

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第五課的第二週內容,2.2、2.9和2.10內容,同時也是本週理論部分的最後一篇。
本週為第五課的第二週內容,與 CV 相對應的,這一課所有內容的中心只有一個:自然語言處理(Natural Language Processing,NLP)。
應用在深度學習裏,它是專門用來進行文本與序列信息建模的模型和技術,本質上是在全連接網絡與統計語言模型基礎上的一次“結構化特化”,也是人工智能中最貼近人類思維表達方式的重要研究方向之一。
這一整節課同樣涉及大量需要反覆消化的內容,橫跨機器學習、概率統計、線性代數以及語言學直覺。
語言不像圖像那樣“直觀可見”,更多是抽象符號與上下文關係的組合,因此理解門檻反而更高。
因此,我同樣會儘量補足必要的背景知識,儘可能用比喻和實例降低理解難度。
本週的內容關於詞嵌入,是一種相對於獨熱編碼,更能保留語義信息的文本編碼方式。通過詞嵌入,模型不再只是“記住”詞本身,而是能夠基於語義關係進行泛化,在一定程度上實現類似“舉一反三”的效果。詞嵌入是 NLP 領域中最重要的基礎技術之一。
本篇的內容關於情緒分類和詞嵌入除偏,是對本週內容的最後補充。
1. 詞向量的使用
在介紹完前面的內容後,你會發現,我們使用各種模型和技術,最終的目的都是為了得到可以合理刻畫文本信息間語義關係的詞向量。
而一旦這些詞向量被訓練出來,它們的價值並不會隨着訓練任務的結束而消失,反而真正的用武之地才剛剛開始。
實際上,在詞向量的使用中,最常見、也是最直接的方式,就是將訓練好的詞向量作為下游任務的輸入表示。
在文本分類、情緒分析、問答系統等任務中,我們不再使用獨熱編碼這種“只區分身份、不包含語義”的表示方式,而是通過查表的方式,將每個詞映射為一個稠密的詞向量,再送入分類器或序列模型中進行處理。
