failed to load Embedding API model: {e}")
@property
def dimension(self) -> int:
"""Get the dimension of embeddings produced by this function"""
self._ensure_model_loaded()
return self._dimension
def __call__(self, input: Documents) -> Embeddings:
"""
Generate embeddings using Embedding API.
Args:
input: Single document (str) or list of documents (List[str])
Returns:
List of embedding vectors
"""
# Handle single string input
if isinstance(input, str):
input = [input]
# Handle empty input
ifnot input:
return []
# Call Embedding API
client = OpenAI(
api_key=self.api_key,
base_url=self.base_url
)
response = client.embeddings.create(
model=self.model_name,
input=input
)
# Extract Embedding API embeddings
embeddings = [item.embedding for item in response.data]
return embeddings
def create_embedding_function() -> EmbeddingFunction:
embedding_function_type = os.environ.get('EMBEDDING_FUNCTION_TYPE')
if embedding_function_type == "api":
print("Using OpenAI Embedding API embedding function")
return OpenAIEmbeddingFunction()
elif embedding_function_type == "local":
print("Using SentenceTransformer embedding function")
return SentenceTransformerCustomEmbeddingFunction()
elif embedding_function_type == "default":
print("Using Default embedding function")
return DefaultEmbeddingFunction()
else:
raise ValueError(f"Unsupported embedding function type: {embedding_function_type}")
創建 Collection
在 get_or_create_collection() 方法中我們傳入了 embedding_function,之後使用這個 collection 的 add() 和 query() 方法的時候就不需要傳入向量了,只需傳入文本,向量會由 embedding_function 自動生成。
def get_seekdb_collection(client, collection_name: str = "embeddings",
embedding_function: Optional[EmbeddingFunction] = DefaultEmbeddingFunction(),
drop_if_exists: bool = True):
"""
Get or create a collection using pyseekdb's get_or_create_collection.
Args:
client: seekdb client instance
collection_name: Name of the collection
embedding_function: Embedding function (required for automatic embedding generation)
drop_if_exists: Whether to drop existing collection if it exists
Returns:
Collection object
"""
if drop_if_exists and client.has_collection(collection_name):
print(f"Collection '{collection_name}' already exists, deleting old data...")
client.delete_collection(collection_name)
if embedding_function isNone:
raise ValueError("embedding_function is required")
# Use pyseekdb's native get_or_create_collection
collection = client.get_or_create_collection(
name=collection_name,
embedding_function=embedding_function
)
print(f"Collection '{collection_name}' ready!")
return collection
核心插入數據函數
def insert_embeddings(collection, data: List[Dict[str, Any]]):
"""
Insert data into collection. Embeddings are automatically generated by collection's embedding_function.
Args:
collection: Collection object (must have embedding_function configured)
data: List of data dictionaries containing 'text', 'source_file', 'chunk_index'
"""
try:
ids = [f"{item['source_file']}_{item.get('chunk_index', 0)}"for item in data]
documents = [item['text'] for item in data]
metadatas = [{'source_file': item['source_file'],
'chunk_index': item.get('chunk_index', 0)} for item in data]
# Collection's embedding_function will automatically generate embeddings from documents
collection.add(
ids=ids,
documents=documents,
metadatas=metadatas
)
print(f"Inserted {len(data)} items successfully")
except Exception as e:
print(f"Error inserting data: {e}")
raise
向量相似度搜索
results = collection.query(
query_texts=[question],
n_results=3,
include=["documents", "metadatas", "distances"]
)
統計 Collection 中的數據情況
def get_database_stats(collection) -> Dict[str, Any]:
"""Get statistics about the collection."""
try:
results = collection.get(limit=10000, include=["metadatas"])
ids = results.get('ids', []) if isinstance(results, dict) else []
metadatas = results.get('metadatas', []) if isinstance(results, dict) else []
unique_files = {m.get('source_file') for m in metadatas if m and m.get('source_file')}
