

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第四課的第四周內容,4.1到4.5的內容。
本週為第四課的第四周內容,這一課所有內容的中心只有一個:計算機視覺。應用在深度學習裏,就是專門用來進行圖學習的模型和技術,是在之前全連接基礎上的“特化”,也是相關專業裏的一個重要研究大類。
這一整節課都存在大量需要反覆理解的內容和機器學習、數學基礎。 因此我會盡可能的補足基礎,用比喻和實例來演示每個部分,從而幫助理解。
第四周的內容是對前三週內容的綜合應用,介紹了一些通過卷積網絡實現的實際應用,它們在使用卷積網絡的基礎上又各有自己的特點來匹配不同的任務要求,是對如何真實應用卷積網絡的良好演示。
本篇的內容關於人臉識別。
1. 人臉驗證與人臉識別
人臉驗證和人臉識別是兩個相似的概念。
而在人臉識別系統中,我們説人臉驗證是人臉識別的一個基本模塊。
現在就來展開一下二者的關係:
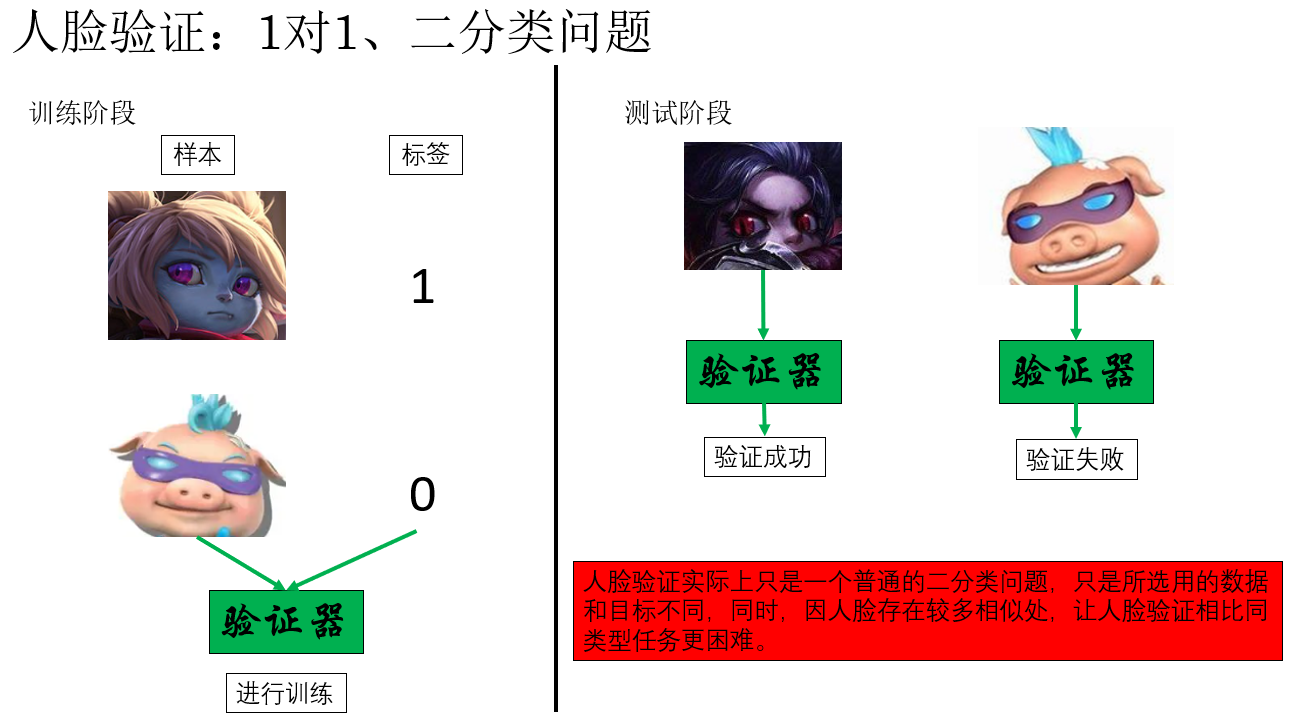
我們在圖裏提到人臉驗證是一個1對1問題,這是因為在假定驗證器完全準確的情況下,它只會對一個人説 “Yes” 而拒絕其他所有人。