也正是這種連續、可度量的語義空間,使得模型在還沒有接觸具體任務之前,就已經擁有了一定程度的語言理解能力。
而且,你會發現這其實是一種非常典型的遷移學習思想:
詞向量模型在大規模語料上學習到的是一種通用的語言結構與語義分佈,而下游任務只需要在此基礎上進行少量參數調整,就可以完成更具體的目標。
更重要的是, NLP 中對詞向量的遷移學習和我們之前介紹的 CV 內容有所不同,在 CV 任務中,遷移效果往往高度依賴於任務之間的相似性,例如用自然圖片上訓練得到的模型參數去處理醫學影像,效果未必理想。
而在 NLP 領域中,由於語言本身具有極強的通用性,只要任務使用的是同一語言,將預訓練詞向量作為嵌入層矩陣的初始化方式,往往是一種“用了就不虧”的選擇。
最終,從模型結構上看,這相當於模型的第一層不再從完全隨機的參數開始學習,而是直接站在了一個已經組織好語義結構的空間中,再去完成具體任務。
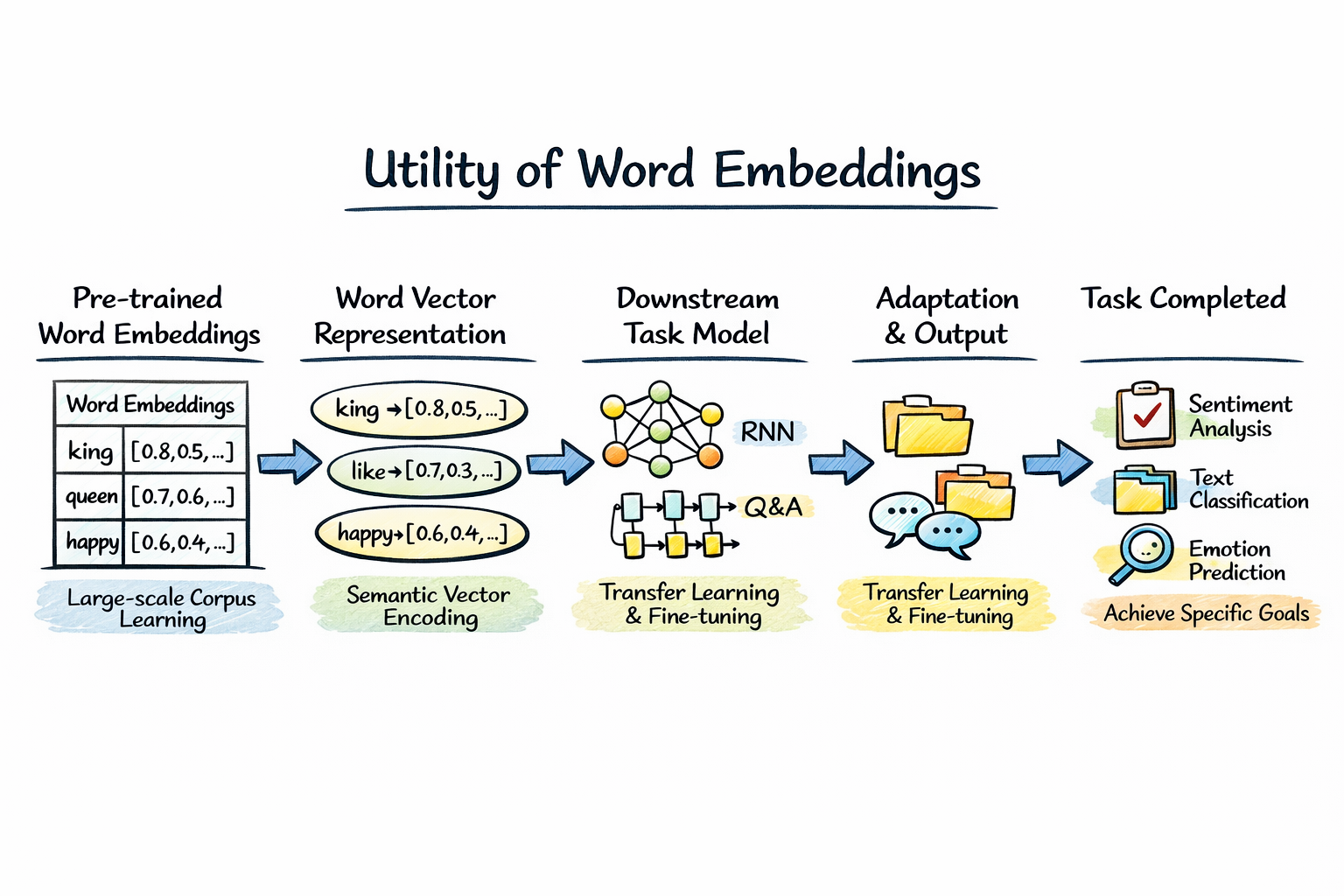
也正是在這樣的背景下,NLP 的各種應用百花齊放,其中最經典的應用之一,就是下面要介紹的情緒分類。
2. 情緒分類(Sentiment Classification)
2.1 情緒分類原理
情緒分類是自然語言處理領域中最早被系統研究、同時也最具代表性的任務之一。
其基本形式並不複雜:給定一段文本,判斷其情緒傾向,例如正面、負面,或更細粒度的多類別情緒。
簡單舉個例子:
對於兩條酒店評論 “拉完了” 和 “夯爆了”,我們可以在不同的情緒粒度下,對它們給出不同形式的分類結果。
- 正負二分類:在最粗粒度的情緒分類任務中,我們只關心文本所表達的整體態度是正面還是負面。
- “拉完了” → 負面情緒
- “夯爆了” → 正面情緒
在這一設定下,模型的目標非常明確:只需判斷“喜歡”還是“不喜歡”,而不關心情緒強度或細節差異。
2. 星級五分類:如果進一步提高情緒刻畫的精細程度,就可以將任務擴展為多類別分類,例如常見的 1~5 星評分預測。
