

我們已經知道:高光譜圖像的每一個像素,本質上是一個高維光譜向量,其波段數量可能達到上百維。
這固然提供了更多的信息,但於此同時也極大增加了計算量。
並且,結合實際生活,你會發現一個新的問題:
大量特徵間的重要性並不等價。
舉個例子:假設我們要區分三種動物:貓、狗和老虎。
現在我們為每隻動物記錄一系列特徵,如體重、體長、毛髮顏色、是否有鬍鬚、是否會游泳、心跳頻率、是否有條紋、爪子長度、是否食肉等等。
仔細想想就會發現,這些特徵在這個分類任務中並非同等重要,而高光譜圖像也是如此,舉例如下:
| 動物分類 | 高光譜圖像 |
|---|---|
| “是否有條紋”對區分貓和老虎非常關鍵 | 某些波段區分度高,信息量豐富 |
| “是否食肉”對三者幾乎沒有區分度 | 某些波段對分類貢獻有限 |
| “是否會游泳”可能完全無關 | 某些波段可能屬於無關信息 |
| “體重”和“體長”高度相關,信息重複 | 部分波段之間高度相關,存在冗餘 |
| 個別測量誤差可能影響判斷 | 部分波段可能包含噪聲 |
也就是説,雖然我們通過採集高光譜圖像獲得了每個像素的更多特徵,但是同時也會發現這種情況:
光譜向量中有的特徵信息量大,有的特徵幾乎是噪聲,還有的特徵彼此冗餘。
如果我們把這些特徵全部平等對待,不僅計算複雜,而且可能讓真正重要的差異被淹沒。
那麼,一個自然的問題便出現了,那就是能不能自動找出“最重要”的那些方向?
這其實本質上是計算機領域的經典的優化問題:
如何在儘可能保留信息的前提下,降低維度來減少計算成本?
於是便有了非常經典的方法: 主成分分析(Principal Component Analysis,PCA)。
主成分分析是一種非常通用的線性降維方法,它廣泛應用於幾乎所有涉及“高維數據”的領域。高光譜成像只是其中一個典型應用場景。
