

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第三課第二週的課程習題部分的講解和代碼實踐。
1 . 理論習題
還是先上鍊接:【中英】【吳恩達課後測驗】Course 3 -結構化機器學習項目
這兩週的理論習題都是對一些實際項目中的選擇策略,還是不多提了,我們把重點放在下面對本週瞭解的遷移學習和多任務學習的演示上。
2. 代碼實踐
2.1 遷移學習
這次就撿起來我們之前的貓狗二分類模型,之前我們嘗試訓練這個模型,多輪訓練後驗證集的最高準確率也只在 70% 上下波動,來看看對這個模型應用遷移學習的效果。
在對二分類模型應用遷移學習前,先簡單介紹一下我們的遷移來源任務。
2.1.1 預訓練模型 ResNet18(ImageNet 預訓練)
我們使用的預訓練模型叫ResNet18,ResNet全稱為Residual Neural Network,中文翻譯為殘差神經網絡,18是指網絡深度。
這是一個非常經典且具有開創意義的模型結構,在大量的領域都能廣泛應用。而它最初的使用,就是在圖像分類上。
這裏擺一張網絡結構圖,暫時先不介紹它的結構和原理,課程在下一部分才正式介紹圖像學習的基本:卷積神經網絡,現在,只需要知道我們借來了一個很厲害的模型就好了。
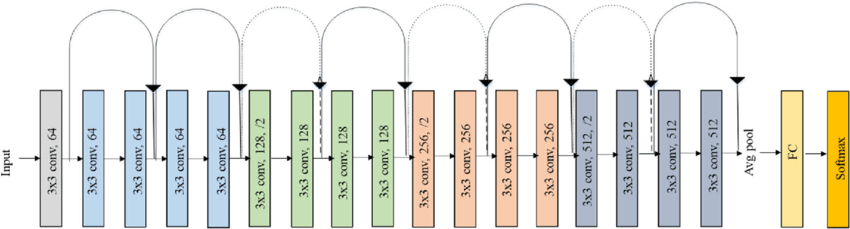
(注:這張圖來自這裏)
而對於ImageNet,我們之前也提到過:ImageNet 是一個包含 1400 萬張圖像、覆蓋 1000 個類別 的大型圖像分類數據集。每張圖像都帶有準確的標籤,相當於給模型提供了大量“優質原材料”,讓它先在通用視覺特徵上打下堅實基礎。

(注:這張則來自這裏)
雖然ImageNet本身也包括了貓和狗的圖像,有一些“透題”的感覺,但1000 類中“貓狗”類比例極小(不到 0.5%),超多的類別並不會讓它特別偏向二者的識別,而是通用的紋理識別。
因此,經過ImageNet預訓練的ResNet18模型仍很適合作為我們的遷移來源模型。
下面就看看如何改動我們之前的代碼來引入它。
2.1.2 PyTorch引入預訓練ResNet18
現在,我們就從代碼層面看看如何使用預訓練ResNet18。
(1)修改預處理以適應ResNet18輸入層
首先,引入預訓練ResNet18就代表數據從原本的輸入我們創建的模型改為輸入ResNet18。
所以,我們首先就應該更改數據預處理方法以匹配ResNet18輸入層。
而在PyTorch裏,負責數據預處理的就是transforms模塊。
先看看我們原來的預處理:
transform = transforms.Compose([
transforms.Resize((128, 128)),
# 將圖像的大小調整為 128x128 像素,保證輸入圖像的一致性
transforms.ToTensor(),
# 將圖像從 PIL 圖像或 NumPy 數組轉換為 PyTorch 張量,圖像的像素值也會被從 [0, 255] 範圍映射到 [0, 1 ]範圍,這是使用 Pytorch 固定的一步。
transforms.Normalize((0.5,), (0.5,))
# 標準化,原本在 [0, 1] 範圍內的像素值會變換到 [-1, 1] 範圍內。
])
·····中間代碼
self.hidden1 = nn.Linear(128 * 128 * 3, 1024) # 模型輸入層,對應輸入維度和Resize大小對應,* 3是因為彩色圖片有三個通道。
而現在,使用ResNet18,自然就要匹配他的一些輸入設置,所以,我們修改成如下設置:
transform = transforms.Compose([
transforms.Resize((224, 224)), # ResNet 輸入 224x224 這一步一定要有
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]) # ResNet 官方均值方差
# 這些數字是基於 ImageNet 數據集 上的統計計算得到的,是針對每個通道的均值和方差。
])
如果你忘了標準化的是用來做什麼的,我們第一次介紹它是在這裏:歸一化
現在,我們的數據經過預處理就能順利輸入ResNet18了,我們繼續下一步。
(2)調用預訓練ResNet18模型
同樣,PyTorch 內置了 ResNet18 的模型結構,我們這樣調用它:
model = models.resnet18(pretrained=True)
# pretrained 參數的T和F就代表是否使用預訓練的模型參數,這裏的 True 就代表使用。
# 而如果更改為 False ,就代表只使用 ResNet18 的網絡結構。
注意,這時我們原本設計的網絡結構就被這一行替代了。