- “拉完了” → ★☆☆☆☆
- “夯爆了” → ★★★★★
在這一情況下,模型不僅需要識別情緒的正負,還需要理解情緒的強烈程度,相比二分類任務,五分類對語義表示的要求明顯更高。

可以看出,情緒分類任務的核心難點並不在於模型結構本身,而在於如何讓模型“理解”文本所藴含的情緒語義。
而這恰恰正是詞向量發揮作用的地方:只有當“拉完了”“夯爆了”這樣的詞語在向量空間中被映射到合理的位置,後續的分類模型才有可能做出穩定、可靠的判斷。
而在句子中,情緒本身並不是由單個詞獨立決定的,而是由多個詞在語義空間中的組合關係共同構成。
同樣舉例來説明,比如:
- “好” 和 “棒” 在語義空間中彼此接近。
- “糟糕” 和 “失望” 會聚集在另一片區域。
因此,當文本被表示為一組詞向量後,模型實際上是在判斷:這些向量整體更靠近“正面情緒區域”,還是“負面情緒區域”。
這也是為什麼,在情緒分類任務中,詞向量的質量往往直接決定了模型的上限。
瞭解了基本原理後,我們來看看如何實現情緒分類。
2.2 情緒分類 1.0 :平均詞向量輸入分類器
在最早期、也是最樸素的情緒分類實現中,我們並不會引入複雜的序列模型,而是採用一種幾乎不關心詞序的做法:將一句話中所有詞的詞向量取平均,作為整句文本的表示。
具體來説,假設一句話由 \(n\) 個詞組成,其對應的詞向量分別為 :\(\mathbf{w}_1, \mathbf{w}_2, \dots, \mathbf{w}_n\),那麼句向量可以直接定義為:
這個 \(\mathbf{s}\) 就被視為整段文本在語義空間中的“位置”,隨後只需要將它送入一個簡單的分類器(如全連接層 + softmax),即可完成情緒預測。
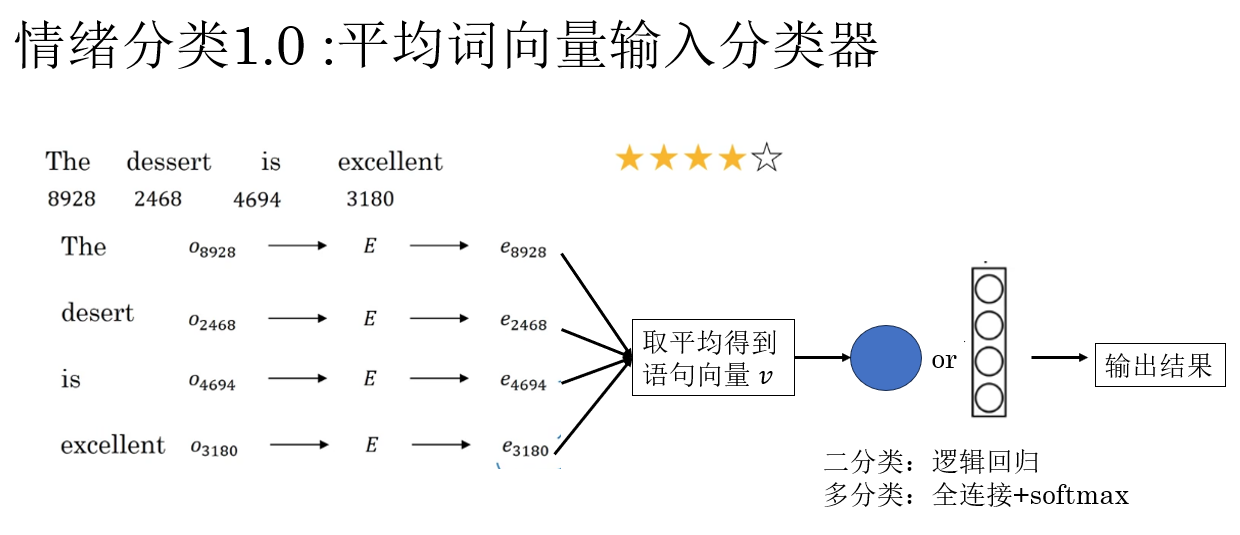
這種方法理解起來很直觀:這句話裏,所有詞語的“情緒方向”加起來,更偏向哪一邊?
