

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第四課第二週的課後習題和代碼實踐部分。
1. 理論習題
【中英】【吳恩達課後測驗】Course 4 -卷積神經網絡 - 第二週測驗
還是先上一下鏈接,這周的理論習題涉及一些公式推導,但是在這篇博客裏已經給出了很詳細的過程。所以就不再展開這一部分了。
這周的代碼演示內容較多,我們就把精力主要放在下面的實踐內容中。
2. 代碼實踐
要提前説明的是,在吳恩達老師的課程中,本週編程作業的題目是 Keras 入門與殘差網絡的搭建。
不過需要注意:Keras 原本是一個獨立的第三方庫,但在 TensorFlow 2.x 中,它已被集成成為 TensorFlow 的高級 API。
因此,在這位博主的 Keras入門與殘差網絡的搭建 博客中,部分導入語法在新版本中可能會報錯,這只是由於版本更新導致,並不影響博客的核心內容,且殘差網絡的手工搭建部分仍然是正確且值得學習的。
我們在正文部分依舊還是用 PyTorch 來演示這周所學的內容。
因為內容較多,這裏先簡單列舉一下:
- 使用 LeNet-5 進行手寫數字圖像識別
- 使用 AlexNet 進行手寫數字圖像識別,貓狗圖像二分類
- 使用 VGG-16 進行貓狗圖像二分類
- 使用 ResNet-18 進行貓狗圖像二分類
2.1 使用 LeNet-5 進行手寫數字圖像識別
回看一下 LeNet-5 的網絡結構:
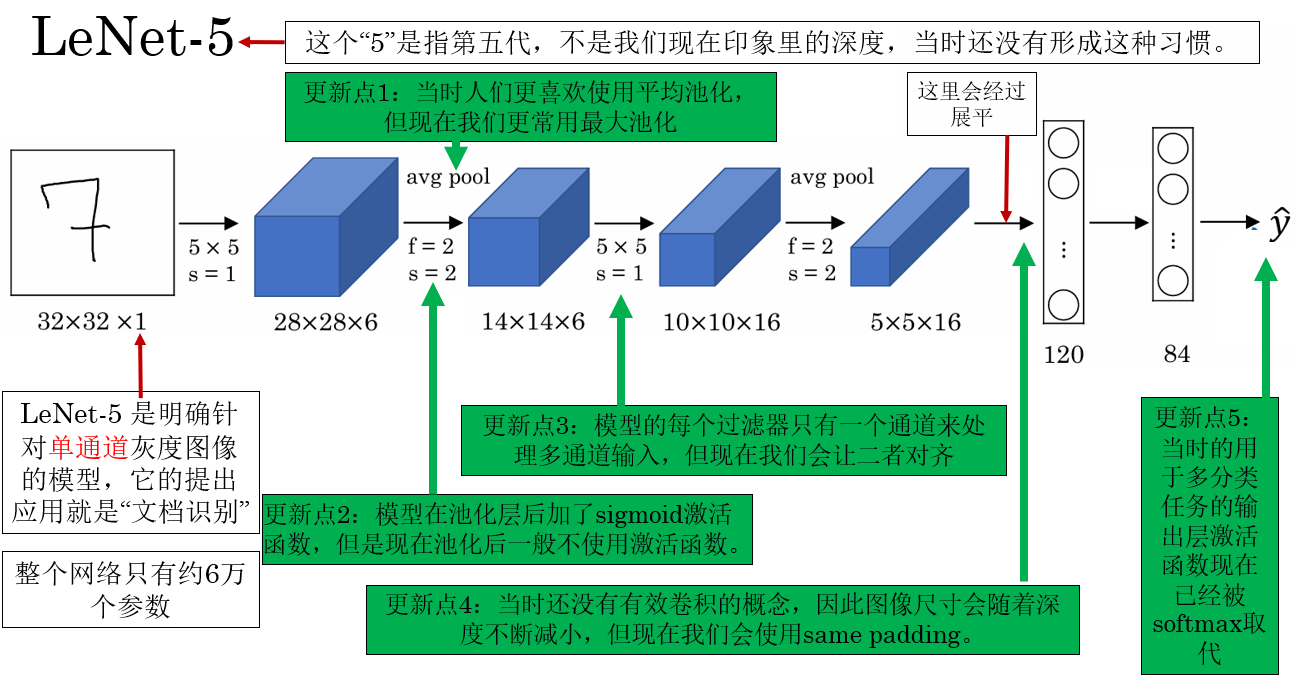
我們在介紹它的時候就提到過,LeNet-5 的提出應用就是單通道的文檔識別。
因此,我們就來看看這個二十多年前的模型在手寫數字圖像識別上的效果如何。
LeNet-5 的網絡結構並不複雜,我們用 ReLU 替換了原始的 sigmoid/tanh,用CrossEntropyLoss 替代原始平方誤差損失,這樣在 PyTorch 中更適合現代訓練。
最後代碼如下:
class LeNet5(nn.Module):
def __init__(self, num_classes=10):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5) # 輸入: 1x32x32 -> 輸出: 6x28x28
self.pool = nn.AvgPool2d(kernel_size=2, stride=2) # 6x28x28 -> 6x14x14
self.conv2 = nn.Conv2d(6, 16, kernel_size=5) # 16x10x10
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, num_classes)
def forward(self, x):
x = F.relu(self.conv1(x)) # 6x28x28
x = self.pool(x) # 6x14x14
