

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第五課第三週的內容,3.9到3.10的內容,同時也是本週理論部分的最後一篇。
本週為第五課的第三週內容,與 CV 相對應的,這一課所有內容的中心只有一個:自然語言處理(Natural Language Processing,NLP)。
應用在深度學習裏,它是專門用來進行文本與序列信息建模的模型和技術,本質上是在全連接網絡與統計語言模型基礎上的一次“結構化特化”,也是人工智能中最貼近人類思維表達方式的重要研究方向之一。
這一整節課同樣涉及大量需要反覆消化的內容,橫跨機器學習、概率統計、線性代數以及語言學直覺。
語言不像圖像那樣“直觀可見”,更多是抽象符號與上下文關係的組合,因此理解門檻反而更高。
因此,我同樣會儘量補足必要的背景知識,儘可能用比喻和實例降低理解難度。
本週的內容關於序列模型和注意力機制,這裏的序列模型其實是指多對多非等長模型,這類模型往往更加複雜,其應用領域也更加貼近工業和實際,自然也會衍生相關的模型和技術。而注意力機制則讓模型在長序列中學會主動分配信息權重,而不是被動地一路傳遞。二者結合,為 Transformer 等現代架構奠定了基礎。
本篇的內容關於語音識別和觸發字檢測,是 seq2seq 模型在音頻數據上的應用。
1. 音頻數據(Audio data)
音頻數據雖然和文本數據同樣都為序列數據,但是如果我們希望實現相關的應用,所尋找到的數據集樣本往往都是一段段連續的錄音,無法直接輸入模型。
因此,就像為文本數據構建詞典一樣,在使用 seq2seq 模型完成在語音領域的任務時,我們同樣需要對音頻數據進行預處理,而這就涉及到音頻數據本身的特點。
1.1 音位(Phoneme)
在展開音頻數據的預處理方式之前,有必要先引入一個語言學中的概念:音位(phoneme)。
