

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第四課的第三週內容,3.9到3.10的內容,同時也是本週理論部分的最後一篇。
本週為第四課的第三週內容,這一課所有內容的中心只有一個:計算機視覺。應用在深度學習裏,就是專門用來進行圖學習的模型和技術,是在之前全連接基礎上的“特化”,也是相關專業裏的一個重要研究大類。
這一整節課都存在大量需要反覆理解的內容和機器學習、數學基礎。 因此我會盡可能的補足基礎,用比喻和實例來演示每個部分,從而幫助理解。
第三週的內容將從圖像分類進一步拓展到目標檢測(Object Detection) 這一更具挑戰性的計算機視覺任務。
與分類任務只需回答“圖中有什麼”不同,目標檢測需要同時解決“ 有什麼”以及“在什麼位置”兩個問題,因此在模型結構設計、訓練方式和評價標準上都更為複雜。
本篇的內容關於YOLO 傳播,是在瞭解完之前的基礎後的完整演示和一些簡單拓展。
1. YOLO 傳播過程
在上一篇中,我們瞭解了交併比、非極大值抑制和錨框這些目標檢測算法的組件,這裏就應用這些內容,來看看課程裏演示的 YOLO 算法的完整傳播過程。
1.1 數據設置
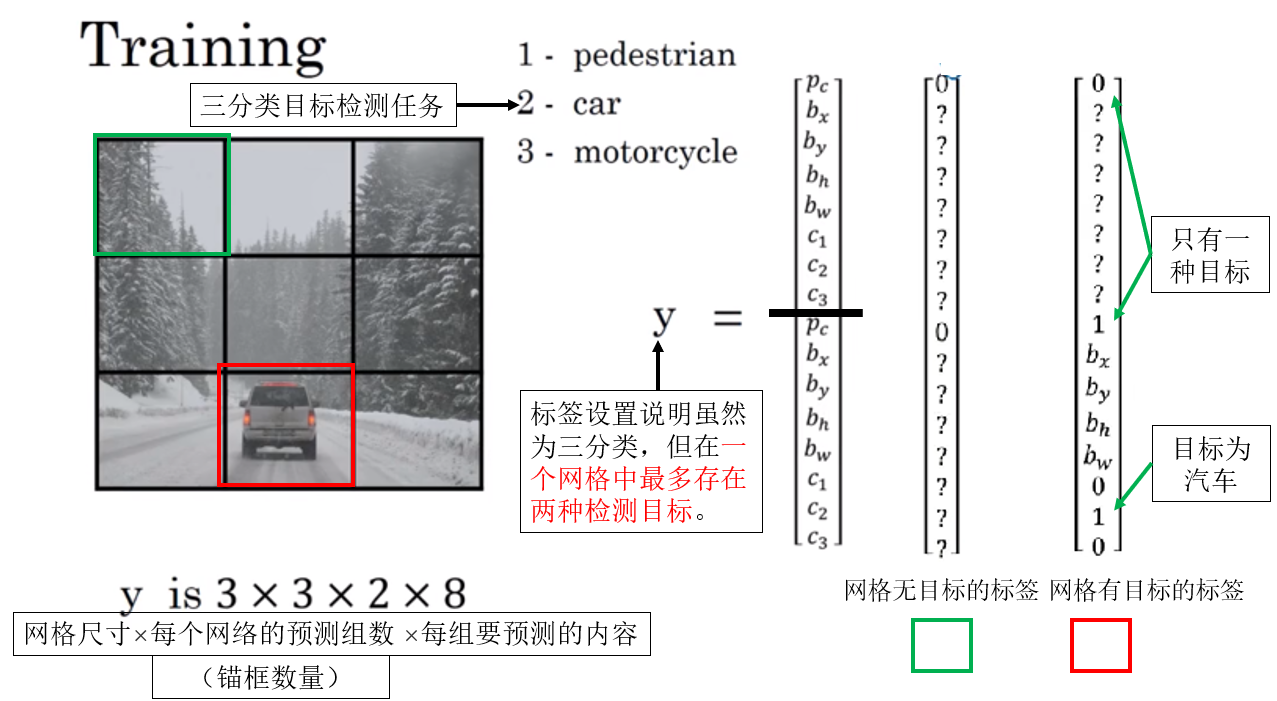
1.2 正向傳播
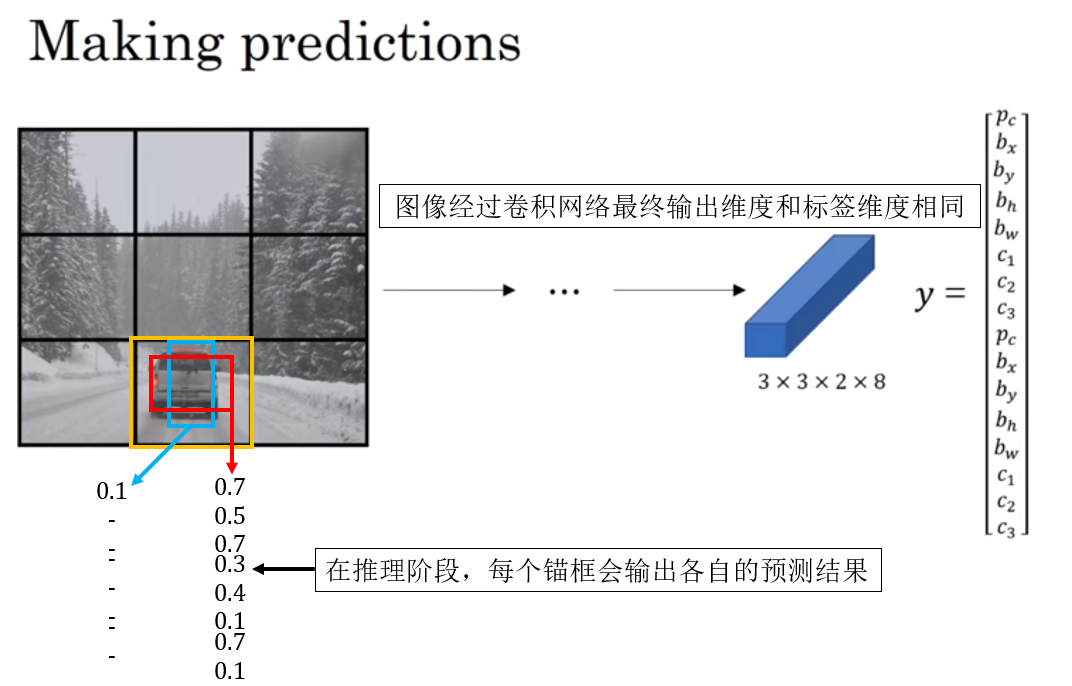
1.3 正向傳播輸出的後處理
這是一個新出現的概念,我們來展開一下這部分。
其實這部分內容在上一篇中已經有所提及,就是我們説的:“兩次篩選”。
為什麼説是正向傳播的後處理,是因為嚴格來説:當網絡輸出結果時,正向傳播部分就結束了。
