

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第四課的第四周內容,4.6到4.11的內容,同時也是本篇理論部分的最後一篇。
本週為第四課的第四周內容,這一課所有內容的中心只有一個:計算機視覺。應用在深度學習裏,就是專門用來進行圖學習的模型和技術,是在之前全連接基礎上的“特化”,也是相關專業裏的一個重要研究大類。
這一整節課都存在大量需要反覆理解的內容和機器學習、數學基礎。 因此我會盡可能的補足基礎,用比喻和實例來演示每個部分,從而幫助理解。
第四周的內容是對前三週內容的綜合應用,介紹了一些通過卷積網絡實現的實際應用,它們在使用卷積網絡的基礎上又各有自己的特點來匹配不同的任務要求,是對如何真實應用卷積網絡的良好演示。
本篇的內容關於圖像風格轉換。
1. 什麼是圖像風格轉換?
並不難理解,我們之前也提到過它,用課程裏的例子來進行演示:

如圖所示,使用圖像風格轉換,我們就可以把自己拍的照片在保證內容不變的同時,轉換成名畫,或者整蠱版的畫風。這種應用更貼近我們的生活,在現在的手機應用裏也十分普遍。
現在就來看看如何實現圖像風格轉換。
2. 如何實現圖像風格轉換?
我們已經不止一次提到,神經網絡中的許多學習任務,本質上都可以抽象為一個優化問題:通過定義合適的目標函數,並藉助梯度下降等方法,使優化目標不斷減小,從而得到期望的結果。
在監督學習中,這一過程通常表現為不斷更新模型參數,以減小模型輸出與標籤之間的差異。
而在圖像風格轉換任務中,也沿用了同樣的優化思想。
此時,我們需要回答的關鍵問題是:如何度量內容圖像與風格圖像之間的差異,使生成結果在保持內容結構的同時,逐步逼近目標風格?
答案就在於構造合適的代價函數。
代價函數這個名字已經很久沒有出現過了,我們先回顧一下損失函數和代價函數的概念:前者是單個樣本輸出和標籤之間的差距,後者是訓練集中所有樣本輸出和標籤之間差距的平均值。
但在實際工程實現和大量論文中,二者往往被混用,深度學習框架中也普遍使用 loss 來指代最終用於反向傳播的優化目標。
因此,雖然二者數學上可區分,但在實際工程上經常不區分,我們明白含義就好。