如果一句話中大多數詞的向量都靠近“正面情緒區域”,那麼平均後的結果自然也會偏向正面;反之亦然。
它的優點是實現簡單,計算開銷極低;不依賴複雜模型,對小數據集也較為友好,而且通過這種簡單的方式也可以直觀體現詞向量質量對下游任務的影響。
但它的缺點非常突出,我們常説:語言是有順序的,這種方法完全忽略了詞序信息,只看孤立的語義方向的堆疊,便極有可能產生相應的誤解。
例如:“缺少好的服務,好的環境和好的餐食。”
這句話很明顯是負面評價,分類器卻可能因為出現了很多“好”而將其判斷為正面評價。
因此,平均詞向量 + 分類器 只是情緒分類任務的入門解法,我們知道有這種方式即可。
2.3 情緒分類 2.0 :使用循環神經網絡
與直接取平均不同,RNN 會按順序逐詞讀取文本,並在每一步將當前詞的信息與歷史上下文進行融合。
而回顧之前介紹的語言模型內容就會發現,不同於我們之前演示使用的命名實體識別,情緒分類是在讀取完整句信息後輸出一個分類結果,它是一個多對一模型,這類模型反而更符合我們的直覺,來看它的傳播過程:
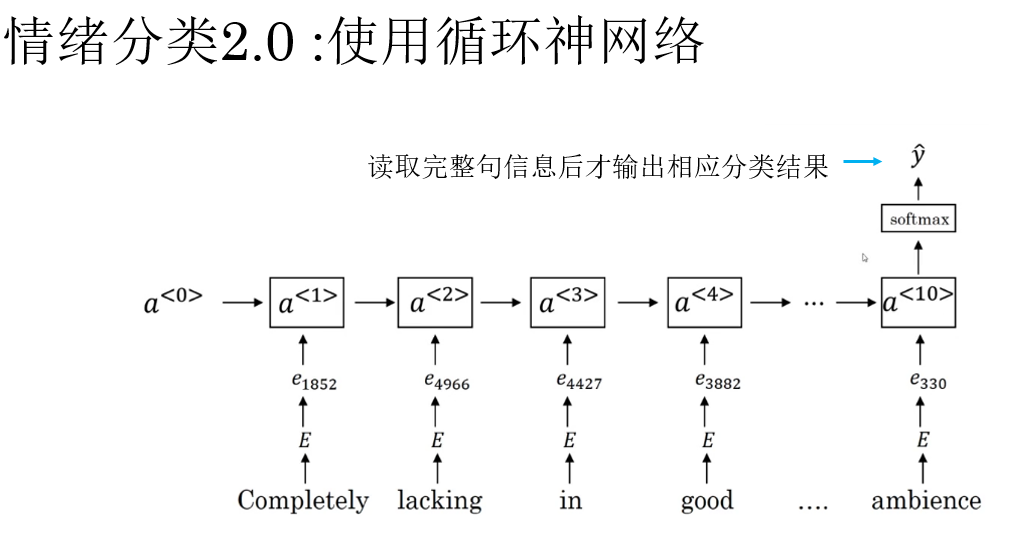
對於一個詞序列 \(w_1, w_2, \dots, w_n\),RNN 的核心計算可以抽象為:
其中,\(\mathbf{a}_t\) 表示模型在讀到第 \(t\) 個詞時,對“當前語義狀態”的綜合理解。
我們使用最後一個隱藏狀態 \(\mathbf{a}_n\) 作為整句文本的表示,再將得到的句向量輸入分類器進行預測,得到最終的分類結果。
這種方式帶來的最大改變在於:情緒不再是詞向量的簡單疊加,而是一個隨閲讀過程逐步演化的結果。
舉例來説:
- 在讀到“好”的時候,模型的情緒傾向可能偏正。
- 但當隨後讀到“不”時,隱藏狀態會被重新調整。