很顯然,這種邏輯在我們實際生活中的大多場景都不適用,公司、宿舍的門禁等都支持通過一個模型識別多個人。而不是為每個人單獨設置一個閘機。
因此,我們便稱這種實現“1對多”邏輯的相應任務為人臉識別。
按照剛才的邏輯推下去,一個很自然、也很“機器學習直覺”的想法是:那人臉識別不就是一個多分類問題嗎? 像這樣:
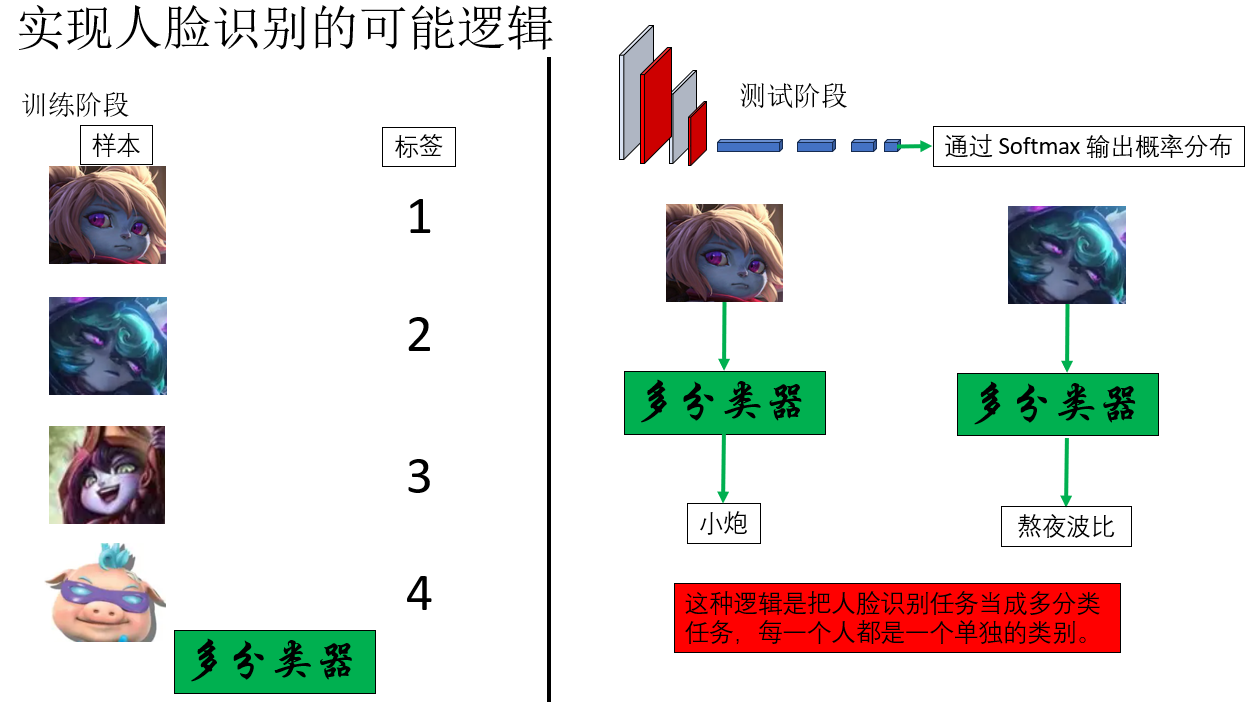
但如果在實際部署中這樣實現人臉識別,你會發現這樣一些問題:
- 如果單位有新員工加入或老員工離職,就要重新調整數據和網絡輸出層,重新訓練。
- 當單位規模較大時,數據可能包含成千上萬個類別。更重要的是,每個類別數據量很少,而深度學習往往又依賴於數據量,難道辦理入職要先拍幾百幾千張照片嗎?
因此,我們得出結論:因為人臉識別任務在實際部署中的特殊性,讓我們之前瞭解的常規分類算法並不適用作為一個可持續部署方案對其應用。
而在現實生活中,你會發現,我們在相關係統錄入人臉時,往往只需要一張證件照即可,這是怎麼做到的呢?我們繼續。
2. 一次學習(one-shot learning)
繼續剛剛的內容,我們會發現一個看似矛盾的現象:
在實際的人臉系統中,錄入一個新用户時,往往只需要一張證件照。但在深度學習的經驗認知裏,模型性能又高度依賴數據量。 這兩點,不衝突嗎?