(3)第一次嘗試:freeze遷移
我們先試試freeze遷移,也就是ResNet18的任何一層的參數都固定,不參與反向傳播。
這樣設置:
for param in model.parameters():
param.requires_grad = False # 默認為 True
# 顯然,這個 for 循環就是在對現在模型每一層説:“不要參與反向傳播”
(4)替換輸出頭以適配遷移目標任務
這一步的邏輯就是找到輸出層,替換輸出層。
要強調的一點是,這一步一定要在凍結之後進行。
替換層級會讓層級初始化,並默認參與反向傳播。 如果你把凍結放在了這步之後,那整個網絡就不存在反向傳播了。
來看看具體怎麼做:
num_features = model.fc.in_features
# 這一行是在獲取模型的一個叫 fc 的層的輸入維度。
# 我們一般將網絡的最後一層全連接層命名為 fc
# 也就是説,這一行是在獲取模型的輸出層的輸入維度。
model.fc = nn.Sequential(
# Sequential 是 PyTorch 提供的一個容器類,它允許將多個層按順序組合在一起。
nn.Linear(num_features, 1),
nn.Sigmoid()
)
# 很明顯,我們把最後一層換成了只有一個神經元並經過Sigmoid激活來適配我們的任務要求。
我只是將原模型的輸出層更改成適配貓狗二分類的結構,如果你想在最後增加更多自己的層級設置,只需要在 Sequential 裏按順序添加,並確保層間維度匹配即可。
好了,現在我們就完成了所有配置,來看看效果吧。
2.1.3 第一次運行:freeze遷移+目標任務數據較多
回憶一下,我們的貓狗數據集總共只有 2400 幅圖像,這時一個相當小規模的數據集。在經過劃分後,用於訓練的數據就只有約 2000 個樣本,我們是這樣設置的:
train_size = int(0.8 * len(dataset))
我們先看看不改變這個劃分,只應用遷移學習的效果,結果如下:
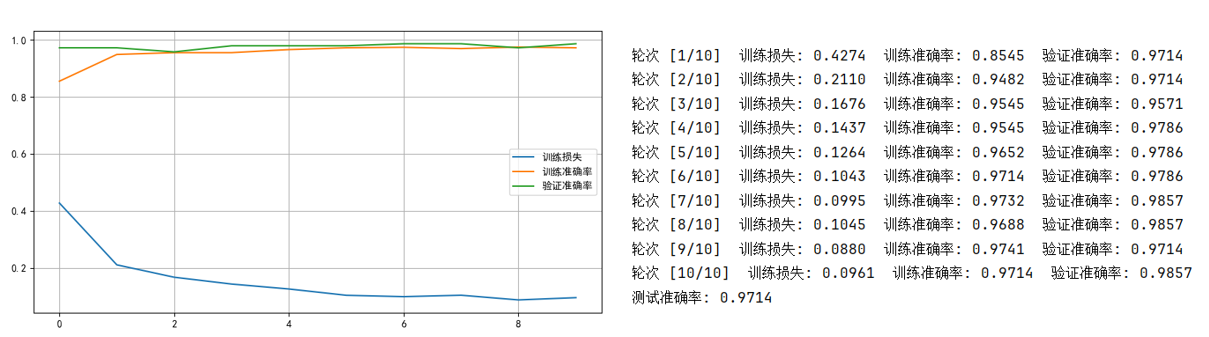
好傢伙,強大無需多言,即使是隻訓練一輪的效果就已經強於我們之前的訓練效果了。
簡單分析一下原因:
- ImageNet 的超大規模樣本讓 ResNet18 模型學習了對通用特徵的識別。
- 卷積網絡和殘差網絡本身在圖學習的優越性也幫助了擬合。
簡單打個比方就是:教材好+學生聰明。
2.1.4 第二次運行:freeze遷移+目標任務數據較少
之前我們在遷移學習的理論部分裏提到過,遷移學習的出現原因還是因此遷移目標任務的數據不足。
我們再次嚴格一下這個條件試試:
train_size = int(0.1 * len(dataset))
現在,訓練集,驗證集,測試集都只有 240 個樣本,我們再來看看效果:
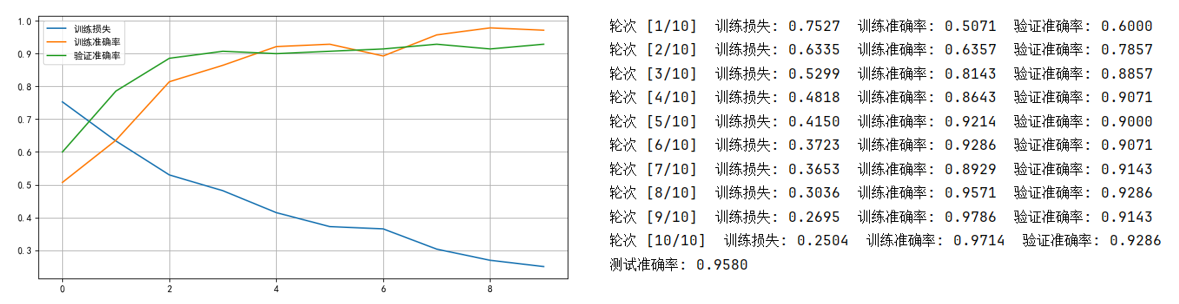
可以看到和第一次運行的最大差別就在於最開始的輪次效果。
換句話説,這一次我們只給模型提供了很少的“練習題”,而模型只能依靠最後一層去適應貓狗分類這個任務。
繼續打比方:這就像你找了一個學過大量數學知識的學霸來做一套小測驗,他的思維能力依然很強,但題目太少,所以在前面幾道題裏發揮得並不穩定。
不過隨着訓練輪次增加,曲線還是逐漸穩定下來,這説明遷移學習確實提供了很好的“啓動點”。
最終的結果也再次驗證了一個關鍵結論:數據越少,遷移學習越有價值。
如果我們不遷移、從頭訓練,那麼240 張訓練圖像幾乎不可能產生有意義的分類能力,而 freeze 遷移學習卻做到了“可用”。
現在,我們再來看看遷移學習的另一種形式。
2.1.5 第三次運行:fine-tuning
現在,我們再試試 fine-tuning 的效果,它是指在預訓練基礎上整體微調,也就是説,我們現在要”解凍“ 模型之前的層級。
如何解凍?你可能已經想到了:
for param in model.parameters():
param.requires_grad = False # 默認為 True
把這兩行刪掉或者註釋掉就OK了。
現在來看看運行結果,這裏我把訓練集佔比恢復到了0.8:
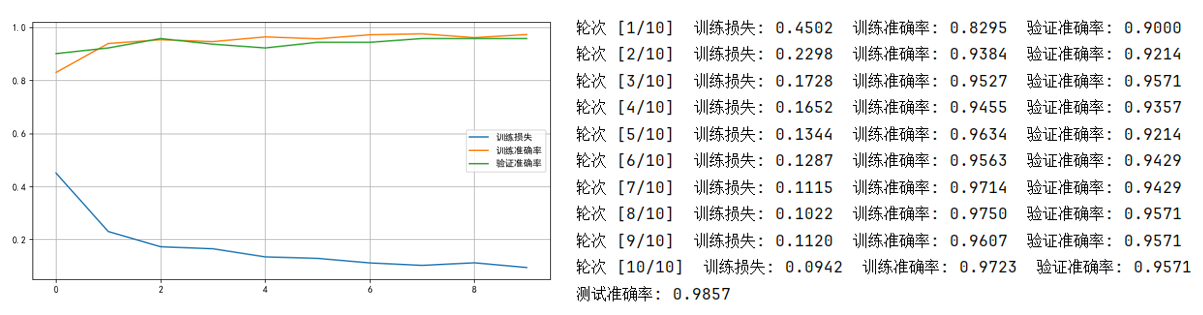
很顯然,效果仍然不錯,就不再詳細解釋了。
最後要説的是,遷移學習是我們在面對當前任務數據不足時的一種選擇,但它的效果不一定會像我們現在展示的這麼好。
雖然我們之前訓練貓狗二分類的結果一直不太好,但實際上是因為課程把卷積網絡安排在了後面介紹,我們之前使用全連接網絡訓練更像是"狗拿耗子",自然不會有很好的結果。
實際上,貓狗二分類只是一個圖學習中入門級的任務,加上和 ResNet18 的適配,所以在這次演示中起到了很好的效果,如果要應用遷移學習,還是要視具體任務選擇。
