

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第四課的第二週內容,2.3到2.4的內容。
本週為第四課的第二週內容,這一課所有內容的中心只有一個:計算機視覺。應用在深度學習裏,就是專門用來進行圖學習的模型和技術,是在之前全連接基礎上的“特化”,也是相關專業裏的一個重要研究大類。
這一整節課都存在大量需要反覆理解的內容和機器學習、數學基礎。 因此我會盡可能的補足基礎,用比喻和實例來演示每個部分,從而幫助理解。
第二週的內容是對一些經典網絡模型結構和原理的介紹,自然會涉及到相應的文獻論文。因此,我也會在相應的模型下附上提出該模型的論文鏈接。
本篇的內容關於殘差網絡,同樣是為了讓深層網絡仍能夠有效訓練,緩解梯度現象而出現的技術。
1. 什麼是殘差網絡(ResNet)?
殘差網絡英文原名為 residual networks ,簡稱 ResNet,它在 2015 年的一篇論文:Deep Residual Learning for Image Recognition 中被提出,這篇論文提出了殘差學習框架,是 ResNet 系列網絡的開創之作。
要了解什麼是殘差網絡,首先要了解什麼是殘差。
1.1 什麼是殘差?
先給出一個殘差學習的嚴謹結論:殘差學習並不是讓網絡直接學習目標映射,而是讓網絡學習目標映射相對於“恆等映射”的偏差。
你可以把恆等映射理解為“什麼都不做,直接把輸入原樣傳下去”,而殘差學習做的事情,就是在這個“原樣輸出”的基礎上,學習還需要額外補充哪些變化。
用一句直觀的話説就是:這一層並不負責“從零得到結果”,而只負責在原有輸入的基礎上“該改多少”。
下面我們從普通網絡的傳播邏輯開始,對比引出殘差的含義。
(1) 非殘差網絡的傳播邏輯
在監督學習的神經網絡裏,每一層都試圖直接學一個從輸入到輸出的映射關係
可以寫成:
意思是:給你輸入 \(x\) 和運算單元,你自己學習怎麼映射出輸出 \(y\)。
這種結構在淺層網絡中通常沒有問題,但當網絡不斷加深時,會逐漸暴露出訓練困難。
常見原因包括梯度消失或爆炸等優化問題。
但是注意:普通深層網絡的問題並不在於“表達能力不夠”,而在於“優化過程本身變得困難”。
因此,即便梯度問題被一定程度緩解,普通深層網絡仍然難以有效逼近“恆等映射”,從而導致訓練誤差隨着深度增加反而上升。這種現象在 ResNet 論文中被稱為 degradation problem(退化問題)。
簡單舉個例子:
假設有一個極簡的一維迴歸任務:
- 輸入樣本:\(x = 5\)
- 真實標籤:\(y = 8\)
在非殘差網絡裏,這一層要直接學: $$y = F(x)$$也就是説,這一層的目標是學會: $$F(5) = 8$$如果當前網絡參數學得不好,比如此時: $$F(5) = 3$$那麼誤差就是: $$\text{error} = 8 - 3 = 5$$此時,誤差信號需要通過多層非線性變換向前反向傳播,深層參數只能接收到被多次“稀釋”後的梯度,導致參數更新緩慢、訓練困難。這也是為什麼深層普通網絡並不一定比淺層網絡更容易訓練。
因此,深層網絡並不像我們直覺裏那樣的“結構越複雜,擬合能力越強”。
為了讓深層網絡仍能訓練,其中一種解決方法就是應用殘差學習。
(2)殘差是什麼?
在數學上,“殘差”可以理解為目標值與某個基準值之間的差異。在殘差網絡中,這個“基準值”並不是零,而是恆等映射本身,也就是 \(x\)。
更準確地説,殘差學習並不是讓網絡直接去學習目標映射 \(H(x)\),而是將其重寫為: $$H(x)=x+F(x)$$其中:
- \(x\) 表示輸入特徵(恆等映射)
- \(F(x)\) 表示網絡需要學習的殘差項,即目標映射相對於 \(x\) 的偏差
需要注意的是,這裏的“殘差”並不是"標籤減輸入"這樣的一個已知量,而是通過優化損失函數間接逼近的結果。
我們繼續:
1.2 如何應用殘差形成殘差網絡?