因此,不同於我們之前用作示例的“精準預測”,實際上,網絡輸出的結果是這樣的:
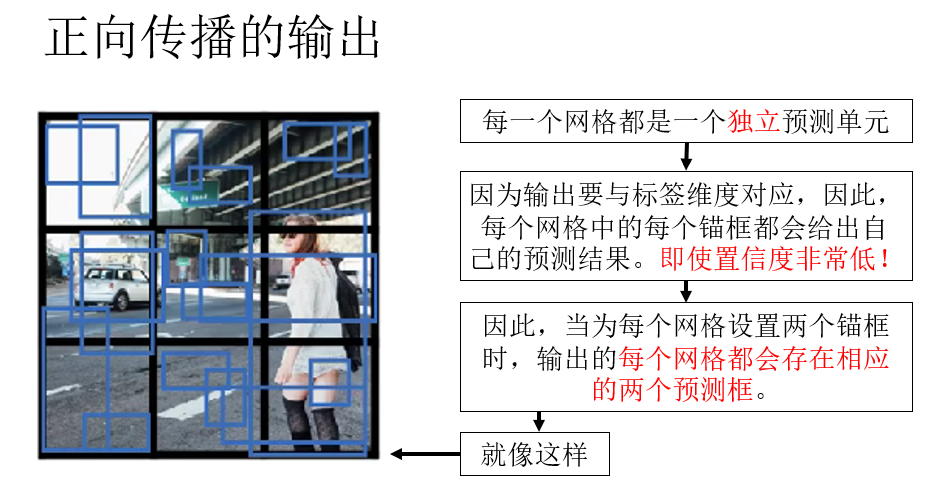
你會發現,即使在最邊角的背景部分,該網格同樣輸出了兩個預測框。
同時,因為背景部分沒有目標的特徵,因此,這兩個預測框的置信度,也就是 \(p_c\) 一定是極低的。
所以,我們便由此進行了第一次篩選:
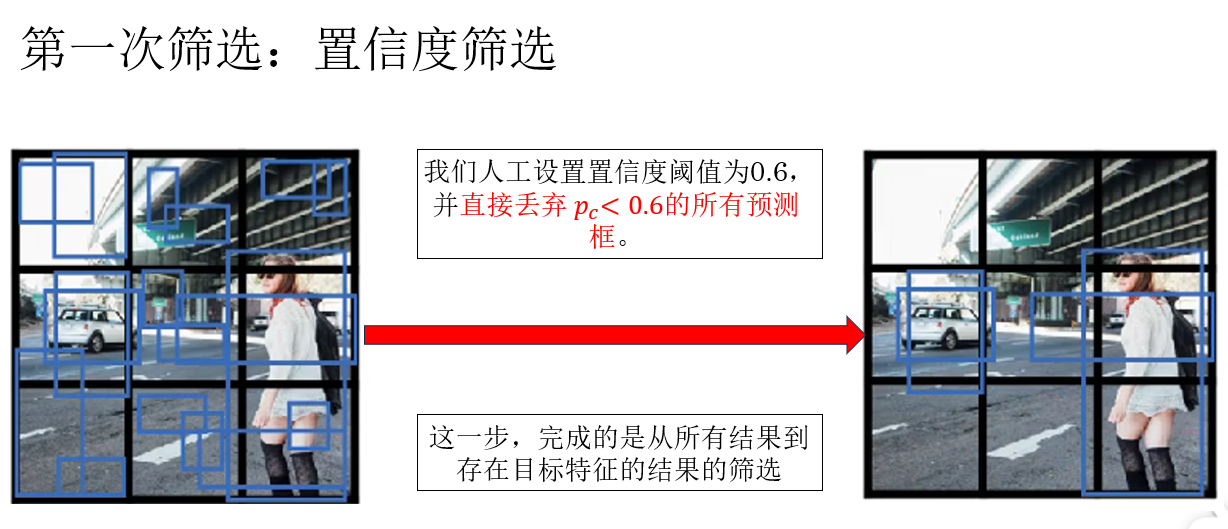
經過這一步後,我們才回到了之前提到過的多個預測框重疊導致的把一個目標的各個部分預測為多個目標的問題。
因此下一步就是非極大值抑制:
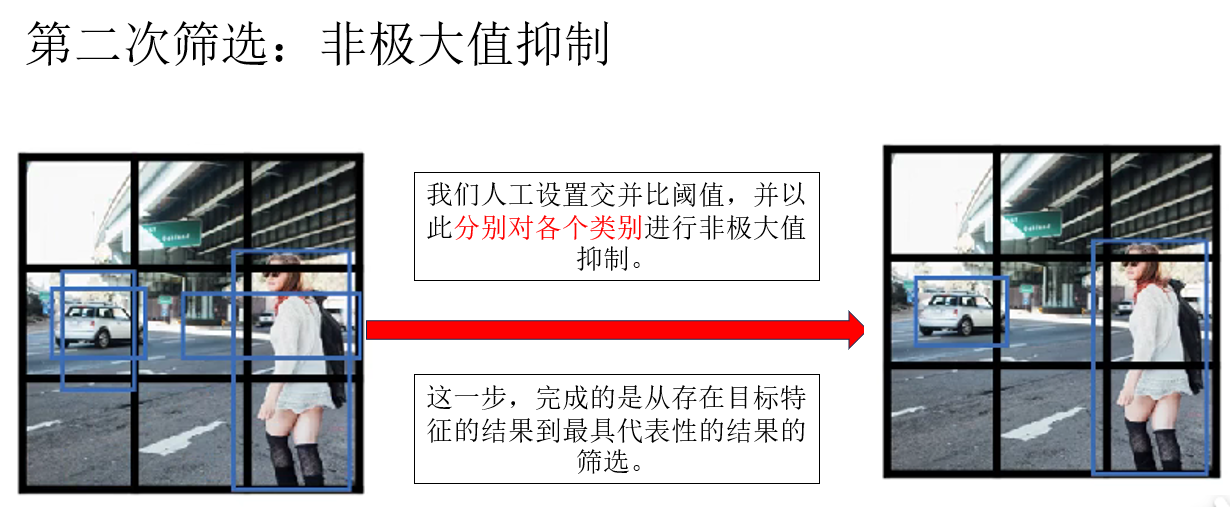