在調優過程中,不變的還是不斷的嘗試。
下面就來看看這周瞭解的另一種學習方式:多任務學習。
2.2 多任務學習
多任務學習在代碼邏輯上的重點在於數據集標籤和網絡結構上,其他部分不會產生太大的變化。
這部分就不再找專門的數據集來進行演示了,我們重點看看如何實現多任務學習的“前面共享、後面分頭”的結構。
還是先拿我們之前的老結構拿出來曬曬:
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.hidden1 = nn.Linear(128 * 128 * 3, 1024)
self.hidden2 = nn.Linear(1024, 512)
self.hidden3 = nn.Linear(512, 128)
self.hidden4 = nn.Linear(128, 32)
self.hidden5 = nn.Linear(32, 8)
self.hidden6 = nn.Linear(8, 3)
self.relu = nn.ReLU()
self.output = nn.Linear(3, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.flatten(x)
x = self.relu(self.hidden1(x))
x = self.relu(self.hidden2(x))
x = self.relu(self.hidden3(x))
x = self.relu(self.hidden4(x))
x = self.relu(self.hidden5(x))
x = self.relu(self.hidden6(x))
x = self.sigmoid(self.output(x))
return x
如果不使用這種一條路走到底的線性結構,而是實現允許“分叉” 的多任務學習樹形結構,就是這部分內容。
2.2.1 多任務學習的網絡結構
下面給出一個簡單的例子:
任務A:二分類(貓狗)
任務B:圖像亮度迴歸(0~1)
網絡結構就可以變成這樣:
class MultiTaskNet(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.relu = nn.ReLU()
# —— 前面共享部分 ——
self.shared1 = nn.Linear(128 * 128 * 3, 1024)
self.shared2 = nn.Linear(1024, 256)
# —— 後面分頭部分 ——
# 任務 A:貓狗二分類
self.headA = nn.Linear(256, 1)
# 任務 B:亮度迴歸
self.headB = nn.Linear(256, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.flatten(x)
x = self.relu(self.shared1(x))
x = self.relu(self.shared2(x))
outA = self.sigmoid(self.headA(x)) # 分類
outB = self.headB(x) # 迴歸
return outA, outB # 返回量增加為兩個
你可以看到,整個結構的前半部分的參數是共享的;後半部分兩個任務分頭走,最後的兩個返回值就是對兩個任務的預測。
2.2.2 多任務學習的損失函數怎麼寫?
因為現在有兩個輸出,就需要計算兩個任務的損失,再把它們加起來:
lossA = criterionA(outA, labelA) # 比如二分類 BCE
lossB = criterionB(outB, labelB) # 比如 MSE 迴歸損失
loss = lossA + lossB
loss.backward()
如果兩個任務重要程度不同,也可以加權:
loss = 0.7 * lossA + 0.3 * lossB
比如主任務是貓狗分類,輔助任務是亮度預測,那就讓“分類任務”權重大一點。
這就是本篇的全部內容了,下一章就到計算機視覺部分了,也就終於可以展開之前一直在提的卷積網絡了。
3.附錄
3.1 Pytorch版 遷移學習代碼
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
transform = transforms.Compose([
transforms.Resize((224, 224)), # ResNet 輸入 224x224 transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]) # ResNet 官方均值方差
])
dataset = datasets.ImageFolder(root='./cat_dog', transform=transform)