x = F.relu(self.conv2(x)) # 16x10x10
x = self.pool(x) # 16x5x5
x = torch.flatten(x, 1) # 16*5*5=400
x = F.relu(self.fc1(x)) # 120
x = F.relu(self.fc2(x)) # 84
x = self.fc3(x) # 10
return x
# 參數設置:
criterion = nn.CrossEntropyLoss() #內置 softmax
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 10
現在,來看看 LeNet-5 在手寫數字圖像識別上的效果如何:
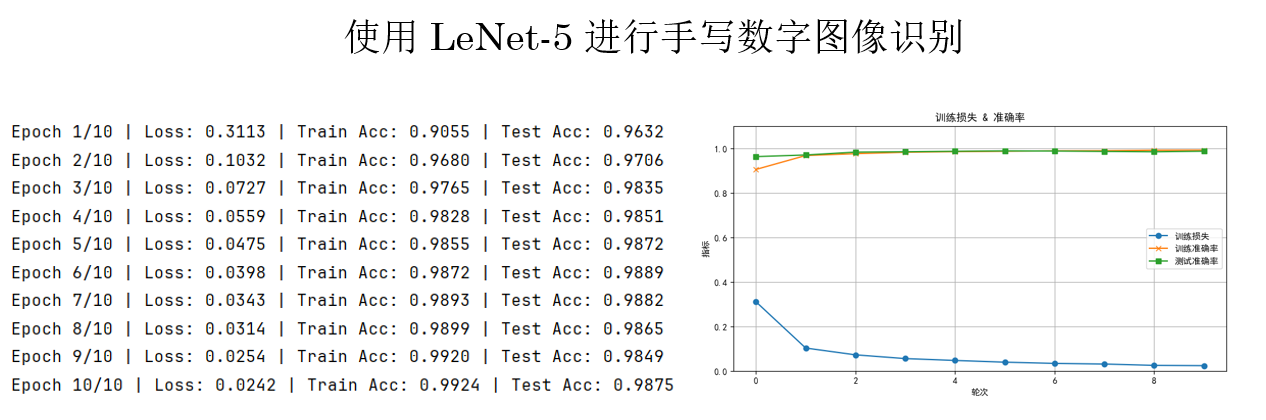
可以看到及效果極佳,僅僅 10 輪訓練,訓練準確率幾乎達到 100%,測試準確率也接近 100%,並且損失仍在平穩下降。
原因一方面,LeNet-5 的卷積-池化結構能夠有效提取手寫數字的局部到全局特徵;另一方面,MNIST 數據集相對簡單、規範,使得小型模型也能快速收斂並取得高精度。
2.2 AlexNet
還是先回顧一下網絡結構:
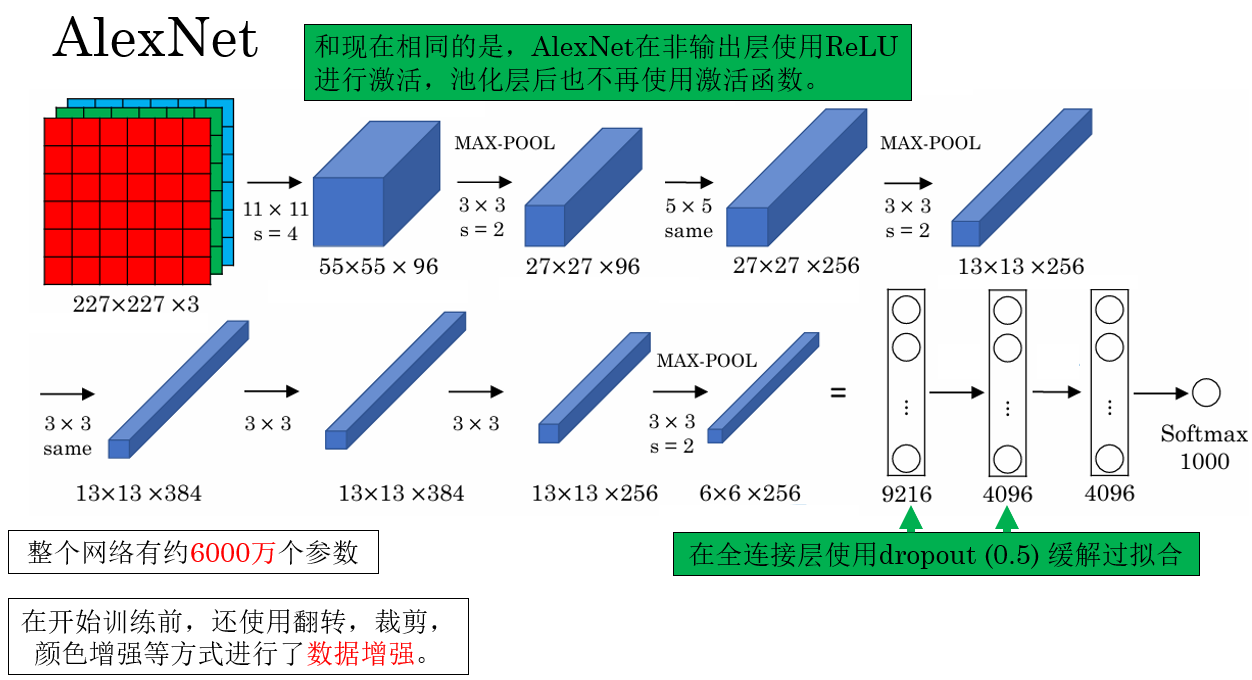
實際上,AlexNet 被已經被PyTorch內置了,我們可以比較方便的調用:
# 使用內置
AlexNetmodel = models.alexnet(pretrained=False)
現在就來看看 AlexNet 在不同任務上的效果。
(1)使用 AlexNet 進行手寫數字圖像識別
這裏先使用 AlexNet 跑 MNIST ,並不是追求更高精度,而是對比模型規模變大後,訓練效率和收斂行為的變化。
因為 AlexNet 接受的輸入為RGB圖像,因此,在開始訓練前,還需要對 MNIST 數據集進行預處理:
transform = transforms.Compose([
transforms.Resize((224, 224)), # AlexNet 需要 224x224
transforms.Grayscale(num_output_channels=3), # MNIST 是單通道,將其複製為 3 通道
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),
(0.5, 0.5, 0.5))
])
運行結果是這樣的:
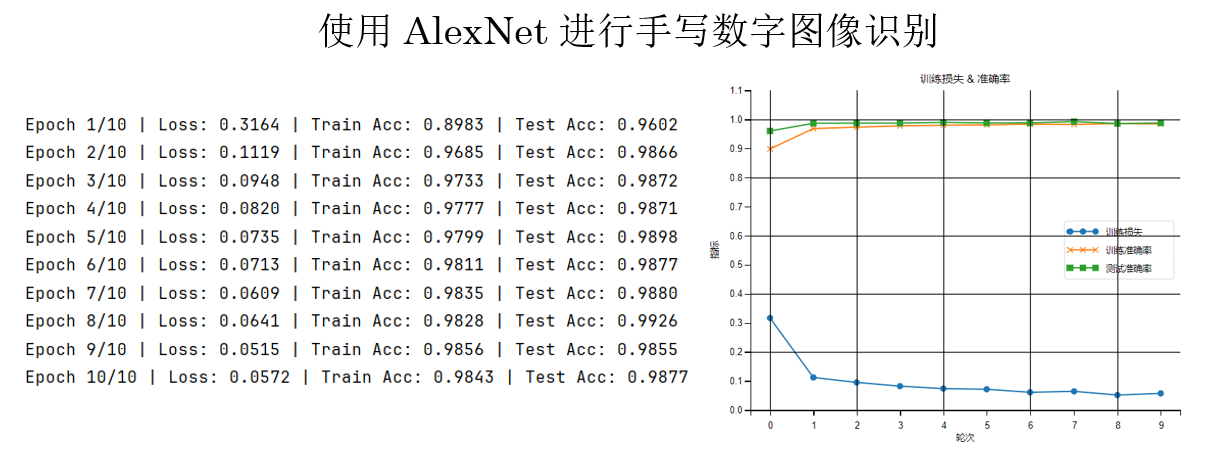
這個結果不出意料,AlexNet 在 LeNet-5 的基本邏輯上又通過網絡深度增加了非線性表達能力,但相應的,也會增加每輪的平均訓練時間。
同時你會發現,在相同訓練輪次下,AlexNet 的損失值相對 LeNet-5 略高,這並不意味着模型性能更差,而是由於其參數規模更大、優化難度更高,在有限輪次下尚未充分收斂。
