

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第三課的第二週內容,2.7的內容。
本週為第三課的第二週內容,本週的內容關於在上週的基礎上繼續展開,並拓展介紹了幾種“學習方法”,可以簡單分為誤差分析和學習方法兩大部分。
其中,對於後者的的理解可能存在一些難度。同樣,我會更多地補充基礎知識和實例來幫助理解。
本篇的內容關於遷移學習,這是一個在現在仍廣泛使用的技術方法。
1. 遷移學習出現的背景
遷移學習出現的根本原因還是我們在DL領域裏老生常談的問題:數據不足。
在真實場景中,大規模、高質量的數據往往非常難獲取。
例如:
- ImageNet(這是一個非常著名的超大規模數據集) 裏有上千萬張標註清晰的貓狗、汽車、物體照片。
- 但某些新的任務,例如 “識別工業零件缺陷”,往往只有幾百張甚至幾十張數據。
我們之前已經提到過,在數據不足的情況下,我們有一種比較“取巧”的處理方式:數據增強
它通過擴展現有數據集來增加數據,但是我們也在前面的數據不匹配部分提到過,在數據量本就不多的情況下再進行數據擴展有很大的過擬合風險。
在這種情況下,便有人提出了另一種思路:很多任務的低層次特徵都是差不多的,你的數據少,但是它的數據多,我們能不能把它的模型的前幾層直接拿來用?
我們用兩個例子來詳細展開這句話從而幫助理解:
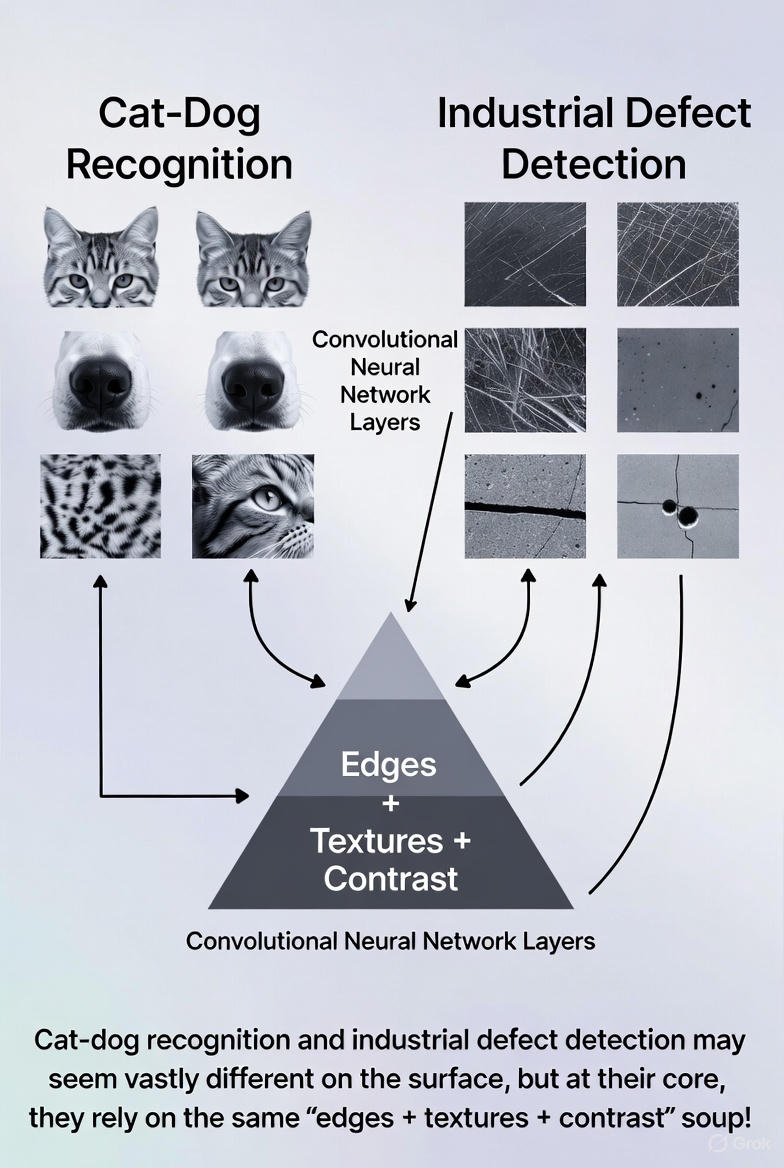
(1)貓狗識別和工業缺陷檢測
這兩個任務好像八竿子搭不到邊,但在圖像學習的邏輯裏,它們雖然一個識別動物,一個識別零件瑕疵,但其實都依賴基礎特徵:
- 輪廓線
- 邊緣變化
- 明暗對比
- 表面紋理
這些低層特徵我們人很難系統地總結, 但機器卻擅長通過像素捕捉這些特徵,網絡的前幾層學到的正是這些通用特徵。
所以,在ImageNet上學過貓和狗的模型,也能對“金屬表面凹坑”這種完全不同的任務產生幫助。
(嘗試了一下使用grok來生成配圖,相比GPT確實在這種邏輯上更擅長一些,但是中文顯示很拉跨。)
(2)人臉識別和手寫數字識別
繼續來看這個任務,經過上面例子的解釋,你可能已經感覺二者的聯繫了。
任務完全不同,但兩者都需要:
- 邊緣檢測(數字的筆畫、眉毛輪廓)
- 局部形狀(眼睛形狀、數字弧度)
- 小範圍的紋理變化
所以它們實際上也有可以公用的地方。
因此,不同任務的高層語義不一樣,但低層視覺特徵卻高度通用,因此可以直接遷移。 這正是遷移學習的根基。
現在,我們就來具體看看遷移學習本身。
2. 什麼是遷移學習?