音位是一種抽象的語音單位,其定義並非基於聲學相似性,而是基於是否能夠區分詞義。
在某一語言中,如果兩個發音單元的替換會導致詞義變化,它們就屬於不同的音位;反之,即使在物理髮音上存在差異,只要不影響詞義,它們仍被視為同一音位。
換句話説,音位關心的是語言系統內部能區分意義的功能,而不是具體的發音表現。
通過大量對比,語言學家逐步歸納出某一語言的音位系統。在英語中,音位通常藉助音標來表示,但音標與音位又並不等同:音標只是描述發音的工具,而音位是一種功能性分類結果。同一個音位在不同語音環境中可能呈現略有不同的實際發音形式(如口音差異),但只要這些差異不承擔區分語義的功能,它們仍被視為同一音位的不同實現。
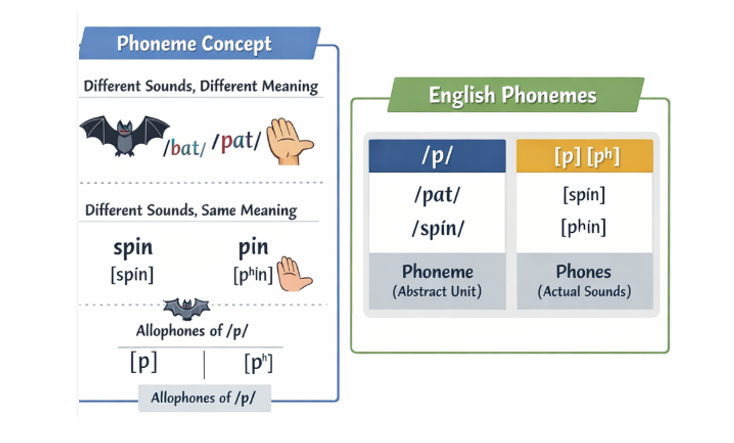
這便是音位的基本概念,到這裏,一個自然而然的想法就是把音頻數據處理為連續的音位序列,就像文本數據一樣進行處理輸入模型。
然而,我們剛剛也提到了,音位雖然可以代表語義,但是這是我們人為歸納的特徵而不是音頻本身的屬性。因此,在實驗中,音位並不是可以直接從連續的音頻波形中觀測得到的量。
其獲取過程高度依賴人工標註、規則設計或複雜的對齊模型,這也在實踐中限制了其作為模型直接輸入的可行性。
這一現實,直接推動了後續更偏向信號層面的語音表示方法的發展,也為聲譜圖等特徵形式的廣泛應用奠定了背景。
1.2 聲譜圖(Spectrogram)
由於音位是人為抽象的單位,無法直接從連續的音頻波形中觀測得到,因此在實際語音處理與建模中,我們更傾向於使用信號層面的連續特徵表示,其中最常用的表示方式之一就是聲譜圖(spectrogram)。
聲譜圖是一種將音頻信號在時間與頻率域上進行表示的二維圖像。
簡單來説,它將連續的音頻波形分割為短時片段,並對每個片段計算頻譜能量,從而得到時間-頻率矩陣,矩陣中的每個值反映該時刻該頻率成分的強度,就像這樣:
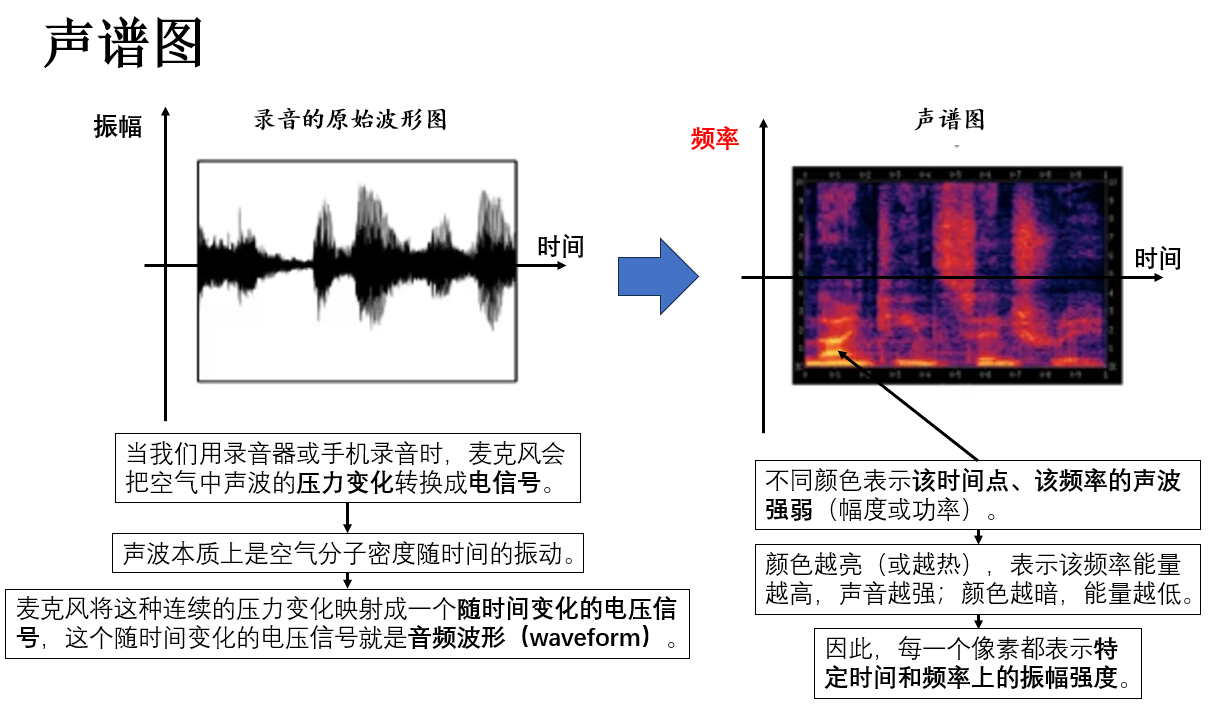
通過這種方式,原本連續的波形被轉換為一組能夠揭示語音細節的特徵,既保留了聲音的動態變化,也便於計算機處理。
在計算機處理時,聲譜圖的每一列包含該時間片段所有頻率的能量值,可以看作一個多維向量。因此,我們通常把聲譜圖的每一列視為一個時間步的輸入向量。
這樣,原本二維的時間-頻率矩陣就被轉化為時間序列的特徵向量序列,與文本序列類似,使模型能夠在連續語音中捕捉語義和聲學模式。
聲譜圖的關鍵優勢在於無需人工標註音位的同時保留了豐富的聲學信息,並且其二維矩陣形式可以直接作為模型輸入,實現端到端語音識別、聲學建模或語音生成。
瞭解了對音頻數據的基本處理邏輯後,現在就來看看其應用:
2. 語音識別(Speech Recognition)
對音頻數據最常見的應用領域就是語音識別。生活中,我們最常用的例子可能是微信的語音轉文字,也包括語音助手、電話客服的語音輸入等。
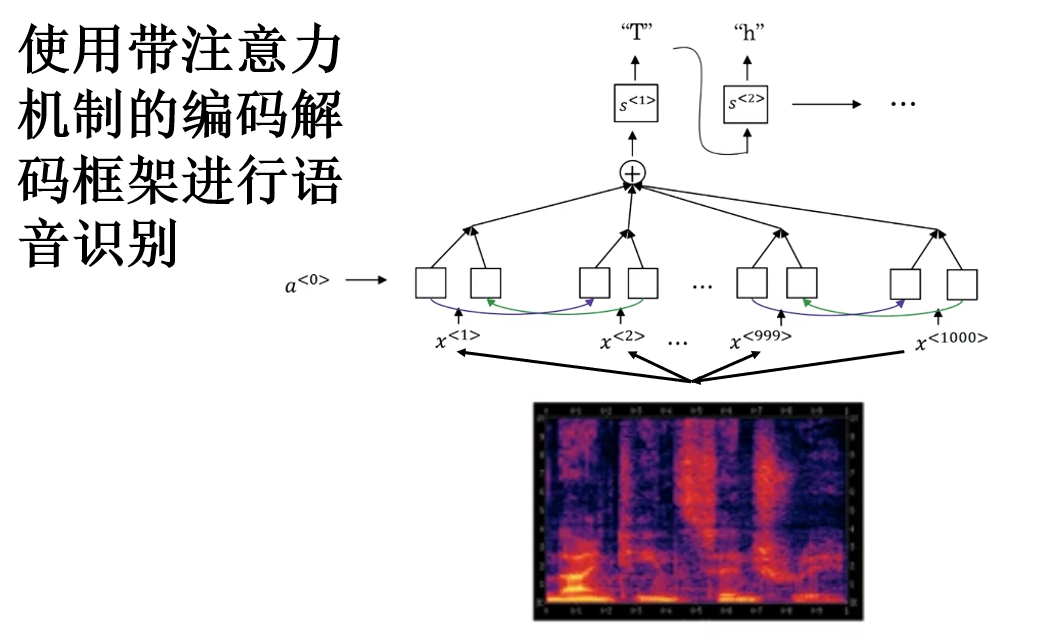
語音識別的核心任務是將連續的音頻信號映射為文字序列。由於音頻本身是連續信號,而文字序列是離散符號序列,因此,這一任務本質上也是一個 seq2seq 問題。
一個主流且常見的訓練方式就是應用我們剛剛介紹的帶注意力機制的編碼解碼框架:
此外,還存在一種獨特的技術,我們稱為 CTC(Connectionist Temporal Classification) 。
CTC 是一種專門用於處理輸入輸出長度不匹配的序列學習方法,非常適合語音識別這樣的任務。它的核心思想是:允許模型在連續的時間步上輸出“空白”或重複符號,從而自動對齊輸入序列與輸出序列。