從模型容量和表達能力上看,AlexNet 具備更高的性能上限,在更大數據規模或更充分訓練條件下通常能取得更優結果。
(2)使用 AlexNet 進行貓狗圖像二分類
我們先試試使用預訓練的 AlexNet 來看看模型在這個任務上的上限。
AlexNetmodel = models.alexnet(pretrained=True)
結果如下:
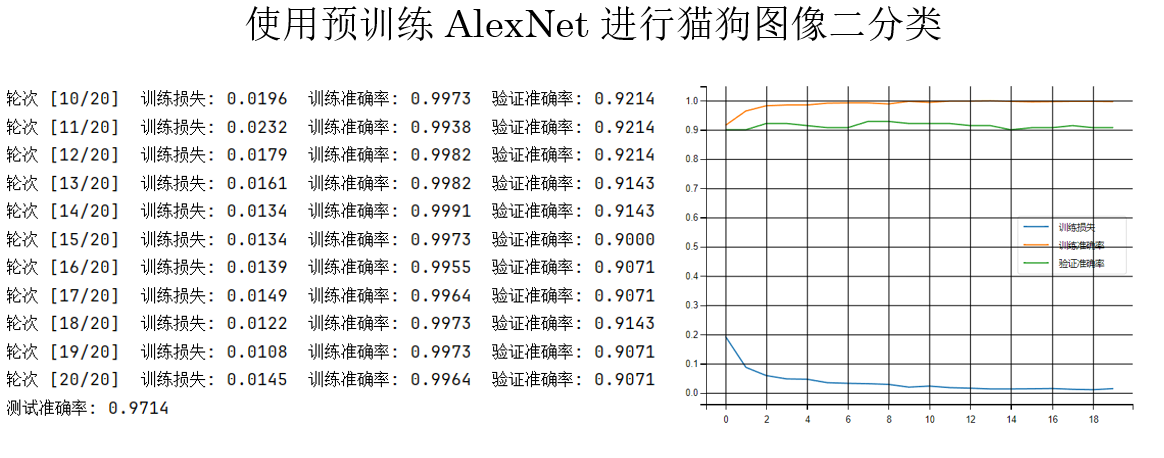
現在,我們再試試從頭開始訓練:
AlexNetmodel = models.alexnet(pretrained=False)
結果如下:
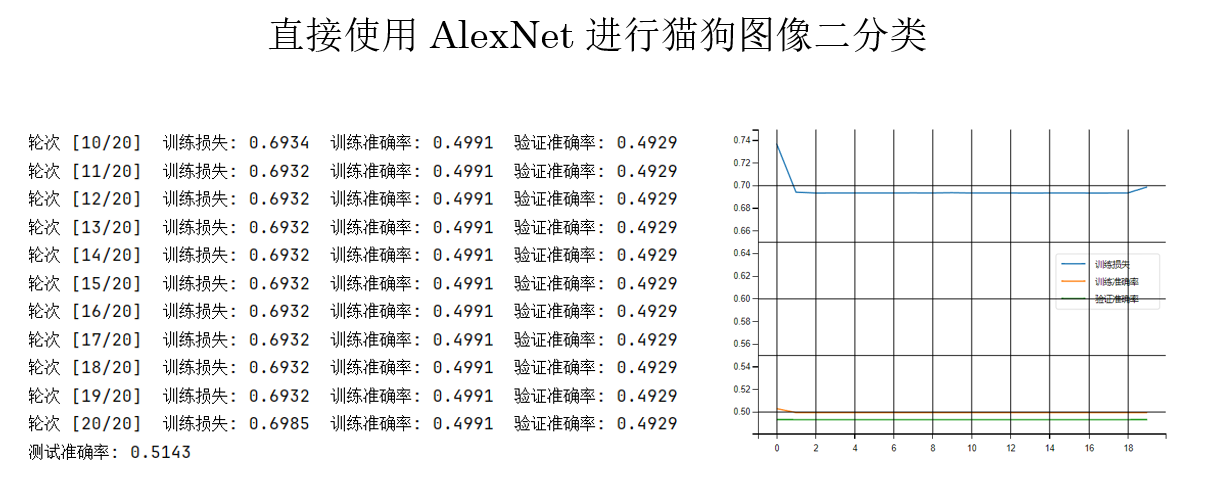
僅僅不使用預訓練參數,訓練過程就明顯變得困難、損失下降緩慢,前幾層幾乎學不到有意義的特徵,表現出典型的梯度消失現象。
原因在於:AlexNet 參數規模大,但缺乏 BN 和殘差等穩定訓練的結構設計,在小數據集上很難把梯度有效傳回前層。
因此,我們由此進行一些調試:
- 進行數據增強變相“增加數據量”,這一點在原論文也提到過。
- 縮小學習率,調試能否避免像這樣一樣“卡死”。
transform = transforms.Compose([
# (1)尺度裁剪
transforms.RandomResizedCrop(
224,
scale=(0.8, 1.0),
ratio=(0.9, 1.1)
),
# (2)左右翻轉
transforms.RandomHorizontalFlip(p=0.5),
# (3)旋轉
transforms.RandomRotation(
degrees=10,
interpolation=transforms.InterpolationMode.BILINEAR
),
# (4)顏色抖動
transforms.ColorJitter(
brightness=0.2,
contrast=0.2,
saturation=0.2,
hue=0.05
),
transforms.ToTensor(),
# (5)標準化
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
),
])
optimizer = optim.Adam(model.parameters(), lr=0.0001)
現在再來看結果:
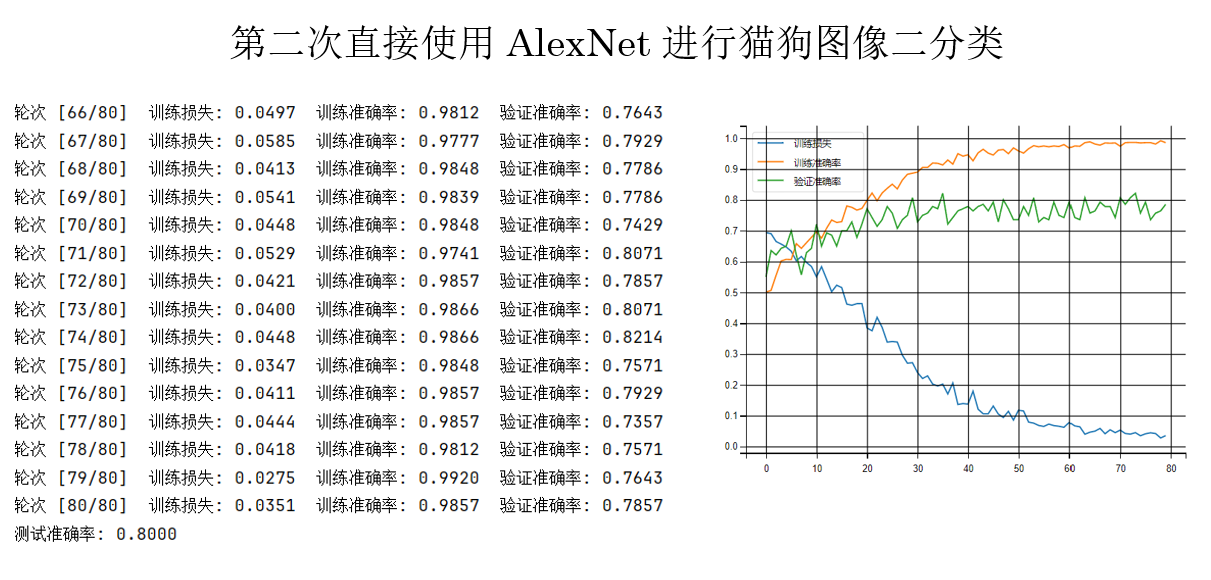
很明顯有了好轉,損失穩步下降,但是又出現了過擬合傾向。
我們先不着急繼續優化,來看看別的模型的表現。
2.3 VGG-16
現在,保持其他所有參數不變,只改變模型為沒有預訓練的 VGG-16:
model = models.vgg16(pretrained=False)
再次運行,看看結果:
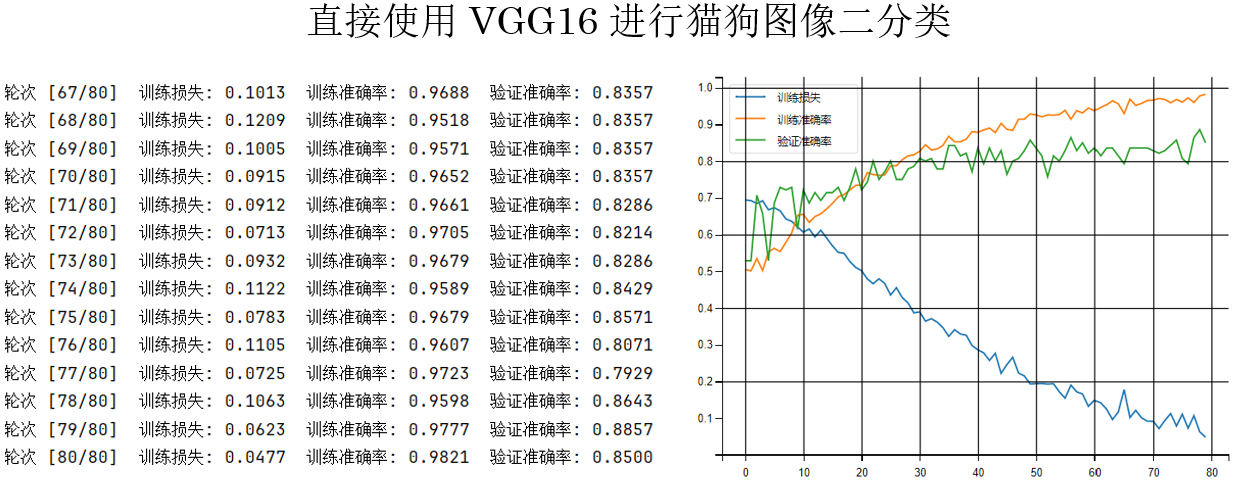
你會發現,在相同的參數設置下,AlexNet的驗證準確率最高只能達到80%,而 VGG-16 卻可以幾乎穩定在80%以上。
