









前言
書接上文,上一小節簡單介紹了多元迴歸的基本原理、使用方式,本小節來實踐:qps與cpu、內存、磁盤io、網絡io之間的關係
獲取數據
參考一元線性迴歸的獲取方式
from flow import *
from datetime import datetime
start_time = datetime.strptime('2025-04-06 00:00:00', '%Y-%m-%d %H:%M:%S').timestamp()
end_time = datetime.strptime('2025-04-06 23:59:59', '%Y-%m-%d %H:%M:%S').timestamp()
step = 600
sls_step = 3600*6
query = get_query_data(start_time, end_time, sls_step)
cpu = get_cpu_data(start_time, end_time, step)
memory = get_memory_data(start_time, end_time, step)
network_in = get_network_in_data(start_time, end_time, step)
network_out = get_network_out_data(start_time, end_time, step)
file_read = get_file_read_data(start_time, end_time, step)
file_write = get_file_write_data(start_time, end_time, step)
print('cpu 數據個數為{} ,前10數據為{}'.format(len(cpu), cpu[:10]))
print('query 數據個數為{} ,前10數據為{}'.format(len(query), query[:10]))
print('memory 數據個數為{} ,前10數據為{}'.format(len(memory), memory[:10]))
print('network_in 數據個數為{} ,前10數據為{}'.format(len(network_in), network_in[:10]))
print('network_out 數據個數為{} ,前10數據為{}'.format(len(network_out), network_out[:10]))
print('file_read 數據個數為{} ,前10數據為{}'.format(len(file_read), file_read[:10]))
print('file_write 數據個數為{} ,前10數據為{}'.format(len(file_write), file_write[:10]))
腳本!啓動:

特徵標準化
特徵數據已經獲取完成,看起來是沒問題,但是仔細分析,好像又有點問題,首先cpu數據非常小,內存數據又很大,特徵數據之間的數量級差距太大了,特別是在多元迴歸中,不同特徵的量綱和尺度可能差異巨大。若未標準化, 迴歸係數的數值大小會受特徵尺度影響,導致難以直接比較特徵的重要性
那首先先人為的進行數據縮放
query = [round(x/10000, 4) for x in get_query_data(start_time, end_time, sls_step)]
cpu = get_cpu_data(start_time, end_time, step)
