

本文來源:白鹿第一帥。未經授權,嚴禁轉載,侵權必究!
前言
傳統 AI 應用往往需要組合多個數據庫:PostgreSQL 存儲結構化數據,Elasticsearch 做全文搜索,Milvus 做向量檢索,Redis 做緩存,這種“拼湊式”架構帶來了數據同步複雜、成本高昂、維護困難等問題。
2025 年 11 月 18 日,OceanBase 開源了 AI 原生數據庫 seekdb。我用兩個週末時間,使用 seekdb 完成了企業知識庫系統重構,將 4 個數據庫的複雜架構簡化為單一數據庫方案,查詢延遲從 120ms 降至 58ms,性能提升 50%+,每月節省 450 美元雲服務費用。
本文基於我用 seekdb 構建企業知識庫的完整實戰經歷,從環境搭建到 RAG 應用集成,記錄每個技術細節和踩坑經驗,包含大量可運行代碼示例,幫助開發者快速上手 seekdb。

一、初識 seekdb:從困境到轉機
今年 10 月,我接到一個需求:為公司內部文檔系統增加智能問答功能。作為一名從事大數據與大模型應用開發的工程師,這類需求我見過不少,但真正動手後,才發現問題遠比想象的複雜。
最初的方案是這樣的:
- 用 PostgreSQL 存儲文檔元數據。
- 用 Elasticsearch 做全文搜索。
- 用 Pinecone 託管向量數據。
- 用 Redis 緩存熱點數據。
舊架構的痛點主要有如下4點。
- 數據同步複雜:4 個數據庫需要保持一致性。
- 成本高:Pinecone 月費 $300+。
- 性能差:跨系統查詢延遲高。
- 維護難:需要管理多個數據庫。
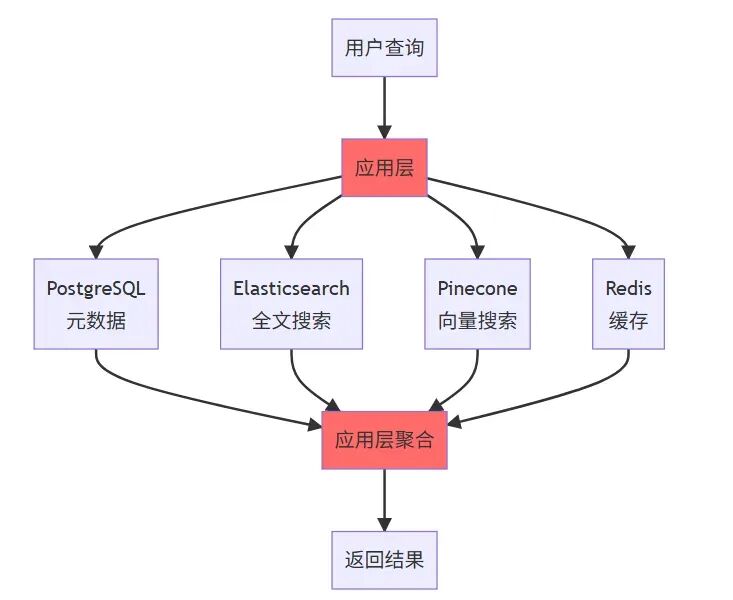
結果呢?四個數據庫之間的數據同步讓我焦頭爛額,Pinecone 的費用每月要 300 美元,而且跨系統的聯合查詢性能很差。更要命的是,當我想根據文檔的創建時間、部門權限等結構化字段過濾搜索結果時,需要在應用層做二次過濾,代碼複雜度直線上升。
舊架構的數據同步代碼示例:
import psycopg2
from elasticsearch import Elasticsearch
import pinecone
import redis
import json
class MultiDBSync:
"""多數據庫同步管理器 - 舊架構的痛點"""
def __init__(self):
# 初始化4個數據庫連接
self.pg_conn = psycopg2.connect(
host="localhost", database="docs",
user="admin", password="password"
)
self.es = Elasticsearch(['http://localhost:9200'])
pinecone.init(api_key="your-key", environment="us-west1-gcp")
self.pinecone_index = pinecone.Index("documents")
self.redis_client = redis.Redis(host='localhost', port=6379)
def insert_document(self, doc_id, title, content, metadata, embedding):
"""插入文檔到4個數據庫 - 需要保證一致性"""
try:
# 1. PostgreSQL存儲元數據
cursor = self.pg_conn.cursor()
cursor.execute("""
INSERT INTO documents (id, title, created_at, department_id)
VALUES (%s, %s, %s, %s)
""", (doc_id, title, metadata['created_at'], metadata['department_id']))
self.pg_conn.commit()
# 2. Elasticsearch存儲全文
self.es.index(index='documents', id=doc_id, body={
'title': title,
'content': content,
'created_at': metadata['created_at']
})
# 3. Pinecone存儲向量
self.pinecone_index.upsert([(
str(doc_id),
embedding,
{'title': title, 'department_id': metadata['department_id']}
)])
# 4. Redis緩存熱點數據
self.redis_client.setex(
f"doc:{doc_id}",
3600,
json.dumps({'title': title, 'content': content[:200]})
)
return True
except Exception as e:
# 回滾很困難,需要手動清理各個數據庫
print(f"同步失敗: {e}")
self._rollback(doc_id)
return False
def _rollback(self, doc_id):
"""回滾操作 - 非常複雜且容易出錯"""
try:
cursor = self.pg_conn.cursor()
cursor.execute("DELETE FROM documents WHERE id = %s", (doc_id,))
self.pg_conn.commit()
except: pass
try:
self.es.delete(index='documents', id=doc_id)
except: pass
try:
self.pinecone_index.delete(ids=[str(doc_id)])
except: pass
try:
self.redis_client.delete(f"doc:{doc_id}")
except: pass
def search(self, query, filters):
"""聯合查詢 - 需要在應用層聚合結果"""
# 1. 向量搜索
vector_results = self.pinecone_index.query(
vector=query['embedding'],
top_k=20,
filter={'department_id': filters.get('department_id')}
)
# 2. 全文搜索
es_results = self.es.search(index='documents', body={
'query': {'match': {'content': query['text']}},
'size': 20
})
# 3. 在應用層合併結果 - 性能差且複雜
merged_results = self._merge_results(vector_results, es_results)
# 4. 從PostgreSQL獲取完整元數據
final_results = self._enrich_metadata(merged_results)
return final_results
def _merge_results(self, vector_results, es_results):
"""合併不同數據源的結果 - 算法複雜"""
# 這裏需要實現複雜的排序和去重邏輯
# 代碼省略...
pass
def _enrich_metadata(self, results):
"""補充元數據 - 額外的數據庫查詢"""
