

前言
經過之前幾節內容,我們的架構已經變為,nginx->envoy->backend,並且envoy作用sidecar,與nginx在同一個pod中工作,但是現在有個問題,nginx將流量轉發到envoy,需要修改nginx的配置文件
upstream backend_ups {
server 127.0.0.1:10000; # 原配置 backend_service:10000
}
server {
listen 80;
listen [::]:80;
server_name localhost;
location /test {
proxy_pass http://backend_ups;
}
}
從兩個方面來説:
- 部署層不應該依賴於業務層的配置,要將該配置解耦
- 底層轉發對於業務層應該是無侵入的,不應該侵入業務層的代碼或者配置,業務層不需要關心流量怎麼轉發
基於此,本文就來討論一下,如何在不修改業務層nginx配置的情況下,envoy怎麼劫持業務流量
原nginx配置文件:
upstream backend_ups {
server backend-service:10000;
}
server {
listen 80;
listen [::]:80;
server_name localhost;
location /test {
proxy_pass http://backend_ups;
}
}
環境準備
如果之前一直跟着操練的同學,可以重置一下測試環境: envoy測試環境
修改域名映射
使用hostAliases,將本來應該指向後端服務的backend_service換成指向本地127.0.0.1的envoy即可
修改nginx的pod編排文件
...
hostAliases:
- hostnames:
- backend-service
ip: 127.0.0.1
# 注意和containers一個級別
containers:
...
...
這種做法簡單有效,但是有2個問題:
- 如果backend的端口和envoy的代理端口不一樣,那就不能用。而在我們的這個例子中,envoy的代理端口和後端的服務端口,恰好都是10000,可以使用
- 域名映射是pod級別的,會讓所有的containers生效,nginx轉發的名字與envoy轉發的名字不能是同一個。在我們的例子當中,nginx的upstream轉發配置是
backend-service,envoy的轉發配置是backend-headless-service,恰好不同,可以使用
由此可知,該方法是最簡單的流量劫持,通過host映射,將流量轉發至envoy,但是限制太大,一旦上述2個條件不滿足,是沒法使用該方法的
使用iptables
到這裏,又要請出iptables了,作為老演員,iptables在前面(利用iptables記錄後端ip)就出場過,現在又需要了
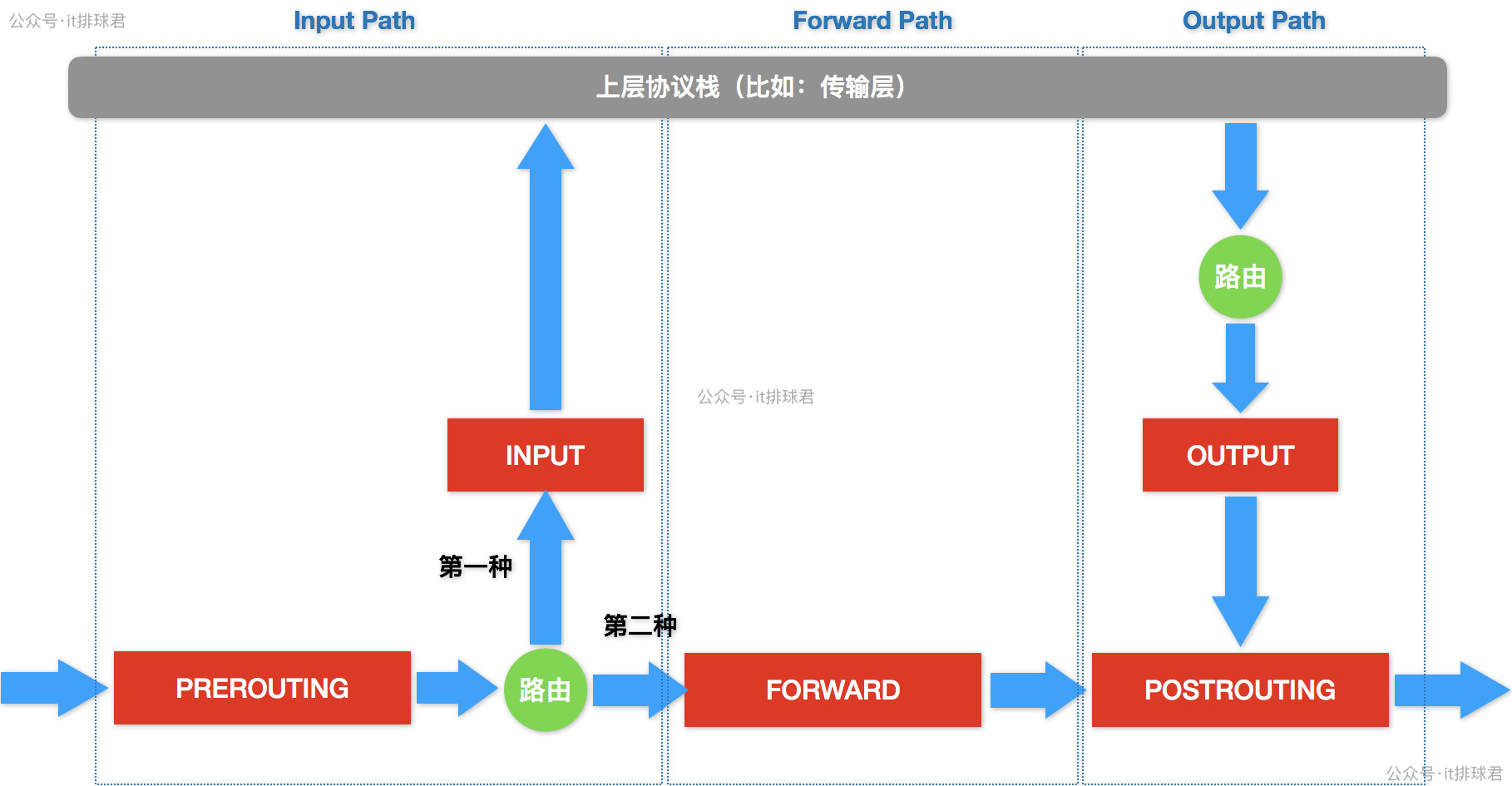
先來個高清大圖鎮場
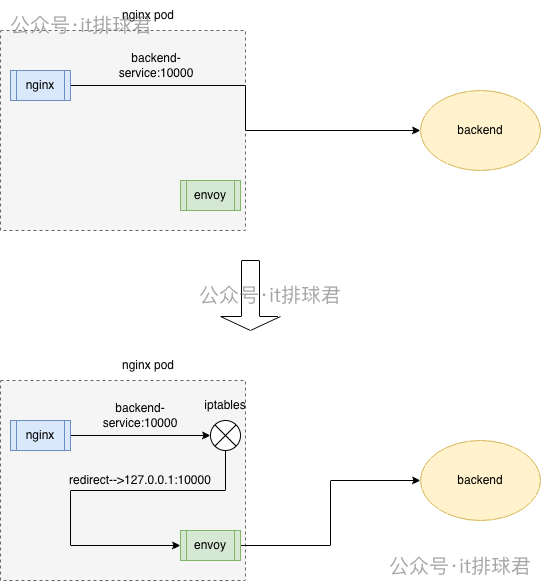
劫持所有的出流量
- 要將所有從nginx發送到backend-service:10000的流量劫持到envoy中(127.0.0.1:10000),通過iptables可以完成
- 由於本文中,後端服務backend與envoy監聽的都是同一個10000端口,所以需要做特殊的處理
-
目標端口為10000的端口,並且目標ip非127.0.0.1的流量,都要轉發到本地的10000端口