回到正題,在 2015 年,一篇名為A Neural Algorithm of Artistic Style的論文首次提出神經風格轉換的概念。
這篇論文的核心思想是:在固定預訓練卷積神經網絡參數的前提下,利用網絡中間層特徵,將圖像的內容結構與風格統計進行顯式分離,並通過在特徵空間中最小化相應的代價函數,直接對輸入圖像進行優化,從而重構出一幅同時匹配內容與風格約束的圖像。
簡單來説,圖像風格轉換的代價函數被分成了兩部分:內容代價函數和風格代價函數:
其中,\(\mathcal{J}_{\text{content}}\) 用於約束生成圖像在高層特徵空間中與內容圖像保持一致,\(\mathcal{J}_{\text{style}}\) 則通過統計特徵相關性來刻畫並匹配目標風格,\(\alpha\) 與 \(\beta\) 用於平衡內容與風格在生成結果中的相對重要性。
陳述偏學術,有些迷惑很正常,我們下面就來詳細展開:
2.1 圖像風格轉換的訓練邏輯
在剛剛説明神經風格轉換的核心思想時,你可能注意到了一個細節:固定預訓練卷積神經網絡參數。
這意味着,我們在優化的過程中不去改變網絡本身的權重。
那問題來了:如果網絡不動,代價函數還能下降嗎?答案是肯定的——關鍵在於優化的對象變了。
這便是神經風格轉換的一個核心點:被優化的不是網絡參數,而是生成圖像本身。
這是什麼意思?我們展開説明:
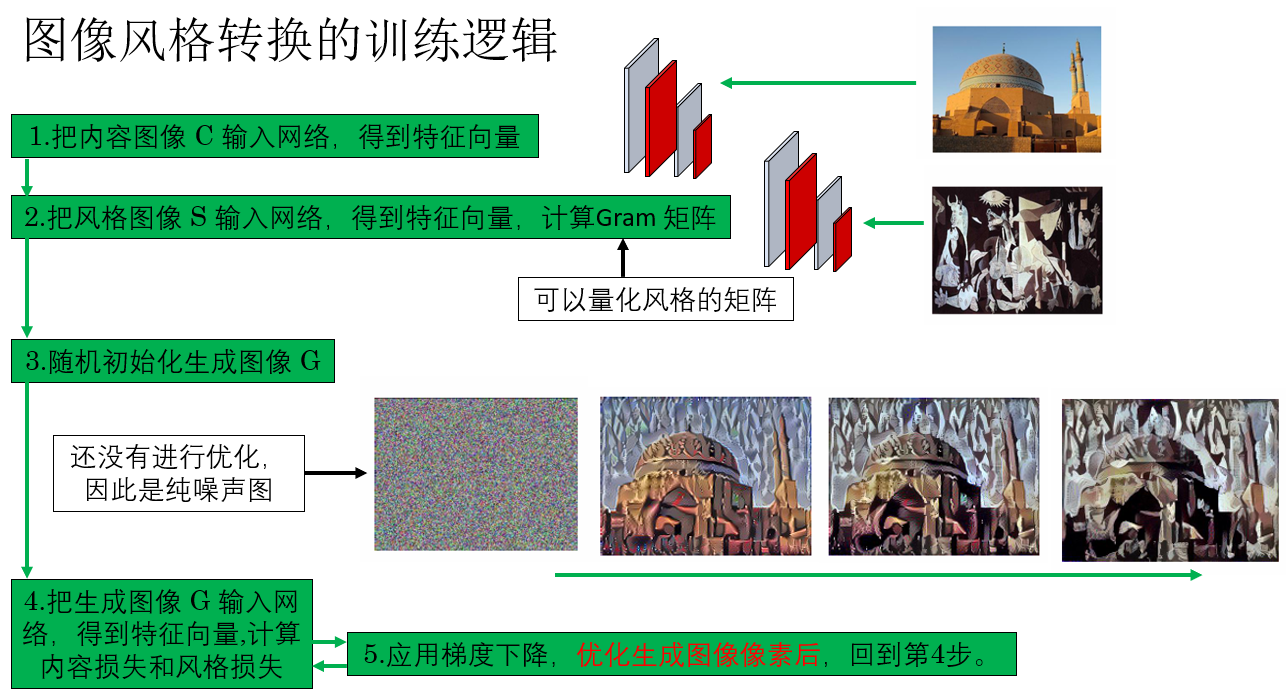
如圖所示,你會發現,在這套訓練邏輯中,網絡只是一個工具,就像一把已經刻好的尺子,只負責提取圖像的內容和風格特徵。
我們將生成圖像輸入網絡,通過前向傳播得到其內容特徵和風格特徵,再與內容圖像和風格圖像的預計算目標特徵比較,得到代價函數。隨後,通過梯度反向傳播,更新生成圖像像素,而網絡參數保持固定。
這樣一來,雖然網絡不訓練,我們仍然可以通過迭代優化生成圖像,使其內容與風格逐步逼近目標。
瞭解了基本的訓練邏輯後,我們再來看看到底如何實現代價函數。
2.2 內容代價函數
我們先來看看較為直觀的內容代價函數:\(\mathcal{J}_{\text{content}}(C,G)\)
顧名思義,這部分代價函數的作用是用來衡量生成圖像和內容圖像之間的差異,顯然,我們希望這部分能最小化來保持圖像內容不變。
如何實現這部分?