簡單總結來看:
- 在相同訓練設置下,VGG-16 比 AlexNet 更容易從頭訓練,訓練過程也更穩定。
- 原因在於 VGG-16 使用了統一的小卷積核結構,特徵是逐層、漸進式學習的,梯度傳播更順暢。
因此,VGG-16 比 AlexNet 更好優化。
繼續,最後登場的是 ResNet 。
2.4 ResNet-18
同樣,我們先回顧一下它的網絡結構:
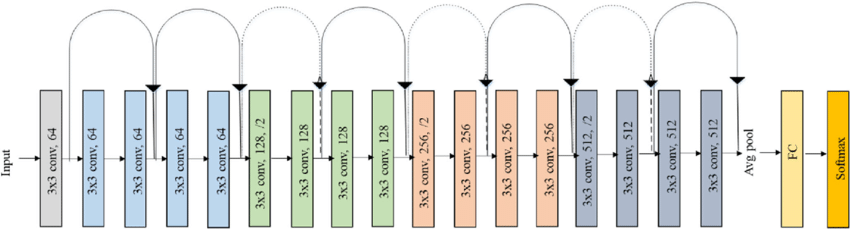
我們對它的使用也並不陌生:
model = models.resnet18(pretrained=False)
model.fc = nn.Linear(model.fc.in_features, 1)
同樣保持其他參數不變,來看看運行結果:
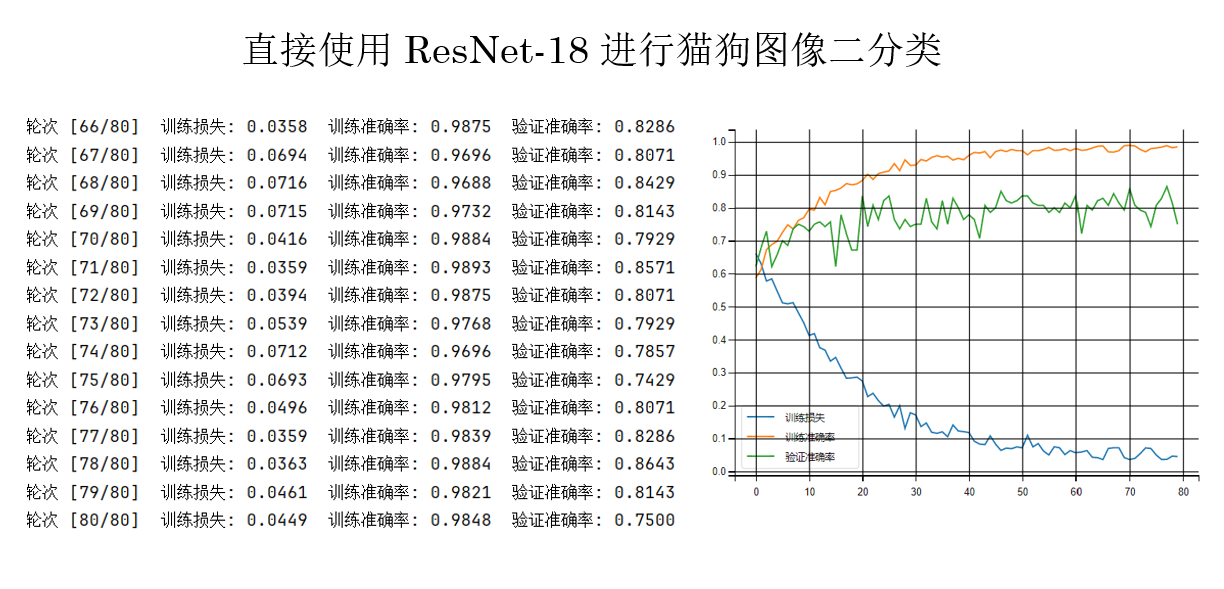
在這個實驗規模下,ResNet-18 的優勢還未被完全放大,但它的訓練過程已經表現出明顯的穩定性優勢,這正是殘差結構的核心價值。
2.5 對比總結
| 模型 | 結構特點 | 訓練難度 | 實驗表現 | 核心結論 |
|---|---|---|---|---|
| LeNet-5 | 淺層網絡,卷積 + 池化 + 全連接,參數量小 | 非常容易 | 在 MNIST 上快速收斂,準確率接近 100% | 結構簡單但有效,適合小圖像、低複雜度任務 |
| AlexNet | 較深網絡,大卷積核 + 大量全連接層,無 BN、無殘差 | 困難 | 小數據集從頭訓練易梯度消失,需預訓練或強正則 | 表達能力強,但優化不穩定,強依賴數據規模與初始化 |
| VGG-16 | 統一小卷積核(3×3)堆疊,結構規則 | 中等 | 從頭訓練穩定,驗證準確率明顯高於 AlexNet | 結構“規整”比“更淺”更重要,更易優化 |
| ResNet-18 | 殘差連接(skip connection),梯度直通 | 最容易 | 訓練最穩定,小數據集也能正常收斂 | 殘差結構本質上解決了深層網絡難訓練問題 |
模型越往後發展,提升的重點不是“更強的表達能力”,而是“更容易被訓練好”。
當然這並不絕對,同樣有可以兼顧二者的強大技術,我們之後就會了解到。
回到現在,LeNet-5 結構簡單,在低複雜度任務上非常好訓;AlexNet 雖然更深,但缺乏良好的優化設計,小數據集上反而容易卡住;VGG-16 用規則的小卷積堆疊,讓網絡更深卻更穩定;而 ResNet-18 通過殘差連接給梯度開了“直通車”,徹底緩解了深層網絡難訓練的問題。
實際應用中,我們也能發現,在小規模數據集中,預訓練權重往往比模型深度更重要,而在從頭訓練時,結構是否好優化比參數量大小更關鍵。
3.附錄
3.1 訓練代碼 PyTorch版
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
# 數據預處理
transform = transforms.Compose([