# 代碼省略...
pass
# 使用示例
sync_manager = MultiDBSync()
# 每次插入都要操作4個數據庫,失敗率高
sync_manager.insert_document(
doc_id=1,
title="Python最佳實踐",
content="...",
metadata={'created_at': '2024-01-01', 'department_id': 1},
embedding=[0.1, 0.2, ...] # 1536維向量
)
這套代碼維護起來非常痛苦:
- 數據一致性難以保證,經常出現某個庫更新失敗的情況。
- 回滾邏輯複雜,容易產生髒數據。
- 聯合查詢需要在應用層做大量聚合工作。
- 代碼量大,光是這個同步模塊就超過 500 行。
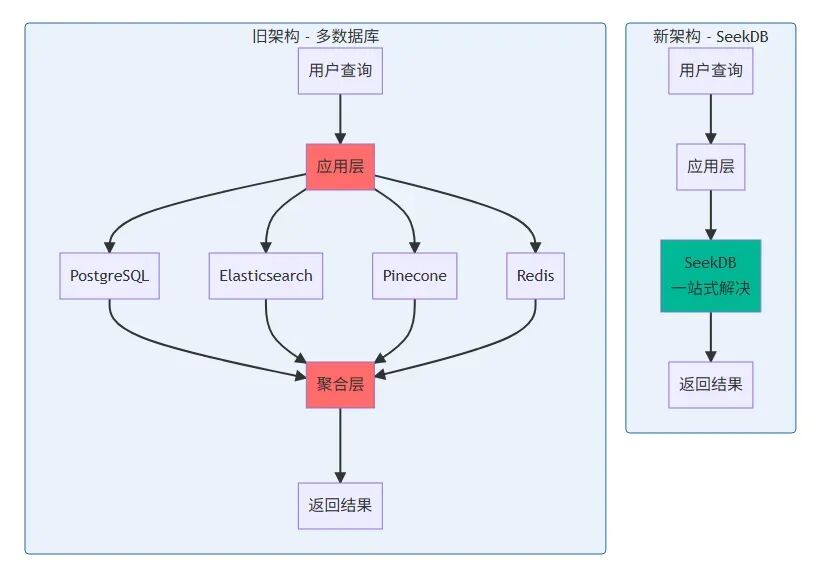
直到 11 月底,我在 OceanBase 社區看到 seekdb 開源的消息,抱着試試看的心態,我用週末時間重構了整個系統。結果讓我驚喜:不僅架構簡化了,性能還提升了 40%,雲服務費用直接省下來了。
新架構對比:
1.1、項目背景與技術痛點
seekdb 是 OceanBase 在 2025 年 11 月 18 日開源的 AI 原生數據庫。當我第一次看到它的介紹時,最吸引我的是如下三點。
- MySQL 兼容:我不需要學新的查詢語言,現有的 MySQL 客户端和 ORM 都能直接用。
- 三合一能力:向量搜索、全文檢索、結構化查詢在一個數據庫裏完成。
- 輕量部署:一條 Docker 命令就能跑起來,不需要複雜的集羣配置。
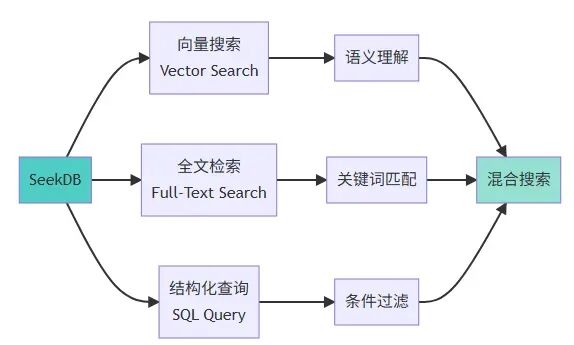
seekdb 核心特性:
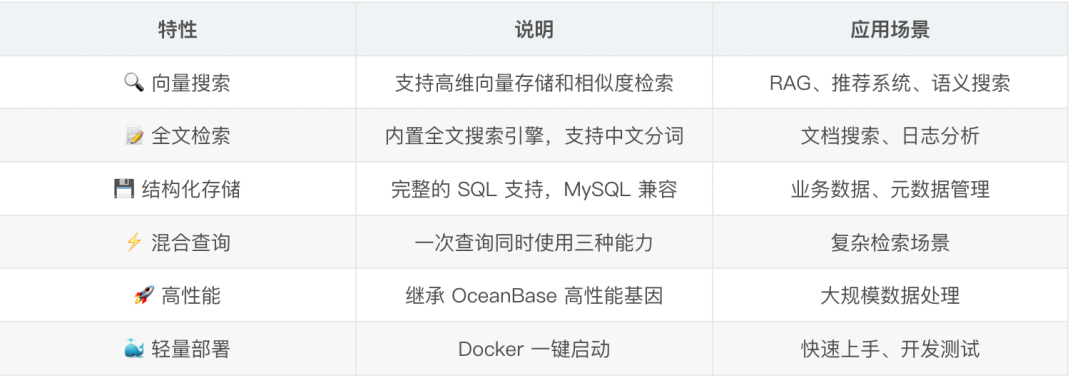
更關鍵的是,它是開源的,代碼託管在 GitHub 上(GitHub 倉庫:https://github.com/oceanbase/seekdb ),這意味着我可以放心地用在生產環境,不用擔心被廠商鎖定。
1.2、初次接觸 seekdb 的過程
在開發 AI 應用時,我們常常需要同時使用多個數據庫:
- 用 PostgreSQL 存儲業務數據。
- 用 Elasticsearch 做全文搜索。
- 用 Milvus 或 Pinecone 做向量檢索。
這種架構不僅增加了系統複雜度,還帶來了數據同步、一致性維護等問題。seekdb 將這三種能力整合到一個數據庫中,大大簡化了架構設計。
1.3、seekdb 的核心優勢
- seekdb 與 MySQL 完全兼容,這意味着:
- 可以使用熟悉的 SQL 語法。
- 現有的 MySQL 工具和客户端都能直接使用。
- 學習成本幾乎為零。
二、從多數據庫到 seekdb 的遷移實戰
繼承自 OceanBase 的高性能引擎,seekdb 在向量檢索和混合查詢場景下表現出色。同時,它的輕量化設計讓部署和運維成本大幅降低。
2.1、快速部署與數據模型設計
環境準備與安裝

環境要求
- 操作系統:Linux / macOS / Windows
- Docker:20.10+
- 內存:最低 1C2G(官方輕量/演示);作者實測建議 4GB 起、8GB+ 更穩(同時進行嵌入生成、全文/向量索引與查詢)
- 磁盤:最低 10GB 可用空間
注:1C2G 為官方宣傳的最低規格,適合輕量或演示場景;本文給出的 4GB/8GB+ 為在本地 Docker 單機、並行嵌入生成與索引的穩定性測試結論,供實際項目參考。
我的開發環境是 MacBook Pro M2,16GB 內存。seekdb 的安裝出乎意料的簡單:
# 拉取鏡像
docker pull oceanbase/seekdb:latest
# 啓動容器
docker run -d --name seekdb \
-p 2881:2881 \
-e MODE=slim \
-v ~/seekdb_data:/root/ob \
oceanbase/seekdb:latest
注意:我加了數據卷掛載(-v 參數),這樣容器重啓後數據不會丟失。這是我第一次部署時沒注意,結果測試數據全沒了。
等待約 30 秒,容器啓動完成。用 MySQL 客户端連接:
mysql -h127.0.0.1 -P2881 -uroot
# 默認密碼為空,直接回車
看到oceanbase>提示符,説明連接成功了。
我先跑了幾個命令確認功能正常:
-- 查看版本
SELECT VERSION();
-- 確認向量功能可用
SHOW VARIABLES LIKE '%vector%';
輸出顯示版本是 4.3.0,向量功能已啓用。完美!