- 最終輸出的表示能夠體現“否定”對整體情緒的修正。
因此,RNN 在對語義的理解能力上明顯優於簡單的平均向量方法。當然,這也帶來了梯度問題和訓練成本的提升。
情緒分類的相關技術同樣在不斷進步,如今,以 BERT 為代表的雙向 Transformer 通過大規模語料預訓練,能夠捕獲更精細的上下文語義關係,在情緒分類等判別任務上顯著超越傳統模型,而更前沿的做法是直接利用指令微調的大語言模型,通過 prompt 或少量樣本即可完成情緒判斷。
情緒分類正逐步從“專用模型任務”內化為“通用語言理解能力”的自然體現。
下面,我們補充最後一部分內容:
3. 詞嵌入除偏(Word Embedding Debiasing)
我們知道,詞向量並不是從真空中學到的,它們來源於真實語料。而真實語料,本身就不可避免地攜帶着各種社會偏見和統計偏向。
由於詞向量的訓練目標是捕捉詞與詞的共現關係,如果某些刻板印象在語料中頻繁出現,那麼它們就會被“如實地”編碼進向量空間中。
例如,在大量文本中,如果:
- “醫生” 、“工程師”更頻繁地與男性詞彙共現。
- “護士” 、“保姆”更頻繁地與女性詞彙共現。
那麼訓練出來的詞向量空間中,就可能形成一條明顯的“性別方向”,並在無意中強化這些關聯。
從模型角度看,這種行為是完全合理的統計學習結果,但從應用角度看,這種偏見在情緒分析、招聘篩選、推薦系統等場景中,可能帶來嚴重問題。
這便是詞嵌入除偏的目標:在儘量保留語義信息的前提下,削弱或移除特定維度上的偏見成分。
2016 年, 論文 Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings 中,首次對詞嵌入中的社會偏見進行了清晰的建模,並提出了一套可操作的除偏方法。它的主要觀點是:偏見並不是“到處都是”的,而是主要集中在某些可解釋的方向上。