要理解這一點,我們需要先回到剛才“把人臉識別當作多分類問題”的思路。
在標準的多分類任務中,分類標籤本身就為數據劃分了明確的邊界:模型只能通過同一標籤下的樣本來學習該類別的特徵,而不同類別之間的數據是被嚴格隔離使用的。
正因為如此,如果將人臉識別直接建模為“每個人一個類別”,那麼模型要學好某一個人的特徵,就必然需要大量屬於這個人的樣本——也就出現了“要給每個人拍寫真集”的不現實要求。
但是,你會發現:在人臉識別任務中,總的數據量其實並不少,真正稀缺的只是“每個身份對應的樣本數量”。這意味着,並不是“數據不夠”,而是數據被標籤強行分割後,無法被充分利用。
正是由於這種設置與實際部署場景不匹配,我們自然會產生一個新的疑問:能不能讓所有人的樣本都參與學習,而不是被身份標籤各自隔離開來?
在機器學習中,這類“每個類別只有極少樣本”的問題被稱為一次學習(one-shot learning)問題。
而在具體的人臉識別場景下,one-shot 人臉識別指的是:每個身份在訓練或建庫階段,僅提供一張(或極少幾張)已知人臉樣本。
為了解決這種“總體樣本量很大,但單個身份樣本極少”的矛盾,人們提出了一種不同於傳統分類的思路: 不再讓模型回答“這張臉屬於所有人中的哪一個?”,而是讓它判斷“這張臉是否和某一個已知的某張臉足夠相似?”
現在,網絡目標就從一開始的“學習分類”變成了“學相似度”,就像這樣:
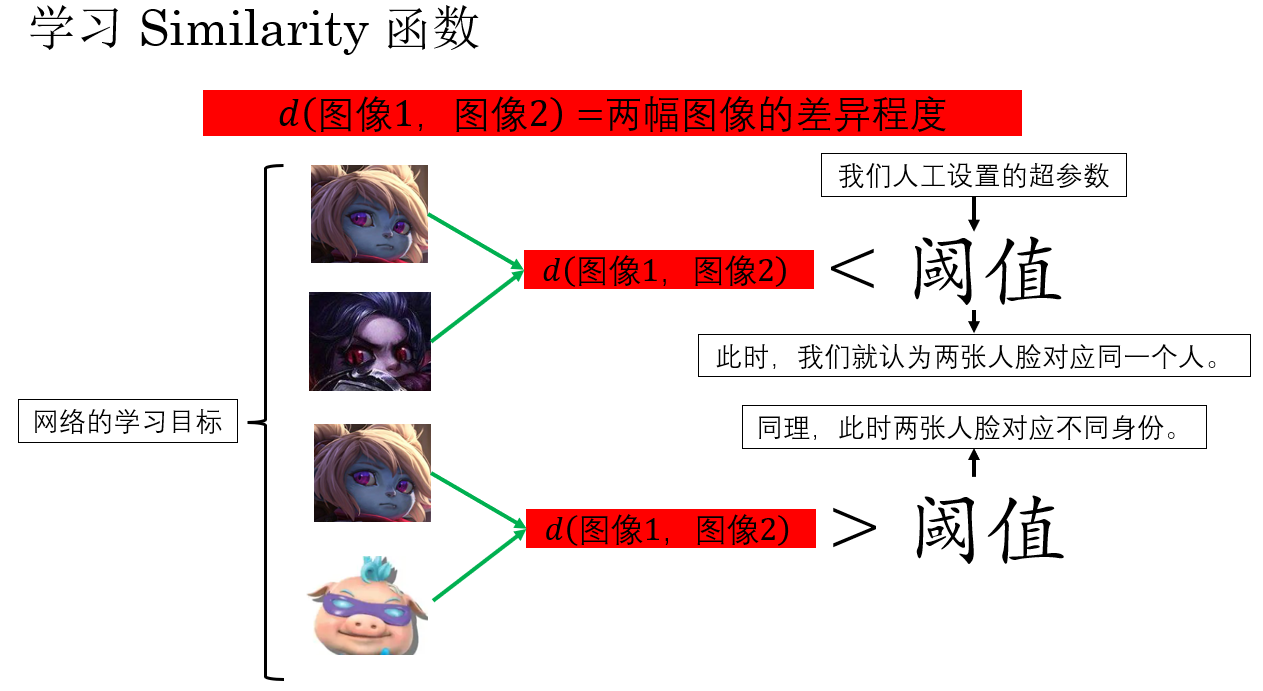
如果如圖中這樣,網絡實現了“學習兩張人臉的相似度“,我們就解決了剛剛的問題:
- 如果單位有新員工加入或老員工離職,就要不再需要調整網絡和重新訓練,只需要把相應數據加入數據庫或從數據庫中刪除。
- 所有的數據都被充分利用,同時每人只需要一張證件照,在門禁時人臉和數據庫中的人臉對比,找到滿足相似度閾值的樣本即通過,不存在即拒絕。
3. Siamese 網絡
現在,我們明確了針對面部識別任務的目標:訓練一個可以學習兩張人臉相似度的網絡。
現在,要怎麼實現這一點呢?