iptables -t nat -A OUTPUT -p tcp --dport 10000 ! -d 127.0.0.1/32 -j REDIRECT --to-ports 10000 -
由於端口都是10000,所以需要攔截nginx發送的,而放行envoy發出的,否則就要打環了。通過uid來確認envoy發出的流量
▶ kubectl exec -it nginx-test-557df7457b-dr7sf -c envoy -- id envoy uid=101(envoy) gid=101(envoy) groups=101(envoy)iptables -t nat -A OUTPUT -m owner --uid-owner 101 -j RETURN
-
整理一下最終的版本(注意順序):
iptables -t nat -A OUTPUT -m owner --uid-owner 101 -j RETURN
iptables -t nat -A OUTPUT -p tcp --dport 10000 ! -d 127.0.0.1/32 -j REDIRECT --to-ports 10000
root@wilson:/home/wilson/workspace# iptables -L -n -t nat
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
RETURN all -- 0.0.0.0/0 0.0.0.0/0 owner UID match 101
REDIRECT tcp -- 0.0.0.0/0 !127.0.0.1 tcp dpt:10000 redir ports 10000
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
但並不是所有的容器都可以使用iptables這個命令的,所以為了調試方便,我們使用nsenter進入
利用nsenter進入container
- 找到nginx容器id
▶ sudo crictl ps | grep nginx-test 091f9a85ba53e 49b0af0078643 30 minutes ago Running envoy 0 ac7556e89b5b3 nginx-test-557df7457b-dr7sf default 6b143efde5b0f 7f553e8bbc897 30 minutes ago Running nginx-test 0 ac7556e89b5b3 nginx-test-557df7457b-dr7sf default - 找到容器對應的pid
▶ sudo crictl inspect 6b143efde5b0f | grep -i pid "pid": 1, "pid": 1569896, "type": "pid" - 進入容器
▶ sudo nsenter -n --target 1569896 - 之後開始執行iptables命令即可
驗證是否能夠劫持流量
執行curl 10.22.12.178:30785/test,並且查看nginx日誌
10.244.0.1 - - [26/Dec/2025:02:15:43 +0000] "GET /test HTTP/1.1" 200 10.105.148.194:10000 40 "-" "curl/7.81.0" "-"
確實已經有日誌進入nginx,但是再查看envoy的時候,空空如也,説明流量並沒有被轉發至envoy