我們知道,在卷積神經網絡中,隨着網絡層數的增加,輸出特徵圖的抽象程度逐漸提高:
- 淺層特徵主要捕捉局部紋理和邊緣信息
- 深層特徵則編碼全局語義和高級抽象
我們一般使用深層特徵來進行分類或檢測等任務,但如果直接使用深層特徵來計算內容損失,雖然語義信息豐富,但局部結構可能丟失;如果只用淺層特徵,又容易被細節干擾。
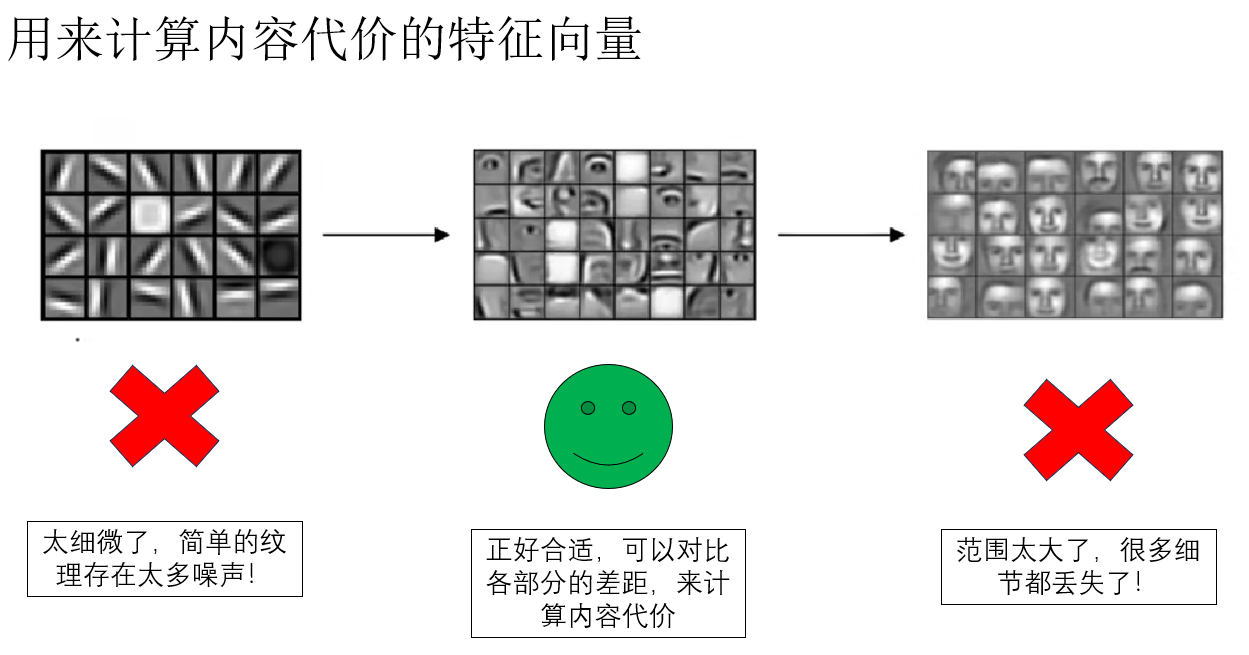
因此,我們通常選擇中間層特徵來計算內容代價,它既能反映圖像的整體結構,又保留足夠的局部信息,正好適合衡量生成圖像與內容圖像之間的差異。
可以形象地理解為:我們不希望只對紋理“計較”,也不希望只看整體概念,而是找到一個中間尺度,既能保留結構,又不過於抽象。
也就是説,我們讓用來計算內容代價的兩組特徵向量的抽象程度維持在一個合適的程度,既不是簡單的紋理,也不是全局語義,就像這樣:
明白了這一點後,我們現在就來看看到底如何計算內容代價:
並不複雜,一句話就可以説明:計算這兩組向量中對應量差的平方和。
公式表示為:
其中,\(l\) 為我們選定的輸出特徵抽象程度合適的層級。
你也可以加入歸一化:
瞭解完計算方式後,我們來看一個實例加深一下印象:
假設我們在某一中間層得到的特徵圖如下:
- 內容圖像 \(C\) 的特徵向量:
- 生成圖像 \(G\) 的對應特徵向量:
代入內容代價公式計算:
可以看到,這個值就表示生成圖像在該層特徵上與內容圖像的差異。優化的目標就是讓這個值儘量減小,從而讓生成圖像儘量保留原有內容結構。
這就是對內容代價的計算,下面我們繼續看代價的另一部分:風格代價。
2.3 風格代價函數
相比內容代價,風格代價顯得就抽象了些。我們把這節分為幾部分,來進行較詳細的介紹。
(1)量化風格
顯然,要計算風格代價的首要問題就在於:我們要如何量化一幅圖像的“風格”?