# (1)尺度裁剪
transforms.RandomResizedCrop(
224,
scale=(0.8, 1.0),
ratio=(0.9, 1.1)
),
# (2)左右翻轉
transforms.RandomHorizontalFlip(p=0.5),
# (3)旋轉
transforms.RandomRotation(
degrees=10,
interpolation=transforms.InterpolationMode.BILINEAR
),
# (4)顏色抖動
transforms.ColorJitter(
brightness=0.2,
contrast=0.2,
saturation=0.2,
hue=0.05
),
# (5)轉 Tensor
transforms.ToTensor(),
# (6)標準化
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
),
])
dataset = datasets.ImageFolder(root='./cat_dog', transform=transform)
train_size = int(0.8 * len(dataset))
val_size = int(0.1 * len(dataset))
test_size = len(dataset) - train_size - val_size
train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ----------------------------------
# 重點:模型選擇
# ----------------------------------
# model = models.alexnet(pretrained=False) # 使用 AlexNet
# model = models.vgg16(pretrained=False) # 使用 VGG16
model = models.resnet18(pretrained=False) # 使用 ResNet18
# 替換最後一層分類器 AlexNet、VGG16 使用這行
# model.classifier[6] = nn.Linear(model.classifier[6].in_features, 1)
# 替換最後一層分類器 ResNet18 使用這行
model.fc = nn.Linear(model.fc.in_features, 1)
model = model.to(device)
# 訓練參數
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
epochs = 80
train_losses = []
train_accs = []
val_accs = []
for epoch in range(epochs):