train_size = int(0.8 * len(dataset))
val_size = int(0.1 * len(dataset))
test_size = len(dataset) - train_size - val_size
train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = models.resnet18(pretrained=True)
# 是否凍結預訓練參數
for param in model.parameters():
param.requires_grad = False
# 替換最後一層
num_features = model.fc.in_features
model.fc = nn.Sequential(
nn.Linear(num_features, 1),
nn.Sigmoid()
)
model = model.to(device)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.fc.parameters(), lr=0.001)
epochs = 10
train_losses = []
train_accs = []
val_accs = []
for epoch in range(epochs):
model.train()
epoch_train_loss = 0
correct_train = 0
total_train = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_train_loss += loss.item()
preds = (outputs > 0.5).int()
correct_train += (preds == labels.int()).sum().item()
total_train += labels.size(0)
avg_train_loss = epoch_train_loss / len(train_loader)
train_acc = correct_train / total_train
train_losses.append(avg_train_loss)
train_accs.append(train_acc)
model.eval()
correct_val = 0
total_val = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0.5).int()
correct_val += (preds == labels.int()).sum().item()
total_val += labels.size(0)
val_acc = correct_val / total_val
val_accs.append(val_acc)
print(f"輪次 [{epoch+1}/{epochs}] "
f"訓練損失: {avg_train_loss:.4f} "
f"訓練準確率: {train_acc:.4f} "
f"驗證準確率: {val_acc:.4f}")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,5))
plt.plot(train_losses, label='訓練損失')
plt.plot(train_accs, label='訓練準確率')
plt.plot(val_accs, label='驗證準確率')
plt.legend()
plt.grid(True)
plt.show()
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0.5).int()
correct += (preds == labels.int()).sum().item()
total += labels.size(0)
print(f"測試準確率: {correct / total:.4f}")
3.2 Tensorflow版 遷移學習代碼
注:TF沒有內置ResNet的18版本,而是ResNet50以及更高的版本,而TF和提供第三方 ResNet18 庫的兼容性又不太好,因此這裏實際上使用的是ResNet50。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
IMG_SIZE = (224, 224)
BATCH_SIZE = 32
train_ds = keras.preprocessing.image_dataset_from_directory(
"./cat_dog",