我們分點來看看這一方法的實現邏輯:
3.1 定義偏見方向(Bias Direction)
論文的第一步,是顯式地定義什麼是“偏見方向”。
以性別偏見為例,我們並不憑主觀判斷去找偏見,而是構造一組成對的性別詞,例如:
- (he, she)
- (man, woman)
- (king, queen)
對於每一組詞對,都可以在詞向量空間中計算其差向量。將這些差向量進行平均,便可得到一個代表“性別差異”的方向向量,就像這樣:
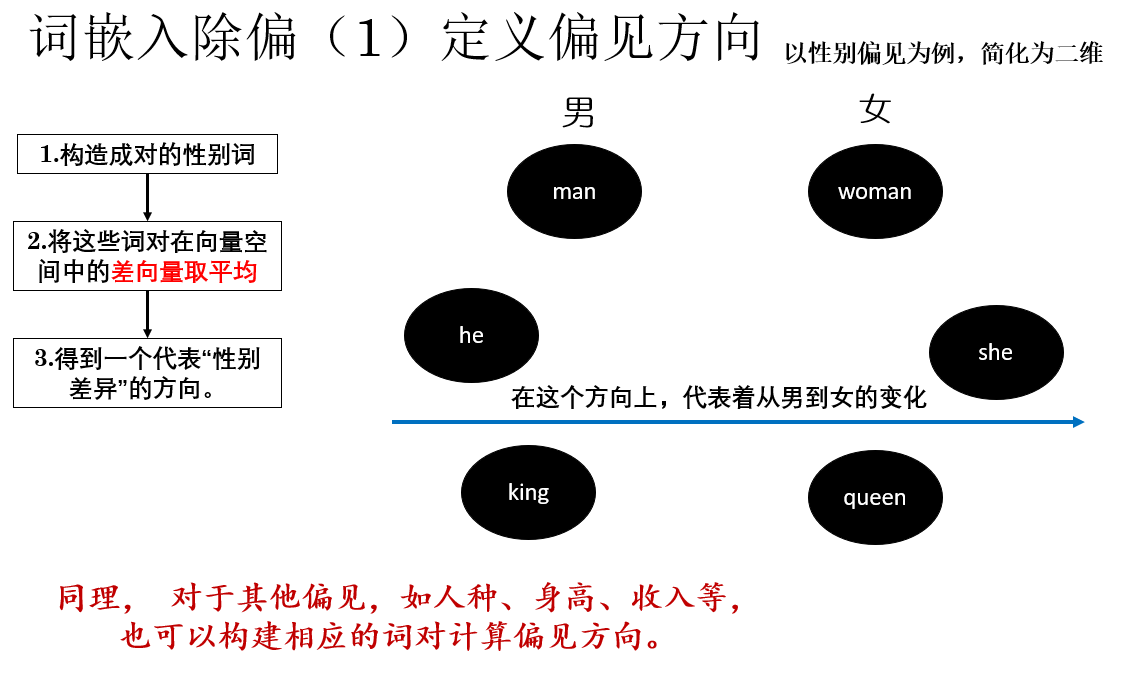
假定詞向量擬合度較高,那麼對於這個方向就可以理解為:沿着這條方向移動,語義主要在“男性 ↔ 女性”之間變化,而與其他語義因素關係不大。
這一步的意義在於將原本模糊、抽象的“偏見”問題,轉化為向量空間中一個可操作的幾何方向。,就像射擊前需要先確定靶心一樣,只有明確了偏見方向,後續才能有針對性地削弱或移除某些詞在該方向上所攜帶的偏見成分。
3.2 區分中性詞與性別詞
同樣以性別偏見為例:接下來,我們將詞彙分為兩類:
- 性別中性詞:如 doctor, nurse, homeworker,它們不應天然帶有性別信息。
- 性別特定詞:如 man, woman, she, he,要保留合理的性別信息。
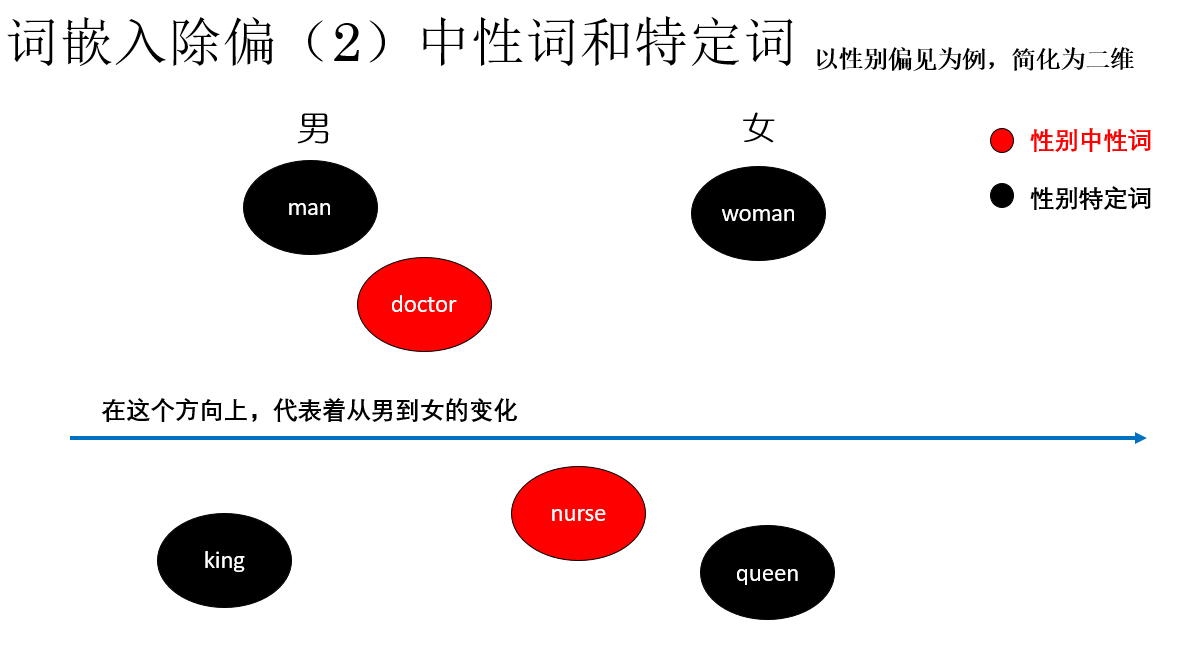
注意,這樣區分並不代表我們不對特定詞進行處理,而是對不同類型的詞采取不同策略:
- 對語義上應當與性別無關的中性詞,應移除其性別方向上偏見。
- 對本身就包含性別差異的詞對,則在保留性別信息的前提下,強制其在性別維度上對稱、在其他語義維度上對齊,從而避免偏見被不合理地放大。