理解遷移學習的關鍵,是把它視為一種“借力”的思維方式。
如果你從零開始訓練一個模型,那麼模型需要依靠你的數據,從最底層的邊緣、線條開始學習,一直到最後的任務語義。
但就像上面的背景裏説的,在數據量不足的任務中,這種“從零開始”幾乎是不可能成功的。
所以,遷移學習的核心思想非常樸素:
既然別人已經在大型數據集上訓練出一個很強的模型,那我能不能直接借用它已經學好的部分,讓我的小任務站在它的肩膀上?
在這種思想下,使用遷移學習在實際應用中有一個更常見的説法叫做:使用預訓練模型。
典型的遷移學習可以分為兩種,你可以理解為“借多少”——借得少一點?還是借得多一點?
下面分別來看。
2.1 固定前幾層,只訓練最後幾層(也叫 freeze 遷移)
這種方式的思路就像“借一本已經做滿筆記的教材,只在你需要的章節上補充內容”。
具體做法是:
- 取一個在大規模數據集(例如 ImageNet)上已經訓練好的模型
- 保留它的前幾層(這些層已經學會了邊緣、紋理、局部形狀等通用特徵)
- 將最後幾層替換成你自己任務的分類器或輸出模塊
- 只訓練最後幾層即可
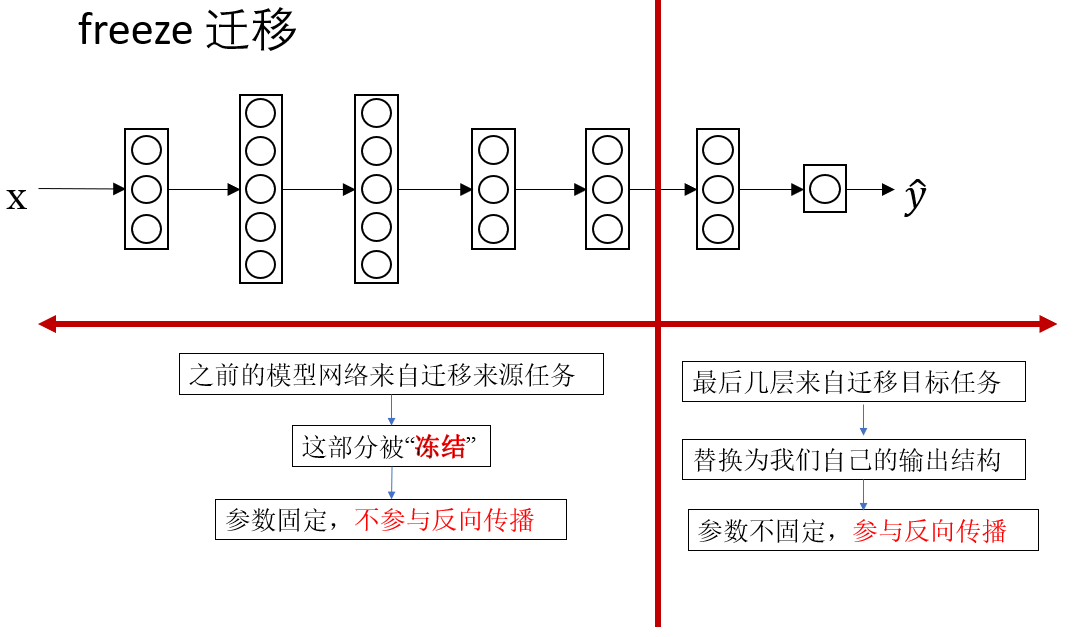
在數據量很少的情境裏,這往往是最穩妥、最有效的方式。原因在於,你並不需要模型重新學習那些基礎視覺技能。
例如:
- 圖像中“這是一條邊”
- “這是簡單紋理變化”
- “這是一個局部形狀的突變”
這些基礎知識早已被預訓練模型學得非常紮實。你需要讓模型重新學習的,只是最終的“任務語義”。
因此,這種方式特別適合: - 你的數據非常少
- 新任務和原任務比較接近(例如都屬於圖像分類)
2.2 在預訓練基礎上整體微調(fine-tuning)
第二種方式比喻起來更像是:“拿到別人寫好的教材,但你對其中很多部分都有自己的想法,於是你決定在原有基礎上全書都修改一點,只不過改得很輕。”
具體做法是:
- 仍然從一個預訓練模型開始
- 不是隻訓練最後幾層,而是允許整個網絡都參與更新
- 使用較小的學習率,避免把原來已經學得很好的特徵破壞掉
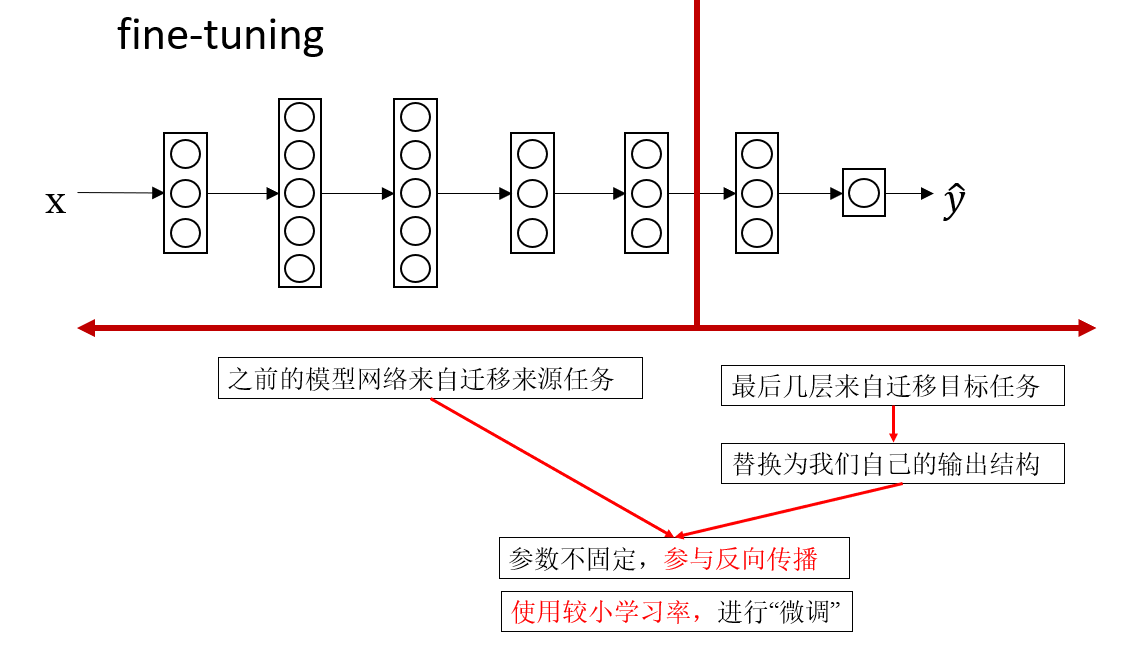
再舉一個例子,你可以把它想象成:
模型已經是一個受過良好訓練的學生,但你希望他再進一步按照你的任務風格來調整思路,於是讓他重新複習你修改過的知識,但修改幅度非常小。
這種方式適用於:
- 新任務的數據量比剛才那種情況更多
- 新任務和原任務差別較大(例如原任務是動物分類,你的任務是醫學影像)
- 你希望模型能真正為你的任務“深入適配”
微調整個網絡的好處是:靈活、適應性強,能更充分地利用你提供的新數據。
但它需要更多數據,同時也更容易過擬合。
2.3 兩種方式的選擇邏輯
一句話總結:
- 如果你的數據很少,只訓練最後幾層更保險
- 如果數據量適中,或者新舊任務差異明顯,微調整個網絡會有更好的表現。
我會在本週的代碼實踐部分着重演示如何使用遷移學習和它的實際效果,在如今的的實際任務中,它是很常見的一種調試方向。
3. 在應用遷移學習的幾點注意事項
- 確保遷移來源任務和遷移目標任務擁有相同類型的輸入,比如同樣大小的圖片或相同數量的特徵,這樣才能進行訓練。
- 只有在遷移來源任務的數據量更多的情況下,把它的模型遷移到目標任務才是更有意義的。
- 當遷移來源任務和遷移目標任務的低層次特徵更相似時,遷移學習往往能起到更大的幫助。
4. 總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 遷移學習 | 利用在大數據集上訓練好的模型,把已學到的低層特徵(如邊緣、紋理、局部形狀)遷移到數據量少的新任務上,只訓練新任務相關的部分或微調整個網絡 | “借力”——站在別人肩膀上學習 |
| 遷移學習的出現背景 | 數據量不足,高質量標註數據難獲取 | 比如工業零件缺陷識別,數據只有幾十張,無法從零訓練深度網絡 |
| 遷移學習的 核心思想 | 低層視覺特徵通用,高層語義任務差異大 | 貓狗識別模型也能幫助工業零件瑕疵檢測,因為輪廓、邊緣、紋理等特徵通用 |
| 固定前幾層(freeze) | 保留預訓練模型前幾層,只替換最後幾層分類器,新任務只訓練最後幾層 | “借一本已經做滿筆記的教材,只在你需要的章節上補充內容” |
| 微調整個網絡(fine-tuning) | 在預訓練模型基礎上,允許整個網絡都參與更新,使用小學習率調整已有特徵以適應新任務 | “拿到別人寫好的教材,但你對其中很多部分都有自己的想法,輕微修改全書內容” |