注意!你會發現,在這個例子中,重疊現象並不明顯,這是因為我們為了演示把網格尺寸設置的很大以至於目標特徵集中在某些網格中,在置信度篩選中就丟棄了大部分預測框,在這種情況下,就要調低交併比閾值來實現更好的篩選,因為重疊部分本就不大。
因為置信度篩選和非極大值抑制並不在網絡中進行,而是對網絡的輸出進行處理,因此,我們稱之為正向傳播輸出的後處理內容。
1.4 反向傳播
(1)正向傳播、反向傳播和後處理的關係
首先,先糾正一個可能出現的誤解,那就是對輸出的後處理並不是在正向傳播和反向傳播之間的一個流程,它只是對輸出結果的整理。
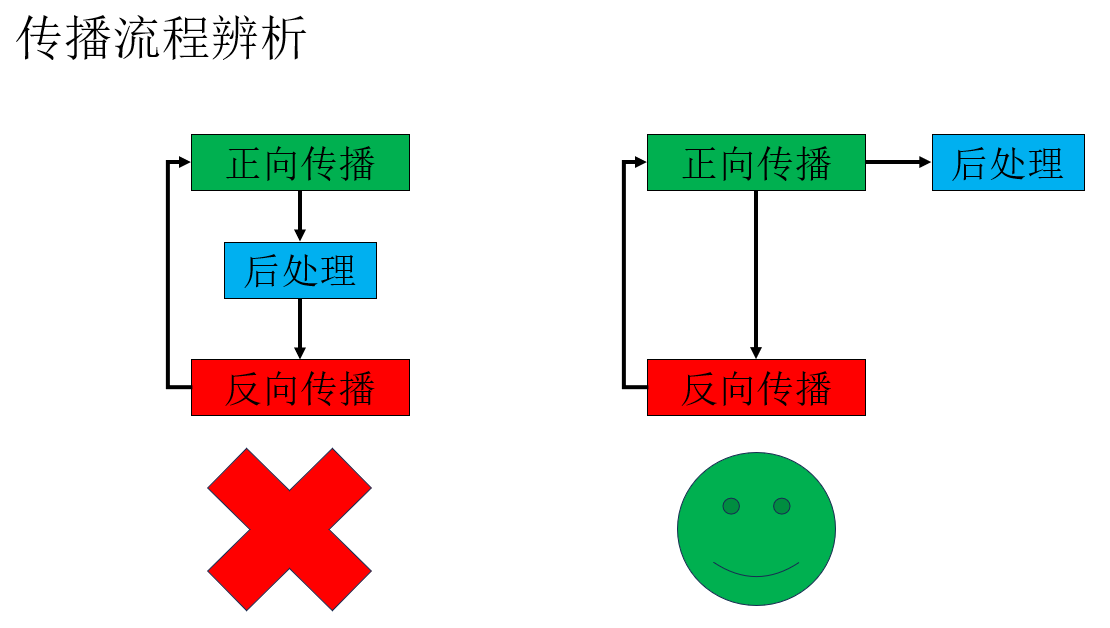
我們再詳細展開一下:
既然置信度篩選和非極大值抑制並不在網絡中進行,那它們會不會影響反向傳播?
那些被篩掉的預測框,訓練時是不是就“不算數”了?