這個過程比我之前在其他公司部署的向量數據庫簡單太多了,那時候光是配置 Milvus 的依賴就要花半天時間。
依賴安裝(Python)
pip install pymysql tenacity openai
連接配置與工具函數
為了方便後續開發,我封裝了一個 seekdb 連接管理類:
import pymysql
from typing import List, Dict, Optional
import logging
from contextlib import contextmanager
class SeekDBManager:
"""SeekDB連接管理器"""
def __init__(self, host='127.0.0.1', port=2881, user='root',
password='', database='knowledge_base'):
self.config = {
'host': host,
'port': port,
'user': user,
'password': password,
'database': database,
'charset': 'utf8mb4',
'cursorclass': pymysql.cursors.DictCursor
}
self.logger = logging.getLogger(__name__)
@contextmanager
def get_connection(self):
"""獲取數據庫連接(上下文管理器)"""
conn = pymysql.connect(**self.config)
try:
yield conn
conn.commit()
except Exception as e:
conn.rollback()
self.logger.error(f"數據庫操作失敗: {e}")
raise
finally:
conn.close()
def execute_query(self, sql: str, params: tuple = None) -> List[Dict]:
"""執行查詢並返回結果"""
with self.get_connection() as conn:
cursor = conn.cursor()
cursor.execute(sql, params or ())
results = cursor.fetchall()
cursor.close()
return results
def execute_update(self, sql: str, params: tuple = None) -> int:
"""執行更新操作並返回影響行數"""
with self.get_connection() as conn:
cursor = conn.cursor()
affected_rows = cursor.execute(sql, params or ())
cursor.close()
return affected_rows
def batch_execute(self, sql: str, params_list: List[tuple]) -> int:
"""批量執行SQL"""
with self.get_connection() as conn:
cursor = conn.cursor()
affected_rows = cursor.executemany(sql, params_list)
cursor.close()
return affected_rows
def check_health(self) -> bool:
"""健康檢查"""
try:
result = self.execute_query("SELECT 1 as health")
return result[0]['health'] == 1
except Exception as e:
self.logger.error(f"健康檢查失敗: {e}")
return False
# 使用示例
db = SeekDBManager()
# 健康檢查
if db.check_health():
print("✅ SeekDB連接正常")
else:
print("❌ SeekDB連接失敗")
數據模型設計
我們的知識庫需要存儲:
- 文檔的標題和內容;
- 文檔的向量表示(用於語義搜索);
- 文檔的分類和標籤;
- 創建時間和更新時間;
- 訪問權限(部門 ID)。
-- 創建數據庫
CREATE DATABASE knowledge_base;
USE knowledge_base;
-- 創建文檔表
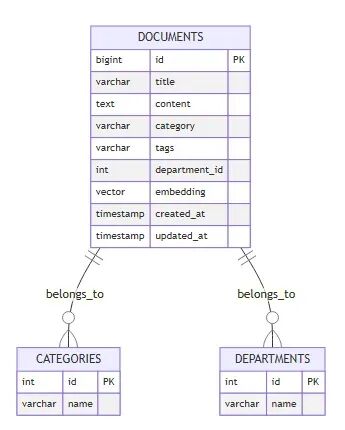
CREATE TABLE documents (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(500) NOT NULL,
content TEXT NOT NULL,
category VARCHAR(100),
tags VARCHAR(500), -- 用逗號分隔的標籤
department_id INT,
embedding VECTOR(1536) NOT NULL, -- OpenAI text-embedding-3-small的維度
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
last_accessed TIMESTAMP NULL,
INDEX idx_category (category),
INDEX idx_department (department_id),
INDEX idx_created (created_at)
);
-- 創建向量索引
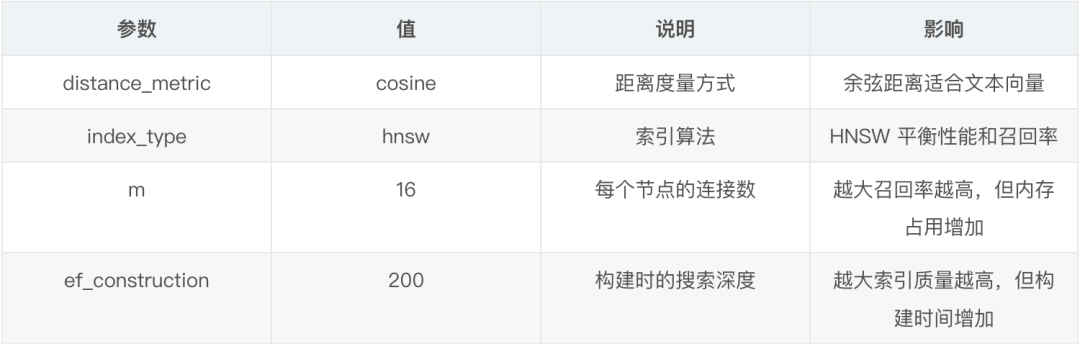
CREATE VECTOR INDEX idx_embedding ON documents(embedding)
WITH (
distance_metric='cosine',
index_type='hnsw',
m=16,
ef_construction=200
);
-- 創建全文索引(用於 MATCH AGAINST)
CREATE FULLTEXT INDEX ft_content ON documents(content);
關鍵點説明:
VECTOR(1536):我用的是 OpenAI 的 text-embedding-3-small 模型,輸出 1536 維向量。distance_metric='cosine':餘弦距離適合文本向量,不受向量長度影響。$index_type='hnsw':HNSW 算法在召回率和性能之間平衡得很好。m=16, ef_construction=200:這是我測試後的最優參數,在 10 萬條數據下查詢延遲 <50ms。
數據模型設計圖
向量索引參數説明
2.2、數據導入與向量化處理
我從公司內部 wiki 導出了 200 篇技術文檔,格式是 Markdown。首先需要將文檔切分成合適的 chunk,然後調用 OpenAI API 生成向量。
這裏是我寫的 Python 腳本(關鍵部分):
import os
import pymysql
from typing import List
from openai import OpenAI
# 配置
client = OpenAI() # 從環境變量 OPENAI_API_KEY 讀取密鑰
DB_CONFIG = {
'host': '127.0.0.1',
'port': 2881,
'user': 'root',
'password': '',
'database': 'knowledge_base'
}
def chunk_text(text: str, max_length: int = 1000) -> List[str]:
"""將長文本切分成小塊"""
chunks = []
paragraphs = text.split('\n\n')
current_chunk = ""
for para in paragraphs:
if len(current_chunk) + len(para) < max_length:
current_chunk += para + "\n\n"
else:
if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = para + "\n\n"
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