答案就是這部分的標題:Siamese 網絡。
要説明的是,吳恩達老師在課程裏提到了一篇 2014 年的論文 DeepFace: Closing the Gap to Human-Level Performance in Face Verification。但 Siamese 網絡並不是從這篇論文才提出的——早在 1993 年,它就被髮明出來,用於判斷兩幅手寫簽名是否同一人。後來也被應用到人臉識別任務中。
Siamese 網絡的核心思路是通過共享權重的雙分支(或多分支)神經網絡,將輸入的兩張圖像映射到同一特徵空間,然後通過度量函數(如歐氏距離或餘弦相似度)計算它們的相似度。
DeepFace 借鑑了 Siamese 網絡的思路,在深度 CNN 上直接學習人臉特徵的相似度,並通過優化和大規模訓練,這才使得系統性能接近人類水平,真正具備部署價值。
現在,就來詳細看看一個較完善的 Siamese 網絡的運行過程:
3.1 對圖像進行編碼處理:三元組損失(triplet loss)
我們先來看看什麼叫對圖像進行編碼處理:
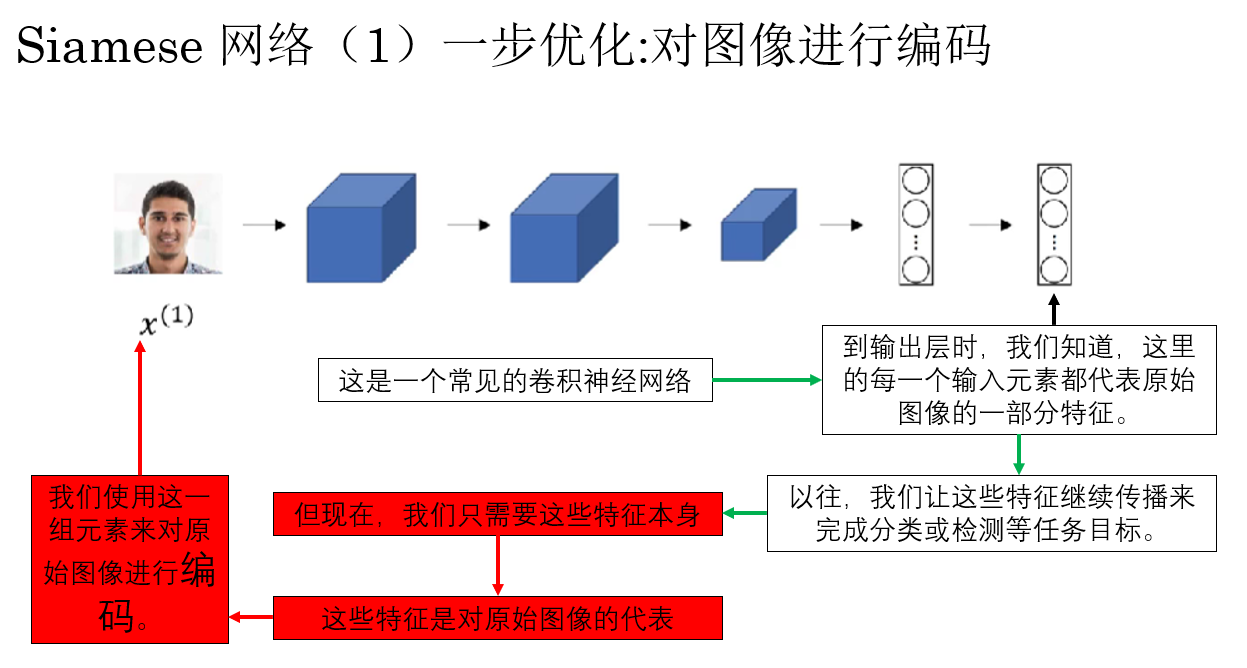
這樣,我們就可以使用一組特徵向量來編碼一張人臉,實際上,這就是 DeepFace 提出的一步優化,這一步設置不止為了計算相似度作準備,同時也極大減少了計算量,縮短了運行時間,可以説相當成功。