問題排查
由於環境特殊,envoy和backend都是10000端口,所以規則裏面新加了一條,只要是uid為101,全部都放行,不再匹配後面的規則
RETURN all -- 0.0.0.0/0 0.0.0.0/0 owner UID match 101
從目前的現象來看,所有的出流量都命中了這條規則,全部被放行了,趕緊去檢查一下nginx啓動用户的uid
▶ kubectl exec -it nginx-test-557df7457b-dr7sf -c nginx-test -- id nginx
uid=101(nginx) gid=101(nginx) groups=101(nginx)
問題找到!由於envoy用户與nginx用户都用101作為uid,導致iptables規則全部放過了,那要解決這個問題,有幾種方法:
- 最簡單最直接的,用另外一個uid作為envoy的uid
name: envoy # 和container name一個級別 ... securityContext: runAsUser: 1234 - 在打docker鏡像的時候指定uid,這個是最好的方案,徹底隔離開pid
由於在調試階段,我們使用第一種方案,臨時換pid
有位老哥要問了,為什麼同一個pod裏面可以有相同的uid呢?因為每個容器有自己的pid namespace,所以就算在容器裏面,他們依然試隔離開的,當然也可以直接配置共享同一個pid namespace:shareProcessNamespace: true
最終結果
[2025-12-26T03:35:12.708Z] "GET /test HTTP/1.0" 200 40 1 856d3200-abb3-486f-8e4c-8441f20bdbb0 "curl/7.81.0" "-" 10.244.0.114:10000 app_service -
[2025-12-26T03:35:12.937Z] "GET /test HTTP/1.0" 200 40 1 271f828e-5bd0-4fa1-95dc-3f17364ba8b8 "curl/7.81.0" "-" 10.244.0.111:10000 app_service -
流量終於被iptables轉發至envoy,並且轉發到後端的backend去了
使用initContainers配置
上面已經驗證了,通過iptables可以劫持相關流量,而業務層不需要做改變即可完成。現在需要將這一套方法變成實際可行的工程方案,並且自動執行,不可能每次都人工修改
使用initContainers,讓每一個pod啓動都優先處理iptables配置
initContainers:
- args:
- |
apk add --no-cache iptables
iptables -t nat -A OUTPUT -m owner --uid-owner 1234 -j RETURN
iptables -t nat -A OUTPUT -p tcp --dport 10000 ! -d 127.0.0.1/32 -j REDIRECT --to-ports 10000
command:
- /bin/sh
- -c
image: alpine:3.23
imagePullPolicy: Always
name: iptables-init
resources: {}
securityContext:
privileged: true
這裏不太優雅的是該容器每次都要先安裝iptables,可以自己打一個鏡像,預裝好iptables