下面就來看看如何實現這些策略:
3.3 硬除偏(Hard Debias)
其實並不難理解,首先,我們處理中心詞,這一步我們稱之為去投影(Neutralize):將中性詞向量在性別方向上的分量直接移除,使其在該方向上的投影為 0。
就像這樣:
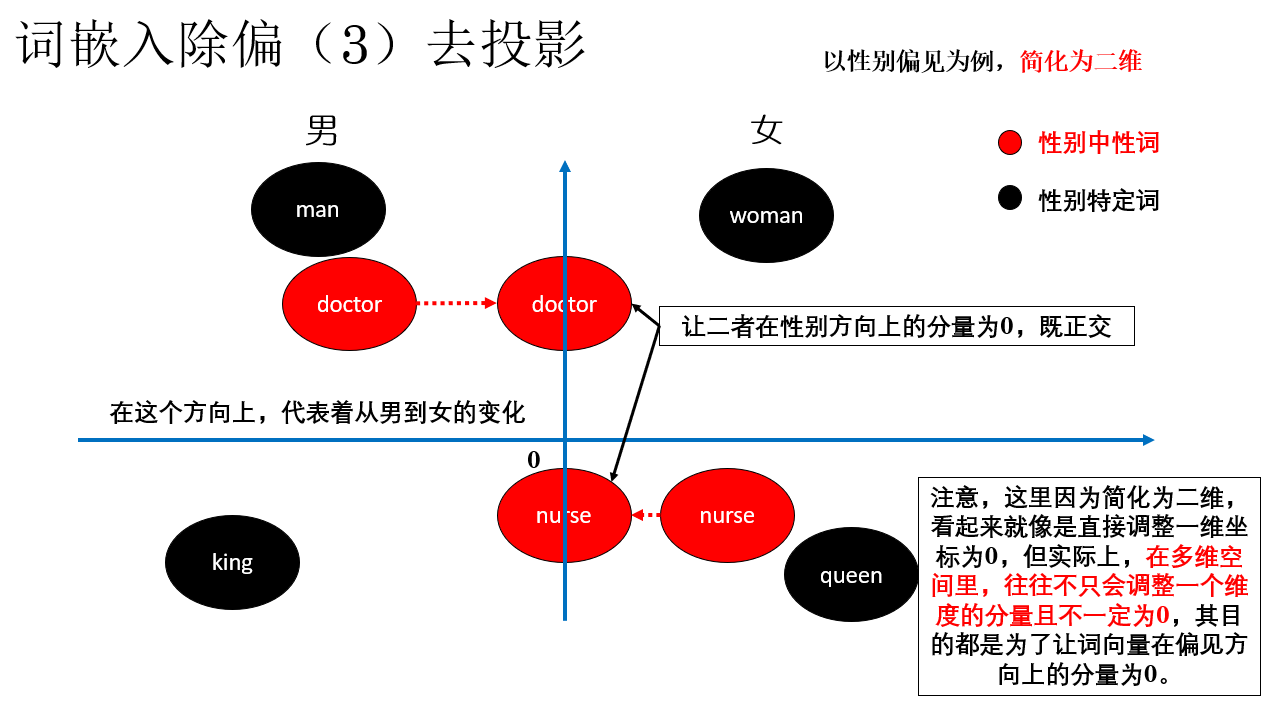
通過這樣調整詞向量,讓中性詞在性別方向上的分量消失,自然就不會因為這個方向上的語義差異而產生偏見。
繼續,我們處理特定詞,而這部分我們稱為等距化(Equalize):對於這類本應只在性別上不同的詞對,強制它們在性別方向上的距離對稱,而在其他語義維度上保持一致。
就像這樣:
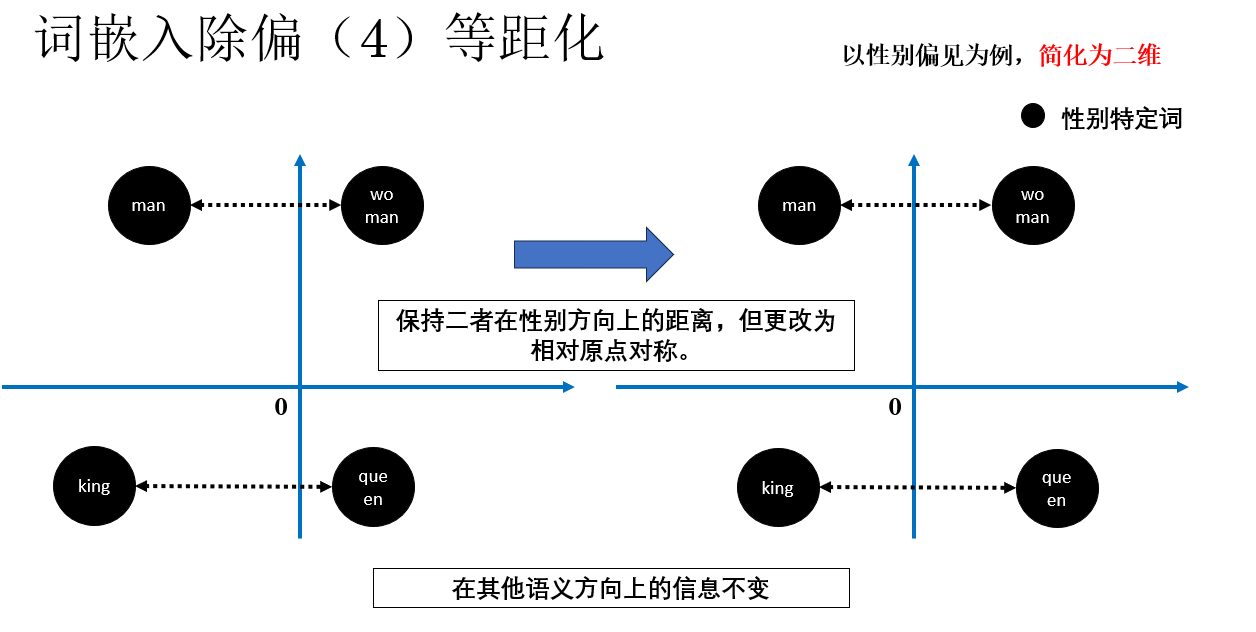
這樣做的道理很直觀:對於“男”和“女”,在語義空間裏,我們不希望出現“男只有一點點男性特徵,而女則非常女性化”的不對稱情況。
如果特定詞在性別方向上不對稱,不僅會模糊性別邊界,還可能降低詞向量的整體質量。
通過等距化,特定詞對在“性別以外”的語義上保持等價,但在性別方向上依然可以清晰區分,從而既消除偏見,又保留必要的性別信息。
此外,既然有硬除偏,自然也有軟除偏,在明白了硬除偏後,軟除偏便不難理解:
簡單來講,軟除偏只針對中性詞,其處理邏輯和硬除偏也大體相同,不同的是軟除偏將每類偏見中“讓中性詞在偏見方向上的分量最小化”的邏輯加入神經網絡損失函數中作為一項進行迭代優化。
這種方法更符合我們在深度學習領域的直覺,實際上在現代技術中也有繼承軟除偏思想、更先進的詞嵌入除偏方法,這裏就不再專門展開了。
4. 總結
| 概念 | 原理 | 理解 |
|---|---|---|