將上面的邏輯應用到神經網絡結構中,其核心做法可以概括為一句話:不直接學習輸出本身,而是學習輸出相對於輸入的修正量,並將二者相加得到最終結果。
簡單來説就是:“我不讓你學 \(y\),我讓你學 \(y\) 和 \(x\) 之間的差。”
也就是:
這裏的 \(F(x)\) 通常由若干層卷積、線性變換和非線性激活函數組成,而 \(x\) 則通過一條恆等分支直接傳遞到輸出端。
換句話説,網絡這一層只負責回答一句話:“保持輸入不變的情況下,我還需要補充或修正多少?”
現在我們把殘差應用到剛剛的例子裏:
- 輸入:\(x = 5\)
- 目標:\(y = 8\)
殘差網絡不讓這一層直接學 \(y\),而是先把輸入“原封不動”地傳下去,再只學差值:
代入數值:
於是這一層真正要學習的目標變成:
如果當前網絡學得不太好,比如:
那麼輸出是:
誤差只剩:
你可以看到一個關鍵變化:
網絡不再為“從 0 到 8”負責,而只是為“在 5 的基礎上補多少”負責。
可以看到,與直接從零擬合目標相比,殘差結構將學習任務轉化為圍繞輸入的小幅修正。
更重要的是,由於恆等分支的存在,反向傳播時梯度可以繞過複雜的非線性變換直接傳遞到前層,從而顯著緩解深層網絡的優化難題。
瞭解了殘差網絡本身後,我們來看看如何具體實現殘差網絡。
2. 如何實現殘差網絡?
同樣先用一句話説明一下結論:要實現殘差網絡,就要使用旁路連接形成殘差塊,實現殘差學習。
現在,我們來逐個展開這句話裏出現的新名詞。
2.1 什麼是旁路連接(shortcut connections)?
旁路連接是一種網絡結構設計,用於在神經網絡中實現殘差映射,從而支持殘差學習。
用嚴謹的説法來具體描述一下它:旁路連接是指在神經網絡中引入一條恆等映射(或線性映射)分支,將某一層的輸入 \(x\) 直接傳遞到後續層,在後續層的線性變換結果與非線性激活之前,與主分支的輸出進行融合(通常為逐元素相加),從而在正向傳播中顯式保留輸入信息,並在反向傳播中為梯度提供一條直接的傳遞通道。
而説簡單點,旁路連接就像給網絡開了一條“捷徑”:你不再要求每一層都從頭學習一個完整的映射關係,而是把已有的信息直接送到後面去,讓網絡只需要決定“在此基礎上還要改多少”。