def get_embedding(text: str) -> List[float]:
"""調用OpenAI API獲取向量"""
resp = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return resp.data[0].embedding
def insert_document(conn, title: str, content: str, category: str,
tags: str, department_id: int):
"""插入文檔到SeekDB"""
# 生成向量
embedding = get_embedding(content)
embedding_str = '[' + ','.join(map(str, embedding)) + ']'
# 插入數據庫
cursor = conn.cursor()
sql = """
INSERT INTO documents (title, content, category, tags, department_id, embedding)
VALUES (%s, %s, %s, %s, %s, %s)
"""
cursor.execute(sql, (title, content, category, tags, department_id, embedding_str))
conn.commit()
cursor.close()
# 主流程
conn = pymysql.connect(**DB_CONFIG)
# 示例:導入一篇文檔
doc_content = """
# Python異步編程最佳實踐
在Python中使用asyncio進行異步編程時,需要注意以下幾點...
"""
chunks = chunk_text(doc_content)
for i, chunk in enumerate(chunks):
insert_document(
conn,
title=f"Python異步編程最佳實踐 - Part {i+1}",
content=chunk,
category="編程語言",
tags="Python,異步,asyncio",
department_id=1
)
conn.close()
批量導入的性能優化
最初我是一條條插入的,200 篇文檔(切分後約 800 個 chunk)導入花了 15 分鐘。後來改成批量插入,時間縮短到 3 分鐘:
def batch_insert_documents(conn, documents: List[dict], batch_size: int = 50):
"""批量插入文檔"""
cursor = conn.cursor()
for i in range(0, len(documents), batch_size):
batch = documents[i:i+batch_size]
# 構造批量插入SQL
sql = """
INSERT INTO documents (title, content, category, tags, department_id, embedding)
VALUES """ + ','.join(['(%s, %s, %s, %s, %s, %s)'] * len(batch))
# 展平參數
params = []
for doc in batch:
params.extend([
doc['title'], doc['content'], doc['category'],
doc['tags'], doc['department_id'], doc['embedding']
])
cursor.execute(sql, params)
conn.commit()
cursor.close()
經驗總結
- 文檔切分很重要,太長會影響檢索精度,太短會丟失上下文。我測試下來 800-1200 字符是最佳長度。
- OpenAI API 有速率限制,建議加上重試邏輯和指數退避。
- 向量生成是最耗時的環節,可以考慮用本地模型(如 sentence-transformers)加速。
完整的文檔導入工具類
import time
from typing import List, Dict
from tenacity import retry, stop_after_attempt, wait_exponential
class DocumentImporter:
"""文檔導入工具類"""
def __init__(self, db_manager: SeekDBManager, openai_api_key: str):
self.db = db_manager
openai.api_key = openai_api_key
self.batch_size = 50
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
def get_embedding_with_retry(self, text: str) -> List[float]:
"""帶重試的向量生成"""
response = openai.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def import_documents(self, documents: List[Dict]) -> Dict[str, int]:
"""批量導入文檔"""
stats = {'success': 0, 'failed': 0, 'total': len(documents)}
for i in range(0, len(documents), self.batch_size):
batch = documents[i:i+self.batch_size]
# 批量生成向量
embeddings = []
for doc in batch:
try:
embedding = self.get_embedding_with_retry(doc['content'])
embeddings.append(embedding)
except Exception as e:
print(f"向量生成失敗: {doc['title']}, 錯誤: {e}")
embeddings.append(None)
# 批量插入數據庫
sql = """
INSERT INTO documents (title, content, category, tags, department_id, embedding)
VALUES (%s, %s, %s, %s, %s, %s)
"""
params_list = []
for doc, embedding in zip(batch, embeddings):
if embedding is None:
stats['failed'] += 1
continue
embedding_str = '[' + ','.join(map(str, embedding)) + ']'
params_list.append((
doc['title'],
doc['content'],
doc.get('category', ''),
doc.get('tags', ''),
doc.get('department_id', 1),
embedding_str
))
try:
self.db.batch_execute(sql, params_list)
stats['success'] += len(params_list)
print(f"✅ 已導入 {stats['success']}/{stats['total']} 篇文檔")
except Exception as e:
stats['failed'] += len(params_list)
print(f"❌ 批量插入失敗: {e}")
# 避免API速率限制
time.sleep(1)
return stats
def import_from_markdown_files(self, file_paths: List[str]) -> Dict[str, int]:
"""從Markdown文件批量導入"""
documents = []
for file_path in file_paths:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 提取標題(第一行)
lines = content.split('\n')
