

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第三課的第二週內容,2.4到2.6的內容。
本週為第三課的第二週內容,本週的內容關於在上週的基礎上繼續展開,並拓展介紹了幾種“學習方法”,可以簡單分為誤差分析和學習方法兩大部分。
其中,對於後者的的理解可能存在一些難度。同樣,我會更多地補充基礎知識和實例來幫助理解。
本篇的內容關於數據不匹配問題,是對在訓練集和測試集的數據分佈不同情況下的分析和處理措施。
1. 訓練集和測試集分佈不同時的數據集劃分
學到現在,即便我們已經知道了很多提升模型性能的方法,但當提及這點時,我想第一個出現在我們腦海裏的很可能還是增加數據量,尤其是對應神經網絡而言。
模型就像一個對輸入不斷學習的學生,輸入數據量就相當於他的”知識量“。因此,在絕大多數情況下,增加數據量都是一個好的選擇,即使他帶來的成本比其他方法要高。
但也同樣如此,如何獲取合適的、可用的數據就成了問題,我們以此來展開:
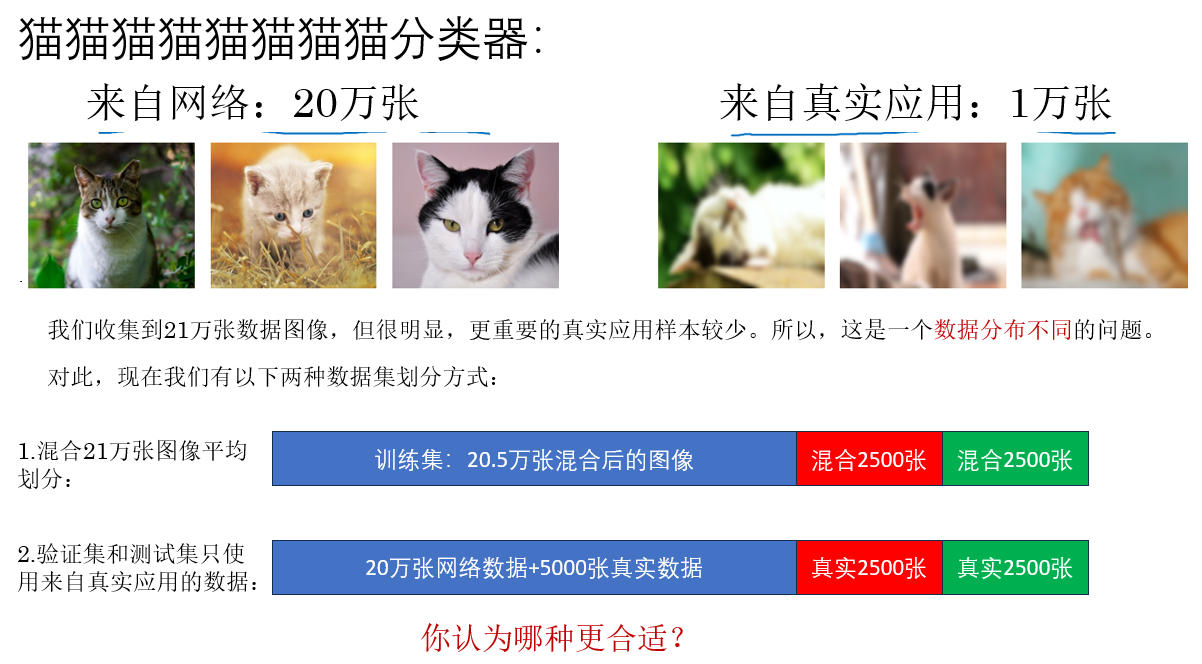
想來這個問題並不難,我們繼續:
課程裏還補充了一個汽車語音識別的例子,但是實際上都是一個意思,就不再重複了,我們來看看如何緩解數據不平衡帶來的分佈問題。
2.數據不平衡帶來的分佈問題
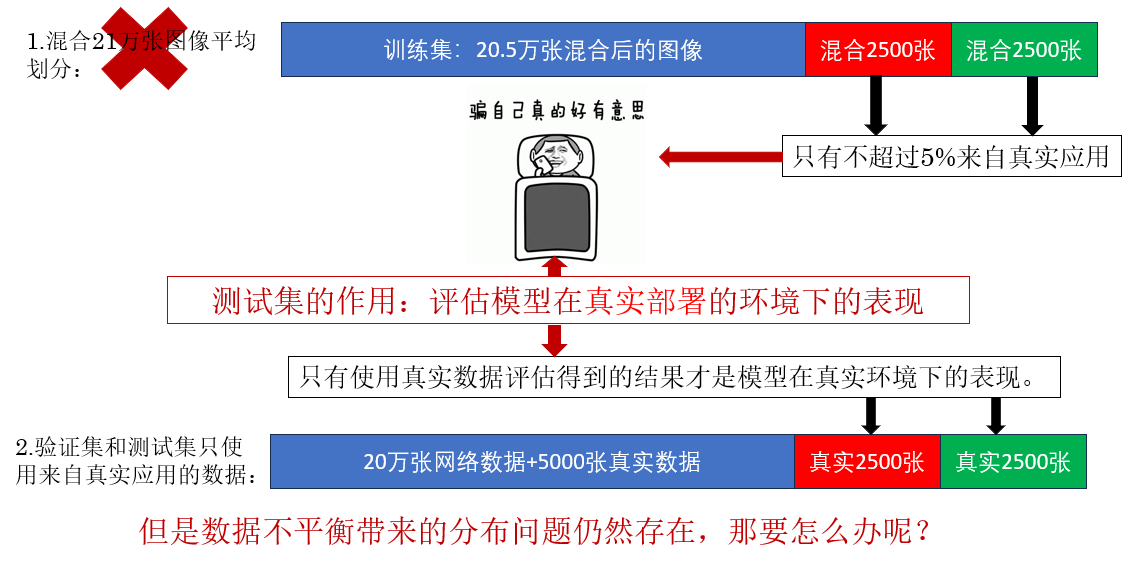
使用了較合理的數據集劃分後,我們繼續看:
很明顯,這種問題讓我們無法從指標中分析出明確的優化方向,自然阻礙了我們的任務進程。