memory = [round(x/1024/1024/1024, 4) for x in get_memory_data(start_time, end_time, step)]
network_in = [round(x/1024/1024, 4) for x in get_network_in_data(start_time, end_time, step)]
network_out = [round(x/1024/1024, 4) for x in get_network_out_data(start_time, end_time, step)]
file_read = [round(x/1024/1024, 4) for x in get_file_read_data(start_time, end_time, step)]
file_write = [round(x/1024, 4) for x in get_file_write_data(start_time, end_time, step)]
看看效果

調整過後,特徵數據都是2位數的了,只不過單位不一樣
- query的單位是萬
- memory的單位是G
- network_in的單位是M
- network_out的單位是M
- file_read的單位是K
- file_write的單位是K
再進行數據標準化,數據標準化的公式
- μ 是特徵的均值,
- σ 是特徵的標準差。
標準化後,所有特徵的尺度統一,均值為0,標準差為1
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
訓練模型
多元迴歸!啓動
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler
from flow import *
from datetime import datetime
import pandas as pd
def adjusted_r2(r2, n, p):
return 1 - (1 - r2) * (n - 1) / (n - p - 1)
start_time = datetime.strptime('2025-04-06 00:00:00', '%Y-%m-%d %H:%M:%S').timestamp()
end_time = datetime.strptime('2025-04-06 23:59:59', '%Y-%m-%d %H:%M:%S').timestamp()
step = 600
sls_step = 3600*6
query = [round(x/10000, 4) for x in get_query_data(start_time, end_time, sls_step)]
cpu = get_cpu_data(start_time, end_time, step)
memory = [round(x/1024/1024/1024, 4) for x in get_memory_data(start_time, end_time, step)]
network_in = [round(x/1024/1024, 4) for x in get_network_in_data(start_time, end_time, step)]
network_out = [round(x/1024/1024, 4) for x in get_network_out_data(start_time, end_time, step)]