但是,同樣也是因為這一步編碼,新的問題出現了:你會發現,這個用來把圖像轉換成編碼的網絡同樣需要訓練。
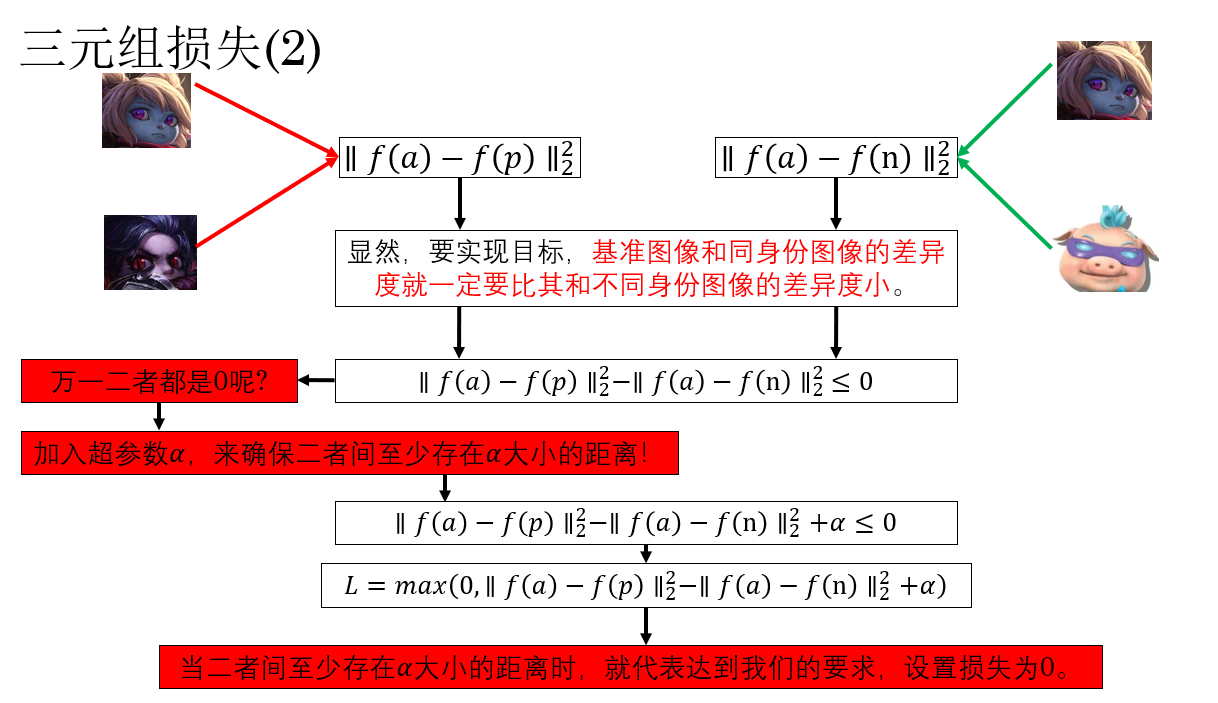
沒錯,我們需要訓練這個網絡,而目標就是:讓同一個身份的人臉編碼差異最小化,不同身份的人臉的編碼差異最大化。
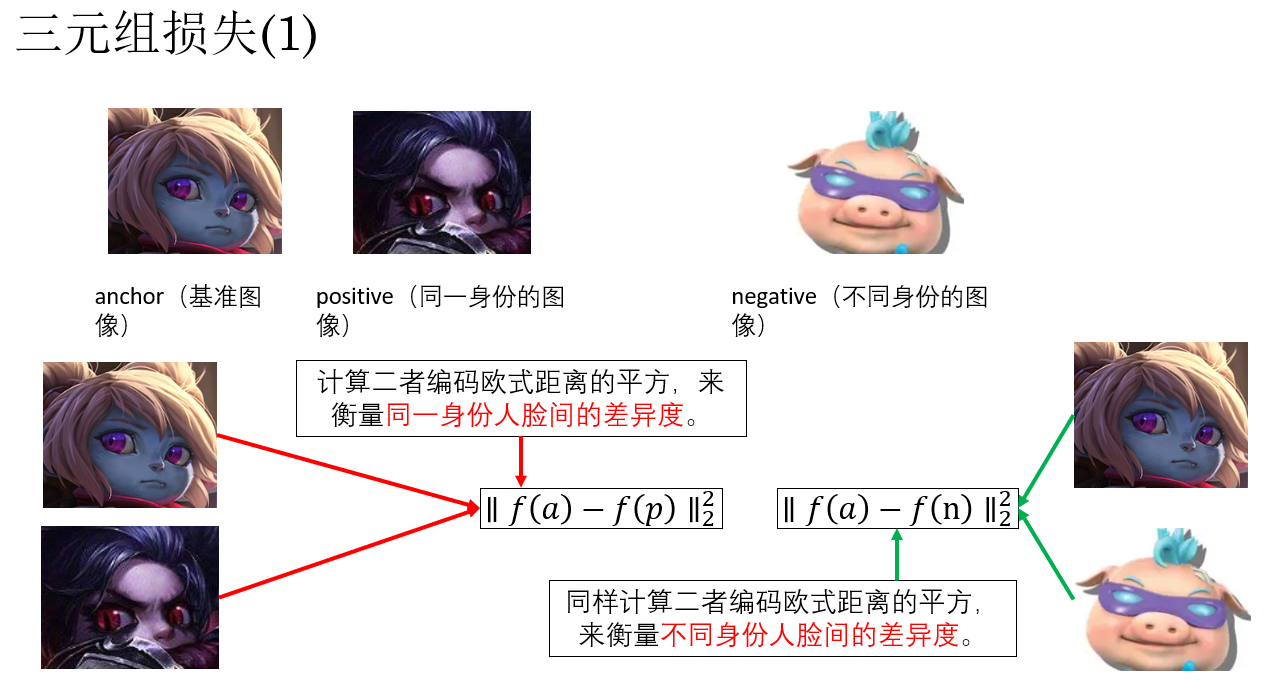
要實現這個目標的常用方法叫做三元組(triplet)損失,這時,網絡在訓練階段需要同時輸入三張圖像。
它的公式長這個樣:
其中:
- \(f(a)\):anchor(基準圖像)映射後的特徵向量
- \(f(p)\):positive(同一身份的圖像)映射後的特徵向量
- \(f(n)\):negative(不同身份的圖像)映射後的特徵向量
- \(\alpha\):間隔(margin),保證不同身份的距離比同一身份距離至少大 \(\alpha\)
別慌,我們用一個例子來演示一遍原理:
只看符號可能有些太繞了,我們再來看一個實例:
假設三張人臉圖像:經過網絡映射後的二維特徵向量如下:
| 圖像 | 特徵向量 |
|---|---|
| a (Alice) | [1.0, 1.0] |