model.train()
epoch_train_loss = 0
correct_train = 0
total_train = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_train_loss += loss.item()
preds = (outputs > 0.5).int()
correct_train += (preds == labels.int()).sum().item()
total_train += labels.size(0)
avg_train_loss = epoch_train_loss / len(train_loader)
train_acc = correct_train / total_train
train_losses.append(avg_train_loss)
train_accs.append(train_acc)
# 驗證集
model.eval()
correct_val = 0
total_val = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0).int()
correct_val += (preds == labels.int()).sum().item()
total_val += labels.size(0)
val_acc = correct_val / total_val
val_accs.append(val_acc)
print(f"輪次 [{epoch+1}/{epochs}] "
f"訓練損失: {avg_train_loss:.4f} "
f"訓練準確率: {train_acc:.4f} "
f"驗證準確率: {val_acc:.4f}")
# 可視化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,5))
plt.plot(train_losses, label='訓練損失')
plt.plot(train_accs, label='訓練準確率')
plt.plot(val_accs, label='驗證準確率')
plt.legend()
plt.grid(True)
plt.show()
# 測試集
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0).int()
correct += (preds == labels.int()).sum().item()
total += labels.size(0)
print(f"測試準確率: {correct / total:.4f}")
3.2 訓練代碼 TF版
由於官方模型庫並未提供 AlexNet 與 ResNet-18,我們分別採用手工實現(AlexNet)與結構等價模型(ResNet50)進行對比。
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