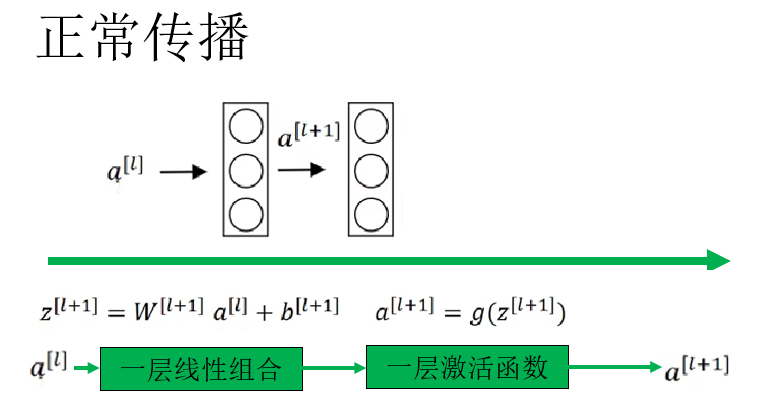
我們已經十分熟悉它的傳播過程了,就不再多説了。
現在,我們按照上面的定義,在這一層中加入旁路連接:
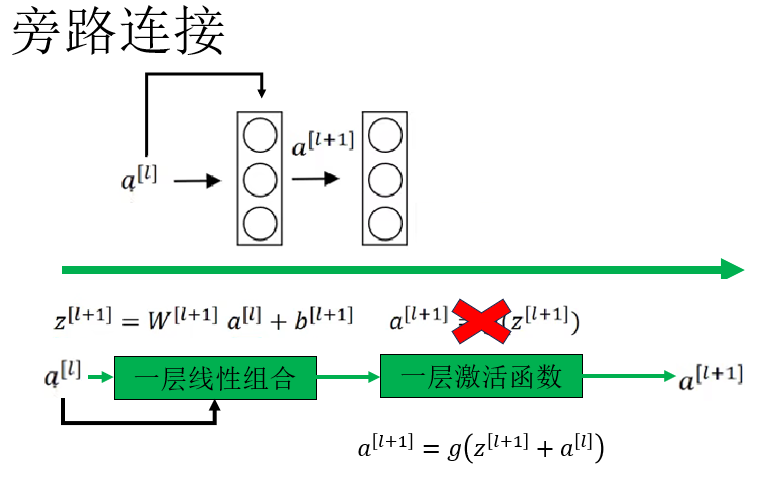
可以看到,在加入旁路連接後,\(a^{[l]}\) 不僅沿着原有的主分支參與下一層的線性變換,還通過旁路連接這一條恆等分支,直接傳輸到下一層的線性輸出之前,並與 \(z^{[l+1]}\) 相加,隨後再經過激活函數得到 \(a^{[l+1]}\)。
這種結構改變了網絡在正向傳播階段的建模方式:網絡不再直接學習目標映射 \(H(x)\),而是將其拆解為“輸入本身”與“輸入到目標之間的修正量”兩部分,即學習殘差函數:
從而使得深層網絡在訓練過程中更容易優化,同時在反向傳播時,梯度也可以通過恆等分支直接傳播,有效緩解隨網絡加深而出現的退化問題。
2.2 什麼是殘差塊(residual block)?
如果你仔細讀了上面提到的旁路連接的定義,就會發現這一點:旁路連接並不侷限於跨越單一層。
是的,實際的殘差網絡中,輸入往往會跨越多箇中間層直接傳遞。由主分支中的若干層卷積、線性變換與非線性激活函數,以及與之配套的一條旁路連接,共同構成的這一基本結構單元,被稱為一個殘差塊。
殘差塊是 ResNet 中最基本、也是最重要的結構單元。整個 ResNet 的主幹網絡,正是通過不斷堆疊這樣的殘差塊構建而成的。
接下來,我們繼續沿用剛剛的例子,具體看看一個典型的殘差塊在結構上是如何實現的,我們延伸剛剛的網絡結構如下:
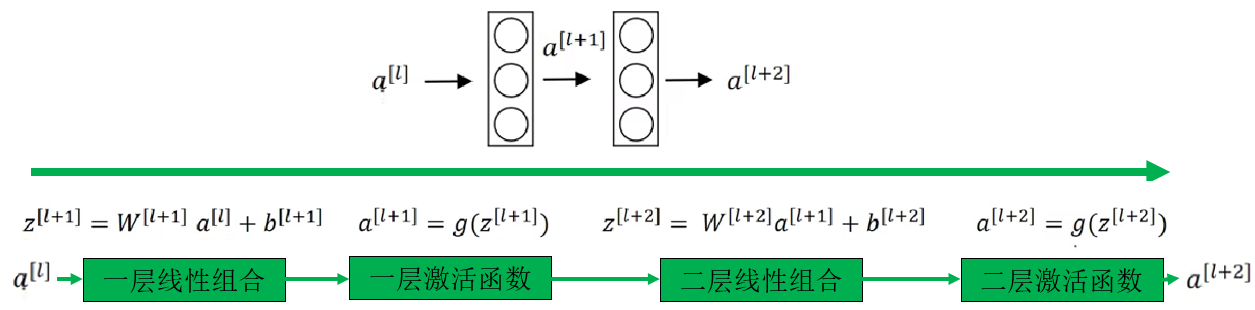
它的傳播同樣簡單明瞭。現在,我們試試跨越一層的旁路連接:
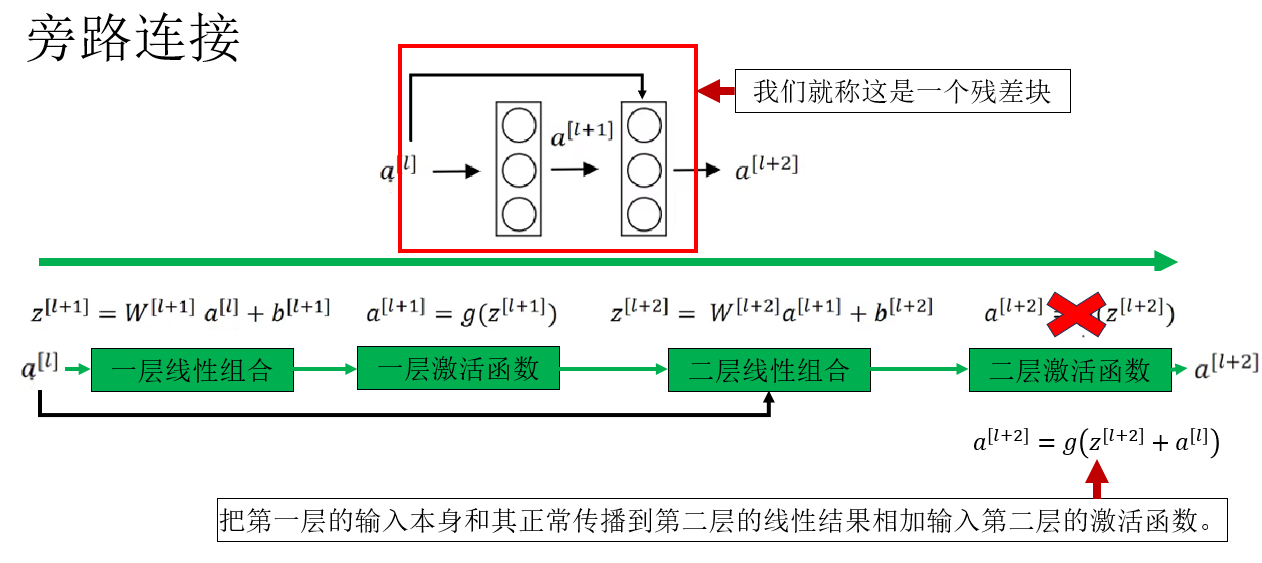
可以看到,此時旁路連接從第 \(l\) 層的輸出 \(a^{[l]}\) 出發,跨越第 \(l+1\) 層,直接與主分支在第 \(l+2\) 層的線性輸出進行融合,並共同生成最終的輸出 \(a^{[l+2]}\)。
從整體上看,這一結構不再關注中間每一層的具體細節,而是將輸入 \(a^{[l]}\) 映射為輸出 \(a^{[l+2]}\),其數學形式可以概括為:
其中,\(F(\cdot)\) 表示由主分支中的若干層共同構成的殘差函數。
因此,殘差塊並不是簡單意義上的“若干層網絡”,而是一個以旁路連接為核心、用於學習殘差映射的整體函數單元。在這一視角下,輸入 \(a^{[l]}\) 與輸出 \(a^{[l+2]}\) 共同界定了一個殘差塊的作用範圍。
總結一下:殘差網絡的引入,使得特徵在前向傳播過程中可以通過恆等分支直接傳遞,不再隨着網絡深度的增加而被層層變換所削弱。
同時,將直接學習目標映射轉化為學習殘差映射,也為反向傳播提供了更加順暢的梯度通道,從而在一定程度上緩解了深層網絡中常見的梯度消失、優化困難等問題。
瞭解了基礎知識後,我們下面就來看看 ResNet 是如何應用殘差思想的。
3. ResNet 的網絡結構
在前面對殘差塊的討論中,你可能已經注意到一個關鍵前提:在殘差塊中,參與融合(相加)的兩條分支,其輸出張量的維度必須一致,否則殘差相加無法進行。
在 ResNet 的實現中,這一條件可以通過多種方式滿足。 例如 same padding 或 \(1\times1\) 卷積。
正是由於殘差結構在設計上顯式地處理了這些維度匹配問題,深層網絡在結構上變得更加可控和穩定,從而為構建更深的網絡提供了基礎條件。
我們接下來來看 ResNet 在論文中給出的整體網絡結構。需要注意的是,ResNet 並不是某一個具體模型,而是一系列採用殘差塊作為基本單元的網絡架構的統稱,包括 ResNet-18、ResNet-34、ResNet-50 等不同深度的版本。

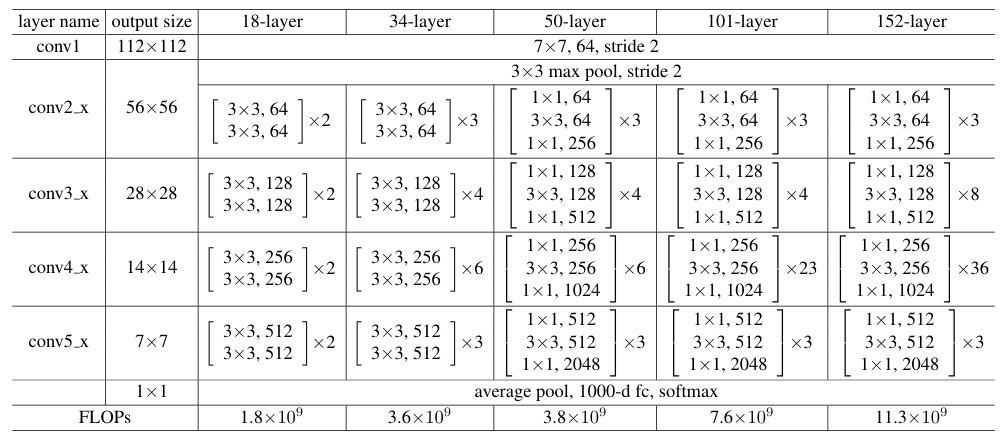
這些都是原論文中的內容,如果拋開殘差思想,你會發現,這就是我們在經典卷積網絡部分中LeNet-5 驗證的“範式”,即通過卷積和池化層層提取和組合特徵,最後輸入全連接層進行決策。
可偏偏正是這一看似簡單的結構改動——將前層的輸入通過旁路連接直接引入後層,與主分支的輸出進行融合——顯著改善了深層網絡的可訓練性,使得網絡深度得以大幅提升,也推動了 CV 模型性能又一次發展。
其實 ResNet 的論文原文中對於模型的構建還有很多這裏沒有展開的細節,但是涉及到一些還沒介紹的技術,我們之後再慢慢展開。