| 詞向量使用 | 將訓練好的詞向量作為下游任務輸入,捕捉語義關係,支持遷移學習。 | 模型第一層不再從零開始,而是“站在已整理好的語義空間上”。 |
| 情緒分類(Sentiment Classification) | 給定文本判斷情緒傾向,可二分類(正/負)或多分類(如 1~5 星)。 | 文本中的詞語向量整體靠近“正面區域”還是“負面區域”。 |
| 平均詞向量 + 分類器 | 將句子中所有詞向量取平均作為整句表示,再送入分類器。 | 詞語的“情緒方向”堆疊,哪邊多就偏向哪邊。 |
| RNN 情緒分類 | 按順序逐詞讀取文本,將當前詞與歷史上下文融合,輸出最後隱藏狀態作為句向量。 | 情緒隨着閲讀過程逐步演化,如“好” → 正面,但遇到“不”被修正。 |
| 詞嵌入偏見問題 | 詞向量從真實語料中學習共現關係,容易捕捉社會偏見(如性別刻板印象)。 | 統計規律“如實反映”,但可能強化偏見。 |
| 偏見方向(Bias Direction) | 構造成對詞(he/she, man/woman),計算差向量並平均得到偏見方向。 | 在向量空間中,沿此方向語義主要在“男性 ↔ 女性”之間變化。 |
| 區分中性詞與特定詞 | 中性詞移除偏見方向成分;特定詞保持性別信息並等距化。 | 中性詞去除偏見就像去掉不必要的色彩,特定詞對保持對稱,就像男女形象保持平衡。 |
| 硬除偏(Hard Debias) | 對中性詞去投影使性別方向為 0,對特定詞做等距化保持對稱。 | 用“刀子”切掉中性詞性別成分,同時調整特定詞對保持對稱。 |
| 軟除偏(Soft Debias) | 只針對中性詞,將“最小化偏見方向分量”的目標加入損失函數,通過迭代優化實現減弱偏見。 | 温和壓低偏見方向,而不是完全切掉,保留語義空間結構。 |