1. 什麼是 PCA ?
PCA 的起源極早,在1901 年,論文 On Lines and Planes of Closest Fit to Systems of Points in Space 就提出了一種用於尋找多維數據的最優擬合方向的數學方法,這就是 PCA 的幾何雛形。
而後,1933 年的論文 Analysis of a Complex of Statistical Variables into Principal Components (鏈接僅為 part1 )對 PCA 進行了系統推廣,延續至今,PCA 仍是現代統計學與機器學習中的經典降維方法。
在開始闡述前,我們要強調的是:PCA 的降維邏輯不是在原數據中找到最有區分度的幾個特徵後刪去其他特徵,而是用所有原始特徵線性組合生成區別度高的新特徵。
而把高維空間的信息壓縮到低維空間,“投影”是最自然的壓縮方式。
現在,我們舉一個最簡單的例子:把二維信息降維到一維,來説明 PCA 的核心思想,來看:
如果不計代價,我們很容易就能做到,就像這樣:
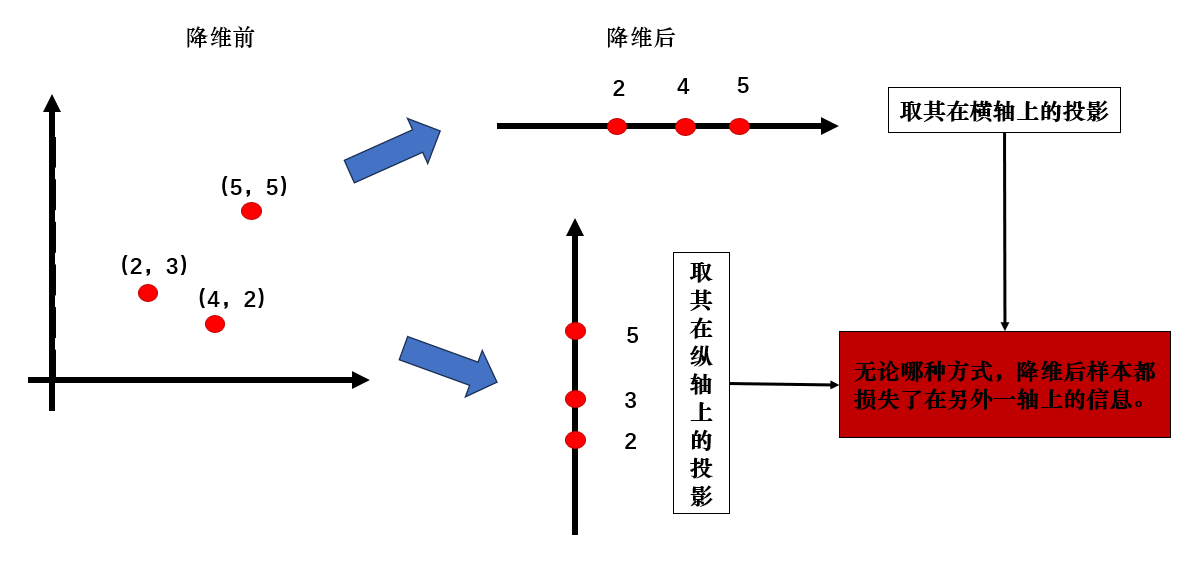
我們以一種十分簡單的方式完成了降維,但就像圖中所示,如果我們只取樣本在原座標軸上的投影,因為座標軸間的正交關係,就會完全損失樣本在其他維度上的信息。
因此,如果想在降維的同時保留更多信息,我們就要跳出原本的座標軸,或者説變換座標軸,讓二維信息綜合在新的一維座標軸上。 就像這樣:
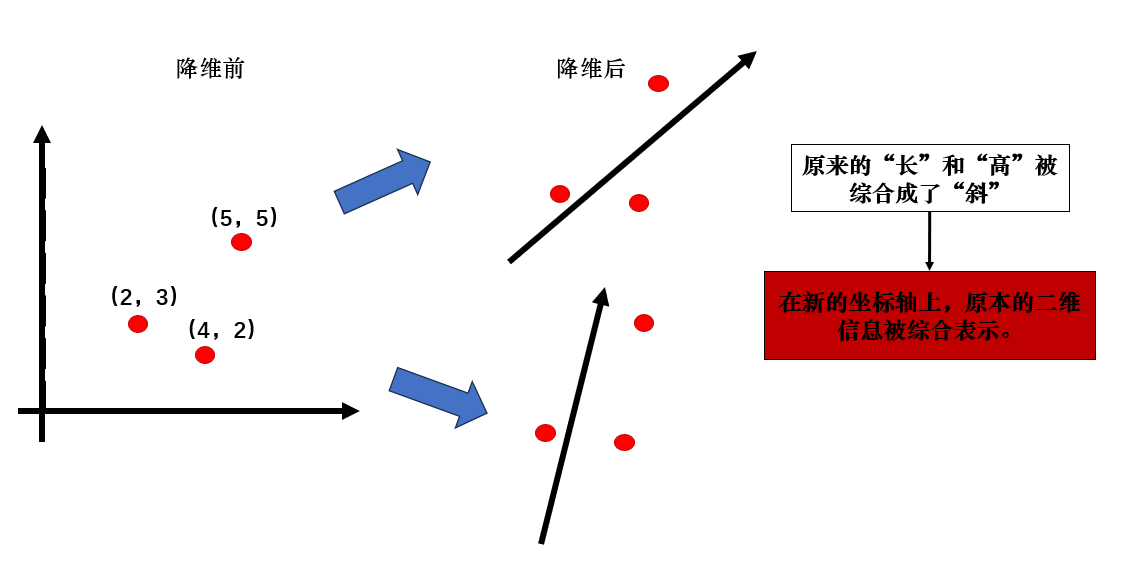
這樣,我們就實現了在降維數據來減少計算量的同時,在一定程度上保留了信息。
但新的問題馬上就來了:
什麼方向上的座標軸,可以讓信息得到最大程度的保留呢?
