

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第四課第三週的課後習題和代碼實踐部分。
1.理論習題
【中英】【吳恩達課後測驗】Course 4 -卷積神經網絡 - 第三週測驗
習題都較為簡單,就不再多説了,還是把重點放在下面的演示部分。
2.代碼實踐
YOLO車輛識別實戰
同樣先擺上這位博主的鏈接,在這周的編程作業中,這位博主手動構建了YOLO網絡及其各個組件,非常詳細,但同樣因為 Keras 如今已經被 TF 的集成,如果要進行相應實踐,需要調整相應的導庫代碼和一些方法的調用。
我們仍然使用較成熟的框架來演示一下 YOLO 算法,只是這次我們既不用 PyTorch ,也不用TF。
我們這次要使用的庫叫做 ultralytics,是 YOLO 官方團隊維護的 Python 包。
無論是使用 YOLO 進行學術實驗,還是競賽打榜,ultralytics 都被廣泛使用,如果説 PyTorch 和 TF 提供的是造模型的積木,那麼 ultralytics 就是針對 YOLO 算法的專精機器。
你可以直接通過 pip 安裝這個包:
pip install ultralytics
ultralytics 畢竟是一個首次使用的全新庫,因此,本篇我會使用一個極小的 demo 數據集,主要演示一下 ultralytics 的使用流程。
2.1 demo 數據集:COCO8
在目標檢測領域,COCO(Common Objects in Context) 是目前使用最廣泛、影響力最大的標準數據集之一。
它以複雜真實場景為特點,強調多目標共存、小目標比例高以及目標與背景強耦合,長期以來被作為目標檢測算法的重要評測基準。
標準的 COCO 數據集規模龐大,僅 2017 版本就包含超過 11 萬張訓練圖像,覆蓋 80 個常見物體類別,完整下載、預處理與訓練成本都較高。因此,儘管 COCO 非常適合用於嚴肅的算法研究與性能對比,但對於初學者上手門檻偏高。

為了解決這一問題,Ultralytics 官方提供了一個用於演示和教學的極簡數據集 —— COCO8。
COCO8 本質上是從 COCO 數據集中抽取出的一個最小化子集,在保持 COCO 數據格式與標註規範完全一致的前提下,將數據規模壓縮到了極低的水平。目前的 COCO8 僅包含 8 張圖像,通常劃分為 訓練集 4 張、驗證集 4 張,並覆蓋 COCO 中的若干典型目標類別。
這種設計使得 COCO8 具備兩個非常突出的特點:
一方面,它可以在數秒內完成下載,並在極短時間內跑完一次完整的訓練流程;另一方面,它又完整保留了真實 COCO 數據集在目錄結構、標註格式與訓練接口上的一致性。
因此,COCO8 的核心用途並不是訓練一個性能良好的檢測模型,而是用於:快速驗證 ultralytics 的安裝與環境配置是否正確、流程是否正常並演示 YOLO 的訓練、驗證與推理的完整閉環。
需要特別説明的是,由於數據規模極小,COCO8 上得到的指標也不具備統計意義,也不反映模型的實際檢測能力。它的價值更多體現在“流程驗證”和“使用示例”層面。
2.2 使用 ultralytics 實現 YOLO 算法
先來看這樣一段代碼:
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
results = model.train(
data="coco8.yaml",
epochs=50,
imgsz=640,
batch=16,
name="coco8_train",
device="cpu"
)
metrics = model.val(device="cpu")
print("mAP50-95:", metrics.box.map)
print("mAP50:", metrics.box.map50)
要説明的是:這就是在 ultralytics 上實現 YOLO 算法的完整代碼,包括創建模型、輸入數據、模型傳播、指標評估甚至包括可視化圖表。
是的,這便是 ultralytics 的顯著特點,它的封裝度極高。
這代表我們使用起來可以較容易地跑通代碼,但同時也意味着隱藏了大量細節,想要熟練應用,就要慢慢拆解。
現在,我們就來詳細看看這段代碼的運行細節:
(1) 模型定義
首先,定義模型:
model = YOLO("yolo11n.pt") # 這裏傳入的是預訓練權重文件名,.pt文件是 PyTorch 的權重格式。
YOLO 是 ultralytics 提供的統一模型接口類,它可以根據傳入的參數,加載不同版本的 YOLO 模型(如 YOLOv8、YOLO11 等),它封裝了模型的所有關鍵邏輯。
要説明的是,YOLO 模型權重文件通常遵循如下命名規則:
在 ultralytics 最新版本中,YOLO 模型權重文件通常遵循如下命名規則:
yolo[版本號][模型大小].pt
版本號表示 YOLO 的算法版本或 ultralytics 發佈的迭代版本。
模型大小 表示模型的參數量與計算複雜度,也是速度和精度的折中指標:
n= nano → 極小模型,參數少,推理快,適合演示和入門s= small → 小型模型,參數稍多,精度和速度平衡m= medium → 中等模型,精度更高,訓練和推理開銷也增大l= large → 大模型,高精度,訓練和推理成本高x= extra large → 超大模型,精度最高,但訓練成本最大
同時,你會發現,只要我們傳入 .pt 結尾的權重文件作為參數,那就代表我們使用的是預訓練模型。
而如果你希望從頭訓練自己的模型,就要改變傳入參數:
# 從頭創建模型,不加載預訓練權重
model = YOLO("yolov8n.yaml") # 只指定網絡結構 YAML,不是 .pt 文件
(2) 訓練方法
瞭解完模型定義後,現在就來看看傳入方法
results = model.train(...)