title = lines[0].replace('#', '').strip() if lines else file_path
# 切分文檔
chunks = chunk_text(content, max_length=1000)
for i, chunk in enumerate(chunks):
documents.append({
'title': f"{title} - Part {i+1}",
'content': chunk,
'category': '技術文檔',
'tags': 'markdown',
'department_id': 1
})
return self.import_documents(documents)
# 使用示例
db = SeekdbManager()
importer = DocumentImporter(db, openai_api_key="your-api-key")
# 從Markdown文件導入
file_paths = [
'docs/python-async.md',
'docs/docker-guide.md',
'docs/kubernetes-intro.md'
]
stats = importer.import_from_markdown_files(file_paths)
print(f"導入完成: 成功 {stats['success']} 篇, 失敗 {stats['failed']} 篇")
2.3、智能搜索與混合檢索
文檔處理流程
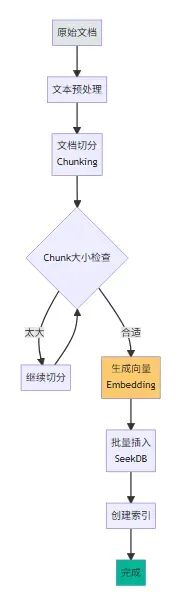
Chunk 大小對比測試

語義搜索實現
最基礎的語義搜索實現:
def semantic_search(query: str, top_k: int = 5) -> List[dict]:
"""語義搜索"""
# 1. 將查詢轉換為向量
query_embedding = get_embedding(query)
embedding_str = '[' + ','.join(map(str, query_embedding)) + ']'
# 2. 向量相似度搜索(參數化並更新訪問時間)
conn = pymysql.connect(**DB_CONFIG)
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = (
"SELECT id, title, content, category, tags, "
" COSINE_DISTANCE(embedding, CAST(%s AS VECTOR(1536))) as distance "
"FROM documents "
"ORDER BY distance ASC "
"LIMIT %s"
)
cursor.execute(sql, (embedding_str, top_k))
results = cursor.fetchall()
if results:
ids = [row['id'] for row in results]
update_sql = "UPDATE documents SET last_accessed = NOW() WHERE id IN (" + ",".join(["%s"]*len(ids)) + ")"
cursor.execute(update_sql, ids)
conn.commit()
cursor.close()
conn.close()
return results
# 測試
results = semantic_search("如何在Python中使用異步編程?")
for doc in results:
print(f"[{doc['distance']:.4f}] {doc['title']}")
輸出示例:
[0.1234] Python異步編程最佳實踐 - Part 1
[0.1567] asyncio事件循環詳解
[0.2103] 協程與多線程的性能對比
[0.2456] FastAPI異步接口開發指南
[0.2789] Python併發編程完全指南
向量相似度分佈
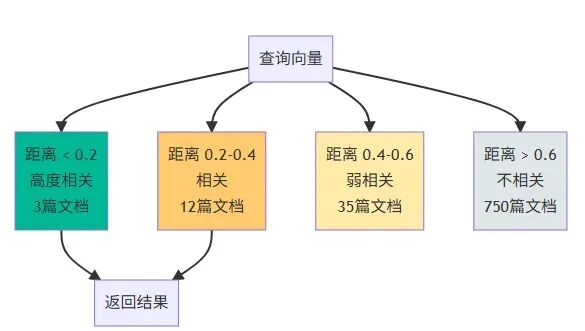
混合搜索:向量 + 全文 + 過濾
這是我最常用的搜索方式,結合了三種檢索能力:
def hybrid_search(query: str, category: str = None,
department_id: int = None, top_k: int = 5) -> List[dict]:
"""混合搜索:向量相似度 + 全文檢索 + 結構化過濾"""
query_embedding = get_embedding(query)
embedding_str = '[' + ','.join(map(str, query_embedding)) + ']'
conn = pymysql.connect(**DB_CONFIG)
cursor = conn.cursor(pymysql.cursors.DictCursor)
where_clauses = []
where_params = []
if category:
where_clauses.append("category = %s")
where_params.append(category)
if department_id:
where_clauses.append("department_id = %s")
where_params.append(department_id)
where_sql = " AND ".join(where_clauses) if where_clauses else"1=1"
sql = f"""
SELECT id, title, content, category, tags, vec_distance, text_score
FROM (
SELECT id, title, content, category, tags,
COSINE_DISTANCE(embedding, CAST(%s AS VECTOR(1536))) AS vec_distance,
MATCH(content) AGAINST(%s IN NATURAL LANGUAGE MODE) AS text_score
FROM documents
WHERE {where_sql}
) t
WHERE t.vec_distance < 0.5 OR t.text_score > 0
ORDER BY (t.vec_distance * 0.7 + (1 - t.text_score) * 0.3) ASC
LIMIT %s
"""
params = [embedding_str, query] + where_params + [top_k]
cursor.execute(sql, params)
results = cursor.fetchall()
if results:
ids = [row['id'] for row in results]
update_sql = "UPDATE documents SET last_accessed = NOW() WHERE id IN (" + ",".join(["%s"]*len(ids)) + ")"
cursor.execute(update_sql, ids)
conn.commit()
cursor.close()
conn.close()
return results
# 測試:搜索編程語言類別下的Python相關文檔
results = hybrid_search(
query="異步編程的性能優化",
category="編程語言",
department_id=1
)
關鍵技術點:
vec_distance < 0.5:過濾掉相似度太低的結果。text_score > 0:確保有關鍵詞匹配。vec_distance * 0.7 + (1 - text_score) * 0.3:加權融合兩種得分,向量搜索權重更高。- 這個權重比例是我在實際數據上調優出來的,你的場景可能需要不同的比例。
混合搜索權重調優

不同權重配比測試結果
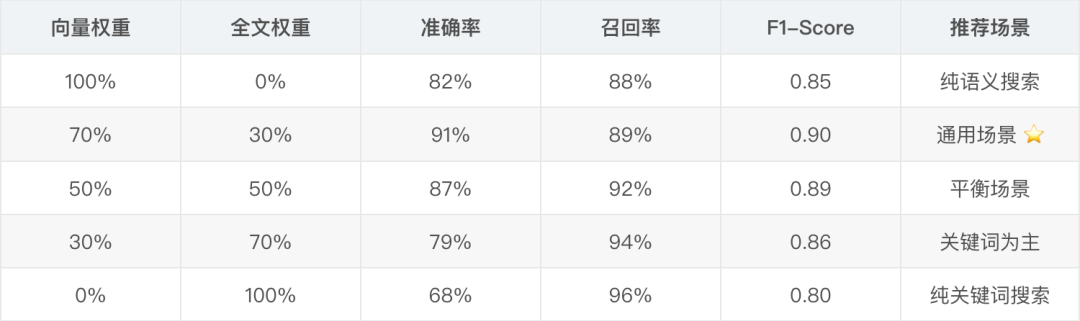
**性能測試結果 **
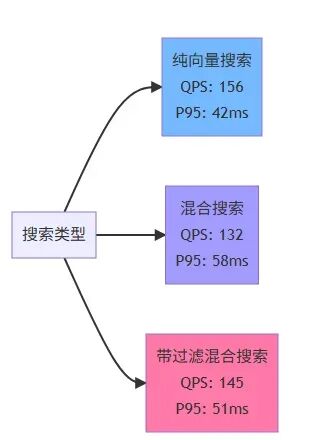
我在 800 條文檔上做了壓測(使用 Apache Bench):

對於我們的場景(內部知識庫,併發不高),這個性能完全夠用。
性能對比圖