file_read = [round(x/1024/1024, 4) for x in get_file_read_data(start_time, end_time, step)]
file_write = [round(x/1024, 4) for x in get_file_write_data(start_time, end_time, step)]
features = {
'feature1': cpu,
'feature2': memory,
'feature3': network_in,
'feature4': network_out,
'feature5': file_read,
'feature6': file_write,
}
data = {
'result': query,
}
data.update(features)
df = pd.DataFrame(data)
X = df[[
'feature1',
'feature2',
'feature3',
'feature4',
'feature5',
'feature6',
]]
y = df['result']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
MSE = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print("R²:", r2)
print("MSE:", MSE)
p = len(features.keys())
n = len(data['result'])
adjusted_r2 = adjusted_r2(r2, n, p)
print(f"調整決定係數 (Adjusted R²): {adjusted_r2}")
腳本!啓動:

完美的模型,來得太順利反而有點不太習慣了
通過lasso迴歸來看下哪一些參數是強相關的
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.1)
lasso.fit(X_scaled, y)
for i, coef in enumerate(lasso.coef_, 1):
print(f'x{i} 的迴歸係數:{coef:.4f}')
lasso迴歸檢查特徵
腳本!啓動:
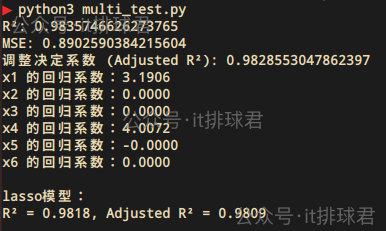
這裏面已經有一些特徵在划水了,找出來,把他們裁掉!當然lasso迴歸已經自動幫我們把假裝幹活的特徵自動裁員了(打工人,哭死=_=!),但是還是有必要找出原因來的
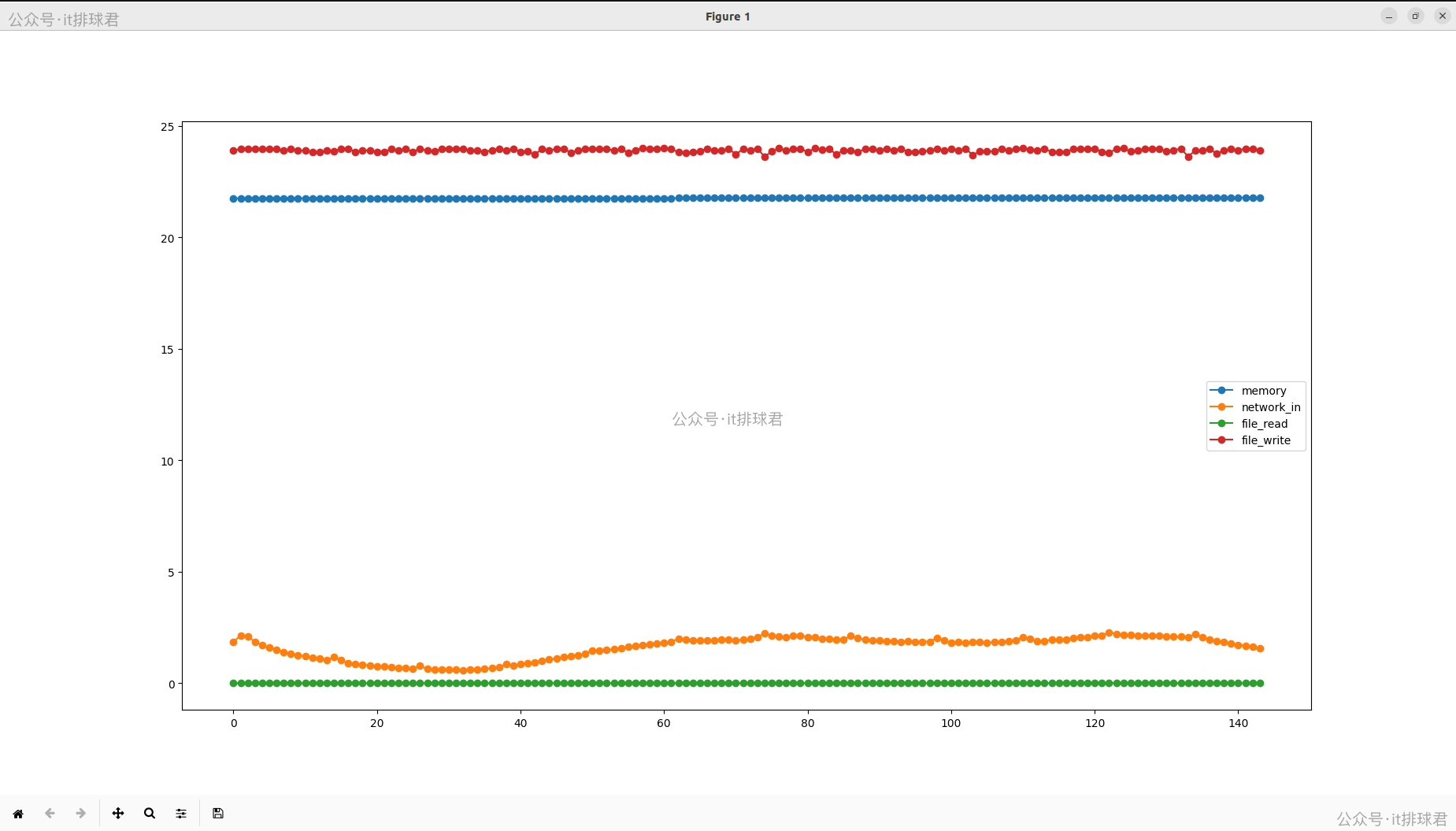
將這4個特徵畫個圖看一下
X2(內存)、X5(file_read)、X6(file_write)符合預期:特徵是一條直線,不隨着query波動
- 首先看X2,這是內存。在業務服務中,由於是java服務,內存在啓動的時候劃分了一大塊交給jvm管理,所以在操作系統看來,變化不大,要折騰都在jvm內部折騰。所以memory是一條直線
- X5,這是file_read。在業務服務中,幾乎沒有的file_read,都是通過network_read,所以file_read一條直線
- X6,這是file_write。在業務服務中,都是緩存寫,再由操作系統同步到磁盤,所以file_write是由操作系統決定的,近似一條直線
再看X3,這是network_in,按理説這個特徵是與query強相關的,有明顯的數據波動,但是lasso迴歸的時候還是把它略掉了,認為它是一個多餘的特徵
t檢驗
定義
檢驗每個自變量是否真正影響了結果。更直接一點,揪出誰在工作誰在划水!