這一行是整個流程的核心。調用 train() 方法後,ultralytics 會自動完成一次完整的目標檢測訓練流程。
從宏觀上看,這一行代碼內部依次完成了以下工作:
- 讀取並解析
coco8.yaml數據集配置文件 - 根據配置構建訓練集與驗證集的數據加載器
- 加載預訓練權重並初始化模型參數
- 按照指定的訓練輪數執行前向傳播、損失計算與反向傳播
- 在訓練過程中自動記錄 loss、mAP 等指標,並生成可視化結果
也就是説,我們在代碼中看到的只是一次函數調用,但在其背後,實際上已經包含了一個標準深度學習訓練框架所需的完整流程。
下面,我們再展開看看這個方法的參數設置:
data="coco8.yaml" # Ultralytics 內置的 COCO8 配置,首次運行自動下載數據集
這一參數用於指定數據集的配置文件。
與之前在代碼中手動構建 Dataset 和 DataLoader 不同,ultralytics 採用 YAML 文件(你可以理解為專用設定集) 來描述數據集的路徑、類別數量以及類別名稱。
通過這種方式,模型與數據集實現瞭解耦: 同一套訓練代碼可以通過更換 YAML 文件,直接應用到不同的數據集上,而無需修改模型或訓練邏輯。
再來看看它的運行時的細節:
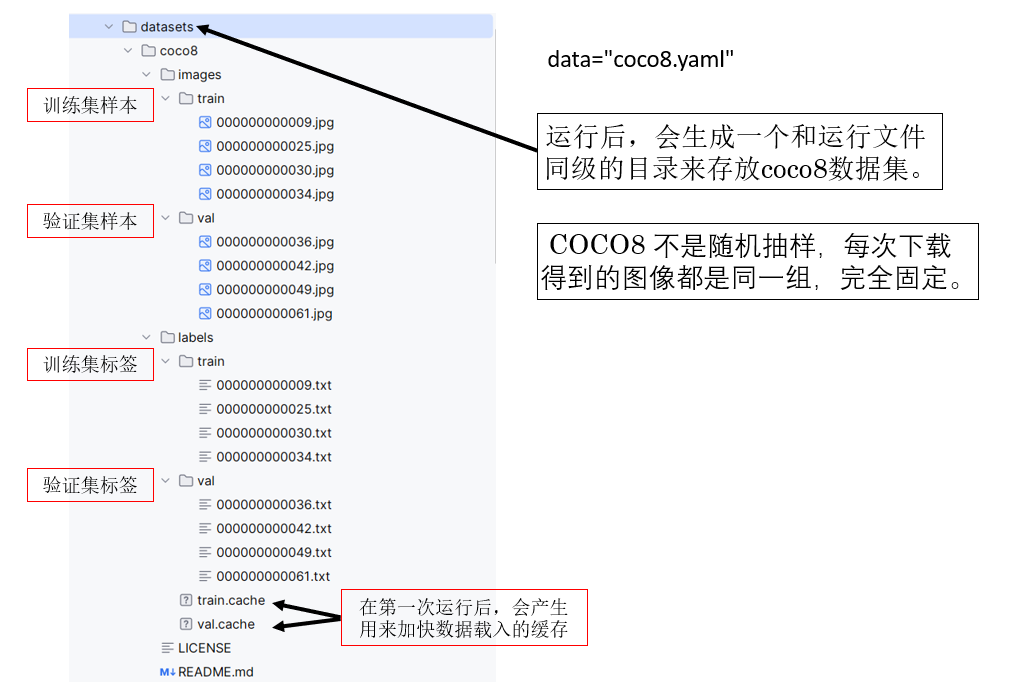
繼續看下面幾個參數:
epochs=50, # 訓練輪次
imgsz=640, # 圖像大小
batch=16, # 批次大小
name="coco8_train", # 實驗名稱
device="cpu" # 如果有 GPU 用 0,或 "cuda";無 GPU 用 "cpu"
這些我們都比較熟悉了,要專門説的一點是:
name="coco8_train" 指定了本次訓練實驗的名字,ultralytics 會根據這個名字創建一個文件夾來保存訓練輸出。每個實驗名對應一個獨立的訓練結果目錄,方便管理。
我們後面展示運行結果時就會再次用到它。