如何在這種分佈不同的問題下明確我們的優化方向? 就是下面的內容。
3. 訓練驗證集
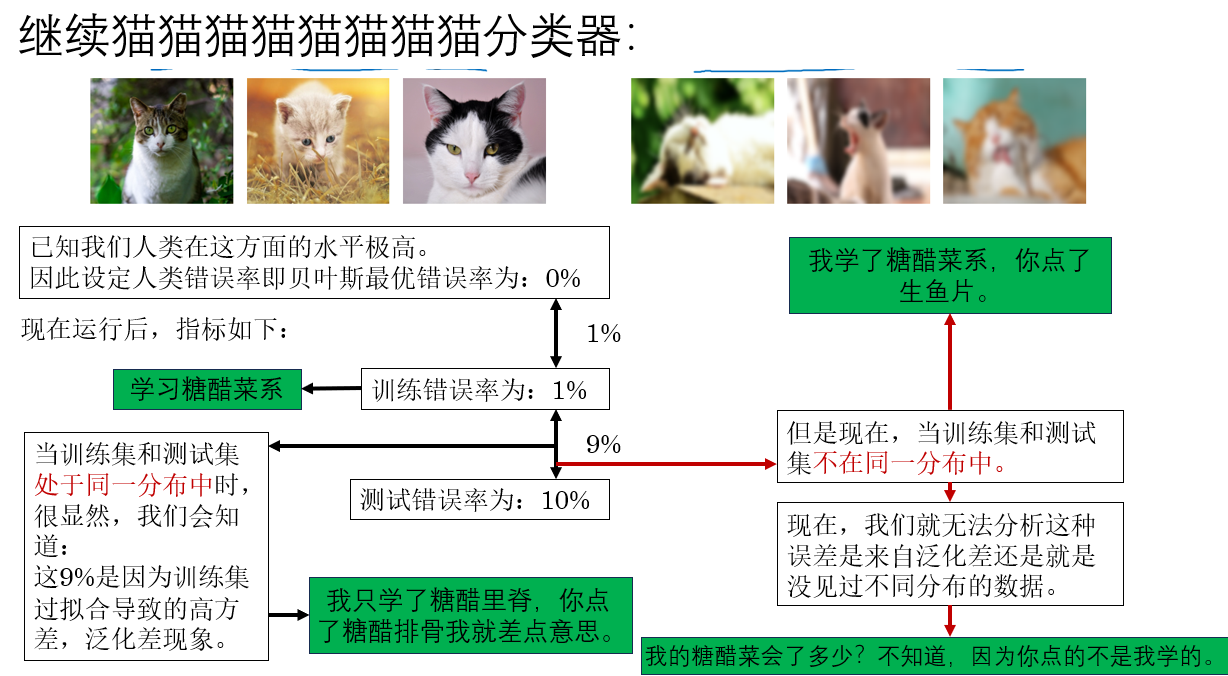
直接説做法:再從訓練集中劃分一部分不用於訓練但和訓練集處於同一分佈的數據,用來評估模型的泛化能力,這就是訓練驗證集。
來看一組例子如何應用訓練驗證集:
由此,在訓練集和測試集的數據分佈不同的情況下,我們通過增加訓練驗證集,仍然實現了對優化方向的誤差分析。
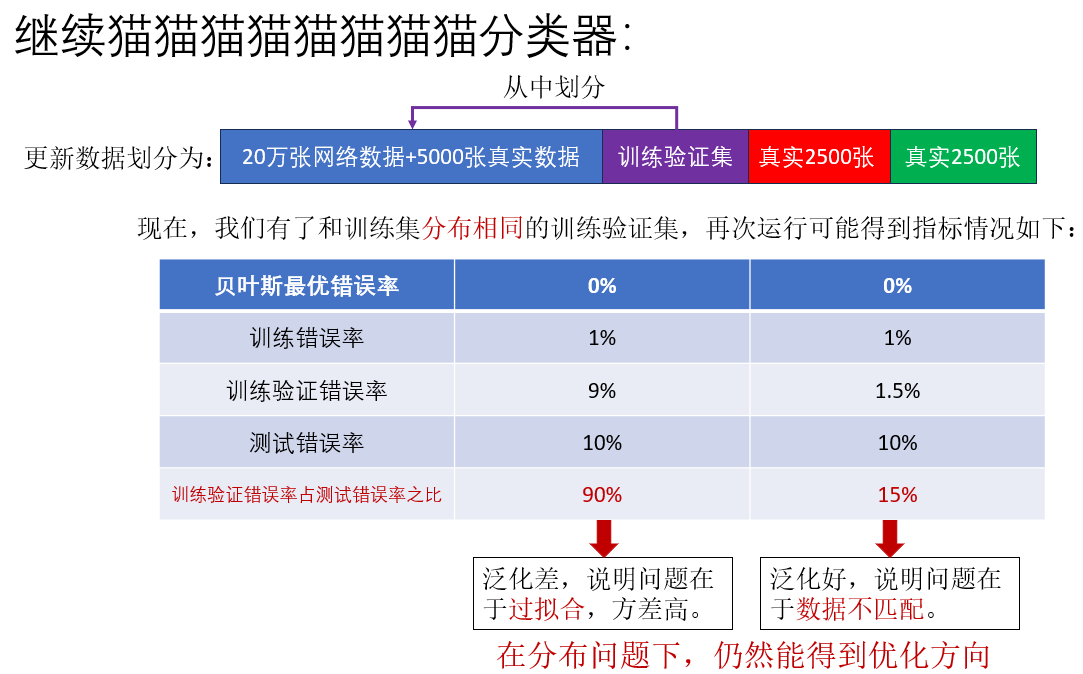
我們再看加入訓練驗證集後幾種情況下的誤差分析:
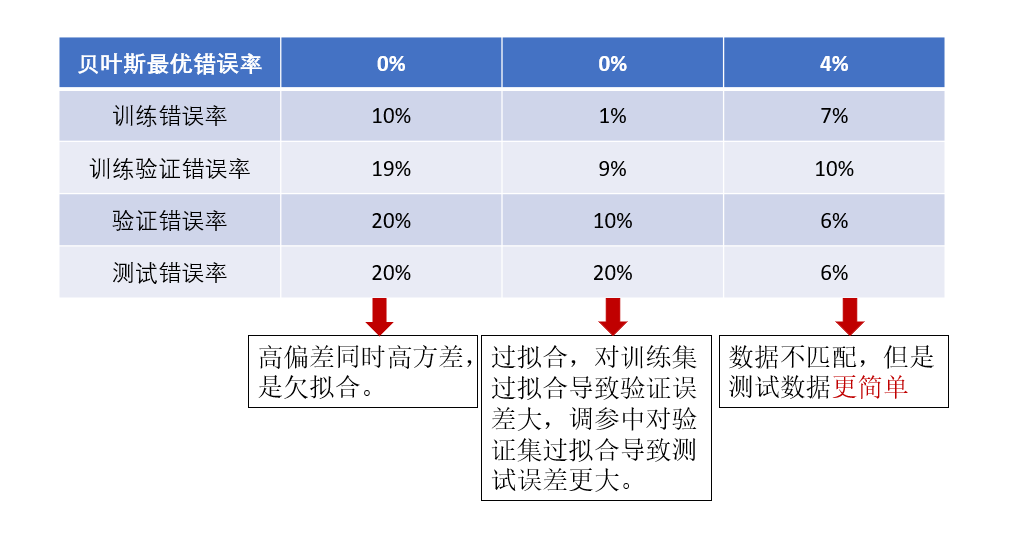
現在,我們已經可以分析出數據不匹配問題了,那怎麼緩解數據不匹配問題呢?這就是最後一部分內容。
4. 數據不匹配問題的緩解方法
這種問題的根本還是因為訓練集和數據集的分佈不同,真實應用獲取的數據量較小不足以支撐訓練導致的,如果要完全解決這種問題,只能獲取更多的真實數據,可是這種問題往往就是因為無法獲取更多真實數據導致的。
而如果在不使用這種方法下,一個比較容易想到的思路就是:儘可能縮小訓練集和真實應用數據的差異,而如何縮小,還需要根據任務不同而變換。
而這種對原始數據進行處理,合成獲取新數據從而解決數據不匹配的邏輯,我們叫人工合成數據。
我們先看一個比較簡單的例子:

而這個模糊化處理可以説可以零成本實現,圖中就是我進行的處理效果,代碼很簡單:
from PIL import Image, ImageFilter #核心出裝
import matplotlib.pyplot as plt
# 打開圖片文件
image_path = "aaa.jpg" # 你的圖片路徑
image = Image.open(image_path)
# 應用模糊濾鏡
blurred_image = image.filter(ImageFilter.GaussianBlur(radius=5)) # radius值越大,模糊效果越強
# 展示對比圖
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
axes[0].imshow(image)
axes[0].set_title("Original Image")
axes[0].axis('off')
axes[1].imshow(blurred_image)
axes[1].set_title("Blurred Image")
axes[1].axis('off')
plt.show()
# 保存模糊後的圖片
#blurred_image.save("blurred_image.jpg")
説到這裏擴展一下,你可能會有一點疑惑,那就是模糊化我們之前在數據增強裏提過,那數據增強和人工合成數據又有什麼區別呢?
其實二者都是一種擴展數據的思路,只是往往用處不同,簡單來説:
- 數據增強往往是因為數據不夠,我們需要更多數據用於訓練。
- 人工合成數據是因為數據不好,我們需要合成數據來緩解數據不匹配。
我們繼續,看課程裏提到的一個難一些的例子:
因此,人工合成數據只是一種緩解數據不匹配的方法,如果過於依賴它反而會讓模型表現出極差的泛化性,無法適應真實應用,因為真實情況遠比合成情況要廣。
5. 總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 分佈不匹配(Distribution Mismatch) | 訓練集與真實應用數據的來源或特徵不同,導致訓練指標無法反映真實表現。 | 你在安靜的教室練習口語,但真正考試是在嘈雜的咖啡廳,自然效果會掉。 |
| 訓練驗證集(Training-Dev Set) | 從訓練分佈中再劃分一部分不參與訓練的數據,用來區分“模型能力不足”和“分佈不同造成的偏差”。 | 像是給你準備一張“模擬考試卷”,難度、風格都和練習冊一樣,用來判斷你是否真的掌握。 |
| 數據不匹配誤差(Data Mismatch Error) | 模型在訓練驗證集表現良好,但在測試集表現差,這部分差距就是分佈不匹配造成的。 | 就像你在訓練場能跑 100 米 13 秒,但比賽當天因為風大、路滑,只能跑 14 秒。 |
| 人工合成數據(Synthetic Data) | 對訓練集進行修改,讓它更接近真實應用分佈,從而緩解數據不匹配。 | 為了適應比賽環境,你在訓練時故意讓跑道變濕、開風扇模擬逆風。 |
| 數據增強(Data Augmentation) | 通過旋轉、翻轉、縮放等方式擴充訓練樣本數量,讓模型更穩健。 | 拓展練習題數量,讓你做更多不同角度但同類型的題目。 |