實踐
先介紹一個專門用於數據分析的工具:statsmodels,用來做統計推斷,並且提供額外的模型檢查工具
安裝也很簡單:
pip3 install statsmodels
添加代碼:
import statsmodels.api as sm
X_with_const = sm.add_constant(X)
sm_model = sm.OLS(y, X_with_const).fit()
print(sm_model.summary())
腳本!啓動:
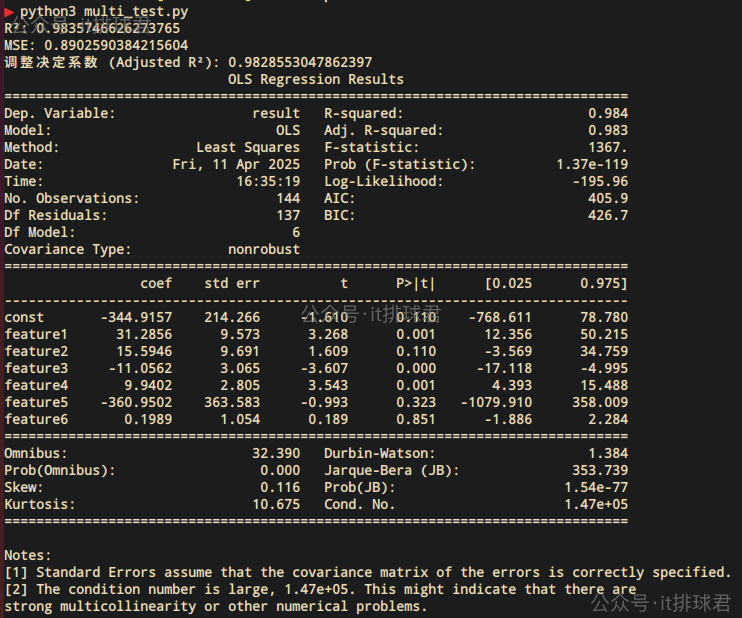
這怎麼還越整越複雜了!這輸出的都是些什麼東西啊?!
彆着急,這部分主要是描述t檢驗,先拿出t檢驗相關的數據
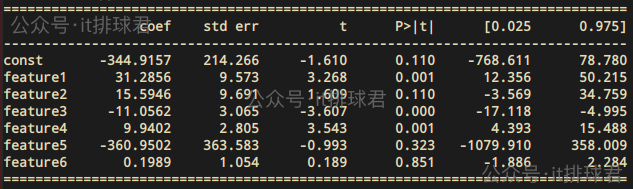
簡單解釋一下:
- 第一列就是參數,const是常數項,也就是公式中的\(β_0\),其餘的是6個參數
- 第二列coef,是所謂的係數,就是\(β_1 β_2 \dots β_n\)
- 第三列std err,就是所謂的標準誤差
- 第四列t值,計算公式為:
- 第五列P>|t|,所謂的P值,計算公式就不列出來了,我自己都沒搞明白 =_=!,只要記住非常有用就行,一會會用
- 最後兩列一起看[0.025 0.975],這是所謂的置信區間,什麼置信區間?正態分佈熟悉吧,記住置信區間和正態分佈強相關就行了,
這裏意味着,有95%的係數是落在[12.36, 50.21] 之間feature1 31.2856 9.573 3.268 0.001 12.356 50.215
説了這麼半天,最直接有效的就是看P值,越接近0,那就説明該係數越相關
還有個更簡單的方法,直接丟gpt看看
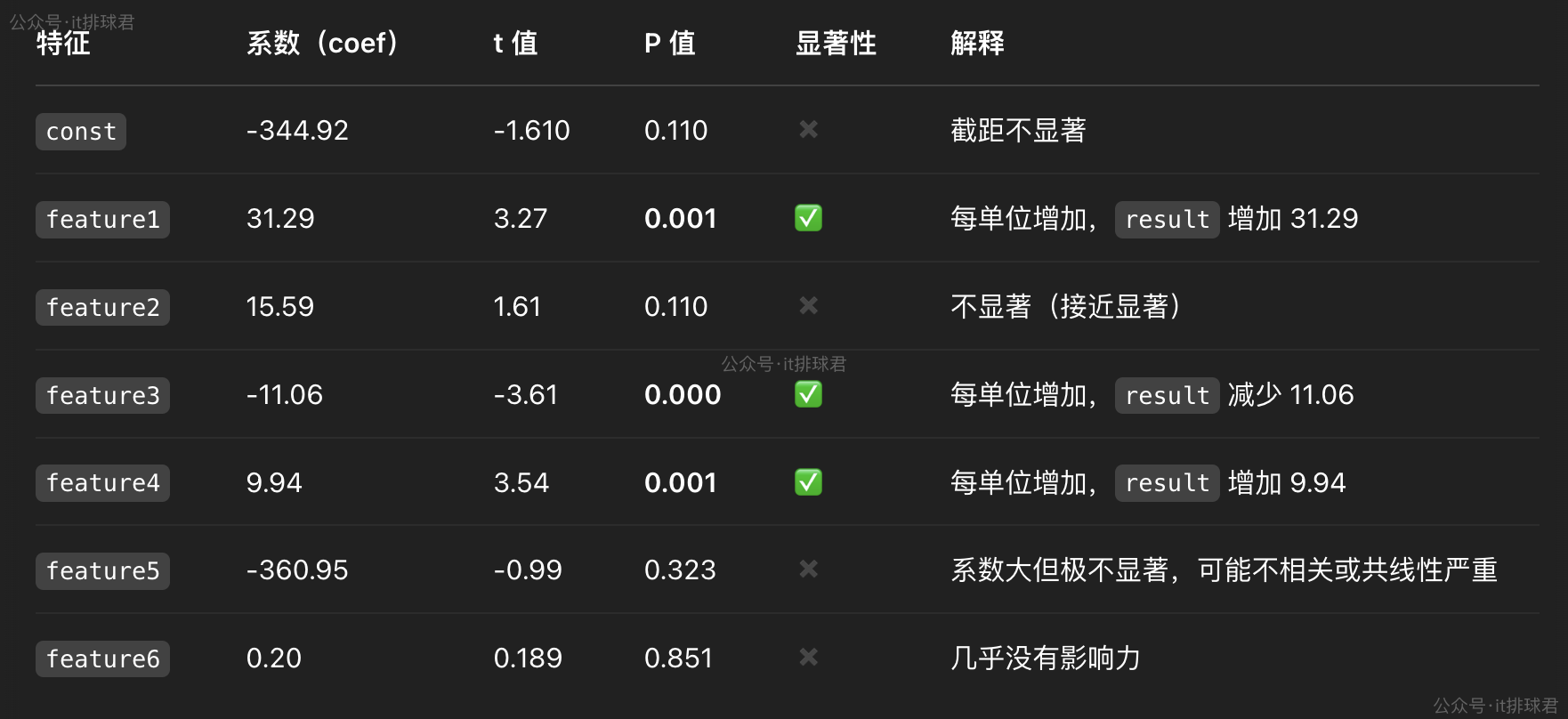
ai牛逼,科技提高工作效率。至此,通過t檢驗,也可以發現有哪些特徵是強相關的,哪些特徵是無用的。feature1(cpu)、feature3(network_in)、feature4(network_out)這3個特徵對於結果有重大的影響。之前的lasso回 歸中,feature3(network_in)已經被判定了對於結果沒有重大影響
為什麼這兩個評估工具給出了不一樣的答案呢?