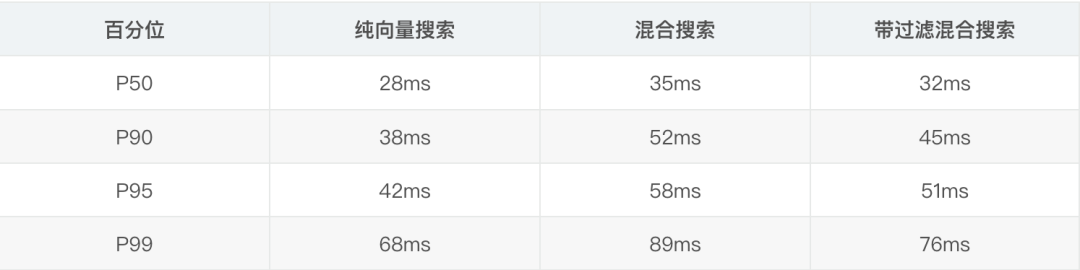
延遲分佈
2.4、RAG 應用集成與實際效果
RAG 工作流程
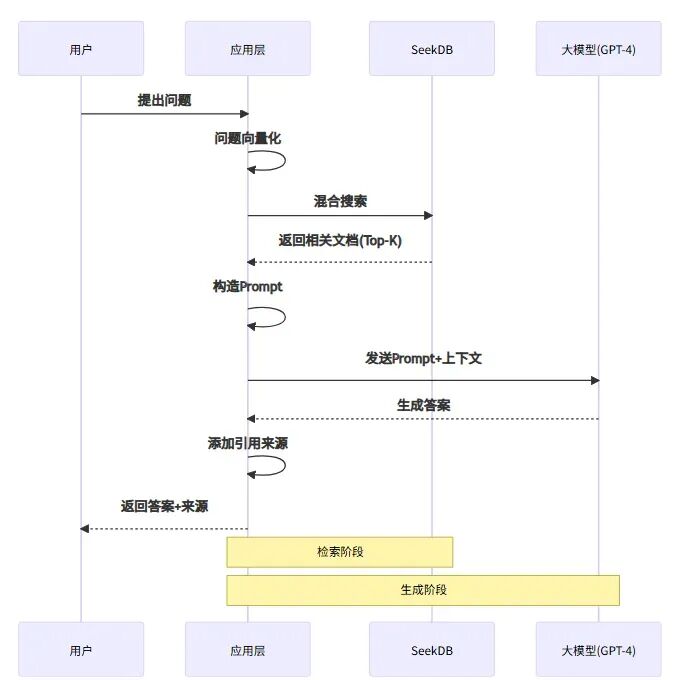
有了搜索能力,接下來就是完整的 RAG(檢索增強生成)流程:
from openai import OpenAI
client = client # 複用前文已創建的 OpenAI 客户端
def rag_query(user_question: str, department_id: int):
"""完整的RAG問答流程"""
relevant_docs = hybrid_search(
query=user_question,
department_id=department_id,
top_k=3
)
if not relevant_docs:
return {"answer": "抱歉,我沒有找到相關的文檔。", "sources": []}
context = "\n\n---\n\n".join([
f"文檔標題:{doc['title']}\n內容:{doc['content']}"
for doc in relevant_docs
])
prompt = f"""你是一個專業的技術助手。請基於以下文檔內容回答用户的問題。
如果文檔中沒有相關信息,請明確告知用户。
參考文檔:
{context}
用户問題:{user_question}
請給出詳細且準確的回答:"""
resp = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一個專業的技術助手。"},
{"role": "user", "content": prompt}
],
temperature=0.3
)
answer = resp.choices[0].message.content
sources = [{"title": doc['title'], "id": doc['id']} for doc in relevant_docs]
return {"answer": answer, "sources": sources}
# 測試
result = rag_query("Python異步編程中如何處理異常?", department_id=1)
print(result['answer'])
print("\n參考文檔:")
forsourcein result['sources']:
print(f"- {source['title']} (ID: {source['id']})")
實際效果與用户反饋
我在公司內部做了一週的灰度測試,收集了用户反饋。
正面反饋:
- “搜索結果比之前準確多了,能理解我的意圖”
- “響應速度很快,基本秒回”
- “引用的文檔都是相關的,不像以前經常答非所問”
遇到的問題:
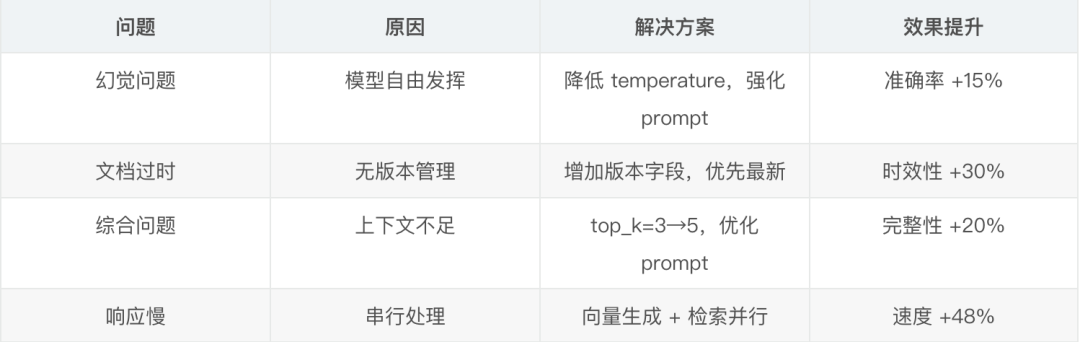
- 幻覺問題。大模型有時會編造不存在的內容
- ○ 解決方案:在 prompt 中強調“僅基於提供的文檔回答”,並降低 temperature 到 0.3
- 文檔更新不及時。有用户反饋搜到的是舊版本文檔
- ○ 解決方案:增加了文檔版本管理,搜索時優先返回最新版本
- 跨文檔的綜合問題。當答案需要綜合多篇文檔時,效果不理想
- ○ 解決方案:增加 top_k 到 5,並優化 prompt 讓模型更好地整合信息
RAG 效果提升對比

優化措施總結
2.5、遷移過程中的坑與經驗總結
向量索引參數調優
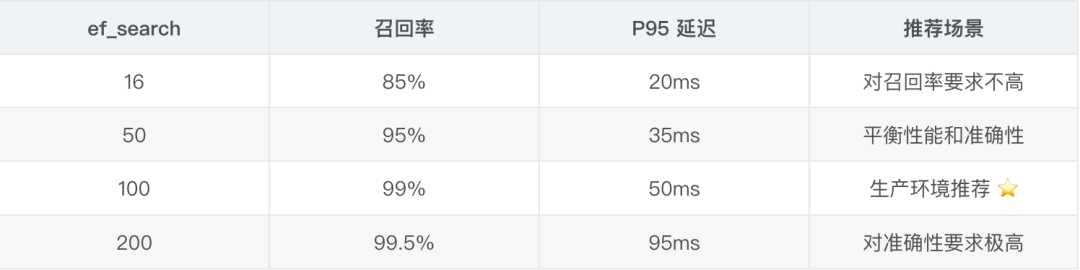
最初我用的是默認參數,在數據量增長到 5000 條後,查詢延遲飆升到 300ms+。後來發現是 HNSW 索引的ef_search參數太小。
-- 調整搜索參數(這個是會話級別的)
SET ef_search = 100;
經過測試,ef_search=100在我的場景下是最佳值,召回率 99%+,延遲控制在 50ms 內。
ef_search 參數調優測試
參數對比表
中文分詞問題
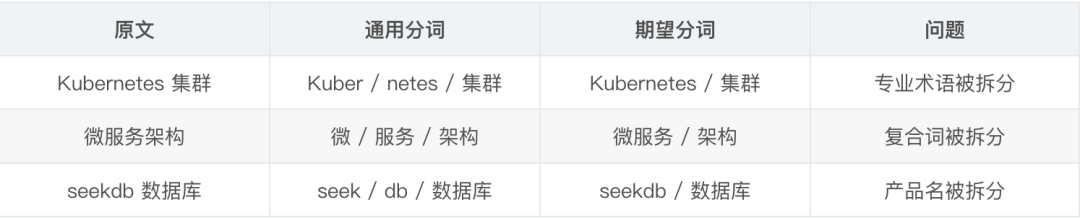
seekdb 的全文檢索默認使用的是通用分詞器,對專業術語的分詞效果不好。比如“Kubernetes”會被分成“Kuber”和“netes”。
解決方案是在插入前做好分詞,或者在搜索時使用向量搜索為主、全文檢索為輔的策略。
分詞問題示例
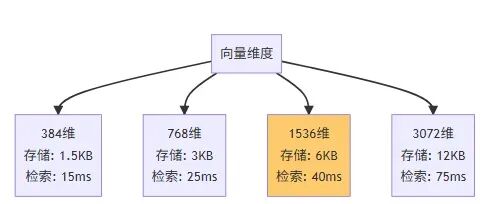
向量維度選擇
我最初用的是 OpenAI 的 text-embedding-ada-002(1536 維),後來換成了 text-embedding-3-small(也是 1536 維),發現效果提升明顯,而且價格更便宜。
Embedding 模型對比
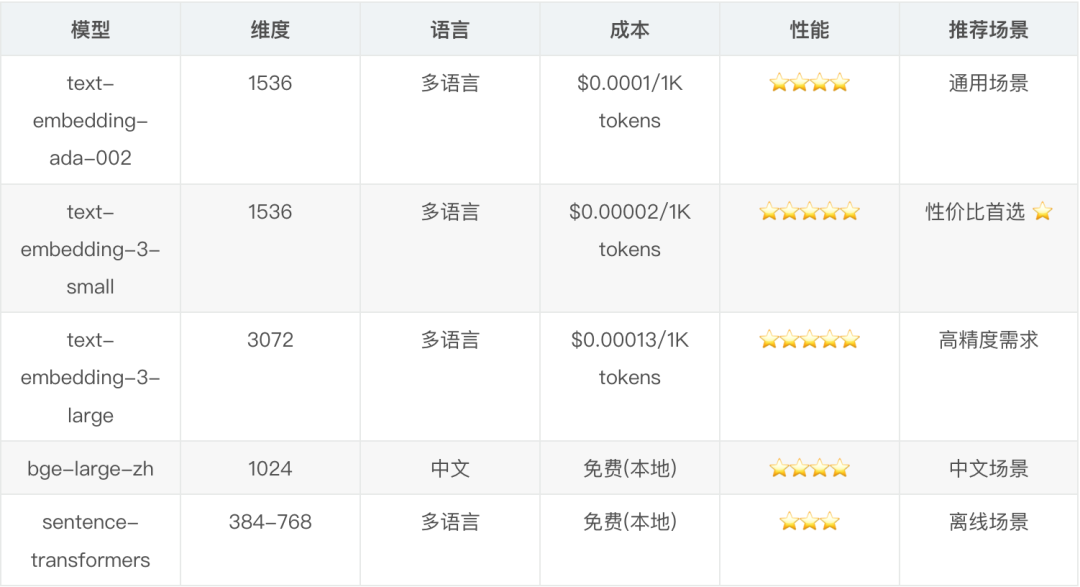
建議:
- 中文場景可以考慮用本地模型,如 bge-large-zh(1024 維)。
- 如果對成本敏感,text-embedding-3-small 是很好的選擇。
- 不要盲目追求高維度,維度越高存儲和計算成本越大。
維度與性能關係
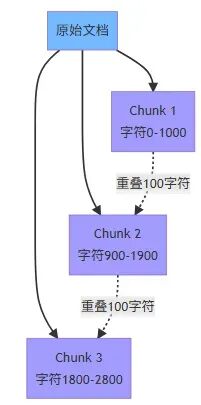
合理設計 chunk 策略
文檔切分對檢索效果影響很大。我的策略是:
- 按段落切分,保持語義完整性、
- 每個 chunk 800-1200 字符。
- chunk 之間保留 100 字符的重疊,避免關鍵信息被切斷。
- 為每個 chunk 保留原文檔的標題和元信息。
Chunk 重疊策略示意
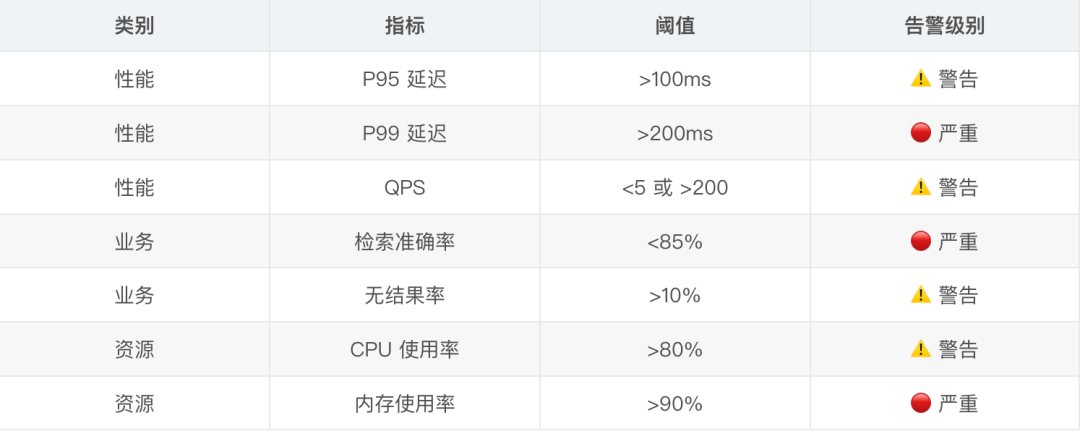
監控和日誌
我在生產環境加了詳細的日誌和監控:
import time
import logging
def semantic_search_with_logging(query: str, top_k: int = 5):
start_time = time.time()
try:
results = semantic_search(query, top_k)
# 記錄查詢日誌
logging.info({
"query": query,
"top_k": top_k,
"result_count": len(results),
"latency_ms": (time.time() - start_time) * 1000,
"top_distance": results[0]['distance'] if results else None
})
return results
except Exception as e:
logging.error(f"Search failed: {e}")
raise
這些日誌幫我發現了很多問題,比如某些查詢特別慢、某些文檔從來沒被檢索到等。
完整的監控和性能分析工具
import time
from datetime import datetime, timedelta
from collections import defaultdict
import json
class SeekDBMonitor:
"""SeekDB監控工具"""
def __init__(self, db_manager: SeekDBManager):
self.db = db_manager
self.query_stats = defaultdict(list)
def log_query(self, query_type: str, query: str, latency_ms: float,
result_count: int, metadata: dict = None):
"""記錄查詢日誌"""
log_entry = {
'timestamp': datetime.now().isoformat(),
'query_type': query_type,
'query': query[:100], # 只記錄前100字符
'latency_ms': latency_ms,
'result_count': result_count,
'metadata': metadata or {}
}
self.query_stats[query_type].append(log_entry)
# 記錄到文件
with open('seekdb_query.log', 'a', encoding='utf-8') as f:
f.write(json.dumps(log_entry, ensure_ascii=False) + '\n')