直覺上,風格並不取決於“畫的是什麼”,而更多體現在顏色搭配、紋理分佈、筆觸規律等整體視覺特徵上,也就是説,**風格是一種“統計特性”,而不是依賴具體空間位置的結構信息。
因此,在計算風格代價時,我們需要一種統計方式:這種方式不關注具體的空間位置信息,而是聚焦於統計不同特徵之間的相關性。
我們展開解釋一下這句話,就像這樣:
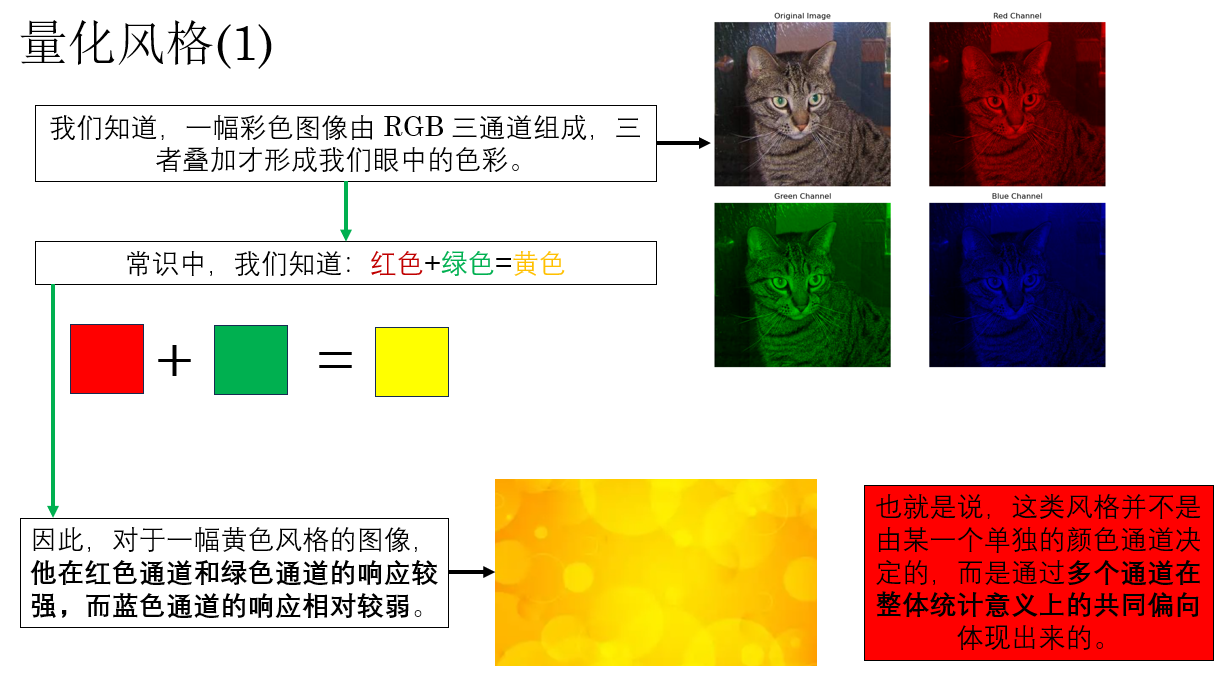