(3)評估方法
同樣,這一方法被高度封裝:
metrics = model.val(device="cpu") # 默認使用GPU,因此,如果沒有GPU,要顯式指定CPU。
print("mAP50-95:", metrics.box.map)
print("mAP50:", metrics.box.map50)
這是 ultralytics YOLO 提供的驗證接口, 它在內部做了這些關鍵步驟:
- 讀取並加載驗證集:如果有緩存(
.cache文件),會加快數據載入。 - 模型前向傳播:自動使用非極大值抑制篩選重複框。
- 計算指標:返回的
metrics對象中包含了不同類型的指標數據。
於是,我們便可以直接打印 metrics 對象中的指標。
現在,瞭解了框架本身後,我們來看看運行效果和其過程中的細節。
2.3 在 coco8 上運行 YOLO 算法
YOLO 的模型時至今日仍在不斷地更新,我們使用的 YOLOv11 的網絡結構如下:
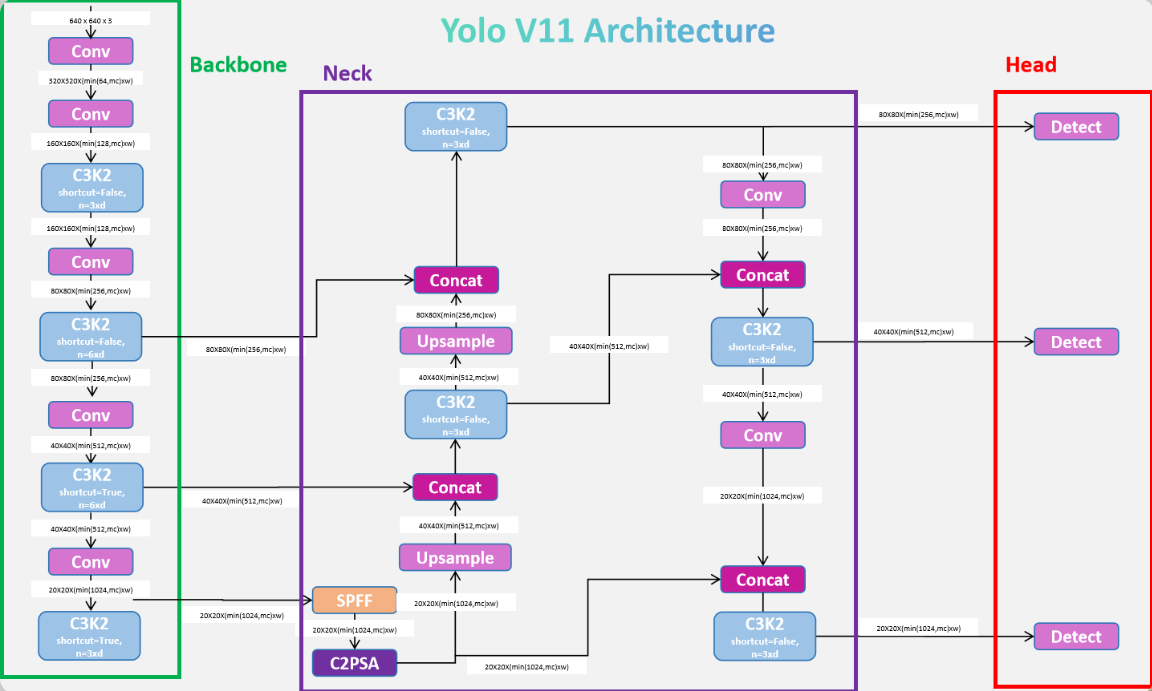
它集成了很多的先進技術,非常複雜,目前階段,我們理解 YOLO 算法的基礎原理就好。
現在,我們來看看代碼的運行過程:
(1)控制枱輸出內容
當代碼成功開始運行後,你會發現在輪次信息前,控制枱就輸出了很多內容。這些其實是在訓練開始時的標準日誌,它主要是在做訓練前的準備、模型初始化、數據檢查和優化器配置。
我們簡單看一看:

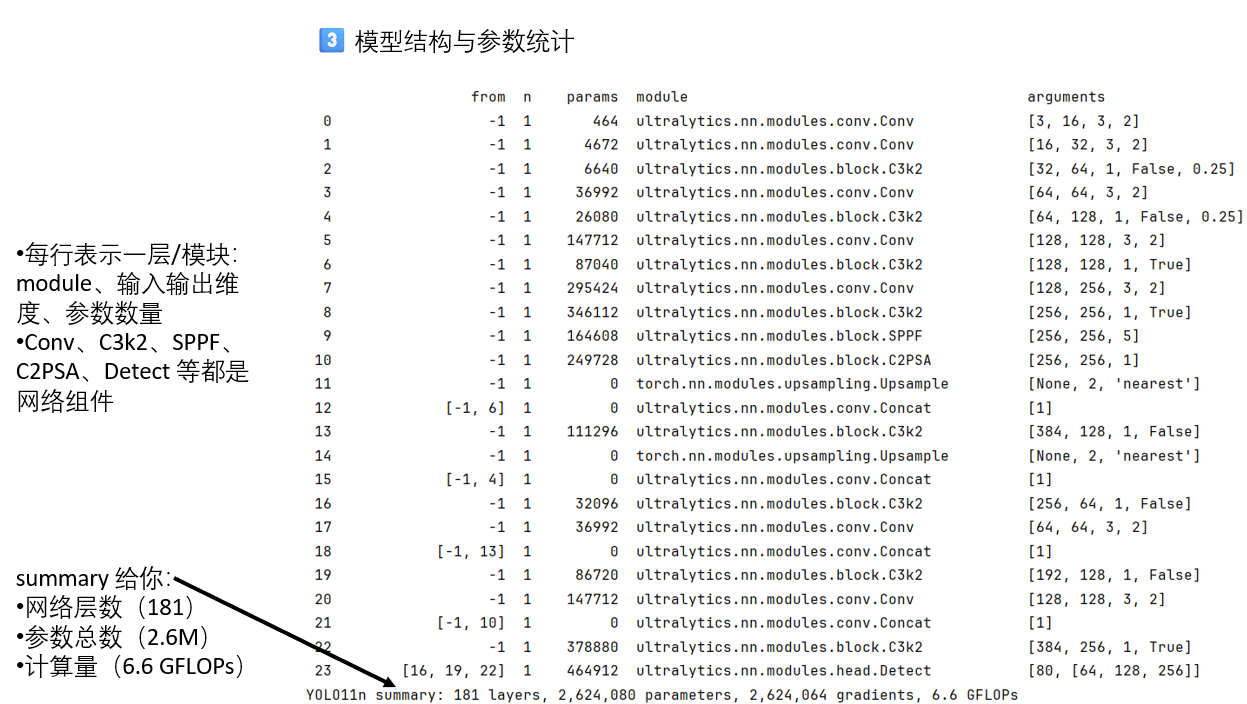

直到這裏,模型才完成前期準備工作,開始正式訓練。
同樣,ultralytics 對訓練信息的輸出也十分豐富:

別急,還沒完,在結束訓練後,ultralytics 還會給你做一些”善後和總結“:

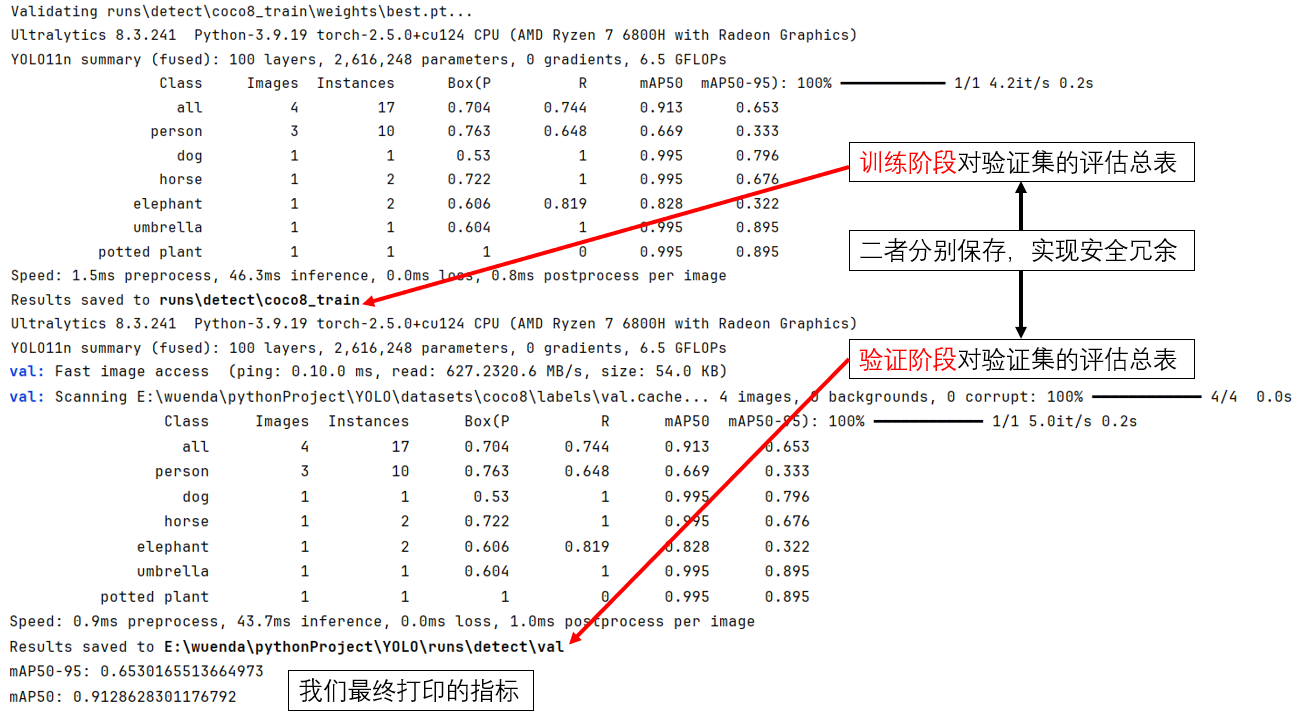
顯然,這裏的指標較高是預訓練的成果。