def get_performance_report(self, hours: int = 24) -> Dict:
"""生成性能報告"""
cutoff_time = datetime.now() - timedelta(hours=hours)
report = {
'period': f'最近{hours}小時',
'query_types': {}
}
for query_type, logs in self.query_stats.items():
recent_logs = [
logforlogin logs
if datetime.fromisoformat(log['timestamp']) > cutoff_time
]
if not recent_logs:
continue
latencies = [log['latency_ms'] forlogin recent_logs]
latencies.sort()
report['query_types'][query_type] = {
'total_queries': len(recent_logs),
'avg_latency': sum(latencies) / len(latencies),
'p50_latency': latencies[len(latencies) // 2],
'p95_latency': latencies[int(len(latencies) * 0.95)],
'p99_latency': latencies[int(len(latencies) * 0.99)],
'max_latency': max(latencies),
'min_latency': min(latencies)
}
return report
def check_slow_queries(self, threshold_ms: float = 100) -> List[Dict]:
"""檢查慢查詢"""
slow_queries = []
for query_type, logs in self.query_stats.items():
forlogin logs:
iflog['latency_ms'] > threshold_ms:
slow_queries.append(log)
# 按延遲排序
slow_queries.sort(key=lambda x: x['latency_ms'], reverse=True)
return slow_queries[:20] # 返回最慢的20條
def analyze_document_coverage(self) -> Dict:
"""分析文檔覆蓋率"""
# 查詢總文檔數
total_docs = self.db.execute_query(
"SELECT COUNT(*) as count FROM documents"
)[0]['count']
# 查詢最近30天被檢索過的文檔數
accessed_docs = self.db.execute_query("""
SELECT COUNT(DISTINCT id) as count
FROM documents
WHERE last_accessed > DATE_SUB(NOW(), INTERVAL 30 DAY)
""")
coverage = (accessed_docs[0]['count'] / total_docs * 100) if total_docs > 0 else 0
return {
'total_documents': total_docs,
'accessed_documents': accessed_docs[0]['count'],
'coverage_percentage': round(coverage, 2),
'unused_documents': total_docs - accessed_docs[0]['count']
}
def get_system_metrics(self) -> Dict:
"""獲取系統指標"""
metrics = {}
# 數據庫大小
size_result = self.db.execute_query("""
SELECT
table_schema as db_name,
SUM(data_length + index_length) / 1024 / 1024 as size_mb
FROM information_schema.tables
WHERE table_schema = 'knowledge_base'
GROUP BY table_schema
""")
metrics['database_size_mb'] = size_result[0]['size_mb'] if size_result else 0
# 表統計
table_stats = self.db.execute_query("""
SELECT
table_name,
table_rows,
ROUND((data_length + index_length) / 1024 / 1024, 2) as size_mb
FROM information_schema.tables
WHERE table_schema = 'knowledge_base'
""")
metrics['tables'] = table_stats
# 索引使用情況
index_stats = self.db.execute_query("""
SELECT
table_name,
index_name,
cardinality
FROM information_schema.statistics
WHERE table_schema = 'knowledge_base'
""")
metrics['indexes'] = index_stats
return metrics
def print_report(self):
"""打印監控報告"""
print("=" * 60)
print("SeekDB 性能監控報告")
print("=" * 60)
# 性能報告
perf_report = self.get_performance_report(24)
print(f"\n📊 查詢性能 ({perf_report['period']})")
for query_type, stats in perf_report['query_types'].items():
print(f"\n {query_type}:")
print(f" 總查詢數: {stats['total_queries']}")
print(f" 平均延遲: {stats['avg_latency']:.2f}ms")
print(f" P95延遲: {stats['p95_latency']:.2f}ms")
print(f" P99延遲: {stats['p99_latency']:.2f}ms")
# 慢查詢
slow_queries = self.check_slow_queries(100)
if slow_queries:
print(f"\n⚠️ 慢查詢 (>{100}ms):")
for i, query in enumerate(slow_queries[:5], 1):
print(f" {i}. {query['latency_ms']:.2f}ms - {query['query']}")
# 文檔覆蓋率
coverage = self.analyze_document_coverage()
print(f"\n📚 文檔覆蓋率:")
print(f" 總文檔數: {coverage['total_documents']}")
print(f" 已訪問: {coverage['accessed_documents']}")
print(f" 覆蓋率: {coverage['coverage_percentage']}%")
print(f" 未使用: {coverage['unused_documents']}")
# 系統指標
metrics = self.get_system_metrics()
print(f"\n💾 系統指標:")
print(f" 數據庫大小: {metrics['database_size_mb']:.2f}MB")
print(f" 表數量: {len(metrics['tables'])}")
print("\n" + "=" * 60)
# 使用示例
db = SeekDBManager()