return {
"total_embeddings": len(ids),
"unique_source_files": len(unique_files)
}
except Exception as e:
print(f"Error getting database stats: {e}")
return {"total_embeddings": 0, "unique_source_files": 0}
構建 RAG 系統
本模塊實現了 RAG 系統的檢索功能。通過將用户提出的問題轉換為嵌入向量,利用 seekdb 提供的原生向量搜索能力,快速檢索出與問題最相關的文檔片段,為後續的生成模型提供必要的上下文信息。
導入數據
我們使用 pyseekdb 的 SDK 文檔作為示例,您也可以使用自己的 Markdown 文檔或者目錄。
運行數據導入腳本:
# 導入單個文檔
uv run python seekdb_insert.py ../../README.md
# 或導入目錄下的所有 Markdown 文檔
uv run python seekdb_insert.py path/to/your_dir
啓動應用
在 pyseekdb/demo/rag 路徑下執行如下命令,通過 Streamlit 啓動應用:
uv run streamlit run seekdb_app.py --server.port your_port
使用 IP 和端口號(默認為 8501,可通過 --server.port 選項自定義)即可在瀏覽器中打開 RAG 界面。
提示: 如果使用 uv 作為包管理器,請在命令前加上 uv run 前綴,以確保使用正確的 Python 環境和依賴。
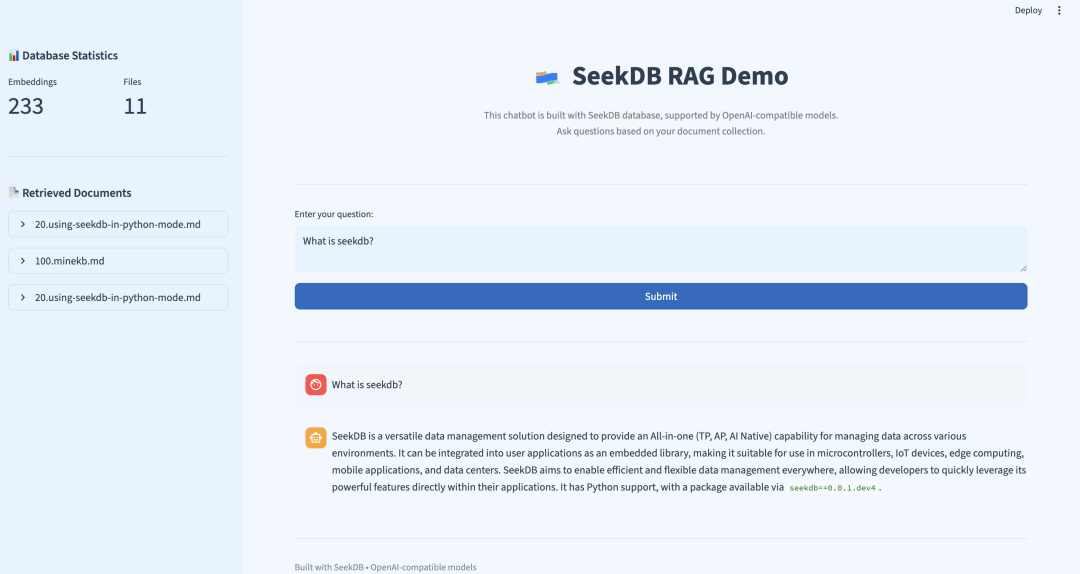
實際運行示例
以下是一個真實的查詢示例,展示了 seekdb RAG 系統的實際效果:
用户問題:“What is seekdb's vector search?”
檢索到的相關文檔:
1. 30.experience-vector-retrieval.md
Vector search overview In today's era of information explosion, users often need to quickly retrieve the information they need from massive amounts o...
2. 20.using-seekdb-in-python-mode.md
Experience vector search SeekDB supports up to 16,000 dimensions of float-type dense vectors, sparse vectors, and various types of vector distance ca...
3. 70.experience-hybrid-vector-index.md
Summary Through this tutorial, you have mastered the core features of SeekDB's hybrid vector index: Simplified usage process: Achieve semantic ret...
使用 LLM 生成的答案:
SeekDB's vector search is a powerful feature that enables efficient and accurate retrieval of data by encoding various types of data—such as text, images, and audio—into mathematical vectors and performing searches in a vector space. This approach captures deep semantic relationships within the data, going beyond traditional keyword-based search methods to deliver more relevant results.
Key capabilities of SeekDB's vector search include:
- High-dimensional vector support: It supports up to 16,000 dimensions for float-type dense vectors and sparse vectors.
- Multiple distance metrics: It supports various similarity or distance calculations, including Manhattan distance, Euclidean distance, inner product, and cosine distance.
- Advanced indexing methods: Vector indexes can be created using HNSW (Hierarchical Navigable Small World) or IVF (Iterative Virtual File), enabling fast approximate nearest neighbor searches.
- Incremental updates: The system allows for real-time insertion and deletion of vectors without compromising search accuracy or recall.
- Hybrid search with scalar filtering: Users can combine vector similarity search with traditional attribute-based (scalar) filtering for more precise results.
- Flexible access interfaces: SeekDB supports SQL access via MySQL protocol clients in multiple programming languages, as well as a Python SDK.
- Automatic embedding and hybrid indexing: With hybrid vector index features, users can store raw text directly—the system automatically converts it into vectors and builds indexes.
In summary, SeekDB's vector search provides a comprehensive, high-performance solution for semantic search, particularly valuable in AI applications involving large-scale unstructured data.
這個示例展示了:
- ✅ 準確的信息檢索:系統成功從文檔中找到了相關信息
- ✅ 多文檔整合:從 3 個不同文檔中提取和整合信息
- ✅ 語義匹配:準確匹配了“vector search”相關的文檔
- ✅ 結構化回答:AI 將檢索到的信息整理成清晰的結構
- ✅ 完整性:涵蓋了 seekdb 向量搜索的主要特性
- ✅ 專業性:回答包含了技術細節和實際應用價值
檢索質量分析:
- 最相關文檔 :
experience-vector-retrieval.md- 向量搜索概覽 - 技術細節 :
using-seekdb-in-python-mode.md- 具體的技術規格 - 高級特性 :
experience-hybrid-vector-index.md- 混合向量索引功能
快速體驗
如需快速體驗 seekdb RAG 系統,請參考 快速部署[3]。
參考資料
[1]
https://dashscope.aliyuncs.com/compatible-mode/v1: https://dashscope.aliyuncs.com/compatible-mode/v1
[2]
https://dashscope.aliyuncs.com/compatible-mode/v1: https://dashscope.aliyuncs.com/compatible-mode/v1
[3]
快速部署: https://github.com/oceanbase/pyseekdb/blob/main/demo/rag/README_CN.md
[4]
seekdb 項目地址:https://github.com/oceanbase/seekdb