多重共線性
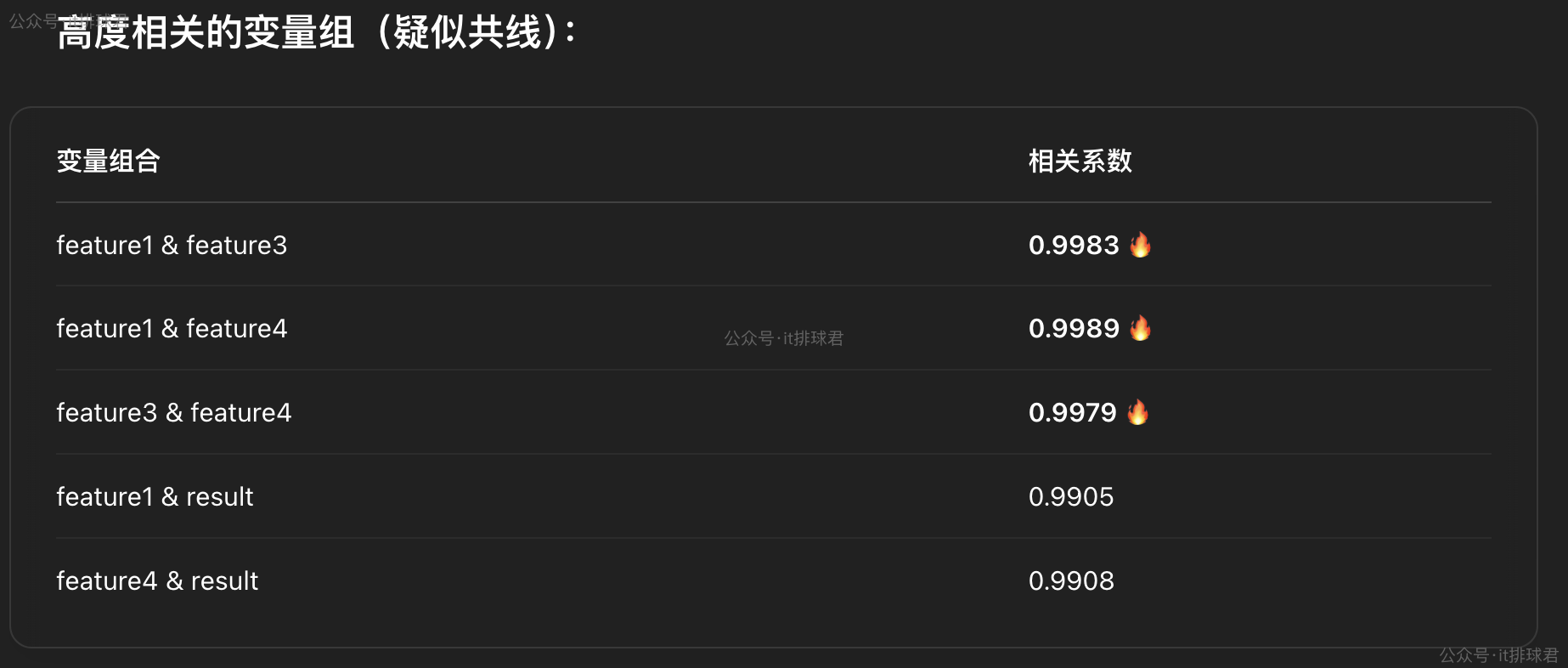
迴歸模型中兩個或多個預測變量(自變量)之間存在高度相關性的情況。針對於我們的這個模型,很容易聯想到feature3(network_in)、feature4(network_out),是高度相關性的
VIF(方差膨脹因子)
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif_df = pd.DataFrame()
vif_df['features'] = X.columns
vif_df['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(vif_df)
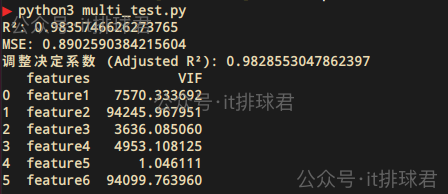
VIF > 10,説明存在嚴重的多重共線性
相關係數矩陣
corr_matrix = df.corr()
print(corr_matrix)
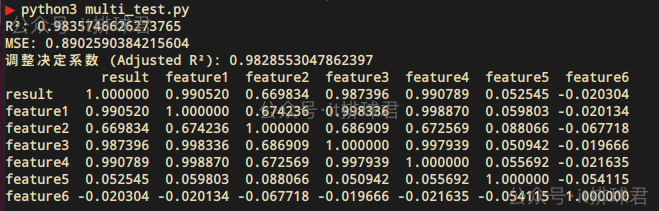
直接丟進gpt
小結
根據上述分析,query可以直接通過cpu特徵就可以分析出來了,其他的特徵存在與否,其實並不重要
在statsmodels的報告中已經揭示了我們的模型存在嚴重的共線性:
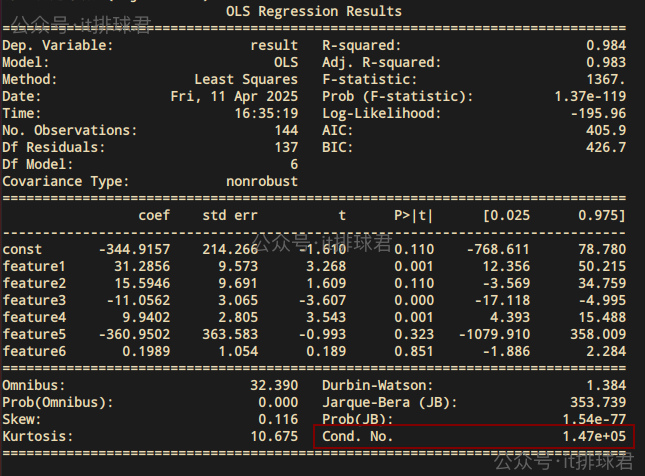
Cond. No.這個值大於1000的時候,就表示存在了嚴重的多重共線性問題
多重共線性帶來的問題:
- 迴歸係數估計變得不穩定,小的數據變化可能導致係數大幅變化
- 係數標準誤增大,t統計量減小,導致變量可能顯得不顯著
- 難以區分單個變量對因變量的獨立影響
- 雖然預測可能仍然準確,但解釋單個變量的影響變得困難
ridge(嶺迴歸)
數學模型
實踐
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1.0)