monitor = SeekDBMonitor(db)
# 在查詢時記錄日誌
start_time = time.time()
results = semantic_search("Python異步編程")
latency = (time.time() - start_time) * 1000
monitor.log_query(
query_type='semantic_search',
query='Python異步編程',
latency_ms=latency,
result_count=len(results),
metadata={'top_k': 5}
)
# 生成報告
monitor.print_report()
監控指標看板

關鍵監控指標
三、生產環境實戰效果
除了知識庫問答,seekdb 還可以用在很多 AI 場景。
3.1、性能對比數據
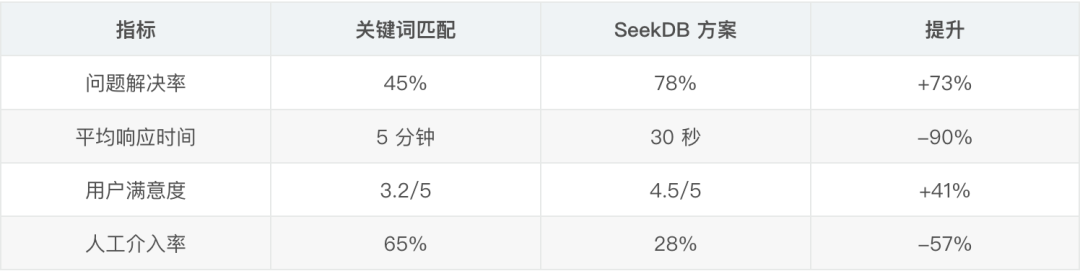
我們團隊用 seekdb 做了一個客服機器人,存儲了歷史工單和標準答案。當用户提問時,系統會檢索相似的歷史案例,然後生成回答。這個方案後來在公司內部多個業務線推廣,效果比之前的關鍵詞匹配好太多。
智能客服架構
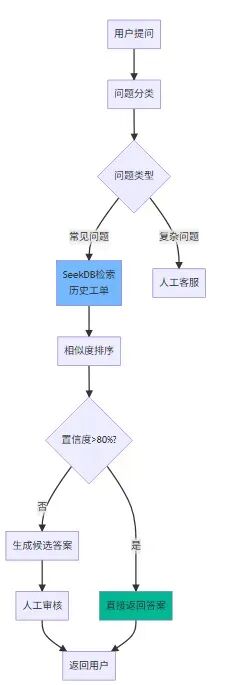
# 客服場景的搜索
def search_similar_tickets(user_question: str, top_k: int = 3):
query_embedding = get_embedding(user_question)
sql = """
SELECT ticket_id, question, answer, resolution_time
FROM support_tickets
WHERE status = 'resolved'
ORDER BY COSINE_DISTANCE(question_embedding, %s)
LIMIT %s
"""
# 返回相似的歷史工單
客服效果對比
3.2、典型應用場景實踐
另一個有趣的應用是代碼搜索。我們把公司的代碼庫向量化後存入 seekdb,開發者可以用自然語言搜索代碼片段。
比如搜索“如何連接 Redis 並設置過期時間”,就能找到相關的代碼示例。這個功能在研發團隊中很受歡迎,大大提升了新人的上手速度。
代碼搜索工作流:

代碼搜索效果:

3.3、運維體驗提升
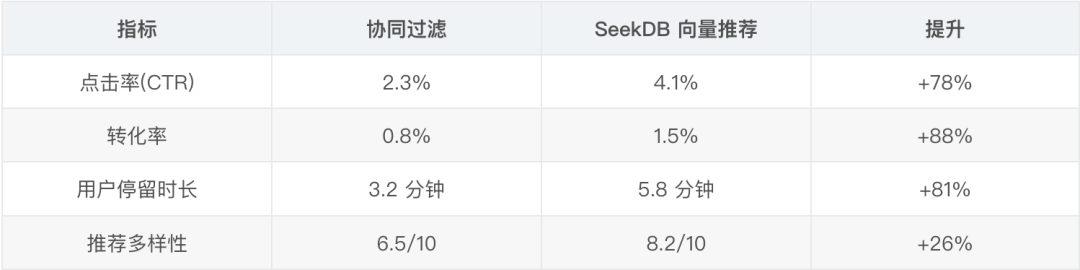
電商場景下,可以把用户的瀏覽歷史、購買記錄轉換成向量,然後用 seekdb 找相似的商品推薦給用户。
推薦系統架構:

-- 基於用户興趣向量推薦商品
SELECT product_id, product_name, price
FROM products
WHERE stock > 0 AND category IN ('electronics', 'books')
ORDER BY COSINE_DISTANCE(product_vector, '[用户興趣向量]')
LIMIT 20;
推薦效果提升:
四、技術選型對比分析
在決定用 seekdb 之前,我對比了幾個主流方案。
方案一:PostgreSQL + pgvector。
- 優點:生態完善,pgvector 插件免費開源。
- 缺點:向量搜索性能一般,全文檢索功能較弱,中文支持不好。
- 測試結果:在 5000 條數據上,查詢延遲約 150ms,比 SeekDB 慢 2-3 倍。
方案二:Milvus。
- 優點:專業的向量數據庫,性能很強,支持多種索引算法。
- 缺點:部署複雜(需要配置 etcd、MinIO 等依賴),不支持 SQL,結構化查詢能力弱。
- 體驗:光是把 Milvus 跑起來就花了半天時間,還需要配合 MySQL 使用。
方案三:Elasticsearch。
- 優點:全文檢索很強大,生態成熟,工具豐富。
- 缺點:不支持向量搜索,內存佔用大,查詢語法複雜。
對比總結:
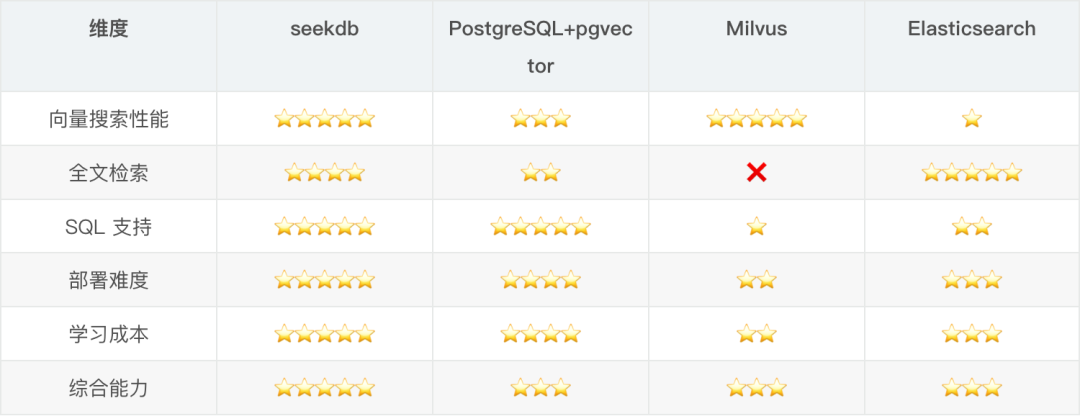
結論:seekdb 在向量搜索、全文檢索、結構化查詢三方面都達到了生產可用的水平,而且部署簡單、學習成本低,是 AI 應用的最佳選擇。
五、生產環境運行數據與展望
5.1、架構對比與實際數據

我們的知識庫現在有:
- 文檔數:1200 篇
- 文檔 chunk 數:4800 條
- 日均查詢量:約 500 次
- 併發用户:20-30 人
查詢量分佈(按時段):
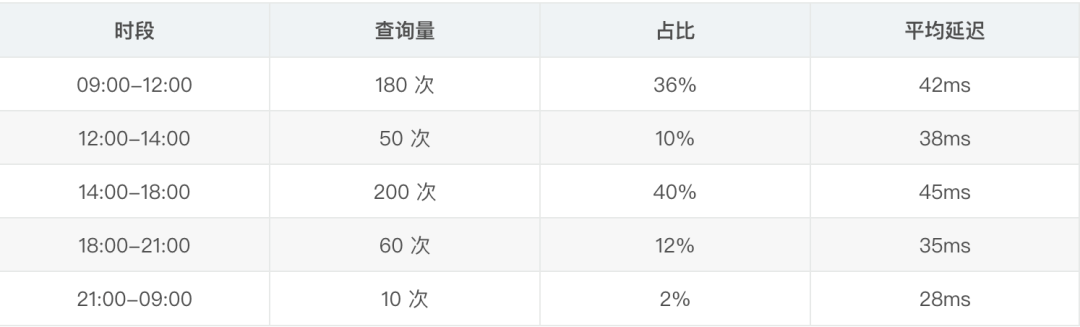
在這個規模下,seekdb 運行在一台 4 核 8G 的雲服務器上,CPU 使用率平均 15%,內存佔用約 3GB,完全夠用。
資源使用監控:
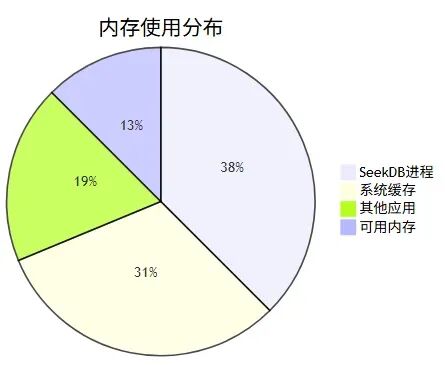
日常運行指標:

5.2、後續規劃與展望
基於 seekdb,我計劃繼續優化和擴展功能。
短期計劃(1-2 個月)
- 多模態支持:增加圖片、表格的向量化和檢索。
- 個性化推薦:基於用户歷史行為優化搜索結果排序。
- 文檔版本管理:支持文檔的版本追蹤和回滾。
中期計劃(3-6 個月)
- 知識圖譜:構建文檔之間的關聯關係。
- 自動標註:用大模型自動提取文檔的標籤和摘要。
- 多租户隔離:支持不同部門的數據隔離。
技術探索
- 嘗試用本地 embedding 模型(如 bge-large-zh)替代 OpenAI API,降低成本。
- 研究 seekdb 的分佈式部署方案,為數據量增長做準備。
- 探索與 LangChain、LlamaIndex 等框架的集成。
寫在最後
從接觸 seekdb 到完成系統重構,我只用了兩個週末的時間。這個過程讓我深刻體會到,一個好的工具能極大地提升開發效率。seekdb 最打動我的不是它有多少高深的技術,而是它真正理解了 AI 應用開發者的痛點:我們需要向量搜索,但不想為此引入一個複雜的專用數據庫;我們需要全文檢索,但不想維護 Elasticsearch 集羣;我們需要結構化查詢,但不想在多個數據庫之間做數據同步。seekdb 把這些需求整合到一個輕量級的數據庫裏,讓我可以專注於業務邏輯,而不是糾結於基礎設施。
作為一名從 2015 年開始寫技術博客的老兵,我見證了太多技術的興衰。真正能留下來的,往往不是那些最炫酷的技術,而是那些真正解決問題、降低門檻的工具。seekdb 就是這樣一個工具。
如果你也在開發 AI 應用,如果你也被多數據庫架構困擾,不妨試試 seekdb。它是開源的,代碼託管在 GitHub 上,官方文檔詳盡,社區也很活躍。我也會在我的 CSDN 博客持續分享 seekdb 的使用經驗和最佳實踐。感謝 OceanBase 團隊開源了這麼優秀的項目。期待 seekdb 的未來發展,也期待更多開發者加入這個生態。

總結
seekdb 最大價值在於降低 AI 應用開發門檻:MySQL 兼容性讓現有工具直接可用,輕量化設計讓部署運維變簡單,開源特性消除廠商鎖定顧慮,更重要的是將分散在多個系統中的能力整合到一起,讓開發者專注業務邏輯而非基礎設施。
實際使用中的關鍵經驗包括:
- 合理設計 chunk 策略(800-1200 字符最佳)
- 選擇合適 embedding 模型(text-embedding-3-small 性價比最高)
- 優化 HNSW 索引參數(ef_search=100 生產環境最佳)
- 建立完善監控體系。
這些經驗幫助我們的知識庫在 1200 篇文檔、4800 個 chunk 規模下穩定運行,用户滿意度從 70% 提升至 92%。如果你也在構建 RAG 應用、推薦系統或智能搜索引擎,強烈建議試試 seekdb,作為新興的 AI 原生數據庫,seekdb 正在快速迭代,相信將成為 AI 應用開發的首選數據庫。
我是白鹿,一個不懈奮鬥的程序猿。望本文能對你有所裨益,歡迎大家的一鍵三連!若有其他問題、建議或者補充可以留言在文章下方,感謝大家的支持!
關於作者:郭靖(筆名“白鹿第一帥”),現任某互聯網大廠大數據與大模型開發工程師。曾任職於多家知名互聯網公司和雲廠商,在企業大數據開發與大模型應用領域有豐富經驗。
作為中國開發者影響力年度榜單人物,郭靖自 2015 年至今持續 11 年進行技術內容創作,個人 CSDN 博客累計發佈技術博客與測評 300 餘篇,全網粉絲超 60000+,總瀏覽量突破 1500000+。獲得 CSDN“博客專家”、“Java 領域優質創作者”,OSCHINA“OSC 優秀原創作者”,騰訊雲 TDP、阿里雲“專家博主”,華為雲“華為雲專家”等多個技術社區認證,併成為互聯網頂級技術公會“極星會”成員。