data_augmentation = tf.keras.Sequential([
layers.Resizing(256, 256),
layers.RandomCrop(224, 224),
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.05),
layers.RandomContrast(0.2),
])
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
"./cat_dog",
validation_split=0.2,
subset="training",
seed=42,
image_size=(224, 224),
batch_size=32
)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
"./cat_dog",
validation_split=0.2,
subset="validation",
seed=42,
image_size=(224, 224),
batch_size=32
)
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.prefetch(AUTOTUNE)
val_ds = val_ds.prefetch(AUTOTUNE)
# -------------------------------
# 模型選擇
# -------------------------------
# ---------- AlexNet ----------
# def build_alexnet():
# return models.Sequential([
# layers.Input(shape=(224, 224, 3)),
# data_augmentation,
# layers.Rescaling(1./255),
#
# layers.Conv2D(96, 11, strides=4, activation='relu'),
# layers.MaxPooling2D(3, strides=2),
#
# layers.Conv2D(256, 5, padding='same', activation='relu'),
# layers.MaxPooling2D(3, strides=2),
#
# layers.Conv2D(384, 3, padding='same', activation='relu'),
# layers.Conv2D(384, 3, padding='same', activation='relu'),
# layers.Conv2D(256, 3, padding='same', activation='relu'),
# layers.MaxPooling2D(3, strides=2),
#