它提出於 06 年的一篇論文:Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
可以發現,CTC 的提出較早,因此也並沒有使用編碼解碼框架,而是等長多對多模型框架。不過如今 CTC 也並沒有被完全淘汰,它仍常見於一些混合方案中。
我們簡單展開如下:
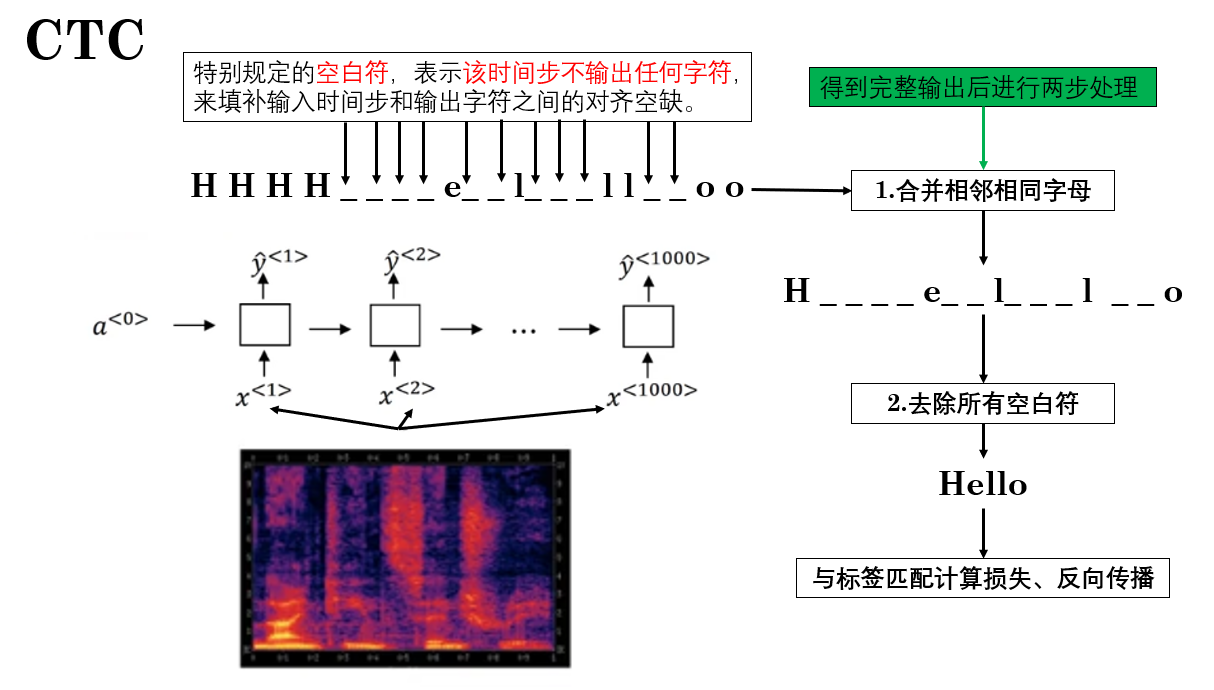
再複述一下其核心思想: CTC 通過引入 blank(空白)符號 和 重複合併規則 來對齊輸入與輸出,來實現端到端訓練,無需在標籤中人工對齊每一幀。
當然,你也會發現它對長距離依賴建模能力有限,對長句子性能很大可能不如注意力機制,瞭解即可。
3. 觸發字檢測(Trigger Word Detection / Keyword Spotting)
對於觸發字檢測我們也並不陌生,生活中最常見的例子包括語音助手的喚醒詞“Hey Siri”“小愛同學”“Alexa”,只有檢測到這些觸發詞後,設備才會進入完整語音識別流程。
不同於語音識別,觸發字檢測任務更為精簡,它在建模中關注的問題是:在連續語音流中,判斷某個特定關鍵詞是否被説出,以及它出現的大致時間位置。
因此,一個關鍵點在於:觸發字檢測模型因其實時性更適合多對多等長模型,模型每個時間幀預測一個觸發概率或二分類信號,表示當前幀是否屬於觸發詞的一部分。
簡單展開如下:
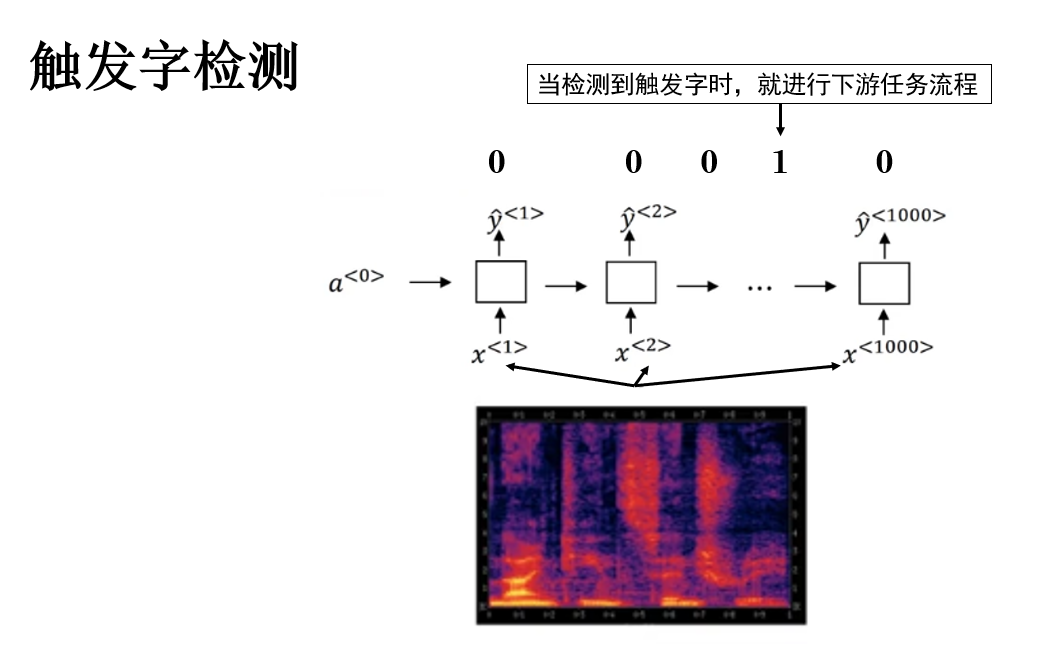
傳播過程並不複雜,但有一點需要注意:觸發字檢測的任務特徵決定了其數據往往是不平衡的,即絕大多數標籤都為 0 ,這導致即使模型全部輸出 0 ,也能得到較好的指標,從而導致錯誤判斷和部署。
對此,一種常用緩解策略是擴展正樣本標籤:不僅將觸發詞對應的幀標記為 1,還將其之後若干幀也標記為 1,形成一個時間段的正樣本窗口,這既平衡了樣本,也符合實際觸發的延遲容忍需求。