攔截入口流量
上述描述的是離開nginx的流量,使用iptables output鏈完成。比如有個需求是需要攔截如的流量,那也很簡單,只需要在prerouting鏈上編寫規則即可。掌握iptables之後,就能融會貫通了
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 10000
iptables -t nat -A OUTPUT -m owner --uid-owner 1234 -j RETURN
第一條規則就是所有來訪問80端口的請求都會重定向到127.0.0.1:10000去。而第二條規則保證了,從envoy發出的請求不會被任何劫持,還是避免打環
小結
本文詳細描述了怎麼使用iptables來劫持流量,讓業務層無感的方式將流量轉發到envoy,這已經將部署層與業務層解耦,業務完全不需要關心底層運行邏輯。Istio的底層正是使用iptables來實現流量攔截和重定向的。離手搓istio又近了一步,當然是開玩笑,本系列的重點還是一步一步去理解服務治理要解決的問題以及選擇對應的方案來匹配自己的系統
但是這裏又提出一個問題,這要反覆折騰,讓流量不斷的從kernel space 與user space中來回穿梭
業務層nginx --> iptables --> envoy(User space) --> iptables
消耗了大量系統資源,在一個高併發的系統當中,這是非常浪費資源的情況,那這種情況該怎麼辦呢?這是很後後後面的東西了,我們先把其他簡單的問題解決再來討論這種優化的問題
後記
關於不同的uid的問題,nginx為101,envoy也是101,如果在這種情況下強行配置shareProcessNamespace: true,會發生什麼事情?
containers: # 注意是containers級別的
...
shareProcessNamespace: true
登錄進去看看
▶ kubectl exec -it nginx-test-54f5b78d57-x4kmj -c envoy bash
root@nginx-test-54f5b78d57-x4kmj:/# ps -ef
UID PID PPID C STIME TTY TIME CMD
65535 1 0 0 03:09 ? 00:00:00 /pause
root 7 0 0 03:09 ? 00:00:00 nginx: master process nginx -g daemon off;
envoy 27 0 0 03:09 ? 00:00:00 envoy -c /etc/envoy/envoy.yaml
envoy 33 7 0 03:09 ? 00:00:00 nginx: worker process
envoy 34 7 0 03:09 ? 00:00:00 nginx: worker process
可以看到,所有的用户都在一個pid namespace下面,並且101用户既啓動了nginx,又啓動了envoy,由於我登錄的envoy container,所以看到了用envoy啓動了nginx,如果使用nginx登錄,那肯定是用nginx啓動了envoy
這樣做了感覺降低了namespace的隔離性,並且信號處理混亂,因為容器的1號進程往往可以接收到k8s的各種信號量,如果全部堆在一個namespace,需要做好信號量傳遞,更是增加了複雜度
所以共享pid namespace,是需要做好評估的
聯繫我
- 聯繫我,做深入的交流

至此,本文結束