顯然,不同方向的座標軸,其保留信息的能力是不同的,我們繼續剛剛的例子:
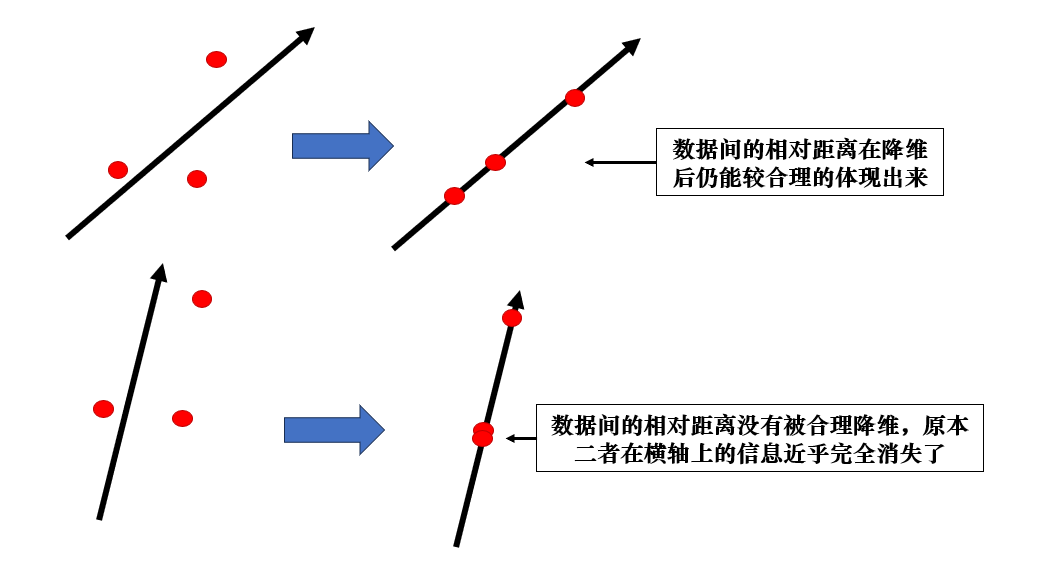
由此,我們可以總結出一個關鍵點:合理的降維方法應該在降維後仍能體現出原數據在向量空間裏的相對距離關係。
那麼,我們要如何量化這個“合理”的程度呢?PCA 給出的答案是:信息主要存在於數據變化最大的方向上。 來看看為什麼:
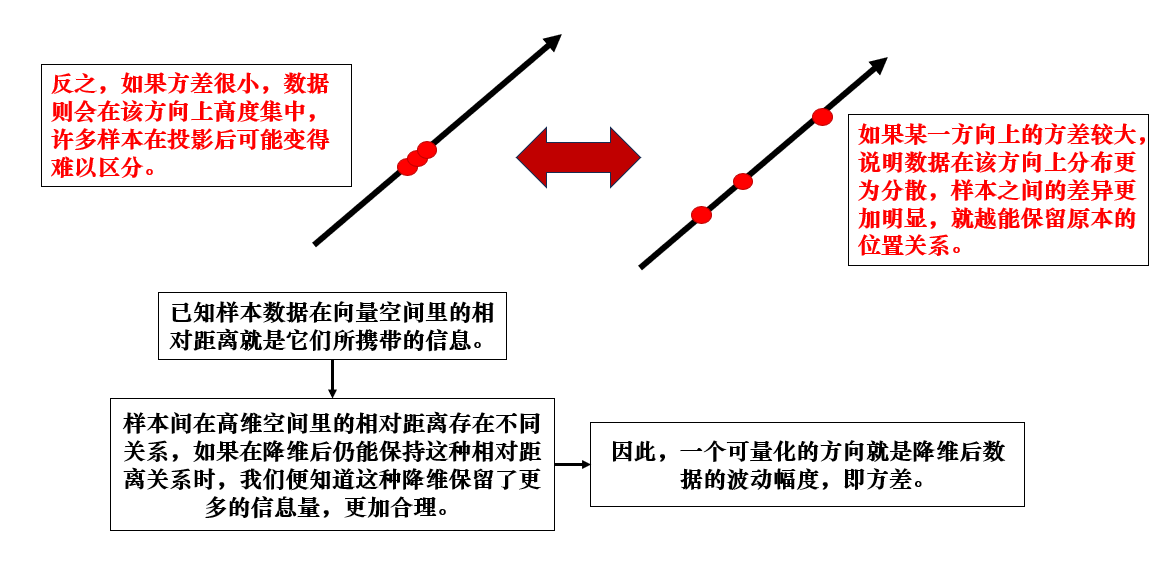
由此,我們的目標就確定了:找到那些能夠保留最大方差的方向。這些方向能夠最大程度地保持數據的變化結構,從而儘可能保留原始數據中的信息。
這就是 PCA 的核心思想,下面就來分步闡述其具體過程:
2. PCA 的過程
我們仍以高光譜圖像來演示這個過程,假定採集 \(n\) 個波段,那麼一個像素就可以表示為:
再推廣到整幅圖像,如果有 \(m\) 個像素,則形成數據矩陣:
其中,每行代表一個像素,每列代表一個波段。
因此,數據矩陣的每一行就是一個樣本,每一列就是一個特徵。
2.1 數據中心化
對數據矩陣的第一步處理並不複雜,一句話概括:對每個特徵(列)進行零均值處理,在數學和機器學習裏,這個操作通常叫做中心化(mean centering)。
用三個像素點來進行進行簡單舉例演示,每個像素包含 100 個波段:
| 像素編號 | 波段1 | 波段2 | … | 波段100 |
|---|---|---|---|---|
| Pixel 1 | 0.12 | 0.35 | … | 0.48 |
| Pixel 2 | 0.10 | 0.37 | … | 0.50 |
| Pixel 3 | 0.11 | 0.36 | … | 0.47 |
對每一列數據進行零均值處理,即:
其中,\(\mu_j\) 為該列的均值,\(\tilde{I}_{ij}\) 即為該位置中心化後的數據。
已知第 1 波段三個像素的反射率為 0.12、0.10、0.11,那麼:$$\mu_1 = (0.12+0.10+0.11)/3 = 0.11$$當列數據與該均值分別做差,即可得到中心化後的數據,表格如下:
| 像素編號 | 波段1 | 波段2 | 波段3 | … | 波段100 |
|---|---|---|---|---|---|
| Pixel 1 | 0.01 | -0.01 | … | … | -0.003 |
| Pixel 2 | -0.01 | 0.01 | … | … | 0.017 |
| Pixel 3 | 0.00 | 0.00 | … | … | -0.013 |
中心化消除了波段間的均值差異,讓每個波段的數據均值為 0。
這樣做減去了數據的偏移,在更準確地反映數據變化方向的同時,也方便了下一步協方差矩陣計算。
2.2 計算協方差矩陣
計算協方差矩陣之前,先簡單擺一下協方差的定義,對於兩個隨機變量 \(X\) 和 \(Y\),協方差定義為:
其中:
- \(X_i, Y_i\) 是第 \(i\) 個樣本的值。
- \(\bar{X}, \bar{Y}\) 是樣本均值。
- \(m\) 是樣本數。
説人話,就是兩個變量中心化後對應樣本的乘積平均值。
現在,再來看協方差矩陣,我們已經有了中心化後的數據矩陣:
那麼協方差矩陣公式就是:
顯然,得到的協方差矩陣 \(C\) 是 \(n \times n\) 的矩陣,其中的元素 \(C_{ij}\) 就是波段 \(i\) 與波段 \(j\) 的協方差。
還沒完,我們再來專門看看協方差矩陣的對角線元素 \(C_{ii}\),將其代入公式後,協方差公式就變成了:
顯然,這就是方差公式,也就是説:協方差矩陣的對角線元素是每個特徵自身的方差。而非對角的元素就可以看作”兩個特徵聯合的波動程度“,也就是協方差。
到這裏,我們就完成了 PCA 降維思想中,對方差的準備部分。
2.3 特徵值分解(Eigenvalue Decomposition,EVD)
在得到協方差矩陣 \(C\) 後,下一步就是對其進行特徵值分解,以提取數據中的主成分方向,這是 PCA 的最核心步驟。
首先,在多維向量空間中,我們會定義單位向量 \(\mathbf{w}\),其長度固定為 1,目的是保證我們只選擇方向,而不會因為向量長度不同而改變投影尺度。
現在,先不提上一步的協方差矩陣,現在假定我們只有一個樣本 \(\mathbf{x}\) ,現在,我們要計算 \(\mathbf{x}\)
在某個方向上的投影,其公式就是:
得到的 \(z\) 即為 \(\mathbf{x}\) 在該方向上的投影數值,是一個標量。
但我們要計算的是 投影后的方差,一個數怎麼計算方差呢?這便涉及到線代裏的結論:
其中,\(C\) 就是我們上一步得到的協方差矩陣。
繼續下一步就是我們的目標:找到投影后最大的方差 即:
現在,問題就轉變成了一個求最值,也就是優化問題,在數學上,其解決方法是用拉格朗日法構造函數:
然後對 \(w\) 求導並讓其為 0 得到:
這個式子就是特徵值方程,簡單補充一下:
給定一個方陣 A(行列數相等的矩陣),假設我們有一個非零的向量 \(\mathbf{v}\),如果這個向量通過矩陣變換後只是按比例放大或縮小,即:
- \(\mathbf{v}\) 就是矩陣的特徵向量。
- \(\lambda\) 就是對應的特徵值。
需要強調的是,這裏雖然使用特徵值方程,但特徵值方程本身並沒有“最大方差方向”的語義,只是我們的數學推導恰好得到了這個形式。
繼續,把特徵值方程代回方差公式,就得到了:
現在,我們就得出了最終結論:特徵值 = 這個方向上的方差,而與特徵值對應的特徵向量的方向,就是我們要找的方差最大的方向。
自此,我們就完成了 PCA 最核心的內容,要説明的是,PCA 的理論基礎是協方差矩陣的特徵值分解,但現代機器學習庫通常使用另一種叫奇異值分解來完成計算,因為其省略了顯式計算協方差矩陣的過程,但二者的結果是相同的。
2.4 選擇主成分
根據線代的基本知識,我們知道一個 \(n \times n\) 的方陣,其特徵值方程最多有 \(n\) 個解。
而協方差矩陣是對稱矩陣的同時也是半正定矩陣,因此其特徵值方程一定有 \(n\) 個正交的解。
也就是説,在上一步,我們最終可以得到 \(n\) 組特徵值和對應的特徵向量。
到這裏,我們就稱這些特徵向量所代表的方向為“成分”。
特徵值 的大小決定每個主成分的重要性。特徵值越大,意味着該主成分方向承載的數據方差越多,信息量也越大。
最大特徵值對應的特徵向量,就是第一主成分方向,第二大的特徵值對應第二主成分方向,以此類推。
而我們在這一步的工作如下:
- 計算所有特徵值之和 = 數據的總方差
- 計算每個主成分的方差佔比並排序
- 一般挑選滿足方差佔比之和大於 95% 的前 \(k\) 個主成分,最終降維到 \(k\) 維。
來看一個簡單的例子,假設我們對數據做完特徵值分解後,得到如下結果:
| 排名 | 特徵值 \(\lambda\) | 解釋的方差比例 |
|---|---|---|
| 1 | 5.0 | 5.0 / (5.0+0.8+0.2)=83.3% |
| 2 | 0.8 | 0.8 / (5.0+0.8+0.2)=13.3% |
| 3 | 0.2 | 0.2 / (5.0+0.8+0.2)=3.3% |
你會發現:前兩個主成分已經解釋了約 96% 的信息
這時我們就可以説:數據的主要結構,幾乎都集中在前兩個方向上。
因此:如果我們把數據從 3 維降到 2 維,仍然可以保留 96% 的信息,丟失的信息只有 4%,這就是 PCA 降維的核心思想。
到此,我們就只剩下最後一步了。
2.5 構建降維後的數據
在得到重要的主成分方向後,最後就是將原始數據投影到這些主成分方向上,得到降維後的數據了。這個過程就是將原始數據映射到新的低維空間中。
投影公式為:
其中:
- \(Y\) 是降維後的數據矩陣,尺寸為 \(m \times k\)。
- \(\mathbf{V}_k\) 是包含前 \(k\) 個主成分的特徵向量矩陣,尺寸為 \(n \times k\)。
- \(Y\) 每行對應一個樣本,通過前 \(k\) 個主成分表示。
我們繼續上一步的例子來演示,假定主成分對應的單位特徵向量為:
然後將兩個特徵向量組合為矩陣:
現在,假設中心化後的數據為:
代入PCA 的投影公式即可得到:
計算結果為:
最終,我們就在儘可能保留信息的前提下,將數據從 3 維壓縮到 2 維。
3.PCA 的優缺
天底下沒有完美的方法,PCA 自然也有其優劣所在。
3.1 PCA 的優勢
| 優點 | 説明 |
|---|---|
| 計算效率高 | PCA 主要依賴協方差矩陣的特徵值分解,算法結構簡單、無需複雜迭代,計算穩定且易實現 |
| 能去除特徵冗餘 | 通過協方差矩陣分析特徵之間的相關性,將高度相關的特徵壓縮到少數幾個主成分中 |
| 數據壓縮能力強 | 在儘量保留主要方差信息的前提下降低數據維度,從而減少計算量和存儲需求 |
| 主成分互不相關 | PCA 得到的主成分兩兩正交,因此在統計意義上互不相關,有利於後續建模 |
3.2 PCA 的不足
| 缺點 | 説明 |
|---|---|
| 只能處理線性結構 | PCA 本質是線性投影方法,對於存在非線性流形結構的數據表達能力有限 |
| 對特徵尺度敏感 | 協方差計算會受到特徵量綱影響,因此通常需要先進行標準化處理 |
| 主成分可解釋性較弱 | 每個主成分通常是多個原始特徵的線性組合,難以直接解釋其物理或業務含義 |
| 對異常值敏感 | 方差對極端值非常敏感,少量異常樣本可能顯著改變主成分方向 |
總之,PCA 通過特徵值分解和主成分選擇,從高維數據中提取最重要的信息,極大地減少了計算複雜度。它不僅用於高光譜圖像的降維,也廣泛應用於其他數據分析和機器學習任務中。以傳統的 PCA 為基礎,後續也發展出了Kernel PCA,稀疏 PCA等改進方法。