答案是不會。
我們需要先明確一個邊界:反向傳播只依賴於網絡的原始輸出與真實標籤計算得到的損失函數。
也就是説,當網絡輸出了每個網格、每個錨框對應的:
- 位置預測
- 置信度 \(p_c\)
- 類別概率
這時,正向傳播已經結束,損失函數開始計算,反向傳播隨即發生。
而置信度閾值篩選與非極大值抑制:
- 不參與損失計算
- 不參與梯度傳播
- 僅用於對“最終預測結果”的整理,用於下一步使用。
打個比方:網絡是”你把這道題所有想到的答案寫出來”,而後處理是“老師幫你去掉明顯不對的答案”。
但當你學習分析這道題時,看的依然是原始答卷,而不是你後來用紅筆劃掉的部分,只有這樣才能學習錯誤並改正。
這就是正向傳播、反向傳播和後處理間的關係。
要強調的是,後處理的結果是給我們查看並進行下一步應用的,網絡不會因為輸出看起來“亂”而學不到東西,反而,它正是在這種一一對應的信息反饋下才能不斷學習。
(2)檢測任務的反向傳播邏輯
在監督學習中,不同任務雖然形式各異,但其反向傳播的基本邏輯是共通的:模型輸出與標註標籤通過損失函數進行對比,得到可微的誤差信號,並利用梯度下降與鏈式法則更新參數,使模型輸出逐步符合任務目標。
接下來,我們從訓練視角來看,再簡述一下目標檢測任務的反向傳播流程:
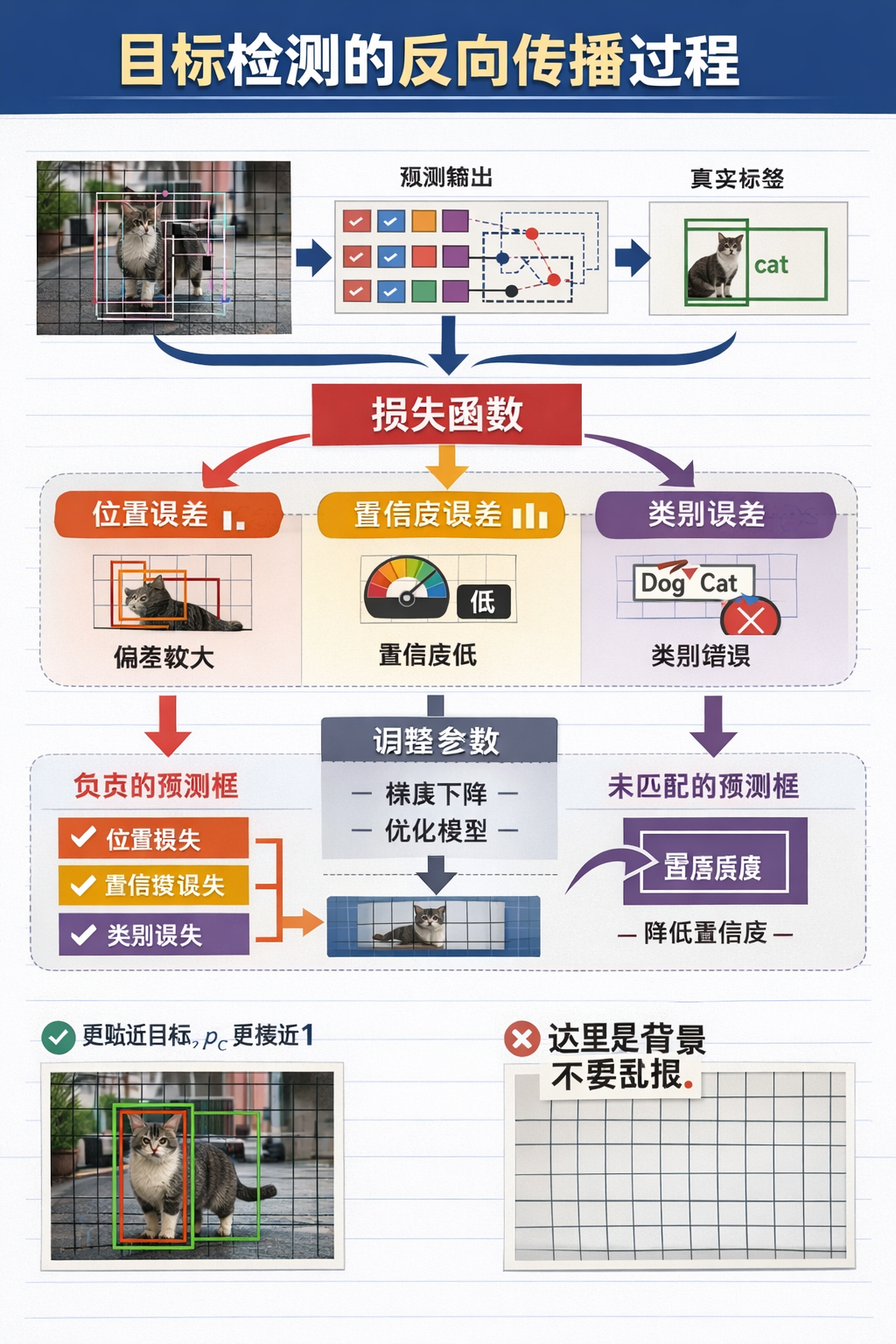
當網絡完成正向傳播後,它會為每一個網格、每一個錨框都給出一組預測結果,這些預測結果並不會先經過篩選,而是整體送入損失函數中,與真實標籤進行逐一對比。
在 YOLO 中,我們可以把損失函數拆分為三類誤差來源:
- 位置誤差:預測框的位置與真實目標框之間的偏差。
- 置信度誤差:該預測框是否“應該負責一個目標”。
- 類別誤差:在負責目標的前提下,類別預測是否正確。
而對於那些被分配去負責某個真實目標的預測框來説:
- 如果預測框位置不準,就會產生位置損失。
- 如果置信度不夠高,就會產生置信度損失。
- 如果類別預測錯誤,就會產生類別損失。
這些損失會共同作用,通過梯度下降推動網絡在反向傳播中調整參數,使得下一次的輸出框更貼近目標、\(p_c\) 更接近 1、類別分佈更集中在正確類別上。