ridge.fit(X_scaled, y)
y_ridge = ridge.predict(X_scaled)
r2_ridge = r2_score(y, y_ridge)
r2_adj_ridge = adjusted_r2(r2_ridge, n, 7)
for i, coef in enumerate(ridge.coef_, 1):
print(f'x{i} 的迴歸係數:{coef:.4f}')
print("\nridge模型:")
print(f"R² = {r2_ridge:.4f}, Adjusted R² = {r2_adj_ridge:.4f}")
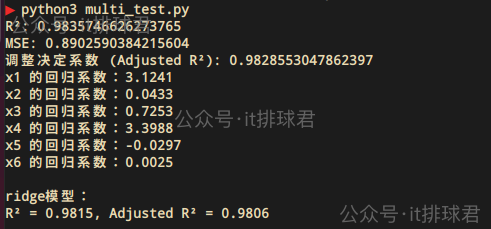
ridge迴歸中,所有係數都會被壓縮向零但不會完全為零,所以不像lasso迴歸中直接為0那麼直觀:
- 絕對值較大的係數通常對應更重要的特徵
- 正負號表示特徵與目標變量的正/負相關關係
如圖所示,X1與X4是更為重要的特徵,這與lasso迴歸得出的結論是一樣的
總結
多元迴歸的複雜性,是由於特徵參數過多帶來的新的問題,無用特徵、多重共線性,要找出特徵的權重,要用到一些檢驗方法,比如t檢驗、VIF、相關矩陣係數等。如果只想關注模型泛化能力,可以通過lasso、ridge等迴歸來自動篩選特徵
綜上所述,本次多元迴歸之旅最終的結果又回到了一元迴歸,饒了一大圈又回到了原點,但是並非毫無收穫,除了收穫了一大堆模型評估方法,什麼調整決定係數、t檢驗、VIF等,還有一堆陌生的檢測算法,lasso迴歸、ridge迴歸等。並且提供了今後對於多元迴歸的一些方法論
裝杯時刻
那位兄弟問了,你這洋洋灑灑搞了這麼半天,怎麼裝杯呢?
今天這個就不給老闆彙報了,畢竟如果只關注結果的話,又回到了一元迴歸的方法論來,但是依然有價值分享給同事,畢竟這一堆猛烈的方法輸出,每月一次的團隊培訓內部培訓,這不是又有題材了不是嗎?
聯繫我
- 聯繫我,做深入的交流

至此,本文結束
在下才疏學淺,有撒湯漏水的,請各位不吝賜教...