總結來説,觸發字檢測本質是低延遲的序列二分類任務。建模邏輯為:先將音頻轉化為時間序列特徵,再利用多對多等長模型預測每一幀的觸發概率,也可通過平滑或滑窗處理得到最終觸發決策。
4.總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 音位(Phoneme) | 語言學中的抽象單位,基於是否能區分詞義進行分類;同一音位在不同環境下可有不同發音,但功能相同。 | 就像文字中的字母,不同字母組合產生不同單詞,但同一字母在不同字體中仍表示相同字母。 |
| 聲譜圖(Spectrogram) | 將音頻分幀並計算每幀的頻譜能量,得到時間-頻率矩陣;每列作為時間步輸入向量,用於模型訓練。 | 好比把連續的聲音切成一格格“照片”,每格顯示不同頻率的亮度,連續播放形成動態影像。 |
| 語音識別(Speech Recognition) | 將連續音頻信號映射為文字序列,可用注意力編碼解碼框架處理 seq2seq 問題,也可用 CTC 進行端到端訓練。 | 就像把一段連續的河流水流(聲音波形)逐段翻譯成文字,注意力機制像有導遊指引每段對應文字,CTC像自動對齊標記。 |
| CTC(Connectionist Temporal Classification) | 輸入為時間序列特徵;允許輸出空白符和重複符號,通過合併規則對齊輸出序列;無需逐幀標註。 | 好比在長河上放置浮標(空白符),只標記關鍵節點,最後整理成整段文字。 |
| 觸發字檢測(Trigger Word Detection / Keyword Spotting) | 輸入音頻轉時間序列特徵;多對多等長模型預測每幀觸發概率;可通過標籤擴展、平滑或滑窗處理緩解數據不平衡。 | 就像警報系統監測連續流水聲,只在聽到特定聲響(觸發詞)後報警,而非逐秒記錄每滴水。 |