在之前的遷移學習部分,我們已經演示過預訓練過的 ResNet-18 的效果,而在本週的實踐部分,我會再次演示單純使用 ResNet-18 本身所實現的效果。
4. 總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 殘差網絡(ResNet) | 通過引入殘差學習框架,將深層網絡的直接映射學習問題,轉化為對輸入恆等映射的修正問題,從而緩解深層網絡的優化困難 | 不要求你“從零做出結果”,而是在已有基礎上“微調改進” |
| 殘差(Residual) | 目標映射 \(H(x)\) 相對於恆等映射 \(x\) 的偏差,形式為 \(F(x)=H(x)-x\),由網絡隱式學習 | 在原有結果上補差,而不是重新做一遍 |
| 恆等映射 | 輸入 \(x\) 原樣傳遞到後續層,不引入任何變換 | 什麼都不做,直接照搬 |
| 非殘差網絡的映射 | 每一層直接學習完整映射 \(y=F(x)\),深層時優化困難 | 每一關都要求你“從頭交付成品” |
| 退化問題(Degradation Problem) | 隨網絡深度增加,訓練誤差反而上升的問題,源於優化難度而非模型表達能力不足 | 路越修越寬,但車反而跑不動 |
| 旁路連接(Shortcut Connection) | 通過恆等(或線性)分支將輸入直接傳遞到後層,與主分支結果融合,為信息與梯度提供直達路徑 | 給網絡開一條不堵車的“快速通道” |
| 主分支 | 由卷積、線性變換和非線性激活構成,用於學習殘差函數 \(F(x)\) | 真正“幹活”的加工流程 |
| 殘差塊(Residual Block) | 由若干主分支層與一條旁路連接共同組成的結構單元,實現 \(a^{[l+k]}=a^{[l]}+F(a^{[l]})\) | 一整套“加工 + 校正”的工作單元 |
| 特徵融合(相加) | 要求兩條分支輸出維度一致,通過逐元素相加完成信息整合 | 兩條尺寸相同的軌道合併 |
| ResNet 網絡結構 | 通過堆疊大量殘差塊構建深層網絡,而非單純增加普通層數 | 用穩定模塊搭高樓,而不是硬堆磚 |