而對於那些不對應任何真實目標的預測框,它們的學習目標是:置信度應該儘可能低,即不應該“誤以為自己發現了目標”。
因此,即使在後處理階段我們會直接把它們篩掉,在訓練階段,它們依然會通過置信度損失向網絡傳遞一個非常明確的信號: “這裏是背景,不要亂報目標。”
正是這些大量、持續的背景約束,才讓網絡逐漸學會在複雜場景中抑制無意義的預測。
關於 YOLO 的內容就暫時介紹到這裏,在下一篇中,我們就來實踐一下它的效果。
吳恩達老師最後補充了一節關於候選區域的內容,簡單來講,候選區域的應用仍是基於滑動窗口的目標檢測算法,它的思想是通過圖像分割等算法提前找到更可能存在目標的區域作為候選區域,並只輸入候選區域進入網絡來減少計算量。
但是説實話,這種技術目前更適合於學術研究中,它的運行時間較長,實際部署價值不如 YOLO ,因此在實際應用中十分少見,就不再展開了。
2.總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 正向傳播(Forward Pass) | 網絡接收圖像輸入,通過卷積、池化等運算生成每個網格、每個錨框的預測輸出(位置、置信度、類別概率)。 | 網絡“寫下所有可能的答案”。 |
| 正向傳播輸出的後處理(Post-processing) | 包括置信度篩選和非極大值抑制(NMS),對網絡輸出進行整理,去掉低置信度和重疊多餘的預測框。 | 老師“幫你劃掉明顯不對的答案”。 |
| 置信度篩選 | 根據預測框的置信度 \(p_c\) 判斷是否保留。背景區域輸出的框通常置信度低,會被篩掉。 | 去掉“明顯錯誤的答案”。 |
| 非極大值抑制(NMS) | 對重疊的預測框進行篩選,只保留置信度最高的框,避免同一目標被重複檢測。 | 老師只留下“最靠譜的答案”。 |
| 反向傳播(Backward Pass) | 網絡輸出與真實標籤計算損失,梯度通過鏈式法則回傳,更新網絡參數。所有預測框(目標和背景)都參與損失計算。 | 網絡“看到原始答卷,知道哪裏做錯了並改正”。 |
| 候選區域(Region Proposal) | 基於滑動窗口或圖像分割的方法,提前選出可能有目標的區域輸入網絡以減少計算量。 | 先挑出可能有答案的題目再做作業,但效率低於直接整張圖像端到端檢測(YOLO)。 |