進一步地,我們把這樣一幅彩色圖像輸入卷積網絡,隨着網絡傳播,輸出特徵圖的通道數也不斷增加,這時,每一個通道都可以粗略地理解為網絡從圖像中提取到的一類特徵響應,它們可能對應顏色、紋理、局部形狀或更復雜的視覺模式。
既然如此,不同特徵通道之間自然也會存在某種統計上的關聯關係,例如某些紋理特徵往往與特定顏色分佈同時出現,就像這樣:
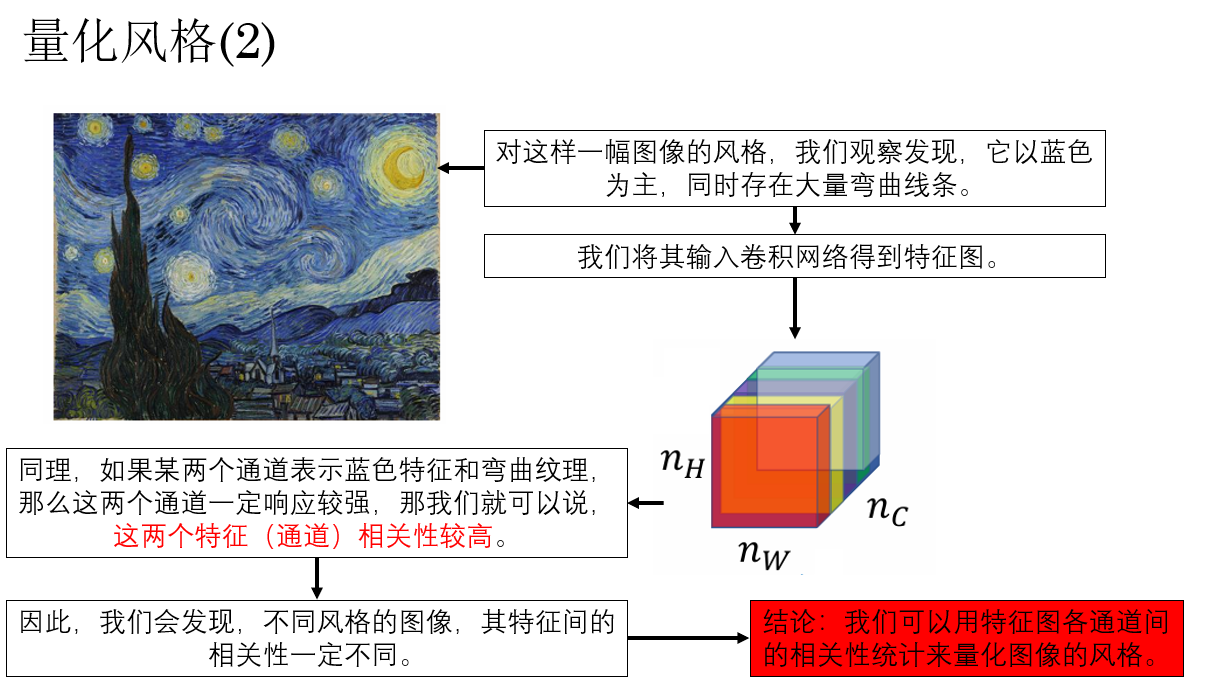
因此,我們可以將一幅圖像的風格,量化為其特徵圖中各通道之間的相關性統計。
而同時,下一個就自然而然的產生:我們怎麼統計各通道的相關性?