validation_split=0.2,
subset="training",
seed=42,
image_size=IMG_SIZE,
batch_size=BATCH_SIZE
)
val_test_ds = keras.preprocessing.image_dataset_from_directory(
"./cat_dog",
validation_split=0.2,
subset="validation",
seed=42,
image_size=IMG_SIZE,
batch_size=BATCH_SIZE
)
val_ds = val_test_ds.take(len(val_test_ds) // 2)
test_ds = val_test_ds.skip(len(val_test_ds) // 2)
preprocess = keras.applications.resnet50.preprocess_input
def preprocess_fn(image, label):
return preprocess(tf.cast(image, tf.float32)), tf.cast(label, tf.float32)
train_ds = train_ds.map(preprocess_fn)
val_ds = val_ds.map(preprocess_fn)
test_ds = test_ds.map(preprocess_fn)
train_ds = train_ds.prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.prefetch(tf.data.AUTOTUNE)
# 構建遷移學習模型(凍結 ResNet50)
base_model = keras.applications.ResNet50(
weights="imagenet",
include_top=False,
input_shape=(224, 224, 3),
pooling="avg"
)
base_model.trainable = False # 凍結
inputs = keras.Input(shape=(224, 224, 3))
x = base_model(inputs, training=False)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=0.001),
loss="binary_crossentropy",
metrics=["accuracy"]
)
# 訓練
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=10
)
plt.figure(figsize=(10, 5))
plt.plot(history.history["loss"], label="訓練損失")
plt.plot(history.history["accuracy"], label="訓練準確率")
plt.plot(history.history["val_accuracy"], label="驗證準確率")
plt.legend()
plt.grid(True)
plt.show()
test_loss, test_acc = model.evaluate(test_ds)
print("測試準確率:", test_acc)
3.3 Tensorflow版 多任務學習網絡結構
class MultiTaskNet(tf.keras.Model):
def __init__(self):
super(MultiTaskNet, self).__init__()
# —— 前面共享部分 ——
self.flatten = layers.Flatten()
self.shared1 = layers.Dense(1024, activation='relu')
self.shared2 = layers.Dense(256, activation='relu')
# —— 後面分頭部分 ——
# 任務 A:貓狗二分類
self.headA = layers.Dense(1, activation='sigmoid')
# 任務 B:亮度迴歸
self.headB = layers.Dense(1, activation=None)
def call(self, inputs, training=False):
x = self.flatten(inputs)
x = self.shared1(x)
x = self.shared2(x)
outA = self.headA(x) # 分類輸出
outB = self.headB(x) # 迴歸輸出
return outA, outB