| p (Alice) | [1.2, 1.1] |
| n (Bob) | [2.5, 2.0] |
(1)計算歐氏距離
Anchor 與 Positive(同一人):
Anchor 與 Negative(不同人):
(2)代入三元組損失公式
假設 \(\alpha = 0.5\),代入數值:
代表當前特徵向量滿足目標,同一人距離接近,不同人距離大於 \(\alpha\)。
(3)如果 Negative 太近
假設 \(f(n) = [1.5, 1.3]\),計算距離:
損失為:
便説明不同人距離太近,網絡需要更新,保留損失來進行反向傳播。
通過這種設計,網絡可以直接學習一個適合度量相似度的特徵空間。
最後要強調的一點是,為了讓訓練效果更好,我們在選擇三元組時,會盡量讓基準圖像和同一人的圖像差別儘可能大,同時讓基準圖像和不同人的圖像差別儘可能小。
這就像是在手動提高考試難度,難題會了,簡單題自然不在話下。
現在,我們便繼續下一部分。
3.2 正向傳播兩幅圖像並計算相似度
在擁有了可以對圖像進行合適編碼的網絡後,我們便可以進行相似度計算的應用,這一步的過程是這樣的:
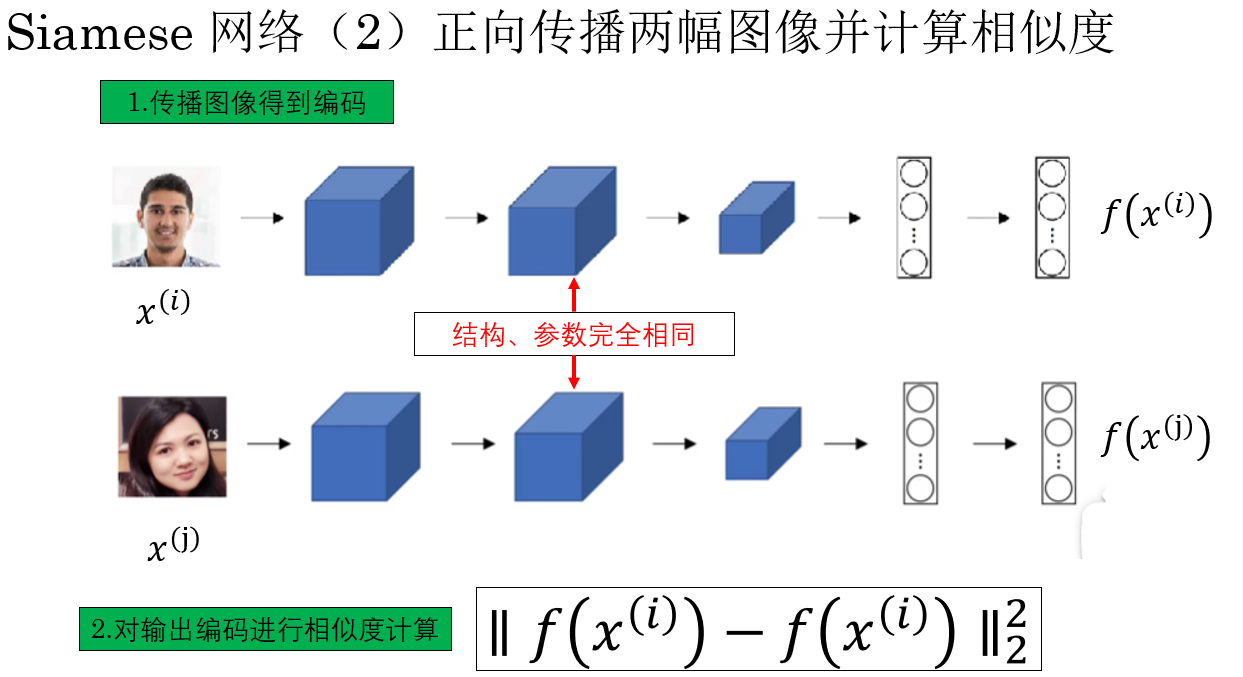
如圖所示,我們通過正向傳播得到兩幅輸入人臉的編碼,並根據編碼計算相似度,自然就可以根據閾值判斷兩張人臉是否屬於同一個人。