(2)Gram 矩陣
在神經風格轉換中,Gatys 等人選擇使用 Gram Matrix(格拉姆矩陣) 來刻畫特徵通道之間的相關性。
先不急着擺公式,我們來看看為什麼 Gram 矩陣是一個合適的選擇:
我們剛剛提到過,如果某兩類特徵在同一幅圖像中經常同時被強烈激活,那麼我們就可以認為它們在統計意義上是“相關的”。
而 Gram 矩陣做的事情正是這一點:它不關心這些特徵在圖像的哪個位置出現,而只關心——
不同特徵通道在整幅圖像中是否傾向於一起出現,以及出現得有多強。
也就是説,Gram 矩陣刻畫的是一種 “特徵與特徵之間的共現關係”。
瞭解了Gram 矩陣的作用後,我們先用人話解釋一下Gram 矩陣的計算過程:對所有通道兩兩組合,計算其相同位置上兩個元素乘積的和,作為 Gram 矩陣中以兩通道索引為座標處的值。
然後,來看公式:
我們採用如下符號約定:
- \(a_{i,j,k}^{[l]}\):表示第 \(l\) 層中,空間位置 \((i,j)\) 處,第 \(k\) 個通道的激活值。
- 特徵圖空間尺寸為 \(n_H^{[l]} \times n_W^{[l]}\),通道數為 \(n_C^{[l]}\)。
在第 \(l\) 層中,輸出特徵圖 的 Gram 矩陣 \(G^{[l]} \in \mathbb{R}^{n_C^{[l]} \times n_C^{[l]}}\) 定義為:
其中:
- \(k, k'\) 表示兩個不同的特徵通道。
- 對所有空間位置 \((i,j)\) 求和,顯式消除了空間位置信息。
在實際計算中,通常會對 Gram 矩陣進行歸一化:
這樣可以避免特徵圖尺寸變化對風格代價產生不必要的影響。
最後,我們發現:Gram 矩陣中的每一個元素 \(G_{k k'}^{[l]}\),刻畫的是第 \(k\) 個特徵與第 \(k'\) 個特徵在整幅圖像中的共現強度,而不是它們出現的位置。
我們補充一個實例:
設第 \(l\) 層共有 \(n_C^{[l]} = 3\) 個通道,每個通道的特徵圖大小為 \(2\times 2\),三個通道的特徵圖分別為:
Gram 矩陣計算公式為:
- 計算對角項(通道自身的相關性)
- 計算非對角項(不同通道之間的相關性)
- 由於 Gram 矩陣是對稱的:
最終 Gram 矩陣即為:
最終,這個 \(3 \times 3\) 的 Gram 矩陣完整地刻畫了三種特徵在整幅圖像中的兩兩共現關係,而完全不包含任何空間位置信息。
到這一步,我們就實現了用一個矩陣來量化一幅圖像的風格。
(3)計算風格代價
在成功實現對圖像風格的量化後,我們便可以計算風格代價:\(\mathcal{J}_{\text{style}}(S,G)\)
它的計算邏輯並不複雜:對生成圖像 G 和風格圖像 S 的Gram 矩陣中對相應位置元素做差並平方,最後求和。
為保證與特徵圖尺寸和通道數無關,我們通常會加入歸一化。
最終,它的公式是這樣的:
再來演示一下:
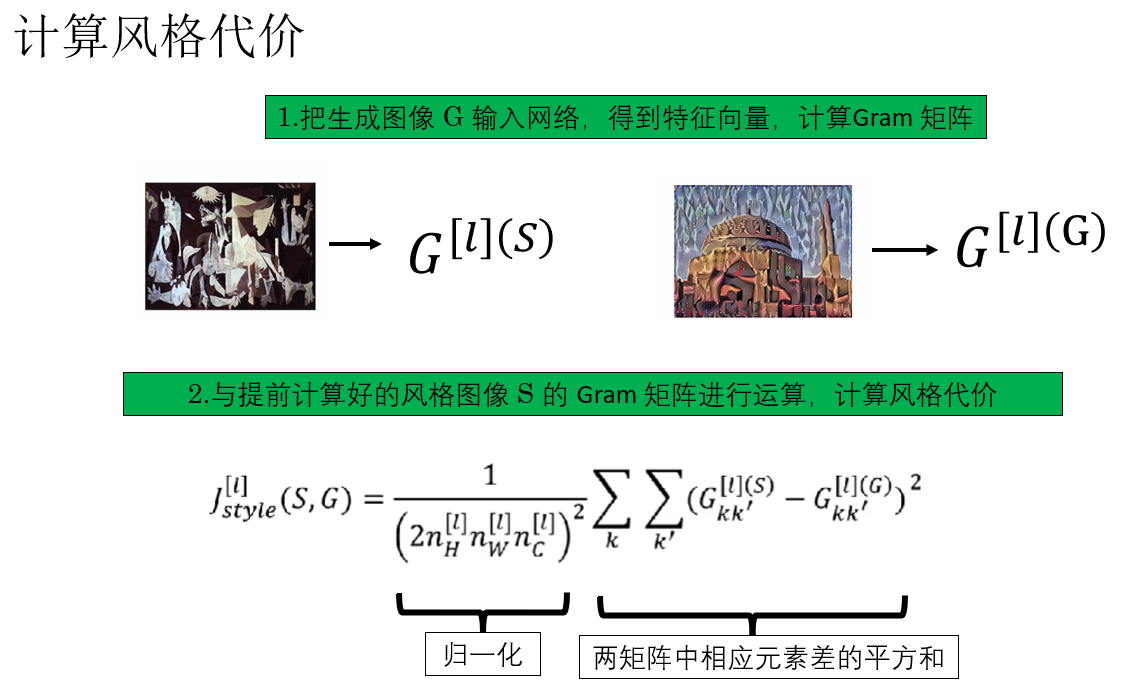