# layers.Flatten(),
# layers.Dense(4096, activation='relu'),
# layers.Dropout(0.5),
# layers.Dense(4096, activation='relu'),
# layers.Dropout(0.5),
# layers.Dense(1) # ])
# model = build_alexnet()
# ---------- VGG-16 ----------
# base_model = tf.keras.applications.VGG16(
# include_top=False,
# weights=None, # input_shape=(224, 224, 3)
# )
# model = models.Sequential([
# layers.Input(shape=(224, 224, 3)),
# data_augmentation,
# layers.Rescaling(1./255),
# base_model,
# layers.Flatten(),
# layers.Dense(4096, activation='relu'),
# layers.Dropout(0.5),
# layers.Dense(4096, activation='relu'),
# layers.Dropout(0.5),
# layers.Dense(1)
# ])
# ---------- ResNet50 ----------
base_model = tf.keras.applications.ResNet50(
include_top=False,
weights=None,
input_shape=(224, 224, 3)
)
model = models.Sequential([
layers.Input(shape=(224, 224, 3)),
data_augmentation,
layers.Rescaling(1./255),
base_model,
layers.GlobalAveragePooling2D(),
layers.Dense(1)
])
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"]
)
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=80
)
plt.figure(figsize=(10, 5))
plt.plot(history.history["loss"], label="訓練損失")
plt.plot(history.history["accuracy"], label="訓練準確率")
plt.plot(history.history["val_accuracy"], label="驗證準確率")
plt.legend()
plt.grid(True)
plt.show()