這一整套下來,你會發現,不同於我們原本自己打印的輸出結果,ultralytics 對訓練日誌的記錄和管理非常完備,而且還不僅僅侷限於控制枱輸出。
我們繼續往下:
(2)日誌文件夾
在完成訓練後,你會發現,運行文件的同級目錄中新出現了一個名為 runs 的文件夾,這就是ultralytics用來管理日誌的文件夾。
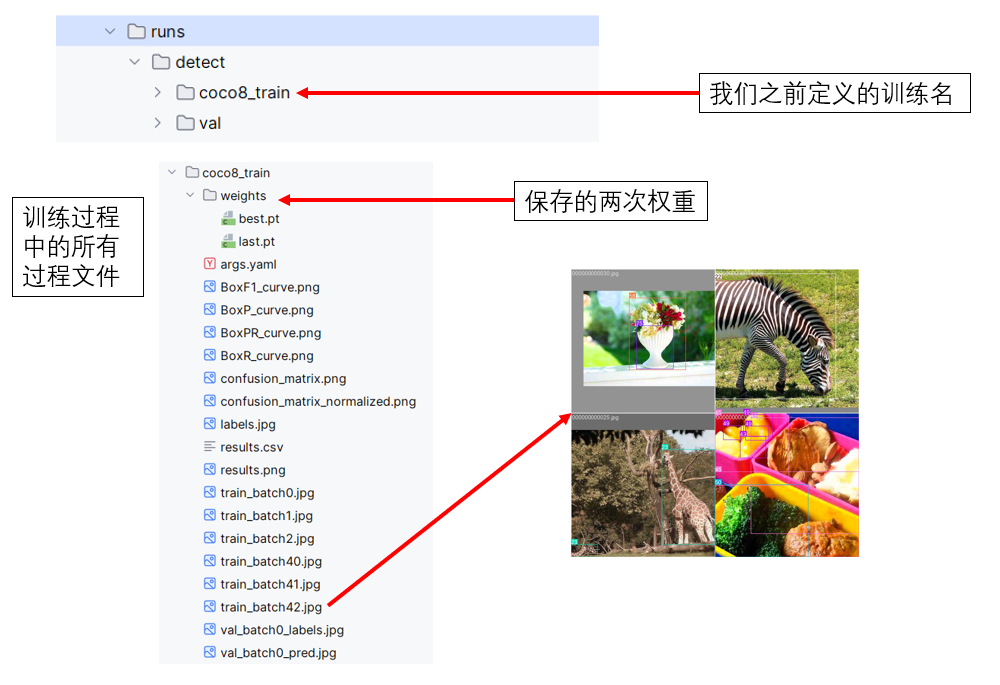
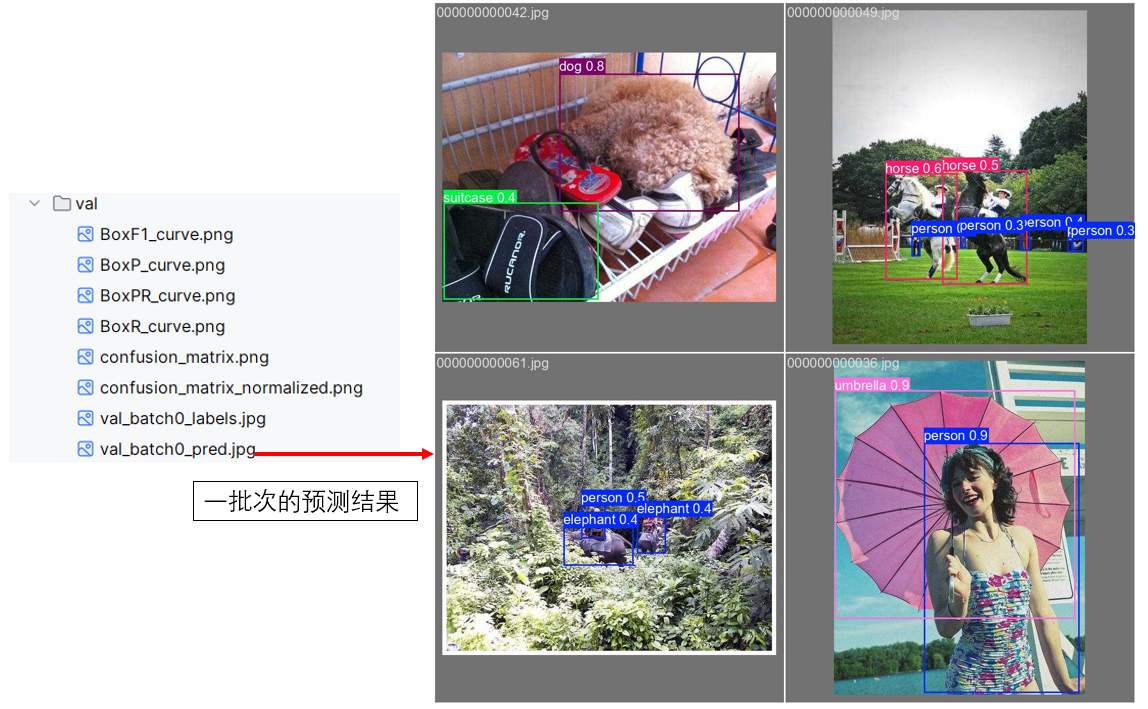
這樣的管理方式也更方便我們的溯源和調試。
我們這次實踐內容就到這裏,實際上,與其説本篇是在演示 YOLO 算法,倒不如説是對 ultralytics 的使用介紹。主要原因是 YOLO 算法作為真正流行的算法,其使用的各項技術和原理已經可以出本書了,我們這裏只將其作為計算機視覺中的一個方向來介紹一些基礎內容。
實際上還有很多內容可以展開,比如在訓練日誌裏出現的一些專業圖表的含義,以及檢測任務的幾個評估指標,這些我們之後遇到再慢慢説。