值得注意的是,上述公式嚴格來説只是單層風格代價,因為我們只使用了網絡中某一層輸出的特徵圖。
如果我們把圖像傳播到網絡的多個卷積層,分別計算各層的 Gram 矩陣並得到對應的風格代價,再按權重加權求和,就得到多層風格代價:
- \(\lambda^{[l]}\):第 \(l\) 層風格代價的權重,可根據需要調節。
多層加權的好處是兼顧不同層次的風格特徵:低層更偏向紋理和顏色,高層更偏向整體圖案和結構,從而生成的圖像風格更加自然豐富。
由此,我們便成功定義了可用於圖像風格轉換的代價函數,接下來就可以通過網絡的反向傳播實現風格轉換。
在本週的實踐內容中,我們也會實際演示一下這種應用。
另外,在本週課程最後,吳恩達老師補充了一節對一維卷積和三維卷積的介紹。
簡單來説:一維卷積通常用於處理序列數據,例如時間序列或文本信號,它在序列方向上滑動卷積核,提取局部模式或特徵。
三維卷積則常用於處理視頻或體數據,它在高度、寬度和時間(或深度)三個維度上同時滑動卷積核,從而能夠捕捉空間和時間上的聯合特徵,適合分析動態場景或三維結構信息。
我們就不再多展開這部分內容了,等遇到了它們的具體應用時,我們再詳細介紹它們。
4.總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 圖像風格轉換 | 利用預訓練卷積神經網絡提取圖像內容和風格特徵,通過優化生成圖像使其內容保持不變、風格逼近目標圖像 | 網絡像一把刻好的尺子,生成圖像像橡皮泥,通過不斷調整橡皮泥使其符合尺子刻度 |
| 代價函數(總) | 將內容代價與風格代價加權求和:\(\mathcal{J}_{\text{total}} = \alpha \mathcal{J}_{\text{content}} + \beta \mathcal{J}_{\text{style}}\) | 衡量生成圖像與目標圖像“差距”的指標,越小越匹配 |
| 內容代價函數 | 衡量生成圖像與內容圖像在中間層特徵空間的差異,通常使用平方和計算 | 找到“中間尺度”既保留結構,又不過於抽象,就像兼顧局部紋理與整體概念 |
| 內容特徵選擇 | 使用中間層特徵,既保留全局結構,又不過分關注局部紋理 | 不希望只對紋理計較,也不希望只看整體概念 |
| 風格代價函數 | 利用Gram矩陣刻畫各特徵通道之間的相關性,通過平方差和加權求和計算 | Gram矩陣像統計特徵共現的表格,不關心位置,只關注不同特徵同時出現的強度 |
| Gram矩陣 | 對每對特徵通道,在所有空間位置上求乘積並求和,歸一化後得到 | 特徵通道之間的“共現強度矩陣”,類似觀察特徵是否喜歡一起出現 |
| 單層 vs 多層風格代價 | 單層只考慮某一層特徵,多層將多層風格代價加權求和,更全面捕捉風格 | 低層捕捉紋理與顏色,高層捕捉整體圖案與結構 |
| 一維卷積 | 在序列方向上滑動卷積核,處理序列數據如時間序列或文本 | 像沿着時間軸觀察和提取局部模式 |
| 三維卷積 | 在高、寬、深/時間三個維度上滑動卷積核,處理視頻或體數據 | 像在空間和時間上同時觀察動態或三維結構 |