而且,這種傳播和計算相似度分離的設計,代表我們可以提前為數據庫中的圖像計算好編碼,只需刷臉時傳入的人臉單獨傳播得到編碼後進行計算就好了,這大大提高了可部署性。
3.3 拓展:另一種訓練編碼網絡的方式
我們剛剛介紹了可以通過三元組損失來訓練編碼網絡,但你可能也發現了,這個方法在數據準備階段較為複雜。
因此,吳恩達老師還介紹了另一種訓練方法:更改標籤,讓Siamese 網絡後接邏輯迴歸變為二分類問題。
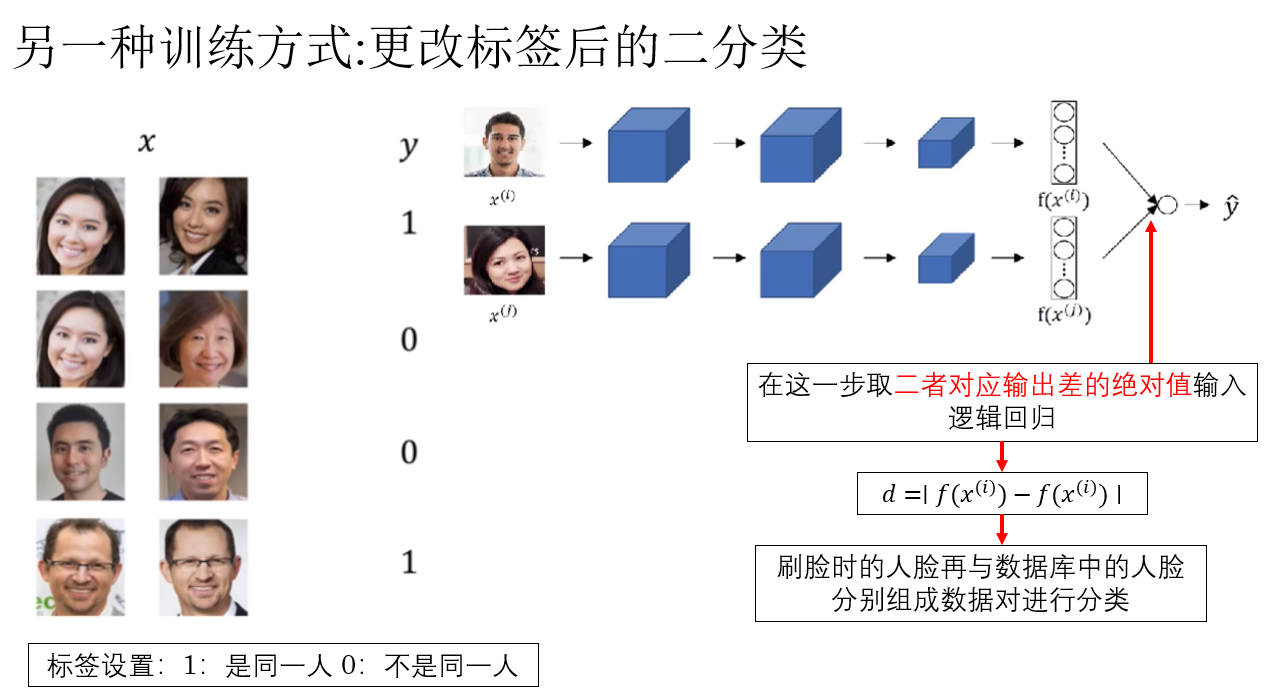
這樣,我們就又把人臉識別問題又轉換回了二分類問題,通過反向傳播來進行訓練。
但是,你會發現,當新員工加入時,還是要重新訓練模型。
因此,實際上這種方式的實際部署價值並不如使用三元組損失。
4.總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 人臉驗證(Face Verification) | 1 對 1 問題,判斷輸入人臉是否與目標身份匹配 | 就像門衞只對某個人説“可以進”,其他人全部拒絕 |
| 人臉識別(Face Recognition) | 1 對多問題,通過模型識別輸入人臉屬於哪一個已知身份 | 門禁系統識別多個員工,不需要單獨為每個人設閘機 |
| 多分類建模問題 | 將每個人作為一個類別進行訓練 | 每個員工都有一本寫真集,要學會區分成千上萬本 |
| 一次學習(One-Shot Learning) | 每個身份僅提供極少樣本,通過相似度判斷識別 | 只需一張證件照就能識別新員工,不用拍寫真集 |
| Siamese 網絡 | 共享權重的雙分支(或多分支)網絡,將圖像映射到同一特徵空間,通過度量函數計算相似度 | 同時看兩張照片,然後比較相似度 |
| 三元組損失(Triplet Loss) | 訓練網絡使同一人距離最小,不同人距離最大,網絡需輸入三張圖像(anchor, positive, negative) | 提高考試難度:基準題和相似題差別小,不同題差別大,訓練更有效 |
| 正向傳播兩圖計算相似度 | 已訓練網絡對兩幅圖像編碼後,計算特徵距離或相似度,用閾值判斷是否同一人 | 先把照片編碼成“身份特徵卡片”,刷臉時只比對卡片 |
| Siamese + 邏輯迴歸二分類 | 將兩張圖像輸入 Siamese 網絡,通過邏輯迴歸判斷是否同一人 | 將人臉識別問題簡化成“是/不是同一人”的選擇題 |
| 部署可行性對比 | 三元組損失支持 one-shot、可提前計算數據庫特徵向量,泛化強;邏輯迴歸方式新身份需重新訓練,泛化差 | 三元組:考試考通用能力;邏輯迴歸:考試只會答已有題目 |